Pearsonin ja Spearmanin korrelaatiomatriisi R:ssä esimerkin kanssa
⚡ Älykäs yhteenveto
Pearsonin ja Spearmanin korrelaatio R:ssä mittaa kahden muuttujan yhdessä liikkumisen voimakkuutta käyttämällä cor()-funktiota yhdelle muuttujaparille ja korrelaatiomatriisia monille. Tämä läpikäynti lisää merkitsevyystestauksen Hmisc:llä ja visualisoi tuloksen GGally-lämpökartoilla.

Kaksimuuttujakorrelaatio R:ssä
Kaksimuuttujasuhde kuvaa R:n kahden muuttujan välistä suhdetta tai korrelaatiota. Tässä opetusohjelmassa käsittelemme korrelaation käsitettä ja näytämme, kuinka sitä voidaan käyttää mittaamaan minkä tahansa kahden muuttujan välistä suhdetta R:ssä.
Korrelaatio R-ohjelmoinnissa
R-ohjelmoinnin kahden muuttujan välisen korrelaation laskemiseksi on kaksi ensisijaista menetelmää:
- Pearson: Parametrinen korrelaatio
- Spearman: Ei-parametrinen korrelaatio
Pearson-korrelaatiomatriisi kirjassa R
Pearson-korrelaatiomenetelmää käytetään yleensä ensisijaisena tarkistuksena kahden muuttujan väliselle suhteelle.
korrelaatiokerroin, kirjoitettuna r:llä, mittaa voimakkuutta lineaarinen kahden muuttujan x ja y välinen suhde. Se lasketaan seuraavasti:
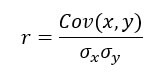
 on x:n keskihajonta
on x:n keskihajonta on y:n keskihajonta
on y:n keskihajonta
Korrelaatio vaihtelee välillä -1 ja 1.
- Jos r on lähellä nollaa tai yhtä suuri kuin nolla, x:n ja y:n välillä on vain vähän tai ei lainkaan lineaarista suhdetta.
- Mitä lähempänä r on arvoa 1 tai -1, sitä vahvempi lineaarinen suhde on.
Voit testata, eroaako r nollasta, alla olevalla t-tilastolla vertaamalla sitä Studentin jakaumaan, jonka vapausasteet ovat n – 2:
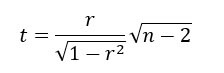
Spearman Rankkorrelaatio R:ssä
Arvokorrelaatio lajittelee havainnot arvon mukaan ja laskee arvon samankaltaisuuden tason. Arvokorrelaatiolla on se etu, että se on robusti poikkeaville havainnoille eikä se ole sidoksissa datan jakaumaan. Arvokorrelaatio on myös oikea valinta ordinaalimuuttujille.
Spearmanin järjestyskorrelaatio, jota merkitään rho:lla, ulottuu myös välille -1–1, ja jommankumman ääripään lähellä olevat arvot osoittavat vahvaa monotonista suhdetta. Se lasketaan seuraavasti:
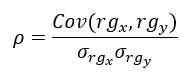
Osoittaja on x:n ja y:n aarteiden välinen kovarianssi ja nimittäjä on niiden keskihajontojen tulo.
R:ssä molemmat lasketaan cor()-funktiolla, joka ottaa vastaan kolme argumenttia: x, y ja metodin.
