सीमा मान विश्लेषण और समतुल्यता विभाजन
⚡ स्मार्ट सारांश
समतुल्यता विभाजन और सीमा मान विश्लेषण ब्लैक-बॉक्स परीक्षण तकनीकें हैं जो इनपुट की बड़ी श्रेणियों को समतुल्यता वर्गों में संपीड़ित करती हैं और विभाजन किनारों का परीक्षण करती हैं, जिससे वैध और अवैध इनपुट में कुशल कवरेज के साथ मजबूत दोष पहचान मिलती है।

समय और संयोजनात्मक सीमाओं के कारण व्यापक परीक्षण शायद ही कभी संभव हो पाता है। समतुल्य विभाजन और सीमा मान विश्लेषण इस समस्या को समूहीकरण द्वारा हल करते हैं।ping समान इनपुट और उनके किनारों को लक्षित करके कम मामलों के साथ बेहतर कवरेज प्राप्त करना।
समतुल्यता विभाजन क्या है?
समतुल्य विभाजन (जिसे इक्विवेलेंस क्लास पार्टीशनिंग या ईसीपी भी कहा जाता है) एक ब्लैक-बॉक्स तकनीक है जो इनपुट डेटा को समान मानों के समूहों में विभाजित करती है। परीक्षक प्रत्येक वर्ग से एक प्रतिनिधि का चयन करता है, यह मानते हुए कि सॉफ़्टवेयर प्रत्येक सदस्य के लिए समान रूप से व्यवहार करता है।
- इनपुट डोमेन को वैध और अवैध समतुल्यता वर्गों में विभाजित करता है।
- सभी पर लागू होता है परीक्षण के स्तर— इकाई, एकीकरण, प्रणाली और स्वीकृति।
सीमा मान विश्लेषण क्या है?
सीमा मूल्य विश्लेषण (बीवीए)रेंज चेकिंग भी कहलाती है, जो प्रत्येक समतुल्यता वर्ग के चरम सिरों को मान्य करती है। चूंकि दोष रेंज सीमाओं पर एकत्रित होते हैं, इसलिए बीवीए पांच प्रमुख बिंदुओं को लक्षित करता है:
- न्यूनतम
- न्यूनतम से थोड़ा ऊपर
- नाममात्र मूल्य
- अधिकतम से थोड़ा नीचे
- अधिकतम

बीवीए समतुल्यता विभाजन का पूरक है: एक बार क्लास परिभाषित हो जाने के बाद, उनके सीमा मान एक-से-एक के अंतर और किनारे की त्रुटियों को उजागर करते हैं।
समतुल्यता विभाजन और सीमा मान विश्लेषण का उपयोग क्यों करें?
जब संयोजन इतने बड़े हों कि उनका व्यापक परीक्षण करना संभव न हो, तो बुद्धिमत्तापूर्ण परीक्षण चयन आवश्यक है। ये तकनीकें तीन लाभ प्रदान करती हैं:
- बड़े टेस्ट केस वॉल्यूम को प्रबंधनीय टुकड़ों में संपीड़ित करें।
- प्रभावशीलता को प्रभावित किए बिना परीक्षण डेटा चुनने के लिए स्पष्ट नियम प्रदान करें।
- यह सूट उन गणना-प्रधान अनुप्रयोगों के लिए उपयुक्त है जिनमें कई संख्यात्मक चर होते हैं।
समतुल्यता विभाजन कैसे करें (उदाहरण)
- नीचे दिए गए ऑर्डर पिज्जा टेक्स्ट बॉक्स पर विचार करें।
- 1-10 तक की मात्राएँ मान्य हैं; सफलता का संदेश दिखाई देता है।
- मात्राएँ 11-99 अमान्य हैं, जिसके कारण समस्या उत्पन्न हो रही है। “केवल 10 पिज़्ज़ा ऑर्डर किए जा सकते हैं”.
