Tutorial do DataStage para iniciantes: IBM Ferramenta ETL
⚡ Resumo Inteligente
DataStage de IBM InfoSphere extracO DB2 processa, transforma e carrega dados corporativos em grande escala. Esta página explica a arquitetura, os componentes, o processamento paralelo, a configuração da replicação SQL, a criação de projetos, a compilação de tarefas e os testes de integração usando um exemplo prático de varejo com o DB2.

O que é DataStage?
DataStage é uma ferramenta ETL usada para extracO DataStage processa, transforma e carrega dados da origem para o destino. A origem desses dados pode incluir arquivos sequenciais, arquivos indexados, bancos de dados relacionais, fontes de dados externas, arquivos compactados, aplicativos corporativos, etc. O DataStage é usado para facilitar a análise de negócios, fornecendo dados de qualidade que auxiliam na obtenção de inteligência de negócios.
A ferramenta DataStage ETL é usada em grandes organizações como uma interface entre diferentes sistemas. Ela cuida de diversas etapas, como a extração de dados e a transformação de cargas.tractransferência, tradução e carregamento de dados da origem para o destino. Foi lançado pela primeira vez pela VMark em meados da década de 90. IBM adquirindo a DataStage em 2005, ela foi renomeada para IBM WebSphere DataStage e posterior para IBM Infoesfera.
As várias versões do Datastage disponíveis no mercado até agora foram Enterprise Edition (PX), Server Edition, MVS Edition, DataStage for PeopleSoft e assim por diante. A última edição é IBM InfoSphere DataStage.
IBM O servidor de informações inclui os seguintes produtos,
- IBM InfoSphere DataStage
- IBM InfoSphere QualityStage
- IBM Diretor de Serviços de Informação InfoSphere
- IBM Analisador de informações do InfoSphere
- IBM Servidor de informações rápidoTrack
- IBM Glossário de negócios do InfoSphere
Com a definição estabelecida, a próxima seção analisa o que o produto realmente pode fazer dentro de um armazenamento de dados ambiente.
Visão geral do DataStage
O Datastage possui os seguintes recursos.
- Ele pode integrar dados da mais ampla variedade de fontes de dados empresariais e externas
- Implementa regras de validação de dados
- É útil no processamento e transformação de grandes quantidades de dados
- Ele usa abordagem de processamento paralelo escalável
- Ele pode lidar com transformações complexas e gerenciar vários processos de integração
- Aproveite a conectividade direta com aplicativos empresariais como fontes ou destinos
- Aproveite metadados para análise e manutenção
- Operatestes em lote, em tempo real ou como um serviço Web
Nas seções seguintes deste tutorial do DataStage, descrevemos brevemente os seguintes aspectos do IBM InfoSphere DataStage:
- Transformação de dados
- Empregos
- Processamento paralelo
O InfoSphere DataStage e o QualityStage podem acessar dados em aplicativos corporativos e fontes de dados como:
- Bancos de dados relacionais
- Bancos de dados de mainframe
- Aplicativos de negócios e analíticos
- Planejamento de recursos empresariais (ERP) ou bancos de dados de gerenciamento de relacionamento com o cliente (CRM)
- Processamento analítico online (OLAP) ou bancos de dados de gerenciamento de desempenho
Tipos de estágio de processamento
IBM O trabalho da infosfera consiste em estágios individuais interligados. Descreve o fluxo de dados de uma fonte de dados para um destino de dados. Normalmente, um estágio tem no mínimo uma entrada de dados e/ou uma saída de dados. No entanto, alguns estágios podem aceitar mais de uma entrada de dados e saída para mais de um estágio.
No design do trabalho, vários estágios que você pode usar são:
- Estágio de transformação
- Estágio de filtro
- Estágio agregador
- Estágio de remoção de duplicatas
- Entrar no estágio
- Estágio de pesquisa
- Estágio de cópia
- Estágio de classificação
- Containers
Por que usar o DataStage para integração de dados?
Conhecer a lista de funcionalidades é uma coisa; saber quando a ferramenta justifica o custo da licença é outra. O DataStage é a escolha ideal para cargas de trabalho em que o volume, a governança e as fontes heterogêneas tornam os scripts escritos manualmente inviáveis.
A razão mais óbvia é a taxa de transferência. Como o mecanismo particiona os dados entre os nós e transmite os registros entre os estágios simultaneamente, adicionar hardware aumenta a taxa de transferência quase linearmente. Uma tarefa projetada em um ambiente de desenvolvimento com dois nós é executada sem alterações em um cluster de produção com oito nós.
Os outros motivos são de ordem organizacional, e não técnica:
- Metadados compartilhados: As definições de tabelas, conexões e termos comerciais são armazenados uma única vez no repositório e reutilizados por cada tarefa, o que elimina a discrepância que surge quando cada desenvolvedor define uma fonte de forma independente.
- Qualidade de dados integrada: O QualityStage executa investigação, padronização, correspondência e análise de sobrevivência em paralelo ao fluxo ETL, portanto, a limpeza não requer um segundo produto.
- Ampla conectividade: Os conectores nativos alcançam o DB2, OracleTeradata, VSAM para mainframe, SAPSalesforce e armazenamento de objetos na nuvem sem código personalizado.
- Operacontrole nacional: O Director fornece o histórico de execução, a contagem de linhas, os avisos e os pontos de reinicialização, que os auditores aceitam como evidência de um pipeline de dados controlado.
- Reutilização: Contêineres e conjuntos de parâmetros compartilhados permitem que uma transformação testada atenda a várias tarefas, em vez de ser copiada para cada uma delas.
Esses benefícios dependem diretamente de como o produto é montado, o que será explicado na próxima seção.
Componentes do DataStage e Archiarquitetura
DataStage tem quatro componentes principais, a saber,
- administrador: É usado para tarefas administrativas. Isso inclui configurar usuários do DataStage, definir critérios de eliminação e criar e mover projetos.
- Manager: É a interface principal do Repositório do ETL DataStage. É usado para armazenamento e gerenciamento de metadados reutilizáveis. Através do gerenciador DataStage é possível visualizar e editar o conteúdo do Repositório.
- Designer: Uma interface de design usada para criar aplicativos OU tarefas do DataStage. Ele especifica a fonte de dados, a transformação necessária e o destino dos dados. Os trabalhos são compilados para criar um executável agendado pelo Diretor e executado pelo Servidor
- Diretor: Ele é usado para validar, planejar, executar e monitorar tarefas do servidor DataStage e tarefas paralelas.