cor(x, y, method)
argumentit:
- x: Ensimmäinen vektori
- y: Toinen vektori
- menetelmä: Korrelaation laskemiseen käytetty kaava. Kolme merkkijonoarvoa:
- "Pearson"
- "kendall"
- "keihäsmies"
Valinnainen argumentti voidaan lisätä, jos vektoreista puuttuu arvo: use = “complete.obs”
Käytämme BudgetUK-tietoaineistoa. Tämä tietojoukko raportoi brittiläisten kotitalouksien budjetin jakautumisesta vuosina 1980-1982. Havaintoja on 1519, joissa on kymmenen ominaisuutta, muun muassa:
- wfood: jaa ruokaa jaa kulutusta
- wpolttoaine: jaa polttoainekulutus
- wc-kangas: budjettiosuus vaatteisiin
- Walc: jaa alkoholikulutus
- wtrans: jaa kuljetuskulut
- vaimo: osuus muista tavaroista
- totexp: kotitalouden kokonaiskulut punnissa
- tulo: kotitalouden nettotulot yhteensä
- ikä: kotitalouden ikä
- lapset: lasten määrä
esimerkki
library(dplyr) PATH <- "https://raw.githubusercontent.com/guru99-edu/R-Programming/master/british_household.csv" data <- read.csv(PATH) %>% filter(income < 500) %>% mutate(log_income = log(income), log_totexp = log(totexp), children_fac = factor(children, order = TRUE, labels = c("No", "Yes"))) %>% select(-c(X, X.1, children, totexp, income)) glimpse(data)
Code Selitys
- Tuomme ensin tiedot ja tarkastelemme glimpse()-funktiota dplyr-kirjastosta.
- Kolme kotitaloutta ilmoittaa tuloiksi 500 tai enemmän, joten filter(tulot < 500) poistaa ne ja rivien määrä putoaa 1 519:stä 1 516:een.
- On yleinen käytäntö muuntaa rahamuuttuja logissa. Se auttaa vähentämään poikkeamien vaikutusta ja vähentämään tietojoukon vinoutta.
lähtö:
## Observations: 1,516 ## Variables: 10 ## $ wfood <dbl> 0.4272, 0.3739, 0.1941, 0.4438, 0.3331, 0.3752, 0... ## $ wfuel <dbl> 0.1342, 0.1686, 0.4056, 0.1258, 0.0824, 0.0481, 0... ## $ wcloth <dbl> 0.0000, 0.0091, 0.0012, 0.0539, 0.0399, 0.1170, 0... ## $ walc <dbl> 0.0106, 0.0825, 0.0513, 0.0397, 0.1571, 0.0210, 0... ## $ wtrans <dbl> 0.1458, 0.1215, 0.2063, 0.0652, 0.2403, 0.0955, 0... ## $ wother <dbl> 0.2822, 0.2444, 0.1415, 0.2716, 0.1473, 0.3431, 0... ## $ age <int> 25, 39, 47, 33, 31, 24, 46, 25, 30, 41, 48, 24, 2... ## $ log_income <dbl> 4.867534, 5.010635, 5.438079, 4.605170, 4.605170,... ## $ log_totexp <dbl> 3.912023, 4.499810, 5.192957, 4.382027, 4.499810,... ## $ children_fac <ord> Yes, Yes, Yes, Yes, No, No, No, No, No, No, Yes, ...
Voimme laskea korrelaatiokertoimen tulo- ja wfood-muuttujien välillä "pearson" ja "spearman" menetelmillä.
cor(data$log_income, data$wfood, method = "pearson")
lähtö:
## [1] -0.2466986
cor(data$log_income, data$wfood, method = "spearman")
lähtö:
## [1] -0.2501252
Ennen kuin tätä laajennetaan koskemaan jokaista muuttujaparia, kannattaa tarkistaa, miten yksittäinen kerroin tulisi lukea.
Korrelaatiokertoimen tulkitseminen
Kertoimesta on hyötyä vasta, kun tiedät, mitä se tarkoittaa. Alla olevat vyöhykkeet ovat tavanomaisia lukemia, ja etumerkki luetaan erillään voimakkuudesta.
| r:n absoluuttinen arvo | Suhteen vahvuus |
|---|---|
| 0.00 ja 0.19 | Hyvin heikko tai ei lainkaan |
| 0.20 ja 0.39 | Heikko |
| 0.40 ja 0.59 | Kohtalainen |
| 0.60 ja 0.79 | Vahva |
| 0.80 ja 1.00 | Erittäin vahva |
Aiemmin laskettu log_income- ja wfood-muuttujien välinen arvo -0.2467 on siis heikko negatiivinen suhde: rikkaammat kotitaloudet käyttävät hieman pienemmän osan budjetistaan ruokaan.
