50 SQL-haastattelun kysymystä ja vastausta vuodelle 2026
SQL-haastattelukysymyksiä fuksilaisille
1. Mikä on DBMS?
Tietokannan hallintajärjestelmä (DBMS) on ohjelma, joka ohjaa tietokannan luomista, ylläpitoa ja käyttöä. DBMS:ää voidaan kutsua tiedostonhallinnaksi, joka hallitsee tietoja tietokannassa sen sijaan, että se tallentaa niitä tiedostojärjestelmiin.
👉 Ilmainen PDF-lataus: SQL-haastattelun kysymykset ja vastaukset >>
2. Mikä on RDBMS?
RDBMS on lyhenne sanoista Relational Database Management System. RDBMS tallentaa tiedot taulukkokokoelmaan, joka liittyy taulukon sarakkeiden välisiin yhteisiin kenttiin. Se tarjoaa myös relaatiooperaattoreita taulukoihin tallennettujen tietojen käsittelemiseksi.
Esimerkki: SQL Server.
3. Mikä on SQL?
SQL on lyhenne sanoista Structured Query Language , ja sitä käytetään kommunikoimaan tietokannan kanssa. Tämä on vakiokieli, jota käytetään suorittamaan tehtäviä, kuten tietojen hakemista, päivittämistä, lisäämistä ja poistamista tietokannasta.
Standard SQL-komennot ovat Valitse.
4. Mikä tietokanta on?
Tietokanta ei ole muuta kuin organisoitu tietomuoto, jonka avulla tietoja on helppo käyttää, tallentaa, hakea ja hallita. Tämä tunnetaan myös strukturoituna tiedon muotona, jota voidaan käyttää monin tavoin.
Esimerkki: School Management Database, Bank Management Database.
5. Mitä ovat taulukot ja kentät?
Taulukko on joukko tietoja, jotka on järjestetty malliin, jossa on sarakkeita ja rivejä. Sarakkeet voidaan luokitella pystysuoraksi, ja rivit ovat vaakasuuntaisia. Taulukossa on määritetty määrä sarakkeita, joita kutsutaan kentiksi, mutta siinä voi olla mikä tahansa määrä rivejä, joita kutsutaan tietueiksi.
Esimerkki:.
Taulukko: Työntekijä.
Kenttä: Emp ID, Emp:n nimi, syntymäaika.
Tiedot: 201456, David, 11.
6. Mikä on ensisijainen avain?
A ensisijainen avain on yhdistelmä kenttiä, jotka määrittävät rivin yksilöllisesti. Tämä on erityinen ainutlaatuinen avain, ja sillä on implisiittinen NOT NULL -rajoitus. Se tarkoittaa, että ensisijaiset avaimen arvot eivät voi olla NULL.
7. Mikä on ainutlaatuinen avain?
Ainutlaatuinen avainrajoitus tunnisti yksilöllisesti jokaisen tietueen tietokannassa. Tämä antaa sarakkeelle tai sarakejoukolle ainutlaatuisuuden.
Ensisijaisen avaimen rajoitukselle on määritetty automaattisesti yksilöllinen rajoitus. Mutta ei Unique Keyn tapauksessa.
Taulukkoa kohden voi olla useita yksilöllisiä rajoituksia, mutta taulukkoa kohden vain yksi ensisijaisen avaimen rajoitus.
8. Mikä on vieras avain?
Vieras avain on yksi taulukko, joka voidaan yhdistää toisen taulukon ensisijaiseen avaimeen. Kahden taulukon välille on luotava suhde viittaamalla vierasavain toisen taulukon ensisijaiseen avaimeen.
9. Mikä on liittyminen?
Tämä on avainsana, jolla haetaan tietoja useammista taulukoista taulukoiden kenttien välisen suhteen perusteella. Näppäimillä on tärkeä rooli, kun käytetään JOIN-koodeja.
10. Mitkä ovat liitostyypit ja selitä ne?
On erityyppisiä liitoksia jota voidaan käyttää tietojen hakemiseen ja se riippuu taulukoiden välisestä suhteesta.