A imagem acima explica como IBM O Infosphere DataStage interage com outros elementos do IBM Plataforma de servidor de informações. O DataStage é dividido em duas seções, Componentes compartilhados e tempo de execução ArchiarquiteturaA tabela abaixo detalha a contribuição de cada uma dessas duas seções.
|
Partilhado |
Interface de usuário unificada |
|
|
Serviços Comuns |
|
|
|
Processamento Paralelo Comum |
|
|
|
Runtime Archiarquitetura |
Script de SST |
|
Como funciona o processamento paralelo no DataStage
A tabela de arquitetura acima nomeia o processamento paralelo comum como um serviço compartilhado. Esta seção explica como esse serviço executa uma tarefa, pois o conceito foi mencionado na visão geral e determina a velocidade de conclusão da tarefa.
Um trabalho paralelo utiliza dois mecanismos simultaneamente, e ambos são aplicados automaticamente em tempo de execução, em vez de serem codificados manualmente.
1. Paralelismo de pipeline. Cada etapa de um trabalho começa imediatamente, em vez de esperar que a etapa anterior termine. A etapa de origem começa a ler as linhas e as envia para um pipeline na memória. O Transformer inicia assim que as primeiras linhas chegam e envia sua saída para um segundo pipeline. O conector de destino começa a gravar imediatamente depois disso. Nenhum arquivo de destino intermediário é gravado, portanto, um trabalho de três etapas sobrepõe as etapas de leitura, transformação e gravação, em vez de executá-las em sequência.
2. Paralelismo de partições. As linhas são divididas em partições separadas, e uma cópia completa da lógica de estágio é executada em cada partição em seu próprio nó. Oito partições significam oito instâncias simultâneas do Transformer. Ao final do fluxo, as partições são reunidas em um único fluxo para o destino.
Escolher o método de particionamento correto é a principal decisão de otimização que um desenvolvedor toma:
- Automóvel: O padrão. O mecanismo escolhe um método com base no que a etapa exige.
- Jogo da velha: Envia linhas com o mesmo valor de chave para o mesmo nó. Necessário antes de Join, Aggregator e Remove Duplicates para garantir que as chaves correspondentes sejam atendidas.
- Rod Robin: Distribui as linhas uniformemente, uma a uma. Ideal para carregar um arquivo plano onde o grupo de teclas...ping Não importa.
- Inteiro: Copia todo o conjunto de dados para cada nó. Usado para pequenas tabelas de referência em um estágio de pesquisa.
- Mesmo: Mantém o particionamento existente intacto, evitando um reparticionamento desnecessário entre dois estágios.
- Alcance e Módulo: Distribua as linhas por uma faixa de valores ou por um resto numérico quando for necessária uma distribuição uniforme.
Um arquivo de configuração (o APT_CONFIG_FILE) declara quantos nós existem. Como a contagem de nós reside fora do job, o mesmo job compilado pode ser escalado de um laptop para uma grade de produção sem alterações no projeto.
Antes que qualquer uma dessas opções possa ser testada, o ambiente precisa estar pronto.
Pré-requisito para ferramenta Datastage
Para o DataStage, você precisará da configuração a seguir.
- Infosfera
- Servidor DataStage 9.1.2 ou superior
- Microsoft Visual Studio .NET 2010 Edição Expressa C++
- Oracle cliente (cliente completo, não um cliente instantâneo) se estiver conectado a um Oracle banco de dados
- Cliente DB2 se estiver conectado a um banco de dados DB2
Agora nesta série de tutoriais do DataStage para iniciantes, aprenderemos como fazer download e instalar o InfoSphere Information Server.
Download e instalação do InfoSphere Information Server
Para acessar o DataStage, baixe e instale a versão mais recente do IBM Servidor InfoSphere. O servidor suporta AIX, Linux e Windows sistema operacional. Você pode escolher conforme a necessidade.
Para migrar seus dados de uma versão mais antiga do infosphere para uma nova versão, use a ferramenta de intercâmbio de ativos.
Arquivos de instalação
Para instalar e configurar o Infosphere Datastage, você deve ter os seguintes arquivos em sua configuração.
Para Windows,
- Pacote de Implantação Etl-windows-oracle.pkg
- Pacote de Implantação Etl-windows-db2.pkg
Para o Linux,
- EtlDeploymentPackage-linux-db2.pkg
- Pacote de Implantação Etl-linux-oracle.pkg
Com o servidor instalado, o exemplo prático no restante desta página utiliza a captura de dados de alteração (change data capture), portanto, é útil entender como os dados de alteração são transmitidos antes de implementá-los.
Fluxo de processo de dados alterados em um trabalho de estágio de transação do CDC