Jokaiseen kertoimeen sovelletaan kolmea varoitusta.
- Korrelaatio ei ole syy-yhteyttä. Vahva r-arvo tarkoittaa, että kaksi muuttujaa liikkuvat yhdessä, eikä koskaan sitä, että toinen aiheuttaa toisen. Kolmas, mittaamaton muuttuja usein ohjaa molempia.
- Pearson näkee vain suoria viivoja. Täydellinen U-muotoinen relaatio palauttaa r:n, joka on lähellä nollaa. Piirrä aina data ennen kuin luotat lukuun.
- Koko on tärkeämpää kuin merkitys. 1 516 havainnolla kerroin 0.06 voi olla tilastollisesti merkitsevä ja silti käytännössä merkityksetön.
Korrelaatiomerkittävyyden testaaminen cor.test()-funktiolla
cor() palauttaa kertoimen eikä mitään muuta. Yhden parin kohdalla cor.test() lisää p-arvon ja luottamusvälin yhdellä kutsulla.
cor.test(data$log_income, data$wfood, method = "pearson")
Tulosteessa on neljä lukemisen arvoista osaa.
- t ja df: testisuure ja sen vapausasteet, n – 2.
- p-arvo: todennäköisyys nähdä näin suuri kerroin, jos todellinen korrelaatio olisi nolla.
- 95 prosentin luottamusväli: todellisen korrelaation uskottava vaihteluväli. Jos se sulkee pois nollan, suhde on merkitsevä kyseisellä tasolla.
- näytearvio: kerroin itse, identtinen cor()-funktion palauttaman kanssa.
Sama funktio suorittaa rank-pohjaiset testit muuttamalla yhtä argumenttia:
# Spearman rank correlation with a p-value cor.test(data$log_income, data$wfood, method = "spearman") # One-sided test: is the correlation greater than zero? cor.test(data$log_income, data$wfood, alternative = "greater")
Milloin kumpaa käyttää. Käytä cor.test()-funktiota, kun tutkit yhtä tiettyä paria, koska se antaa luottamusvälin, jonka rcorr() jättää pois. Käytä yllä esitettyä Hmisc:n rcorr()-funktiota, kun tarvitset p-arvot koko matriisille kerralla. Huomaa, että useiden parien testaaminen kasvattaa väärien positiivisten tulosten määrää, joten säädä p-arvoja p.adjust(p_value, method = “BH”) -funktiolla ennen kuin teet johtopäätöksiä suuresta matriisista.
Korrelaatiomatriisi kirjassa R
Kaksimuuttujainen korrelaatio on hyvä lähtökohta, mutta monimuuttujainen tarkastelu antaa laajemman kuvan. korrelaatiomatriisi on neliönmuotoinen taulukko, joka sisältää jokaisen muuttujan parittaisen korrelaation kaikkia muita muuttujia vastaan.
Cor()-funktio palauttaa korrelaatiomatriisin. Ainoa ero kaksimuuttujakorrelaatioon on, että meidän ei tarvitse määrittää, mitä muuttujia. Oletusarvoisesti R laskee korrelaation kaikkien muuttujien välillä.
Korrelaatiota ei voida laskea tekijälle, joten poista jokainen kategorinen sarake ennen datakehyksen välittämistä cor()-funktiolle.
Korrelaatiomatriisi on symmetrinen, mikä tarkoittaa, että diagonaalin yläpuolella olevilla arvoilla on samat arvot kuin alla. On visuaalisempaa näyttää puolet matriisista.
children_fac on suljettu pois, koska cor() ei voi käsitellä tekijää.
