Sekvens till sekvens (Sekvens till sekvens) Modell med PyTorch
⚡ Smart sammanfattning
Seq2Seq är en kodare-avkodarearkitektur som mappar en inmatningssekvens till en utmatningssekvens med hjälp av två återkommande neurala nätverk, vilket driver maskinöversättning och andra naturliga språkbehandlingsuppgifter där inmatnings- och utmatningslängder skiljer sig åt.

Vad är NLP?
NLP eller Natural Language Processing är en av de populära grenarna inom artificiell intelligens som hjälper datorer att förstå, manipulera eller svara på en människa på deras naturliga språk. NLP är motorn bakom Google Translate som hjälper oss att förstå andra språk.
Vad är Seq2Seq?
Seq2Seq är en metod för kodar-avkodarbaserad maskinöversättning och språkbearbetning som mappar en inmatning av sekvens till en utdata av sekvens med en tagg och uppmärksamhetsvärde. Tanken är att använda 2 RNN som kommer att fungera tillsammans med en speciell token och försöka förutsäga nästa tillståndssekvens från föregående sekvens.
Hur man förutsäger sekvens från föregående sekvens
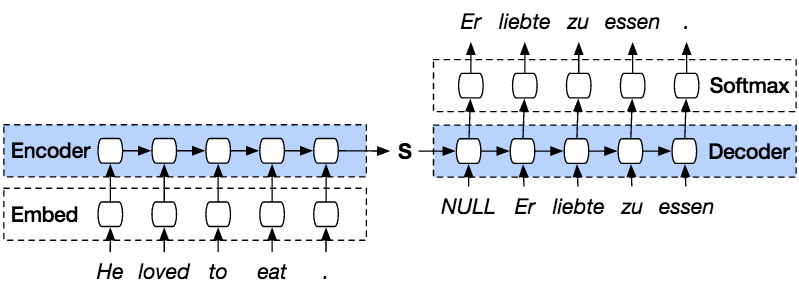
Följande är stegen för att förutsäga en sekvens från föregående sekvens med PyTorch.
Steg 1) Laddar vår data
För vår datauppsättning kommer du att använda en datauppsättning från Tabbavgränsade tvåspråkiga meningspar. Här kommer jag att använda den engelska till indonesiska datasetet. Du kan välja vad du vill men kom ihåg att ändra filnamnet och katalogen i koden.
from __future__ import unicode_literals, print_function, division import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import numpy as np import pandas as pd import os import re import random device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Steg 2) Dataförberedelse
Du kan inte använda datamängden direkt. Du måste dela upp meningarna i ord och konvertera dem till en One-Hot Vector (en enda het vektor). Varje ord kommer att indexeras unikt i Lang-klassen för att skapa en ordbok. Lang-klassen lagrar varje mening och delar upp den ord för ord med addSentence. Skapa sedan en ordbok genom att indexera varje okänt ord för Sequence för att sekvensera modeller.
SOS_token = 0 EOS_token = 1 MAX_LENGTH = 20 #initialize Lang Class class Lang: def __init__(self): #initialize containers to hold the words and corresponding index self.word2index = {} self.word2count = {} self.index2word = {0: "SOS", 1: "EOS"} self.n_words = 2 # Count SOS and EOS #split a sentence into words and add it to the container def addSentence(self, sentence): for word in sentence.split(' '): self.addWord(word) #If the word is not in the container, the word will be added to it, else, update the word counter def addWord(self, word): if word not in self.word2index: self.word2index[word] = self.n_words self.word2count[word] = 1 self.index2word[self.n_words] = word self.n_words += 1 else: self.word2count[word] += 1
Klassen Lang är en klass som hjälper oss att skapa en ordbok. För varje språk delas varje mening upp i ord och läggs sedan till i behållaren. Varje behållare lagrar orden i lämpligt index, räknar ordet och lägger till ordets index så att vi kan använda det för att hitta ordets index eller hitta ett ord från dess index.
Eftersom vår data är separerad av TAB måste du använda pandor som vår dataladdare. Pandas kommer att läsa våra data som en dataFrame och dela upp dem i vår käll- och målmening. För varje mening du har kommer du att normalisera den till gemener, ta bort alla icke-tecken, konvertera till ASCII från Unicode och dela meningarna så att du har varje ord i den.