O diagrama acima tracTrata-se de uma única alteração do banco de dados de origem para o banco de dados de destino, na ordem listada abaixo.
- O serviço 'InfoSphere CDC' para o banco de dados monitora e captura a mudança de um banco de dados de origem
- De acordo com a definição de replicação, o “InfoSphere CDC” transfere os dados alterados para o “InfoSphere CDC para InfoSphere DataStage”.
- O servidor “InfoSphere CDC for InfoSphere DataStage” envia dados para o “estágio de transação do CDC” por meio de uma sessão TCP/IP. O servidor “InfoSphere CDC for InfoSphere DataStage” também envia uma mensagem COMMIT (juntamente com informações de marcador) para marcar o limite da transação no log capturado.
- Para cada mensagem COMMIT enviada pelo servidor “InfoSphere CDC for InfoSphere DataStage”, o “estágio de transação do CDC” cria marcadores de fim de onda (EOW). Esses marcadores são enviados em todos os links de saída para o estágio do conector do banco de dados de destino.
- Quando o “estágio do conector do banco de dados de destino” recebe um marcador de fim de onda em todos os links de entrada, ele grava as informações do marcador em uma tabela de marcadores e, em seguida, confirma a transação no banco de dados de destino.
- O servidor “InfoSphere CDC for InfoSphere DataStage” solicita informações de marcadores de uma tabela de marcadores no “banco de dados de destino”.
- O servidor “InfoSphere CDC for InfoSphere DataStage” recebe as informações do Bookmark.
Esta informação é usada para,
- Determine o ponto inicial no log de transações onde as alterações serão lidas quando a replicação começar.
- Para determinar se o log de transações existente pode ser limpo
Configurando a replicação SQL
Antes de começar com o Datastage, você precisa configurar o banco de dados. Você criará dois bancos de dados DB2.
- Um para servir como fonte de replicação e
- Um como alvo.
Você também criará duas tabelas (Produto e Estoque) e as preencherá com dados de amostra. Então você pode testar sua integração entre SQL Replicação e Datastage.
Seguindo em frente, você configurará a replicação SQL criando tabelas de controle, conjuntos de assinaturas, registros e membros do conjunto de assinaturas. Aprenderemos mais sobre isso em detalhes na próxima seção.
Aqui pegaremos um exemplo de item de vendas no varejo como nosso banco de dados e criaremos duas tabelas Inventário e Produto. Essas tabelas carregarão dados da origem ao destino por meio desses conjuntos. (tabelas de controle, conjuntos de assinaturas, registros e membros do conjunto de assinaturas.)
Passo 1) Crie um banco de dados de origem denominado VENDAS. Neste banco de dados, crie duas tabelas PRODUTOS e Estoque.
Passo 2) Execute o seguinte comando para criar o banco de dados SALES.
db2 create database SALES
Passo 3) Ative a criação de log de arquivamento para o banco de dados SALES. Além disso, faça backup do banco de dados usando os seguintes comandos
db2 update db cfg for SALES using LOGARCHMETH3 LOGRETAIN db2 backup db SALES
Passo 4) No mesmo prompt de comando, acesse o subdiretório setupDB dentro do diretório sqlrepl-datastage-tutorial que você executou.tracextraído do arquivo compactado baixado.

Passo 5) Use o comando a seguir para criar a tabela de inventário e importar dados para a tabela executando o comando a seguir.
db2 import from inventory.ixf of ixf create into inventory
Passo 6) Crie uma tabela de destino. Nomeie o banco de dados de destino como ESTÁGIODB.
Como agora você criou os bancos de dados de origem e de destino, na próxima etapa deste tutorial do DataStage, veremos como replicá-los.
As informações a seguir podem ser úteis para Configurando uma fonte de dados ODBC no IBM Documentação do InfoSphere Information Server.
Criando os objetos de replicação SQL
A imagem abaixo mostra como o fluxo de dados de alteração é entregue do banco de dados de origem para o banco de dados de destino. Você cria um mapeamento de origem para destino.ping entre mesas conhecidas como membros do conjunto de assinaturas e agrupar os membros em um tudo incluso.