# the last column of data is a factor level. We don't include it in the code mat_1 <-as.dist(round(cor(data[,1:9]),2)) mat_1
Code Selitys
- cor(tiedot[, 1:9])Laske korrelaatiomatriisi yhdeksälle numeeriselle sarakkeelle
- pyöreä(…, 2)Pyöristä jokainen kerroin kahden desimaalin tarkkuudelle
- as.dist()Tulosta vain alempi kolmio, koska matriisi on symmetrinen
lähtö:
## wfood wfuel wcloth walc wtrans wother age log_income ## wfuel 0.11 ## wcloth -0.33 -0.25 ## walc -0.12 -0.13 -0.09 ## wtrans -0.34 -0.16 -0.19 -0.22 ## wother -0.35 -0.14 -0.22 -0.12 -0.29 ## age 0.02 -0.05 0.04 -0.14 0.03 0.02 ## log_income -0.25 -0.12 0.10 0.04 0.06 0.13 0.23 ## log_totexp -0.50 -0.36 0.34 0.12 0.15 0.15 0.21 0.49
Merkitsevyystaso
Kerroin yksinään ei kerro, onko suhde tilastollisesti luotettava. Hmisc-kirjaston rcorr()-funktio palauttaa p-arvon jokaiselle parille. Voimme ladata kirjaston osoitteesta Conda ja kopioi koodi liittääksesi sen terminaaliin:
conda install -c r r-hmisc
rcorr() vaatii datakehyksen tallentamisen matriisina. Voimme muuntaa tietomme matriisiksi ennen kuin laskemme korrelaatiomatriisin p-arvon kanssa.
library("Hmisc") data_rcorr <-as.matrix(data[, 1: 9]) mat_2 <-rcorr(data_rcorr) # mat_2 <-rcorr(as.matrix(data)) returns the same output
Listaobjekti mat_2 sisältää kolme elementtiä:
- r: Korrelaatiomatriisin tulos
- n: Havainnon määrä
- P: p-arvo
Olemme kiinnostuneita kolmannesta elementistä, p-arvosta. On yleistä näyttää korrelaatiomatriisi p-arvon kanssa korrelaatiokertoimen sijaan.
p_value <-round(mat_2[["P"]], 3) p_value
Code Selitys
- mat_2[["P"]]: P-arvot tallennetaan elementtiin nimeltä P
- pyöreä(matto_2[["P"]], 3): Pyöristä elementit kolmella numerolla
lähtö:
wfood wfuel wcloth walc wtrans wother age log_income log_totexp wfood NA 0.000 0.000 0.000 0.000 0.000 0.365 0.000 0 wfuel 0.000 NA 0.000 0.000 0.000 0.000 0.076 0.000 0 wcloth 0.000 0.000 NA 0.001 0.000 0.000 0.160 0.000 0 walc 0.000 0.000 0.001 NA 0.000 0.000 0.000 0.105 0 wtrans 0.000 0.000 0.000 0.000 NA 0.000 0.259 0.020 0 wother 0.000 0.000 0.000 0.000 0.000 NA 0.355 0.000 0 age 0.365 0.076 0.160 0.000 0.259 0.355 NA 0.000 0 log_income 0.000 0.000 0.000 0.105 0.020 0.000 0.000 NA 0 log_totexp 0.000 0.000 0.000 0.000 0.000 0.000 0.000 0.000 NA
Korrelaatiomatriisin visualisointi R:ssä
Lämpökartta on toinen tapa lukea korrelaatiomatriisia. GGally-kirjasto laajentaa ggplot2:ta ja asennetaan CRANista condan sijaan:
install.packages("GGally")

Kirjasto sisältää erilaisia toimintoja yhteenvetotilastojen näyttämiseksi, kuten kaikkien muuttujien korrelaation ja jakautumisen matriisi.