#Normalize every sentence def normalize_sentence(df, lang): sentence = df[lang].str.lower() sentence = sentence.str.replace('[^A-Za-z\s]+', '') sentence = sentence.str.normalize('NFD') sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8') return sentence def read_sentence(df, lang1, lang2): sentence1 = normalize_sentence(df, lang1) sentence2 = normalize_sentence(df, lang2) return sentence1, sentence2 def read_file(loc, lang1, lang2): df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2]) return df def process_data(lang1,lang2): df = read_file('text/%s-%s.txt' % (lang1, lang2), lang1, lang2) print("Read %s sentence pairs" % len(df)) sentence1, sentence2 = read_sentence(df, lang1, lang2) source = Lang() target = Lang() pairs = [] for i in range(len(df)): if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH: full = [sentence1[i], sentence2[i]] source.addSentence(sentence1[i]) target.addSentence(sentence2[i]) pairs.append(full) return source, target, pairs
En annan användbar funktion som du kommer att använda är att konvertera par till tensorer. Detta är mycket viktigt eftersom vårt nätverk bara läser data av tensortyp. Det är också viktigt eftersom det är i den delen där det, i varje ände av meningen, kommer att finnas en token som talar om för nätverket att inmatningen är klar. För varje ord i meningen hämtar den indexet från lämpligt ord i ordboken och lägger till en token i slutet av meningen.
def indexesFromSentence(lang, sentence): return [lang.word2index[word] for word in sentence.split(' ')] def tensorFromSentence(lang, sentence): indexes = indexesFromSentence(lang, sentence) indexes.append(EOS_token) return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1) def tensorsFromPair(input_lang, output_lang, pair): input_tensor = tensorFromSentence(input_lang, pair[0]) target_tensor = tensorFromSentence(output_lang, pair[1]) return (input_tensor, target_tensor)
Seq2Seq-modell

PyTorch Seq2seq-modellen är en typ av modell som använder en PyTorch-kodaravkodare ovanpå modellen. Kodaren kodar meningen ord för ord till ett index över ordförråd eller kända ord med ett index, och avkodaren förutsäger utdata från den kodade indatan genom att avkoda indatan i sekvens och försöker använda den sista indatan som nästa indata om det är möjligt. Med den här metoden är det också möjligt att förutsäga nästa indata för att skapa en mening. Varje mening tilldelas en token för att markera slutet på sekvensen. I slutet av förutsägelsen finns det också en token för att markera slutet på utdatan. Så från kodaren skickar den ett tillstånd till avkodaren för att förutsäga utdatan.

Kodaren kodar vår inmatade mening ord för ord i sekvens, och i slutet kommer det att finnas en token som markerar slutet på en mening. Kodaren består av ett inbäddningslager och ett GRU-lager. Inbäddningslagret är en uppslagstabell som lagrar inbäddningen av vår inmatning i en ordbok med fast storlek. Den skickas till ett GRU-lager. GRU-lagret är en gated recurrent unit som består av en flerskiktstyp av RNN som kommer att beräkna den sekvenserade ingången. Detta lager kommer att beräkna det dolda tillståndet från det föregående och uppdatera återställningen, uppdateringen och nya grindar.

Avkodaren avkodar ingången från kodarens utgång. Den försöker förutsäga nästa utgång och om möjligt använda den som nästa ingång. Avkodaren består av ett inbäddningslager, ett GRU-lager och ett linjärt lager. Inbäddningslagret skapar en uppslagstabell för utgången och skickar den till ett GRU-lager för att beräkna det förutspådda utgångstillståndet. Därefter hjälper ett linjärt lager till att beräkna aktiveringsfunktionen för att bestämma det sanna värdet av den förutspådda utgången.
class Encoder(nn.Module): def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers): super(Encoder, self).__init__() #set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers self.input_dim = input_dim self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.num_layers = num_layers #initialize the embedding layer with input and embbed dimention self.embedding = nn.Embedding(input_dim, self.embbed_dim) #intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and #set the number of gru layers self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) def forward(self, src): embedded = self.embedding(src).view(1,1,-1) outputs, hidden = self.gru(embedded) return outputs, hidden class Decoder(nn.Module): def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers): super(Decoder, self).__init__() #set the encoder output dimension, embed dimension, hidden dimension, and number of layers self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.output_dim = output_dim self.num_layers = num_layers # initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function. self.embedding = nn.Embedding(output_dim, self.embbed_dim) self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) self.out = nn.Linear(self.hidden_dim, output_dim) self.softmax = nn.LogSoftmax(dim=1) def forward(self, input, hidden): # reshape the input to (1, batch_size) input = input.view(1, -1) embedded = F.relu(self.embedding(input)) output, hidden = self.gru(embedded, hidden) prediction = self.softmax(self.out(output[0])) return prediction, hidden class Seq2Seq(nn.Module): def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH): super().__init__() #initialize the encoder and decoder self.encoder = encoder self.decoder = decoder self.device = device def forward(self, source, target, teacher_forcing_ratio=0.5): input_length = source.size(0) #get the input length (number of words in sentence) batch_size = target.shape[1] target_length = target.shape[0] vocab_size = self.decoder.output_dim #initialize a variable to hold the predicted outputs outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device) #encode every word in a sentence for i in range(input_length): encoder_output, encoder_hidden = self.encoder(source[i]) #use the encoder's hidden layer as the decoder hidden decoder_hidden = encoder_hidden.to(device) #add a token before the first predicted word decoder_input = torch.tensor([SOS_token], device=device) # SOS #topk is used to get the top K value over a list #predict the output word from the current target word. If we enable the teaching force, then the next decoder input is the next word, else, use the decoder output highest value. for t in range(target_length): decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden) outputs[t] = decoder_output teacher_force = random.random() < teacher_forcing_ratio topv, topi = decoder_output.topk(1) input = (target[t] if teacher_force else topi) if(teacher_force == False and input.item() == EOS_token): break return outputs
Steg 3) Utbilda modellen
Träningsprocessen i Seq2seq-modeller börjar med att konvertera varje par av meningar till tensorer från deras Lang-index. Vår sekvens-till-sekvens-modell använder SGD som optimerare och NLLLoss-funktionen för att beräkna förlusterna. Träningsprocessen börjar med att mata in paret av en mening till modellen för att förutsäga korrekt utdata. Vid varje steg beräknas utdata från modellen med de korrekta orden för att hitta förlusterna och uppdatera parametrarna. Eftersom du kommer att använda 75 000 iterationer kommer vår sekvens-till-sekvens-modell att generera 75 000 slumpmässiga par från vår dataset.