A unidade de replicação no InfoSphere CDC (Change Data Capture) é chamada de assinatura.
- As alterações feitas na fonte são capturadas na “tabela de controle de captura” que é enviada para a tabela CD e depois para a tabela de destino. Enquanto o programa apply terá os detalhes sobre a linha de onde as alterações precisam ser feitas. Ele também se juntará à tabela de CDs no conjunto de assinaturas.
- Uma assinatura inclui um mapa.ping Detalhes que especificam como os dados em um repositório de dados de origem são aplicados a um repositório de dados de destino. Observe que o CDC agora é referido como Replicação de dados da Infosfera.
- Quando uma assinatura é executada, o InfoSphere CDC captura alterações no banco de dados de origem. O InfoSphere CDC entrega os dados alterados ao destino e armazena informações do ponto de sincronização em uma tabela de marcadores no banco de dados de destino.
- O InfoSphere CDC usa as informações do marcador para monitorar o progresso da tarefa do InfoSphere DataStage.
- Em caso de falha, as informações do marcador são utilizadas como ponto de reinicialização. Em nosso exemplo, o ASN.IBMA tabela SNAP_FEEDETL armazena informações de ponto de sincronização relacionadas ao DataStage que são usadas para track Progresso do DataStage.
Nesta seção de IBM Tutorial de treinamento do DataStage, você precisa fazer o seguinte,
- Crie tabelas CAPTURE CONTROL e tabelas APPLY CONTROL para armazenar opções de replicação
- Registre as tabelas PRODUCT e INVENTORY como fontes de replicação
- Crie um conjunto de assinaturas com dois membros
- Criar membros do conjunto de assinaturas e tabelas CCD de destino
Use o programa de linha de comando ASNCLP para configurar a replicação SQL
Passo 1) Localize o arquivo de script crtCtlTablesCaptureServer.asnclp no diretório sqlrepl-datastage-tutorial/setupSQLRep.
Passo 2) No arquivo substitua e " ” com seu ID de usuário e senha para se conectar ao banco de dados SALES.
Passo 3) Mude os diretórios para o diretório sqlrepl-datastage-tutorial/setupSQLRep e execute o script. Use o seguinte comando. O comando irá se conectar ao banco de dados SALES, gerar um script SQL para criação das tabelas de controle do Capture.
asnclp –f crtCtlTablesCaptureServer.asnclp
Passo 4) Localize o arquivo de script crtCtlTablesApplyCtlServer.asnclp no mesmo diretório. Agora substitua duas instâncias de e " ” com o ID do usuário e senha para conexão com o banco de dados STAGEDB.
Passo 5) Agora, no mesmo prompt de comando, use o seguinte comando para criar tabelas de controle de aplicação.
asnclp –f crtCtlTablesApplyCtlServer.asnclp
Passo 6) Localize os arquivos de script crtRegistration.asnclp e substitua todas as instâncias de com o ID do usuário para conexão com o banco de dados SALES. Além disso, altere “ ”Para a senha de conexão.
Passo 7) Para registrar as tabelas de origem, use o seguinte script. Como parte da criação do cadastro, o programa ASNCLP criará duas tabelas CD. CDPRODUTO E CDINVENTÁRIO.
asnclp –f crtRegistration.asnclp
O comando CREATE REGISTRATION usa as seguintes opções:
- Atualização Diferencial: solicita ao programa Apply que atualize a tabela de destino somente quando as linhas na tabela de origem forem alteradas
- Imagem de ambos: Esta opção é usada para registrar o valor na coluna de origem antes da alteração ocorrer e uma para o valor após a alteração ocorrer.
Passo 8) Para conectar-se ao banco de dados de destino (STAGEDB), siga as etapas a seguir.
- Encontre o arquivo crtTableSpaceApply.bat e abra-o em um editor de texto
- Substituir e com o ID de usuário e senha
- Na janela de comando do DB2, insira crtTableSpaceApply.bat e execute o arquivo.
- Este arquivo em lote cria um novo espaço de tabela no banco de dados de destino (STAGEDB)
Passo 9) Localize os arquivos de script crtSubscriptionSetAndAddMembers.asnclp e faça as alterações a seguir.
- Substitua todas as instâncias de e com o ID do usuário e senha para conexão com o banco de dados SALES (fonte).
- Substitua todas as instâncias de e com o ID do usuário para conexão com o banco de dados STAGEDB (destino).
Após as alterações, execute o script para criar o conjunto de assinaturas (ST00) que agrupa as tabelas de origem e de destino. O script também cria dois membros do conjunto de assinaturas e CCD (dados de alteração consistente) no banco de dados de destino que armazenará os dados modificados. Esses dados serão consumidos pelo Infosphere DataStage.
Passo 10) Execute o script para criar o conjunto de assinaturas, os membros do conjunto de assinaturas e as tabelas CCD.
asnclp –f crtSubscriptionSetAndAddMembers.asnclp
Várias opções usadas para criar um conjunto de assinaturas e dois membros incluem
- Concluir na condensação
- Externo
- Exportação de importação de tipo de carga
- Tempo contínuo
Passo 11) Devido ao defeito nas ferramentas de administração de replicação. Você precisa executar outro arquivo em lote para definir a coluna TARGET_CAPTURE_SCHEMA no IBMTabela de controle SNAP_SUBS_SET como nula.
- Localize o arquivo updateTgtCapSchema.bat. Abra-o em um editor de texto. Substituir e com o ID do usuário para conexão com o banco de dados STAGEDB.
- Na janela de comando do DB2, insira o comando updateTgtCapSchema.bat e execute o arquivo.
Criando os arquivos de definição para mapear tabelas CCD para o DataStage
Antes de fazermos a replicação na próxima etapa, precisamos conectar a tabela CCD ao DataStage. Nesta seção, veremos como conectar o SQL ao DataStage.
Para conectar a tabela CCD ao DataStage, você precisa criar arquivos de definição do DataStage (.dsx). O formato de arquivo .dsx é usado pelo DataStage para importar e exportar definições de jobs. Você usará um script ASNCLP para criar dois arquivos .dsx. Por exemplo, aqui criamos dois arquivos .dsx.
- stagedb_AQ00_SET00_sJobs.dsx: cria uma sequência de tarefas que direciona o fluxo de trabalho dos quatro trabalhos paralelos.
- stagedb_AQ00_SET00_pJobs.dsx : Cria os quatro trabalhos paralelos
O programa ASNCLP mapeia automaticamente a coluna CCD para o formato Datastage Column. Só é suportado quando o ASNCLP é executado em Windows, Linux ou Procedimento Unix.