परीक्षण की स्थितियाँ:
- 10 से अधिक कोई भी संख्या अमान्य है।
- 1 से कम कोई भी संख्या अमान्य है।
- Numbers 1–10 मान्य हैं।
- -100 जैसी कोई भी तीन अंकों की संख्या अमान्य है।
प्रत्येक मान का परीक्षण करने पर 100 से अधिक मामले सामने आते हैं। समतुल्यता विभाजन डोमेन को समान व्यवहार वाले वर्गों में समूहित करता है।
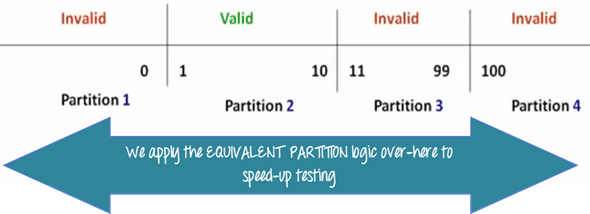
इन समूहों को कहा जाता है तुल्यता वर्गप्रत्येक वर्ग के लिए एक मान चुनें—यदि यह पास होता है, तो अन्य सभी पास हो जाते हैं; यदि यह फेल होता है, तो पूरा वर्ग फेल हो जाता है।
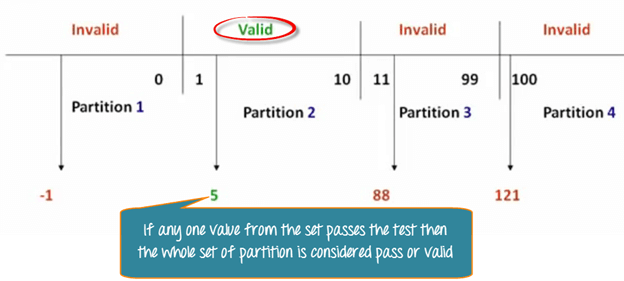
सीमा मान विश्लेषण कैसे करें (उदाहरण)
उसी पिज़्ज़ा फ़ील्ड का उपयोग करते हुए, BVA नाममात्र मूल्यों के बजाय विभाजन किनारों की जाँच करता है। परीक्षक 0, 1, 10 और 11 का मूल्यांकन करते हैं—जो वैध और अवैध सीमाओं को कवर करते हैं।
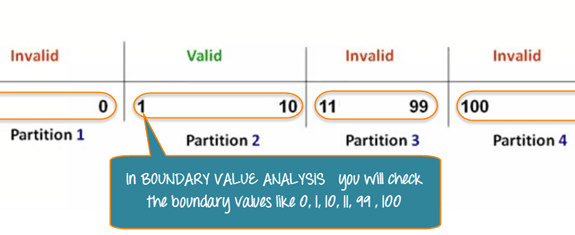
1 से 10 तक इनपुट स्वीकार करने वाले किसी इनपुट के लिए, सीमा परीक्षण मामले इस प्रकार हैं:
| परिदृश्य का परीक्षण करें Descriptआयन | अपेक्षित परिणाम |
|---|---|
| सीमा मान = 0 | सिस्टम को स्वीकार नहीं करना चाहिए |
| सीमा मान = 1 | सिस्टम को स्वीकार करना चाहिए |
| सीमा मान = 2 | सिस्टम को स्वीकार करना चाहिए |
| सीमा मान = 9 | सिस्टम को स्वीकार करना चाहिए |
| सीमा मान = 10 | सिस्टम को स्वीकार करना चाहिए |
| सीमा मान = 11 | सिस्टम को स्वीकार नहीं करना चाहिए |
समतुल्यता विभाजन बनाम सीमा मान विश्लेषण
दोनों ही परीक्षणों की संख्या कम करते हैं लेकिन उनका उद्देश्य और समय अलग-अलग होते हैं।
| पहलू | समतुल्य विभाजन | सीमा मूल्य विश्लेषण |
|---|---|---|
| फोकस | समतुल्य इनपुट के समूह | प्रत्येक समूह के किनारे |
| डेटा चयन | प्रति वर्ग एक मान | न्यूनतम, न्यूनतम के निकट, नाममात्र, अधिकतम के निकट, अधिकतम |
| के लिए सबसे अच्छा | अनावश्यक मामलों को कम करना | एक-एक की चूक को पकड़ना |
| व्यवस्था | पहले लागू किया गया | अगला आवेदन किया गया |
उदाहरण: पासवर्ड फ़ील्ड सत्यापन
एक पासवर्ड फ़ील्ड जो 6 से 10 अक्षर स्वीकार करता है, तीन विभाजन बनाता है—0-5, 6-10 और 11-14—जिनमें से प्रत्येक के भीतर समान परिणाम होते हैं।
| # | परिदृश्य का परीक्षण करें | अपेक्षित परिणाम |
|---|---|---|
| 1 | 0 से 5 अक्षर दर्ज करें | सिस्टम को स्वीकार नहीं करना चाहिए |
| 2 | 6 से 10 अक्षर दर्ज करें | सिस्टम को स्वीकार करना चाहिए |
| 3 | 11 से 14 अक्षर दर्ज करें | सिस्टम को स्वीकार नहीं करना चाहिए |
समतुल्य विभाजन और बीवीए के लिए सर्वोत्तम अभ्यास
टेस्ट की संख्या को नियंत्रित करते हुए कवरेज को मजबूत बनाए रखने के लिए इन प्रक्रियाओं का पालन करें:
- प्रत्येक डोमेन का मानचित्रण करें: सबसे पहले वैध, अवैध और विशेष परिस्थितियों वाले विभाजनों की सूची बनाएं।
- प्रत्येक सीमा के दोनों पक्षों का परीक्षण करें: एक-से-एक की त्रुटियों को पकड़ने के लिए ठीक अंदर और बाहर के मानों को शामिल करें।
- तकनीकों को मिलाएं: जटिल तर्क के लिए निर्णय तालिकाओं या स्थिति-संक्रमण परीक्षण के साथ इसका उपयोग करें।
- विशेष परिस्थितियों को स्वचालित करें: सीमा मानों को पैरामीटराइज़ करें ताकि रिग्रेशन सूट लगातार चल सकें।
चाबी छीन लेना
- समतुल्यता विभाजन समान इनपुट को समूहित करता है; प्रति वर्ग एक मान ही पर्याप्त है।
- सीमा मान विश्लेषण विभाजन सीमाओं और वैध/अवैध किनारों को मान्य करता है।
- ये दोनों ही संख्यात्मक या श्रेणी-आधारित क्षेत्रों के लिए ब्लैक-बॉक्स तकनीकें हैं।
- इन दोनों को मिलाने से दोष-पहचान की गुणवत्ता खोए बिना परीक्षण की मात्रा कम हो जाती है।
सीमा मान विश्लेषण और समतुल्यता विभाजन परीक्षण वीडियो
क्लिक करें यहाँ उत्पन्न करें यदि वीडियो उपलब्ध न हो