teacher_forcing_ratio = 0.5 def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion): model_optimizer.zero_grad() input_length = input_tensor.size(0) loss = 0 epoch_loss = 0 # print(input_tensor.shape) output = model(input_tensor, target_tensor) num_iter = output.size(0) print(num_iter) #calculate the loss from a predicted sentence with the expected result for ot in range(num_iter): loss += criterion(output[ot], target_tensor[ot]) loss.backward() model_optimizer.step() epoch_loss = loss.item() / num_iter return epoch_loss def trainModel(model, source, target, pairs, num_iteration=20000): model.train() optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.NLLLoss() total_loss_iterations = 0 training_pairs = [tensorsFromPair(source, target, random.choice(pairs)) for i in range(num_iteration)] for iter in range(1, num_iteration+1): training_pair = training_pairs[iter - 1] input_tensor = training_pair[0] target_tensor = training_pair[1] loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion) total_loss_iterations += loss if iter % 5000 == 0: avarage_loss= total_loss_iterations / 5000 total_loss_iterations = 0 print('%d %.4f' % (iter, avarage_loss)) torch.save(model.state_dict(), 'mytraining.pt') return model
Steg 4) Testa modellen
Utvärderingsprocessen för Seq2seq PyTorch är att kontrollera modellens utdata. Varje par av sekvens-till-sekvens-modeller matas in i modellen och genererar de förutspådda orden. Därefter tittar du på det högsta värdet vid varje utdata för att hitta rätt index. Och till slut jämför du det för att se vår modellförutsägelse med den sanna meningen.
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH): with torch.no_grad(): input_tensor = tensorFromSentence(input_lang, sentences[0]) output_tensor = tensorFromSentence(output_lang, sentences[1]) decoded_words = [] output = model(input_tensor, output_tensor) # print(output_tensor) for ot in range(output.size(0)): topv, topi = output[ot].topk(1) # print(topi) if topi[0].item() == EOS_token: decoded_words.append('' ) break else: decoded_words.append(output_lang.index2word[topi[0].item()]) return decoded_words def evaluateRandomly(model, source, target, pairs, n=10): for i in range(n): pair = random.choice(pairs) print('source {}'.format(pair[0])) print('target {}'.format(pair[1])) output_words = evaluate(model, source, target, pair) output_sentence = ' '.join(output_words) print('predicted {}'.format(output_sentence))
Låt oss nu börja vår träning med Seq till Seq, med antalet iterationer på 75000 och antalet RNN-lager på 1 med den dolda storleken 512.
lang1 = 'eng' lang2 = 'ind' source, target, pairs = process_data(lang1, lang2) randomize = random.choice(pairs) print('random sentence {}'.format(randomize)) #print number of words input_size = source.n_words output_size = target.n_words print('Input : {} Output : {}'.format(input_size, output_size)) embed_size = 256 hidden_size = 512 num_layers = 1 num_iteration = 100000 #create encoder-decoder model encoder = Encoder(input_size, hidden_size, embed_size, num_layers) decoder = Decoder(output_size, hidden_size, embed_size, num_layers) model = Seq2Seq(encoder, decoder, device).to(device) #print model print(encoder) print(decoder) model = trainModel(model, source, target, pairs, num_iteration) evaluateRandomly(model, source, target, pairs)
Som du kan se matchas vår förutspådda mening inte så bra, så för att få högre noggrannhet måste du träna med mycket mer data och försöka lägga till fler iterationer och antal lager med hjälp av Sequence för att sekvensinlära.
random sentence ['tom is finishing his work', 'tom sedang menyelesaikan pekerjaannya'] Input : 3551 Output : 4253 Encoder( (embedding): Embedding(3551, 256) (gru): GRU(256, 512) ) Decoder( (embedding): Embedding(4253, 256) (gru): GRU(256, 512) (out): Linear(in_features=512, out_features=4253, bias=True) (softmax): LogSoftmax() ) 5000 4.0906 10000 3.9129 15000 3.8171 20000 3.8369 25000 3.8199 30000 3.7957 75000 3.7044