Os jobs do Datastage extraem linhas da tabela CCD.
- Uma tarefa define um ponto de sincronização onde o DataStage parou em extracO trabalho obtém dados das duas tabelas. Ele obtém essas informações selecionando o valor SYNCHPOINT para o conjunto de assinaturas ST00 do IBMtabela SNAP_SUBS_SET e inserindo-a na coluna MAX_SYNCHPOINT do IBMTabela SNAP_FEEDETL.
- Dois empregos que extracOs dados são obtidos das tabelas PRODUCT_CCD e INVENTORY_CCD. Os jobs sabem quais linhas iniciar, por exemplo.tracting selecionando os valores MIN_SYNCHPOINT e MAX_SYNCHPOINT da IBMTabela SNAP_FEEDETL para o conjunto de assinaturas.
Com as definições mapeadas, a replicação pode agora ser iniciada para que as tabelas CCD comecem a ser preenchidas.
Iniciando a replicação
Para iniciar a replicação, você usará as etapas abaixo. Quando as tabelas CCD são preenchidas com dados, isso indica que a configuração de replicação foi validada. Para visualizar os dados replicados nas tabelas CCD de destino, utilize a interface gráfica com o usuário do DB2 Control Center.
Passo 1) Certifique-se de que o DB2 esteja em execução, caso contrário, use início do DB2 comando.
Passo 2) Em seguida, use o comando asncap em um prompt do sistema operacional para iniciar a captura do programa. Por exemplo.
asncap capture_server=SALES
O comando acima especifica o banco de dados SALES como o servidor Capture. Mantenha a janela de comando aberta enquanto a captura estiver em execução.
Passo 3) Agora abra um novo prompt de comando. Então comece o INSCREVA-SE programa usando o comando asnapply.
asnapply control_server=STAGEDB apply_qual=AQ00

- O comando especifica o banco de dados STAGEDB como o servidor de controle do Apply (o banco de dados que contém as tabelas de controle do Apply)
- AQ00 como o qualificador Apply (o identificador para este conjunto de tabelas de controle)
Deixe a janela de comando aberta com o Apply em execução.
Passo 4) Agora abra outro prompt de comandos e emita o comando db2cc para ativar o DB2 Control Center. Aceite o Centro de Controle padrão.
Passo 5) Agora, na árvore de navegação esquerda, abra Todos os bancos de dados > STAGEDB e clique em Tabelas. Double clique no nome da tabela (Produto CCD) para abrir a tabela. Vai parecer algo assim.

Da mesma forma, você também pode abrir a tabela CCD para INVENTÁRIO.

A replicação agora está alimentando as tabelas CCD, então a atenção se desloca do lado do banco de dados para os clientes DataStage.
Como criar projetos na ferramenta Datastage
Primeiramente você criará um projeto no DataStage. Para isso, você deve ser um administrador do InfoSphere DataStage.
Depois que a instalação e a replicação forem concluídas, você precisará criar um projeto. No DataStage, os projetos são um método para organizar seus dados. Inclui a definição de arquivos de dados, etapas e construção de trabalhos em um projeto específico.
Para criar um projeto no DataStage, siga as etapas abaixo:
Etapa 1) Inicie o software DataStage
Inicie o DataStage e o QualityStage Administrator. Em seguida, clique em Iniciar > Todos os programas > IBM Servidor de informações > IBM Administrador do WebSphere DataStage e QualityStage.
Etapa 2) Conecte o servidor e o cliente DataStage
Para conectar-se ao servidor DataStage a partir de seu cliente DataStage, insira detalhes como nome de domínio, ID do usuário, senha e informações do servidor.
Etapa 3) Adicionar um novo projeto
Na janela Administração do WebSphere DataStage. Clique na guia Projetos e em Adicionar.
Etapa 4) Insira os detalhes do projeto
Na janela Administração do WebSphere DataStage, insira detalhes como
- Nome
- Localização do arquivo
- Clique OK'

Cada projeto contém:
- Tarefas do DataStage
- Componentes integrados. Estes são componentes predefinidos usados em um trabalho.
- Componentes definidos pelo usuário. Esses são componentes customizados criados usando o DataStage Manager ou o DataStage Designer.
Veremos como importar trabalhos de replicação no Datastage Infosphere.
Como importar trabalhos de replicação no Datastage e no QualityStage Designer
Você importará trabalhos no IBM Cliente InfoSphere DataStage e QualityStage Designer. E você os executa no IBM Cliente InfoSphere DataStage e QualityStage Director.
O cliente-designer é como uma tela em branco para projetos de construção.tracEle fornece ferramentas que constituem os blocos de construção básicos de um Job, incluindo: transformar, carregar e verificar a qualidade dos dados.
- estágios: ele se conecta a fontes de dados para ler ou gravar arquivos e processar dados.
- Ligações: conecta os estágios ao longo dos quais seus dados fluem
Os estágios no cliente InfoSphere DataStage e QualityStage Designer são armazenados na paleta de ferramentas Designer.
Os estágios a seguir estão incluídos no InfoSphere QualityStage:
- Estágio de investigação
- Padronizar estágio
- Estágio de Frequência de Partida
- Estágio de partida de fonte única
- Estágio de partida de duas fontes
- Estágio de sobrevivência
- Estágio de Avaliação da Qualidade da Padronização (SQA)
Você pode criar 4 tipos de trabalhos na infoesfera do DataStage.
- Trabalho paralelo
- Trabalho de sequência
- Trabalho de mainframe
- Trabalho de servidor
Vamos ver passo a passo como importar arquivos de trabalho de replicação.
Passo 1) Inicie o DataStage e o QualityStage Designer. Clique em Iniciar > Todos os programas > IBM Servidor de informações > IBM WebSphere DataStage e QualityStage Designer
Passo 2) Na janela Anexar ao projeto, insira os seguintes detalhes.
- Domínio
- Nome de usuário
- Senha
- Nome do projeto
- OK

Passo 3) Agora, no menu Arquivo, clique em importar -> Componentes do DataStage.
Uma nova janela de importação do repositório do DataStage será aberta.
- Nesta janela navegue STAGEDB_AQ00_ST00_sJobs.dsx arquivo que criamos anteriormente
- Selecione a opção “Importar tudo”.
- Marque a caixa de seleção “Executar análise de impacto”.
- Clique OK.'