Funktiolla ggcorr() on paljon argumentteja. Esittelemme vain ne argumentit, joita käytämme opetusohjelmassa:
ggcorr-funktio
ggcorr(df, method = c("pairwise", "pearson"), nbreaks = NULL, digits = 2, low = "#3B9AB2", mid = "#EEEEEE", high = "#F21A00", geom = "tile", label = FALSE, label_alpha = FALSE)
argumentit:
- df: Tietojoukko käytetty
- menetelmä: Kaava korrelaation laskemiseksi. Oletusarvoisesti pari ja Pearson lasketaan
- nbreaks: Palauttaa kertoimien värityksen kategorisen alueen. Oletusarvoisesti ei taukoa ja värigradientti on jatkuva
- numeroa: Pyöristä korrelaatiokerroin. Oletusarvona on 2
- matala: Säädä värityksen alempaa tasoa
- keski-: Säädä värityksen keskitasoa
- korkea: Säädä värin korkeaa tasoa
- geom: Hallitse geometrisen argumentin muotoa. Oletuksena "laatta"
- etiketti: Boolen arvo. Näytä tarra tai älä. Oletusarvona on FALSE
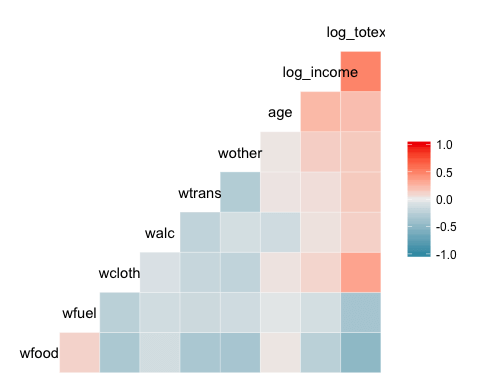
Perus lämpökartta
Paketin yksinkertaisin juoni on lämpökartta. Kaavion selite näyttää gradientin värin välillä – 1:stä 1:een, kuuma väri osoittaa vahvaa positiivista korrelaatiota ja kylmä väri, negatiivinen korrelaatio.
library(GGally) ggcorr(data)
Code Selitys
- ggcorr(data): Tarvitaan vain yksi argumentti, joka on tietokehyksen nimi. Tekijätason muuttujat eivät sisälly kuvaajaan.
lähtö:
Ohjauksen lisääminen lämpökarttaan
Voimme lisätä kaavioon lisää säätimiä:
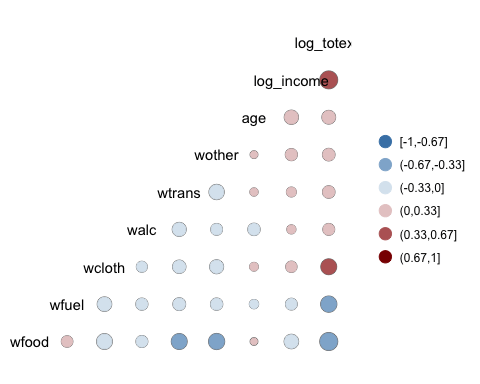
ggcorr(data, nbreaks = 6, low = "steelblue", mid = "white", high = "darkred", geom = "circle")
Code Selitys
- nbreaks=6: murtaa legenda 6 riveillä.
- matala = "teräksensininen": Käytä vaaleampia värejä negatiiviseen korrelaatioon
- keski = "valkoinen": Käytä valkoisia värejä keskialueen korrelaatioon
- korkea = "tumma": Käytä tummia värejä positiiviseen korrelaatioon
- geom = "ympyrä": Käytä lämpökartan ikkunoiden muotoina ympyrää. Ympyrän koko on verrannollinen korrelaation itseisarvoon.