- Sisäinen liitos.
Sisäinen liitos palauttaa rivit, kun taulukoiden välillä on vähintään yksi rivien yhteensopivuus.
- Oikea Liity.
Oikea liitos palauttaa rivit, jotka ovat yhteisiä taulukoiden ja oikeanpuoleisen sivutaulukon kaikkien rivien välillä. Yksinkertaisesti se palauttaa kaikki rivit oikeanpuoleisesta sivutaulukosta, vaikka vasemmassa sivutaulukossa ei ole yhtään osumaa.
- Vasen Liity.
Vasen liitos palauttaa rivit, jotka ovat yhteisiä taulukoiden ja kaikkien vasemmanpuoleisen sivutaulukon rivien välillä. Yksinkertaisesti se palauttaa kaikki rivit vasemmanpuoleisesta sivutaulukosta, vaikka oikeanpuoleisessa sivutaulukossa ei ole osumia.
- Täysi liittyminen.
Täysi liitos palauttaa rivit, kun jossakin taulukossa on vastaavia rivejä. Tämä tarkoittaa, että se palauttaa kaikki rivit vasemmasta sivutaulukosta ja kaikki rivit oikeanpuoleisesta sivutaulukosta.
SQL-haastattelukysymyksiä 3 vuoden kokemuksella
11. Mikä on normalisointi?
Normalisointi on prosessi redundanssin ja riippuvuuden minimoimiseksi järjestämällä tietokannan kenttiä ja taulukkoa. Normalisoinnin päätavoitteena on lisätä, poistaa tai muokata kenttää, joka voidaan tehdä yhteen taulukkoon.
12. Mitä denormalisointi on?
Denormalisointi on tekniikka, jolla päästään käsiksi tietokannan ylemmästä alempaan normaalimuotoon. Se on myös prosessi redundanssin lisäämiseksi taulukkoon sisällyttämällä tietoja asiaan liittyvistä taulukoista.
13. Mitä ovat kaikki erilaiset normalisoinnit?
Tietokannan normalisointi voidaan helposti ymmärtää tapaustutkimuksen avulla. Normaalimuodot voidaan jakaa kuuteen muotoon, ja ne selitetään alla -.
.png)
- Ensimmäinen normaalimuoto (1NF):.
Tämän pitäisi poistaa kaikki päällekkäiset sarakkeet taulukosta. Taulukoiden luominen asiaan liittyville tiedoille ja yksilöllisten sarakkeiden tunnistaminen.
- Toinen normaalimuoto (2NF):.
Täyttää kaikki ensimmäisen normaalimuodon vaatimukset. Tietojen osajoukkojen sijoittaminen erillisiin taulukoihin ja suhteiden luominen taulukoiden välille ensisijaisilla avaimilla.
- Kolmas normaalimuoto (3NF):.
Tämän pitäisi täyttää kaikki 2NF:n vaatimukset. Sellaisten sarakkeiden poistaminen, jotka eivät ole riippuvaisia ensisijaisen avaimen rajoituksista.
- Neljäs normaalimuoto (4NF):.
Jos mikään tietokantataulukko-ilmentymä ei sisällä kahta tai useampaa riippumatonta ja moniarvoista dataa, jotka kuvaavat relevanttia kokonaisuutta, se on 4.th Normaali muoto.
- Viides normaalimuoto (5NF):.
Taulukko on viidennessä normaalimuodossa vain, jos se on 5NF-muodossa, eikä sitä voida hajottaa useiksi pienemmiksi taulukoiksi ilman tietojen menetystä.
- Kuudes normaalimuoto (6NF):.
6th Normal Form -muotoa ei ole standardoitu, mutta tietokantaasiantuntijat keskustelevat siitä kuitenkin jonkin aikaa. Toivottavasti saamme selkeän ja standardoidun määritelmän 6. normaalimuodolle lähitulevaisuudessa…
14. Mikä on näkymä?
Näkymä on virtuaalinen taulukko, joka koostuu taulukon sisältämien tietojen osajoukosta. Näkymiä ei ole käytännössä näkyvissä, ja sen säilyttäminen vie vähemmän tilaa. Näkymässä voi olla yhdistettynä yhden tai useamman taulukon tiedot, ja se riippuu suhteesta.