Depois que a tarefa for importada, o DataStage criará a tarefa STAGEDB_AQ00_ST00_sequence.
Passo 4) Siga os mesmos passos para importar o Arquivo STAGEDB_AQ00_ST00_pJobs.dsx. Esta importação cria os quatro trabalhos paralelos.
Passo 5) No painel Repositório do Designer -> Abra a pasta SQLREP. Dentro da pasta, você verá Sequence Job e quatro trabalhos paralelos.
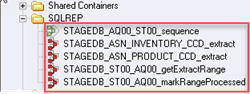
Passo 6) Para ver o trabalho de sequência. Vá para a árvore do repositório, clique com o botão direito na tarefa STAGEDB_AQ00_ST00_sequence e clique em Editar. Ele mostrará o fluxo de trabalho dos quatro trabalhos paralelos controlados pela sequência de trabalhos.

Cada ícone é um palco,
- getExtracestágio tRange: Atualiza o IBMTabela SNAP_FEEDETL. Ela definirá o ponto de partida para os dados ex.tracção até o ponto em que o DataStage último extraclinhas ted e defina o ponto final para a última transação processada para o conjunto de assinaturas.
- getExtractRangeSuccessEsta etapa fornece os pontos de partida para o ex.tractFromINVENTORY_CCD estágio e extractFromPRODUCT_CCD estágio
- AllExtractsSucesso: Esta etapa garante que ambos os extractFromINVENTORY_CCD e extracO evento tFromPRODUCT_CCD foi concluído com sucesso. Em seguida, os pontos de sincronização das últimas linhas buscadas são passados para o estágio setRangeProcessed.
- Estágio setRangeProcessed: Ele atualiza IBMTabela SNAP_FEEDETL. Assim, o DataStage sabe de onde começar a próxima rodada de extração de dados.tracção
Passo 7) Para ver os trabalhos paralelos. Clique com o botão direito em STAGEDB_ASN_INVENTORY_CCD e selecione editar no repositório. Irá abrir uma janela conforme mostrado abaixo.

Aqui na imagem acima, você pode ver que os dados da tabela CCD do Inventário e SyncOs detalhes do ponto h da tabela FEEDETL são renderizados no estágio Lookup_6.
Os trabalhos importados ainda não apontam para lugar nenhum, então um objeto de conexão de dados precisa ser definido em seguida.
Criando uma conexão de dados do DataStage para o banco de dados STAGEDB
Agora, a próxima etapa é construir uma conexão de dados entre o InfoSphere DataStage e o banco de dados de destino do SQL Replication. Ele contém as tabelas CCD.
No DataStage, você usa objetos de conexão de dados com estágios de conector relacionados para definir rapidamente uma conexão com uma origem de dados em um design de tarefa.
Passo 1) STAGEDB contém as tabelas de controle Apply que o DataStage usa para sincronizar seus dados.tracção e as tabelas CCD das quais os dados são extraídostracTed. Use os seguintes comandos
db2 catalog tcpip node SQLREP remote ip_address server 50000 db2 catalog database STAGEDB as STAGEDB2 at node SQLREP
Observação: Endereço IP do sistema onde o STAGEDB foi criado
Passo 2) Clique em Arquivo > Novo > Outro > Conexão de dados.
Passo 3) Você terá uma janela com duas guias, Parâmetros e Geral.

Passo 4) Nesta etapa,
- Em geral, guia, nomeie a conexão de dados como sqlreplConnect
- Na aba Parâmetros, conforme mostrado abaixo
- Clique no botão de navegação ao lado do campo "Conectar usando tipo de estágio" e no
- Janela aberta navegue na árvore do repositório até Stage Types –> Parallel– > Database —-> DB2 Connector.
- Clique em Abrir.

Passo 5) Na tabela de parâmetros de conexão, insira detalhes como
- Connectionstring: STAGEDB2
- Nome de Utilizador: ID do usuário para conexão com o banco de dados STAGEDB
- Senha: Senha para conexão ao banco de dados STAGEDB
- Instância: Nome da instância do DB2 que contém o banco de dados STAGEDB
Passo 6) Na próxima janela, salve a conexão de dados. Clique no botão 'salvar'.
Importando Definições de Tabela do STAGEDB para o DataStage
Na etapa anterior, vimos que o InfoSphere DataStage e o banco de dados STAGEDB estão conectados. Agora, importe a definição de coluna e outros metadados para as tabelas PRODUCT_CCD e INVENTORY_CCD no repositório do Information Server.
Na janela do designer, siga as etapas abaixo.
Passo 1) Selecione Importar > Definições de Tabela > Iniciar Assistente de Importação de Conector
Passo 2) Na página de seleção do conector do assistente, selecione o Conector DB2 e clique em Avançar.

Passo 3) Clique em carregar na página de detalhes da conexão. Isso preencherá os campos do assistente com informações de conexão da conexão de dados que você criou no capítulo anterior.

Passo 4) Clique em Testar conexão na mesma página. Isso solicitará que o DataStage tente uma conexão com o banco de dados STAGEDB. Você pode ver a mensagem “conexão bem-sucedida”. Clique em Avançar.

Passo 5) Certifique-se de que na página Local da fonte de dados os campos Nome do host e Nome do banco de dados estejam preenchidos corretamente. Em seguida, clique em próximo.
Passo 6) Na página Esquema. Insira o esquema das tabelas de controle do Apply (ASN) ou verifique se o esquema ASN está pré-preenchido no campo do esquema. Em seguida, clique em próximo. A página de seleção mostrará a lista de tabelas definidas no esquema ASN.