lähtö:
Tarran lisääminen lämpökarttaan
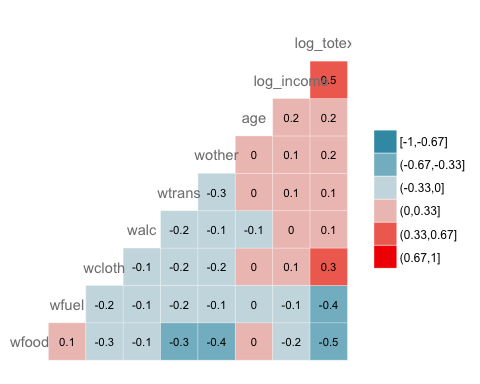
GGally antaa meille mahdollisuuden lisätä tarran ikkunoiden sisään:
ggcorr(data, nbreaks = 6, label = TRUE, label_size = 3, color = "grey50")
Code Selitys
- etiketti = TOSI: Lisää lämpökartan sisällä olevien korrelaatiokertoimien arvot.
- väri = "grey50": Valitse väri, eli harmaa
- etiketin_koko = 3: Aseta tarran kooksi 3
lähtö:
ggpairs-funktio
GGally-kirjasto tarjoaa myös ggpairs()-funktion, joka palauttaa kuvaajamatriisin. K valitulla muuttujalla tulos on ak kertaa k ruudukko: lävistäjä näyttää kunkin muuttujan jakauman, kun taas lävistäjän ylä- ja alapuolella olevat paneelit voivat kukin suorittaa eri laskennan. Syntaksi on:
ggpairs(df, columns = 1:ncol(df), title = NULL, upper = list(continuous = "cor"), lower = list(continuous = "smooth"), mapping = NULL)
argumentit:
- df: Tietojoukko käytetty
- sarakkeet: Piirrä kaavio valitsemalla sarakkeet
- otsikko: Sisällytä otsikko
- ylempi: Ohjaa kuvaajan lävistäjän yläpuolella olevia laatikoita. Sinun on annettava palautettavien laskutoimitusten tai kuvaajan tyyppi. Jos jatkuva = ”korrelaatio”, pyydämme R:ää laskemaan korrelaation. Huomaa, että argumentin on oltava lista. Muita argumentteja on saatavilla; katso GGally-dokumentaatio lisätietoja.
- alentaa: Ohjaa diagonaalin alla olevia ruutuja.
- karttaping: Ilmaisee kaavion esteettisyyden. Voimme esimerkiksi laskea kaavion eri ryhmille.
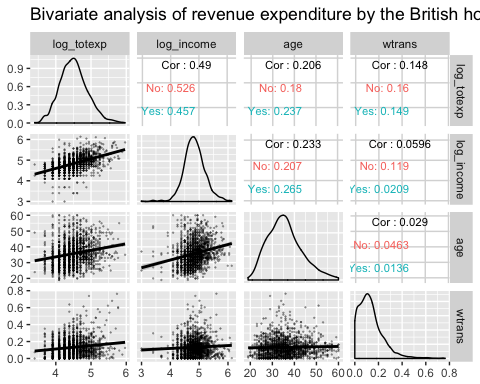
Kaksimuuttuja-analyysi gg-pairilla ryhmien kanssaping
Seuraavassa kaaviossa on kolme tietoa:
- Korrelaatiomatriisi log_totexp-, log_income-, age- ja wtrans-muuttujien välillä ryhmiteltynä sen mukaan, onko taloudessa lapsi vai ei.
- Piirrä kunkin muuttujan jakauma ryhmittäin
- Näytä hajontakaavio trendin kanssa ryhmittäin
library(ggplot2) ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor", size = 3)), lower = list(continuous = wrap("smooth", alpha = 0.3, size = 0.1)), mapping = aes(color = children_fac))
Code Selitys
- sarakkeet = c("log_totexp", "log_income", "age", "wtrans"): Valitse kaaviossa näytettävät muuttujat
- otsikko = "Britannian kotitalouden tulomenojen kaksimuuttujaanalyysi": Lisää otsikko
- ylempi = lista(): Ohjaa kaavion yläosaa. Eli diagonaalin yläpuolella
- jatkuva = kääri ("cor", koko = 3)): Laske korrelaatiokerroin. Käärimme argumentin jatkuvana wrap()-funktion sisällä hallitaksemme graafin esteettisyyttä (eli koko = 3) -lower = list(): Ohjaa kaavion alaosaa. Eli diagonaalin alapuolella.