15. Mikä on indeksi?
Indeksi on suorituskyvyn viritysmenetelmä, joka mahdollistaa tietueiden nopeamman hakemisen taulukosta. Indeksi luo merkinnän jokaiselle arvolle, ja tietojen hakeminen on nopeampaa.
16. Mitä ovat kaikki erityyppiset indeksit?
On olemassa kolmenlaisia indeksejä -.
- Yksittäinen indeksi.
Tämä indeksointi ei salli kentällä olla päällekkäisiä arvoja, jos sarake on yksilöllisesti indeksoitu. Ainutlaatuista indeksiä voidaan käyttää automaattisesti, kun ensisijainen avain on määritetty.
- Clustered Index.
Tämäntyyppinen indeksi järjestää uudelleen taulukon fyysisen järjestyksen ja haun avainarvojen perusteella. Jokaisessa taulukossa voi olla vain yksi klusteroitu indeksi.
- EiClustered Index.
EiClustered Index ei muuta taulukon fyysistä järjestystä ja ylläpitää tietojen loogista järjestystä. Jokaisessa taulukossa voi olla 999 klusteroimatonta indeksiä.
17. Mikä on kohdistin?
Tietokantakursori on ohjausobjekti, joka mahdollistaa taulukon rivien tai tietueiden läpikäynnin. Tätä voidaan pitää osoittimena yhteen riviin rivijoukossa. Kohdistin on erittäin hyödyllinen liikkumiseen, kuten tietokannan tietueiden hakemiseen, lisäämiseen ja poistamiseen.
18. Mikä on suhde ja mitä ne ovat?
Tietokantasuhde määritellään tietokannan taulukoiden väliseksi yhteydeksi. On olemassa erilaisia tietokantasuhteita, ja ne ovat seuraavat:.
- Yksi suhde yhteen.
- Yksi moniin -suhde.
- Monet yhteen suhde.
- Itseviittaussuhde.
19. Mikä on kysely?
DB-kysely on koodi, joka on kirjoitettu saadakseen tiedot takaisin tietokannasta. Kysely voidaan suunnitella siten, että se vastaa odotuksiamme tulosjoukosta. Yksinkertaisesti kysymys tietokantaan.
20. Mikä on alikysely?
Alikysely on toisen kyselyn sisällä oleva kysely. Ulompaa kyselyä kutsutaan pääkyselyksi ja sisäistä kyselyä kutsutaan alikyselyksi. Alikysely suoritetaan aina ensin ja alikyselyn tulos välitetään pääkyselylle.
Katsotaanpa alikyselyn syntaksia -
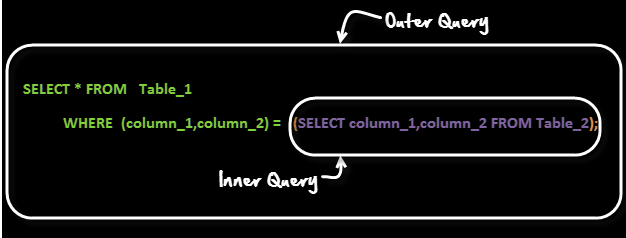
MyFlix Video Libraryn asiakkaiden yleinen valitus on elokuvien alhainen määrä. Johto haluaa ostaa elokuvia kategoriaan, jossa on vähiten nimikkeitä.
Voit käyttää kyselyä kuten
SELECT category_name FROM categories WHERE category_id =( SELECT MIN(category_id) from movies);
SQL-haastattelukysymyksiä 5 vuoden kokemuksella
21. Mitä alikyselytyyppejä on?
Alikyselyjä on kahta tyyppiä – korreloitu ja ei-korreloitu.
Korreloitua alikyselyä ei voida pitää itsenäisenä kyselynä, mutta se voi viitata pääkyselyn FROM-luettelossa olevan taulukon sarakkeeseen.