Passo 7) A primeira tabela da qual precisamos importar metadados é IBMSNAP_FEEDETL é uma tabela de controle de aplicação. Ela contém detalhes sobre os pontos de sincronização que permitem ao DataStage manter track das quais linhas foram obtidas das tabelas CCD. Escolha IBMSNAP_FEEDETL e clique em Avançar.
Passo 8) Para concluir a importação do IBMDefinição da tabela SNAP_FEEDETL. Clique em importar e, na janela aberta, clique em abrir.
Passo 9) Repita as etapas 1 a 8 mais duas vezes para importar as definições para a tabela PRODUCT_CCD e depois para a tabela INVENTORY_CCD.
NOTA: ao importar definições para o inventário e produto, certifique-se de alterar os esquemas de ASN para o esquema sob o qual PRODUCT_CCD e INVENTORY_CCD foram criados.
Agora o DataStage tem todos os detalhes necessários para se conectar ao banco de dados de destino da Replicação SQL.
Configurando propriedades para tarefas do DataStage
Para cada uma das quatro tarefas paralelas do DataStage que temos, ela contém um ou mais estágios que se conectam ao banco de dados STAGEDB. É necessário modificar os estágios para incluir informações de conexão e vincular aos arquivos do conjunto de dados preenchidos pelo DataStage.
Os estágios possuem propriedades predefinidas que podem ser editadas. Aqui, alteraremos algumas dessas propriedades para o STAGEDB_ASN_PRODUCT_CCD_ex.tract trabalho paralelo.
Passo 1) Navegue pela árvore do repositório do Designer. Na pasta SQLREP, selecione STAGEDB_ASN_PRODUCT_CCD_ex.tracPara editar, clique com o botão direito do mouse no trabalho paralelo. A janela de projeto do trabalho paralelo será aberta na Paleta do Designer.
Passo 2) Localize o ícone verde. Este ícone representa o estágio do conector DB2. Ele é usado para, por exemplo,tracobtendo dados da tabela CCD. Double-clique no ícone. Uma janela do editor de palco é aberta.


Passo 3) No editor, clique em Carregar para preencher os campos com informações de conexão. Para fechar o editor de palco e salvar suas alterações, clique em OK.
Passo 4) Agora retorne à janela de design para o STAGEDB_ASN_PRODUCT_CCD_extract trabalho paralelo. Localize o ícone para obterSyncEstágio do conector hPoints DB2. Em seguida, clique duas vezes no ícone.
Passo 5) Agora clique no botão carregar para preencher os campos com informações de conexão.
NOTA: se você estiver usando um banco de dados diferente do STAGEDB como servidor de controle do Apply. Em seguida, selecione a opção de carregar as informações de conexão para obterSyncEstágio hPoints, que interage com as tabelas de controle em vez da tabela CCD.
Passo 6) Nesta etapa,
- Crie um arquivo de texto vazio no sistema em que o InfoSphere DataStage é executado.
- Nomeie este arquivo como productdataset.ds e anote onde você o salvou.
- O DataStage gravará as alterações neste arquivo depois de buscar as alterações na tabela CCD.
- Conjuntos de dados ou arquivos usados para mover dados entre trabalhos vinculados são conhecidos como conjuntos de dados persistentes. É representado por um estágio DataSet.
Passo 7) Agora abra o editor de palco na janela de design e clique duas vezes no ícone insert_into_a_dataset. Isso abrirá outra janela.

Passo 8) Nesta janela,

- Na guia de propriedades, certifique-se de que Target pasta está aberta e a propriedade File = DATASETNAME está destacada.
- À direita, você terá um campo de arquivo
- Insira o caminho completo para o arquivo productdataset.ds
- Clique OK'.
Agora você atualizou todas as propriedades necessárias para a tabela CCD do produto. Feche a janela de design e salve todas as alterações.
Passo 9) Agora localize e abra o STAGEDB_ASN_INVENTORY_CCD_extracCrie um trabalho paralelo a partir do painel de repositório do Designer e repita os passos 3 a 8.
NOTA:
- Você precisa carregar as informações de conexão do banco de dados do servidor de controle no editor de estágio para obterSyncEstágio de hpontos. Se o seu servidor de controle não for STAGEDB.
- Para STAGEDB_ST00_AQ00_getExtracOs jobs paralelos tRange e STAGEDB_ST00_AQ00_markRangeProcessed abrem todos os estágios do conector DB2. Em seguida, use a função load para adicionar informações de conexão para o banco de dados STAGEDB.
Todas as propriedades agora estão definidas, portanto os trabalhos podem ser compilados e executados.
Compilando e executando os trabalhos do DataStage
Quando a tarefa do DataStage está pronta para ser compilada, o Designer valida o design da tarefa observando entradas, transformações, expressões e outros detalhes.
Quando a compilação do trabalho for concluída com sucesso, ele estará pronto para ser executado. Compilaremos todos os cinco trabalhos, mas executaremos apenas a “sequência de trabalhos”. Isso ocorre porque esse trabalho controla todos os quatro trabalhos paralelos.
Passo 1) Na pasta SQLREP. Selecione cada um dos cinco trabalhos por (Cntrl+Shift). Em seguida, clique com o botão direito e escolha a opção de compilação de vários trabalhos.

Passo 2) Você verá que cinco tarefas estão selecionadas no Assistente de Compilação do DataStage. Clique em Avançar.

Passo 3) A compilação começa e exibe uma mensagem “Compilado com sucesso” quando concluída.

