Hur man laddar ner och installerar NLTK
⚡ Smart sammanfattning
Ladda ner och installera NLTK på Windows, Mac eller Linux genom att installera Python först, sedan tillsätt den naturliga Language Toolkit via pip eller Anaconda och ladda ner corpus-datauppsättningarna.

Installerar NLTK i Windows
Lär dig hur du konfigurerar NLTK Windows från kommandotolken. Instruktionerna nedan förutsätter Python är inte installerat än, så det första steget är att installera Python.
Installera Python in Windows
Steg 1) Öppna länken https://www.python.org/downloads/, och välj den senaste Windows släpp.
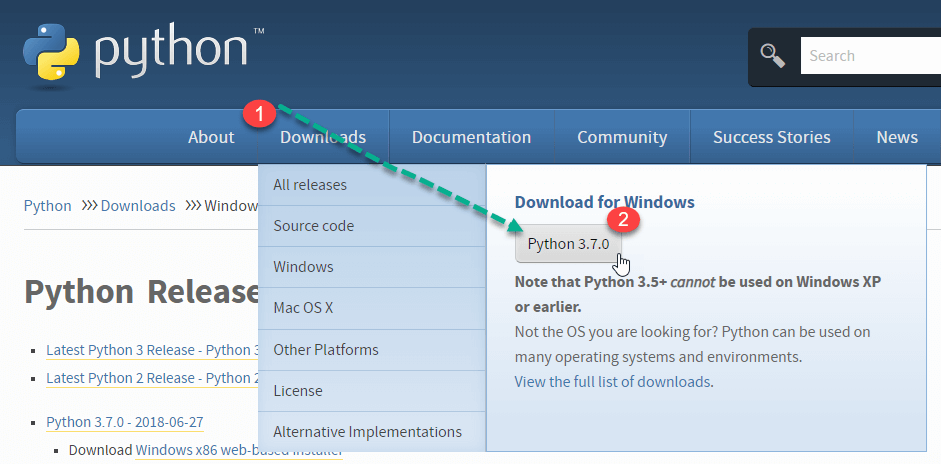
AnmärkningarFör en äldre version, besök fliken Nedladdningar för att se alla utgåvor.

Steg 2) Klicka på den nedladdade installationsfilen.

Steg 3) Välj Anpassa installationen.
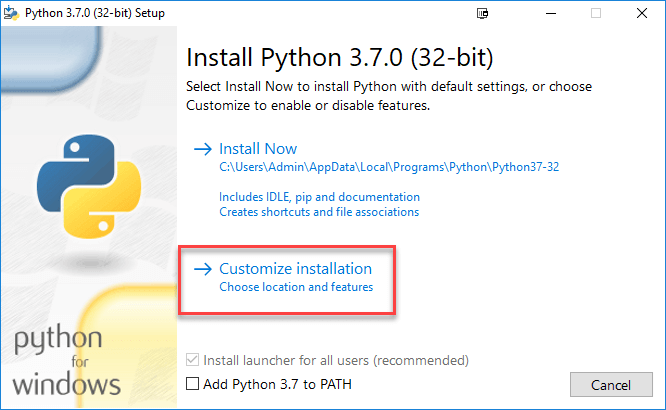
Steg 4) Klicka på NÄSTA.

Steg 5) På nästa skärm:
- Välj de avancerade alternativen.
- Ange en anpassad installationsplats. I det här exemplet är en mapp på C-enheten vald för enklare åtkomst.
- Klicka på Installera.

Steg 6) Klicka på knappen Stäng när installationen är klar.

Steg 7) Kopiera sökvägen till mappen Skript.

Steg 8) I Windows kommandotolken:
- Navigera till platsen för pip-mappen.
- Ange kommandot för att installera NLTK:
pip3 install nltk
- Installationen bör slutföras.

ANMÄRKNINGAR: För Python 2, använd kommandot pip2 install nltk.
Steg 9) Från Windows Start-menyn, sök efter och öppna Python Skal.

Steg 10) Kontrollera att installationen fungerar genom att köra kommandot nedan:
import nltk

Om inget fel visas är installationen klar.
Installera NLTK i Mac/Linux
Att installera NLTK på Mac eller Linux kräver Python pakethanteraren pip. Om pip inte är installerat, följ instruktionerna nedan för att slutföra processen.
Steg 1) Uppdatera paketindexet av typing kommandot nedan:
sudo apt update
Steg 2) Installera pip för Python 3:
sudo apt install python3-pip
Du kan också installera pip via easy_install:
sudo apt-get install python-setuptools python-dev build-essential
När easy_install är installerat, kör kommandot nedan för att installera pip:
sudo easy_install pip
Steg 3) Använd följande kommando för att installera NLTK:
sudo pip install -U nltk sudo pip3 install -U nltk
Installerar NLTK genom Anaconda
Steg 1) Installera Anaconda genom att besöka https://www.anaconda.com/products/individual och välja Python version du behöver.

Obs: Se denna handledning för detaljerade steg till installera Anaconda.
Steg 2) I Anaconda-prompten:
- Ange kommandot:
conda install -c anaconda nltk
- RevVisa informationen för paketuppgradering, nedgradering och installation och ange sedan ja.
- NLTK är nedladdad och installerad.

NLTK Dataset
NLTK-modulen levereras med många dataset som du behöver ladda ner innan användning. Tekniskt sett kallas varje dataset för en corpusVanliga exempel inkluderar stoppord, Gutenberg, framenet_v15, stora_grammatik, brunoch wordnet.
Hur man laddar ner alla paket av NLTK
Steg 1) Kör Python tolk in Windows eller Linux.
Steg 2)
- Ange kommandona:
import nltk nltk.download ()
- NLTK Downloader-fönstret öppnas. Klicka på knappen Ladda ner för att hämta datamängden. Den här processen tar tid beroende på din internetanslutning.

OBS: Du kan ändra nedladdningsplatsen genom att klicka på Arkiv > Ändra nedladdningskatalog.

Steg 3) För att testa den installerade datan, använd följande kod:
>>> from nltk.corpus import brown >>>brown.words()
['The', 'Fulton', 'County', 'Grand', 'Jury', 'said', …]

Kör NLP-skriptet
Det här avsnittet förklarar hur ett NLP-skript körs på en lokal dator. Rätt biblioteksval beror på dina behov. Se den officiella listan över NLP-bibliotek för alternativ som spaCy, gensim och TextBlob.
Hur man kör NLTK-skript
Steg 1) Kopiera koden i din favoritkodredigerare och spara filen som NLTKsample.py:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)

Code Förklaring:
- Målet med detta program är att ta bort alla typer av interpunktion från en given text. Vi importerade "RegexpTokenizer", en modul av Nltk som tar bort alla uttryck, symboler, tecken eller numeriska värden du väljer.
- Ett reguljärt uttryck skickas till modulen ”RegexpTokenizer”.
- Texten tokeniseras med metoden ”tokenize” och utdata lagras i variabeln ”filterdText”.
- Resultatet skrivs ut med hjälp av "print()".
Steg 2) I kommandotolken:
- Navigera till den plats där du sparade filen.
- Kör kommandot
python NLTKsample.py.

Utgången är:
['Hej', 'Guru99', 'Du', 'har', 'bygga', 'en', 'väldigt', 'bra', 'plats', 'och', 'jag', 'älskar', 'besöker', 'din', 'plats']