Ei-korreloitua alikyselyä voidaan pitää itsenäisenä kyselynä ja alikyselyn tulos korvataan pääkyselyssä.
22. Mikä on tallennettu menettely?
Stored Procedure on toiminto, joka koostuu useista SQL-käskyistä pääsyä tietokantajärjestelmään. Useita SQL-käskyjä on yhdistetty tallennettuun toimintosarjaan ja ne suoritetaan aina ja missä tahansa tarpeen.
23. Mikä on laukaisu?
DB-triggeri on koodi tai ohjelmat, jotka suoritetaan automaattisesti vastauksena johonkin tietokannan taulukon tai näkymän tapahtumaan. Pääasiassa laukaisu auttaa ylläpitämään tietokannan eheyttä.
Esimerkki: Kun uusi opiskelija lisätään opiskelijatietokantaan, uudet tietueet tulee luoda vastaaviin taulukoihin, kuten Tentti-, Pisteet- ja Läsnäolotaulukoihin.
24. Mitä eroa on DELETE- ja TRUNCATE-komennoilla?
DELETE-komentoa käytetään rivien poistamiseen taulukosta, ja WHERE-lausetta voidaan käyttää ehdollisten parametrien joukkoon. Commit ja Rollback voidaan suorittaa poistolausekkeen jälkeen.
TRUNCATE poistaa kaikki rivit taulukosta. Katkaisutoimintoa ei voi peruuttaa.
25. Mitä ovat paikalliset ja globaalit muuttujat ja niiden erot?
Paikalliset muuttujat ovat muuttujia, joita voidaan käyttää tai joita voidaan käyttää funktion sisällä. Muut funktiot eivät tunne niitä, eikä niihin voi viitata tai niitä ei voida käyttää. Muuttujia voidaan luoda aina, kun kyseistä funktiota kutsutaan.
Globaalit muuttujat ovat muuttujia, joita voidaan käyttää tai joita voidaan käyttää koko ohjelman aikana. Samaa globalissa ilmoitettua muuttujaa ei voida käyttää funktioissa. Yleisiä muuttujia ei voida luoda aina, kun kyseistä funktiota kutsutaan.
26. Mikä on rajoitus?
Rajoitusta voidaan käyttää taulukon tietotyypin rajan määrittämiseen. Rajoitus voidaan määrittää luotaessa tai muuttaessa taulukkolauseketta. Esimerkkejä rajoituksista ovat.
- EI TYHJÄ.
- TARKISTAA.
- OLETUS.
- SINGLE.
- PÄÄAVAIN.
- ULKOINEN AVAIN.
27. Mitä data on Integrity?
Päiväys Integrity määrittää tietokantaan tallennettujen tietojen tarkkuuden ja johdonmukaisuuden. Se voi myös määrittää eheysrajoituksia, jotka koskevat liiketoimintasääntöjen noudattamista, kun tiedot syötetään sovellukseen tai tietokantaan.
28. Mikä on automaattinen lisäys?
Automaattisen lisäyksen avainsana antaa käyttäjälle mahdollisuuden luoda yksilöllisen numeron, joka luodaan, kun uusi tietue lisätään taulukkoon. AUTO INCREMENT-avainsanaa voidaan käyttää Oracle ja IDENTITY-avainsanaa voidaan käyttää SQL SERVERissä.
Useimmiten tätä avainsanaa voidaan käyttää aina, kun PRIMARY KEY on käytössä.
29. Mitä eroa on Cluster ja eiCluster Indeksi?
Clustered-indeksiä käytetään tietojen helppoon hakemiseen tietokannasta muuttamalla tapaa, jolla tietueet tallennetaan. Tietokanta lajittelee rivit sen sarakkeen mukaan, joka on asetettu klusteroiduksi indeksiksi.
Klusteroitumaton indeksi ei muuta tapaa, jolla se on tallennettu, vaan luo täydellisen erillisen objektin taulukkoon. Se osoittaa takaisin alkuperäisille taulukon riveille haun jälkeen.