- jatkuva = kääri ("sileä", alfa = 0.3, koko = 0.1): Lisää sirontakaavio lineaarisella trendillä. Käärimme argumentin jatkuvana wrap()-funktion sisällä hallitaksemme graafin esteettisyyttä (eli koko=0.1, alpha=0.3)
- karttaping = aes(väri = lasten_fakta)Jaa jokainen paneeli children_fac-tekijän mukaan, jossa järjestetty tekijä on merkitty ”Ei” lapsettomille kotitalouksille ja ”Kyllä” lapsiperheille.
lähtö:

Kaksimuuttuja-analyysi gg-parilla osittaisella ryhmälläping
Alla oleva kaavio on hieman erilainen. Muutamme kartan sijaintia.ping ylemmän argumentin sisällä.
ggpairs(data, columns = c("log_totexp", "log_income", "age", "wtrans"), title = "Bivariate analysis of revenue expenditure by the British household", upper = list(continuous = wrap("cor", size = 3), mapping = aes(color = children_fac)), lower = list( continuous = wrap("smooth", alpha = 0.3, size = 0.1)) )
Code Selitys
- Täsmälleen sama koodi kuin edellinen esimerkki paitsi:
- karttaping = aes(color = children_fac): Siirrä listaa yläosassa = list(). Haluamme laskennan olevan pinottu ryhmittäin vain graafin yläosaan.
lähtö:
Korrelaatio R:ssä: Keskeiset tiedot ja funktioiden viite
- Kaksimuuttujasuhde kuvaa suhdetta - tai korrelaatiota - kahden R:n muuttujan välillä.
- On olemassa kaksi ensisijaista menetelmää kahden muuttujan välisen korrelaation laskemiseksi R-ohjelmointi: Pearson & Spearman.
- Pearson-korrelaatiomenetelmää käytetään yleensä ensisijaisena tarkistuksena kahden muuttujan väliselle suhteelle.
- Sijoituskorrelaatio lajittelee havainnot arvon mukaan ja laskee arvon samankaltaisuuden tason.
- Spearmanin järjestyskorrelaatio on välillä -1 - 1, ja lähellä jompaakumpaa ääripäätä olevat arvot osoittavat vahvaa monotonista suhdetta.
- Korrelaatiomatriisi on neliömäinen taulukko, joka sisältää jokaisen muuttujan parittaisen korrelaation.
- P-arvo kertoo, onko havaittu korrelaatio tilastollisesti erotettavissa nollasta.
Jokainen tässä opetusohjelmassa käytetty korrelaatiofunktio on lueteltu alla:
| Kirjasto | Tavoite | Menetelmä | Code |
|---|---|---|---|
| pohja | Kaksimuuttujainen korrelaatio | Pearson |
cor(dfx2, method = "pearson") |
| pohja | Kaksimuuttujainen korrelaatio | Spearman |
cor(dfx2, method = "spearman") |
| pohja | Monimuuttujakorrelaatio | Pearson |
cor(df, method = "pearson") |
| pohja | Monimuuttujakorrelaatio | Spearman |
cor(df, method = "spearman") |
| Hmisc | P-arvo | - |
rcorr(as.matrix(data[,1:9]))[["P"]] |
| GGally | Lämpökartta | - |
ggcorr(df)
|
| GGally | Monimuuttujakuvaajamatriisi | - |
ggpairs(df, columns = c("x1", "x2")) |