Passo 4) Agora inicie o DataStage e o QualityStage Director. Selecione Iniciar > Todos os programas > IBM Servidor de informações > IBM WebSphere DataStage e QualityStage Director.
Passo 5) No painel de navegação do projeto à esquerda. Clique na pasta SQLREP. Isso traz todos os cinco cargos para a tabela de status de diretor.
Passo 6) Selecione a tarefa STAGEDB_AQ00_S00_sequence. Na barra de menus, clique em Trabalho > Executar agora.

Assim que a compilação estiver concluída, você verá o status de finalizado.

Agora verifique se as linhas alteradas armazenadas nas tabelas PRODUCT_CCD e INVENTORY_CCD foram excluídas.tracprocessado pelo DataStage e inserido nos dois arquivos de conjunto de dados.
Passo 7) Volte ao Designer e abra o arquivo STAGEDB_ASN_PRODUCT_CCD_ex.tract trabalho. Para abrir o editor de palco Double-clique no ícone insert_into_a_dataset. Em seguida, clique em visualizar dados.
Passo 8) Aceite os padrões nas linhas a serem exibidas na janela. Em seguida, clique em OK. Uma janela do navegador de dados será aberta para mostrar o conteúdo do arquivo do conjunto de dados.

Testando a integração entre replicação SQL e DataStage
Na etapa anterior, compilamos e executamos o trabalho. Nesta seção, verificaremos a integração da replicação SQL e do DataStage. Para isso, faremos alterações na tabela de origem e veremos se a mesma alteração é atualizada no DataStage.
Passo 1) Navegue até a pasta sqlrepl-datastage-scripts do seu sistema operacional.
Passo 2) Inicie a replicação SQL seguindo as etapas:
- Execute o startSQLCapture.bat (Windows) para iniciar o programa Capture no banco de dados SALES.
- Execute o startSQLApply.bat (Windows) para iniciar o programa Apply no banco de dados STAGEDB.
Passo 3) Agora abra o arquivo updateSourceTables.sql. Para conectar-se ao banco de dados SALES, substitua e com o ID do usuário e senha.
Passo 4) Abra uma janela de comando do DB2. Mude o diretório para sqlrepl-datastage-tutorial\scripts e execute o problema com o comando fornecido:
db2 -tvf updateSourceTables.sql
O script SQL realizará diversas operações como Atualizar, Inserir e excluir em ambas as tabelas (PRODUTO, INVENTÁRIO) do banco de dados de Vendas.
Passo 5) No sistema em que o DataStage está em execução. Abra o DataStage Director e execute a tarefa STAGEDB_AQ00_S00_sequence. Clique em Trabalho > Executar agora.

Quando você executa o trabalho, as seguintes atividades serão realizadas.
- O programa Capture lê as alterações de seis linhas no log do banco de dados SALES e as insere nas tabelas CD.
- O programa Apply busca as linhas de alteração das tabelas CD em SALES e as insere nas tabelas CCD em STAGEDB.
- Os dois DataStage extracOs jobs capturam as alterações das tabelas CCD e as gravam nos arquivos productdataset.ds e inventory dataset.ds.
Você pode verificar se as etapas acima ocorreram observando os conjuntos de dados.
Passo 6) Siga os passos abaixo,
- Inicie o Designer. Abra o arquivo STAGEDB_ASN_PRODUCT_CCD_ex.tractrabalho.
- Então Double-clique no ícone insert_into_a_dataset. No editor de palco. Clique em Exibir dados.
- Aceite os padrões nas linhas a serem exibidas na janela e clique em OK.
O conjunto de dados contém três novas linhas. A maneira mais fácil de verificar se as alterações foram implementadas é rolar para baixo à direita do Navegador de dados. Agora olhe para as últimas três linhas (veja a imagem abaixo)

As letras I, U e D especificam as operações INSERT, UPDATE e DELETE que resultaram em cada nova linha.
Você pode fazer a mesma verificação na tabela de inventário.
DataStage versus outras ferramentas ETL populares
Uma vez que o fluxo de ponta a ponta esteja funcionando, a próxima pergunta geralmente é onde o DataStage se posiciona em relação às alternativas que uma equipe já utiliza. A tabela abaixo o compara com três plataformas amplamente utilizadas, com base nos critérios que mais frequentemente influenciam a decisão de compra.
| Critérios | IBM DataStage | informática Central de energia | Talend | SSIS |
|---|---|---|---|---|
| Modelo de processamento | Pipeline mais paralelismo de partição | Particionamento orientado por metadados | Gerado Java or Spark código | Fluxo de dados na memória |
| Melhor ajuste | Cargas de trabalho de processamento em lote e CDC de grande porte em empresas | Arquiteturas legadas complexas com governança pesada | Equipes nativas da nuvem e sensíveis a custos | Microsoft SQL Server propriedades |
| Licenciamento | Comercial, nível premium | Comercial | Edição de código aberto mais planos comerciais | Incluído no SQL Server |
| Curva de aprendizado | Íngreme, especialistas em ETL necessários | Íngreme | Habilidade moderada em programação ajuda | Moderado |
| Qualidade dos dados | QualityStage incluído no pacote | Produto de Qualidade de Dados Separado | Qualidade de dados do Talend incluída | Componentes adicionais |
Resumindo, o DataStage é escolhido quando a taxa de transferência bruta, o alcance do mainframe e a linhagem auditável são mais importantes do que o custo da licença. Ideal para equipes que trabalham principalmente na nuvem. arquitetura de data lake ou comparando extracA ordem inicial pode revelar as vantagens e desvantagens em ETL x ELT mais relevante, e uma lista restrita mais ampla aparece no resumo de Ferramentas ETL e ferramentas de integração de dados.