NLTK Tokenize: Ord och meningar Tokenizer med exempel
⚡ Smart sammanfattning
NLTK Tokenize delar upp stor text i mindre enheter som kallas tokens, ett grundläggande steg i naturlig språkbehandling. Verktygslådan tillhandahåller word_tokenize för att dela upp meningar i ord och sent_tokenize för att dela upp text i enskilda meningar.

Vad är Tokenization?
tokenization är den process genom vilken en stor mängd text delas upp i mindre delar som kallas tokens. Dessa tokens är mycket användbara för att hitta mönster och anses vara ett bassteg för stemming och lemmatisering. Tokenisering hjälper också till att ersätta känsliga dataelement med icke-känsliga dataelement.
Naturlig språkbehandling används för att bygga applikationer som textklassificering, intelligent chatbot, sentimental analys, språköversättning, etc. Det blir viktigt att förstå mönstret i texten för att uppnå det ovan angivna syftet.
För närvarande, oroa dig inte för härdning och lemmatisering utan behandla dem som steg för textdatarensning med hjälp av NLP (Natural language processing). Vi kommer att diskutera härdning och lemmatisering senare i handledningen. Arbetsuppgifter som t.ex Textklassificering eller skräppostfiltrering använder sig av NLP tillsammans med djupinlärningsbibliotek som Keras och Tensorflöde.
Natural Language Toolkit har en mycket viktig modul NLTK symbolisera meningar som vidare består av undermoduler
- ord tokenisera
- meningen tokenisera
Tokenisering av ord
Vi använder metoden word_tokenize() att dela upp en mening i ord. Utdata från ordtokenisering kan konverteras till Data Frame för bättre textförståelse i maskininlärningsapplikationer. Den kan också tillhandahållas som indata för ytterligare textrensningssteg såsom borttagning av skiljetecken, borttagning av numeriska tecken eller stemming. Maskininlärningsmodeller behöver numeriska data för att tränas och göra en förutsägelse. Ordtokenisering blir en avgörande del av texten (strängen) till numerisk datakonvertering. Läs gärna om Påse med ord eller CountVectorizer. Se nedanstående ordtokenize NLTK-exempel för att förstå teorin bättre.
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
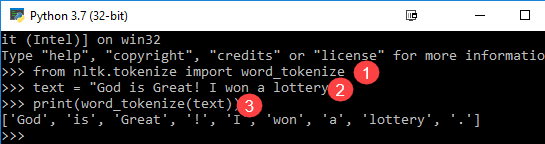
Code Förklaring
- word_tokenize-modulen importeras från NLTK-biblioteket.
- En variabel "text" initieras med två meningar.
- Textvariabel skickas i word_tokenize-modulen och skrivs ut resultatet. Denna modul bryter varje ord med skiljetecken som du kan se i utdata.
Tokenisering av meningar
Undermodulen tillgänglig för ovanstående är sent_tokenize. En uppenbar fråga i ditt sinne skulle vara varför meningstokenisering behövs när vi har möjlighet till ordtokenisering. Föreställ dig att du behöver räkna genomsnittliga ord per mening, hur kommer du att räkna? För att utföra en sådan uppgift behöver du både NLTK-satstokenizer och NLTK-ordtokenizer för att beräkna förhållandet. Sådan utdata fungerar som en viktig funktion för maskinträning eftersom svaret skulle vara numeriskt.
Kontrollera nedanstående NLTK-tokenizer-exempel för att lära dig hur meningstokenisering skiljer sig från ordtokenisering.
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
Vi har 12 ord och två meningar för samma ingång.
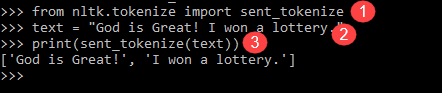
Förklaring av programmet
- I en rad som det föregående programmet, importerade modulen sent_tokenize.
- Vi har tagit samma mening. Ytterligare meningstokenizer i NLTK-modulen analyserade dessa meningar och visar utdata. Det är tydligt att denna funktion bryter varje mening.
Ovanför ordet tokenizer Python exempel är bra sättningsstenar för att förstå mekaniken i ordet och meningstokenisering.