30. Mikä on Datawarehouse?
Datawarehouse on useiden tietolähteiden tietojen keskusvarasto. Nämä tiedot yhdistetään, muunnetaan ja asetetaan saataville louhintaa ja online-käsittelyä varten. Varastotiedoissa on osajoukko dataa nimeltä Data Marts.
31. Mikä on Self-Join?
Itseliittyminen on asetettu kyselyksi, jota käytetään vertaamaan itseensä. Tätä käytetään vertaamaan sarakkeen arvoja muihin saman sarakkeen arvoihin samassa taulukossa. ALIAS ES:tä voidaan käyttää samaan taulukkovertailuun.
32. Mikä Cross-Join on?
Ristiliitos määritellään suorakulmaiseksi tuloksi, jossa ensimmäisen taulukon rivien määrä kerrottuna toisen taulukon rivien määrällä. Jos oletetaan, että WHERE-lausetta käytetään ristiliitossa, kysely toimii kuten INNER JOIN.
33. Mitä ovat käyttäjän määrittämät funktiot?
Käyttäjän määrittämät funktiot ovat toimintoja, jotka on kirjoitettu käyttämään tätä logiikkaa aina tarvittaessa. Samaa logiikkaa ei tarvitse kirjoittaa useita kertoja. Sen sijaan toimintoa voidaan kutsua tai suorittaa aina tarvittaessa.
34. Mitä ovat kaikki käyttäjän määrittämät funktiot?
Käyttäjän määrittämiä toimintoja on kolmenlaisia.
- Skalaarifunktiot.
- Inline-taulukon arvoiset funktiot.
- Monen lauseen arvoiset funktiot.
Skalaaripalautusyksikkö, variantti määritteli paluulausekkeen. Kahden muun tyypin palautustaulukko palautuksena.
35. Mitä on lajittelu?
Lajittelu määritellään säännöiksi, jotka määrittävät, kuinka merkkitietoja voidaan lajitella ja verrata. Tätä voidaan käyttää A- ja muiden kielten merkkien vertailuun, ja se riippuu myös merkkien leveydestä.
ASCII-arvoa voidaan käyttää näiden merkkitietojen vertailuun.
36. Mitä kaikki lajitteluherkkyystyypit ovat?
Seuraavassa on erilaisia lajitteluherkkyystyyppejä -.
- Kirjainherkkyys – A ja a ja B ja b.
- Aksenttiherkkyys.
- Kanan herkkyys – japanilaiset kanahahmot.
- Leveysherkkyys – Yksitavuinen ja kaksitavuinen merkki.
37. Tallennetun menetelmän edut ja haitat?
Tallennettua menettelyä voidaan käyttää modulaarisena ohjelmointina – tarkoittaa, että luo kerran, tallenna ja soita useita kertoja aina tarvittaessa. Tämä tukee nopeampaa suoritusta useiden kyselyjen suorittamisen sijaan. Tämä vähentää verkkoliikennettä ja parantaa tietoturvaa.
Haittapuolena on, että se voidaan suorittaa vain tietokannassa ja käyttää enemmän muistia tietokantapalvelimessa.
38. Mitä on online-tapahtumien käsittely (OLTP)?
Online Transaction Processing (OLTP) hallitsee tapahtumapohjaisia sovelluksia, joita voidaan käyttää tietojen syöttämiseen, tiedonhakuun ja tietojenkäsittelyyn. OLTP tekee tiedonhallinnasta yksinkertaista ja tehokasta. Toisin kuin OLAP-järjestelmät, OLTP-järjestelmien tavoitteena on palvella reaaliaikaisia tapahtumia.
Esimerkki – Pankkitapahtumat päivittäin.
39. Mikä on CLAUSE?
SQL-lauseke on määritelty rajoittamaan tulosjoukkoa tarjoamalla kyselylle ehto. Tämä yleensä suodattaa joitakin rivejä koko tietuejoukosta.
Esimerkki – Kysely, jolla on WHERE-ehto
Kysely, jonka ehto on HAVING.
40. Mikä on rekursiivinen tallennettu proseduuri?
Tallennettu proseduuri, joka kutsuu itsestään, kunnes se saavuttaa jonkin rajaehdon. Tämä rekursiivinen toiminto tai menettely auttaa ohjelmoijia käyttämään samaa koodisarjaa kuinka monta kertaa tahansa.
SQL-haastattelukysymyksiä yli 10 vuoden kokemuksella
41. Mitä ovat Union-, miinus- ja Interact-komennot?
UNION-operaattorilla yhdistetään kahden taulukon tulokset, ja se eliminoi taulukoista päällekkäiset rivit.
MIINUS-operaattoria käytetään palauttamaan rivejä ensimmäisestä kyselystä, mutta ei toisesta kyselystä. Ensimmäisen ja toisen kyselyn vastaavat tietueet ja muut ensimmäisen kyselyn rivit näytetään tulosjoukona.
INTERSECT-operaattoria käytetään palauttamaan molempien kyselyjen palauttamat rivit.
42. Mikä on ALIAS-komento?
ALIAS-nimi voidaan antaa taulukolle tai sarakkeelle. Tähän aliaksen nimeen voidaan viitata WHERE-lauseke tunnistaaksesi taulukon tai sarakkeen.
Esimerkki-.
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
Tässä st viittaa opiskelijataulukon aliaksen nimeen ja Ex viittaa koetaulukon aliaksen nimeen.
43. Mitä eroa on TRUNCATE- ja DROP-lauseiden välillä?
TRUNCATE poistaa kaikki rivit taulukosta, eikä sitä voi rullata taaksepäin. DROP-komento poistaa taulukon tietokannasta, eikä toimintoa voi peruuttaa.
44. Mitä ovat aggregaatti- ja skalaarifunktiot?
Aggregaattifunktioita käytetään matemaattisten laskelmien arvioimiseen ja yksittäisten arvojen palauttamiseen. Tämä voidaan laskea taulukon sarakkeista. Skalaarifunktiot palauttavat yhden arvon syötetyn arvon perusteella.
Esimerkki -.
Aggregate – max(), count – Laskettu suhteessa numeeriseen.
Skalaari – UCASE(), NOW() – Laskettu merkkijonojen suhteen.
45. Kuinka voit luoda tyhjän taulukon olemassa olevasta taulukosta?
Esimerkki on -.
Select * into studentcopy from student where 1=2
Tässä kopioimme opiskelijataulukon toiseen taulukkoon, jolla on sama rakenne ilman kopioituja rivejä.
46. Miten noudetaan yhteiset tietueet kahdesta taulukosta?
Yhteinen ennätystulos voidaan saavuttaa -.
Select studentID from student INTERSECT Select StudentID from Exam
47. Kuinka noutaa vaihtoehtoisia tietueita taulukosta?
Tietueita voidaan hakea sekä parittomille että parillisille rivinumeroille -.
Parillisten lukujen näyttäminen -.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
Parittomien lukujen näyttäminen -.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
from (Valitse rowno, opiskelijatunnus opiskelijalta), jossa mod(rowno,2)=1.[/sql]
48. Kuinka valita yksilöllisiä tietueita taulukosta?
Valitse yksilölliset tietueet taulukosta käyttämällä DISTINCT-avainsanaa.
Select DISTINCT StudentID, StudentName from Student.
49. Millä komennolla haetaan merkkijonon 5 ensimmäistä merkkiä?
On monia tapoja hakea merkkijonon 5 ensimmäistä merkkiä -.
Select SUBSTRING(StudentName,1,5) as studentname from student
Select LEFT(Studentname,5) as studentname from student
50. Mitä operaattoria käytetään kyselyssä kuvioiden yhteensovittamiseen?
LIKE-operaattoria käytetään kuvioiden sovittamiseen, ja sitä voidaan käyttää muodossa -.
- % – Vastaa nollaa tai useampaa merkkiä.
- _(Alleviiva) – Vastaa täsmälleen yhtä merkkiä.
Esimerkki -.
Select * from Student where studentname like 'a%'
Select * from Student where studentname like 'ami_'
Nämä haastattelukysymykset auttavat myös vivassasi (suullinen)