Tutorial Scikit-Learn: come installare ed esempi di Scikit-Learn
⚡ Riepilogo intelligente
Scikit-learn è il software open-source Python Una libreria che copre preelaborazione, classificazione, regressione, clustering e selezione del modello, il tutto racchiuso in un'unica interfaccia di stima coerente, che mantiene un flusso di lavoro completo di machine learning breve, leggibile e riproducibile, dai dati grezzi alle previsioni con punteggio.

Che cos'è Scikit-learn?
Scikit-learn è un open source Python libreria per machine learning. Supporta algoritmi consolidati come KNN, gradient boosting, random forest e SVM, ed è costruito su NumPy e SciPy. Scikit-learn è ampiamente utilizzato nelle competizioni di Kaggle, così come in importanti aziende tecnologiche. Copre la preelaborazione, la riduzione della dimensionalità, la classificazione, la regressione, il clustering e la selezione del modello.
Scikit-learn ha una delle migliori documentazioni tra tutte le librerie open-source. Fornisce persino un grafico di stima interattivo, Scegliere il giusto peritoche ti guida dalla dimensione del tuo set di dati a una lista ristretta di algoritmi che vale la pena provare.
La figura seguente illustra il funzionamento di Scikit-learn.
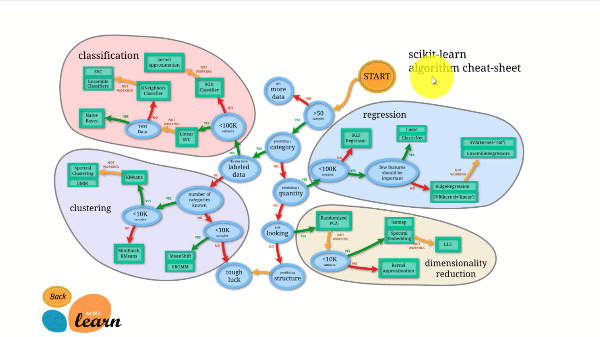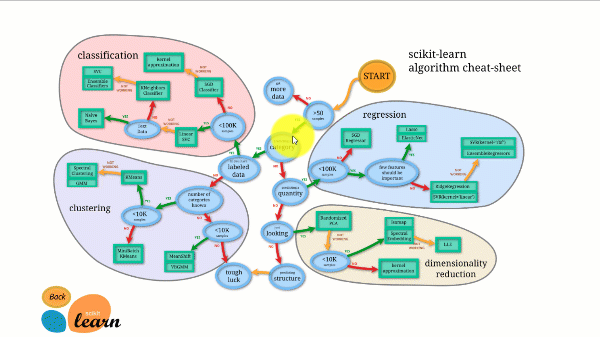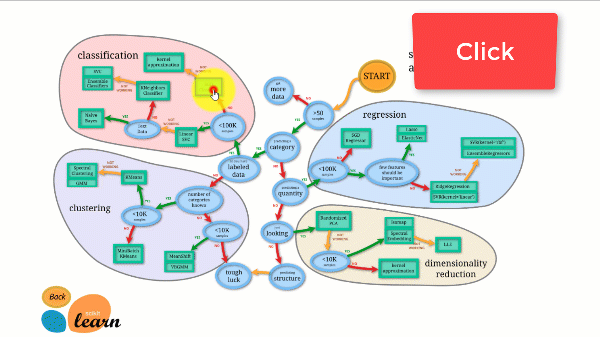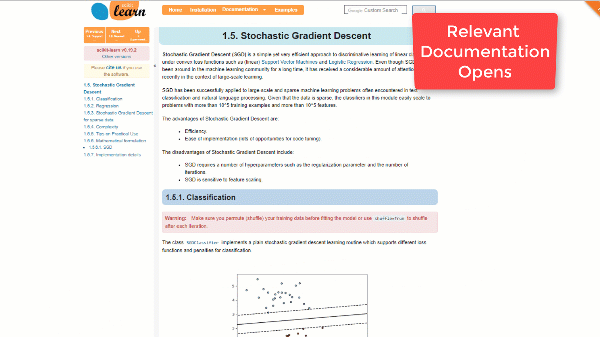
Scikit-learn non è difficile da usare e fornisce risultati eccellenti. Tuttavia, l'addestramento avviene sulla CPU: il lavoro viene parallelizzato tra i core con l'argomento n_jobs anziché su una GPU. Eseguire un algoritmo di deep learning con esso è possibile ma raramente ottimale, soprattutto se si sa già come usarlo TensorFlow.
Come scaricare e installare Scikit-learn
Ora in questo Python In questo tutorial su Scikit-learn imparerai come scaricare e installare Scikit-learn.
Opzione 1: AWS
Scikit-learn può essere utilizzato su AWS. Un'immagine Docker con scikit-learn preinstallato elimina completamente la necessità di configurazione.
Per installare la versione sviluppatore, esegui il comando seguente all'interno Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Opzione 2: Mac o Windows utilizzando Anaconda
Per informazioni sull'installazione di Anaconda, fare riferimento a Come scaricare e installare TensorFlow.
Al momento della stesura di questa guida, gli sviluppatori di scikit avevano rilasciato una versione di sviluppo che risolveva i problemi presenti nella versione allora corrente, quindi i passaggi seguenti utilizzano quella build di sviluppo. Su una macchina nuova oggi, la versione stabile corrente contiene già tutti i trasformatori utilizzati qui e pip install -U scikit-learn è abbastanza.
Come installare scikit-learn con Conda Environment
Se hai installato scikit-learn tramite l'ambiente conda, segui i passaggi seguenti per aggiornarlo alla versione 0.20.
Passaggio 1) Attivare l'ambiente TensorFlow
source activate hello-tf
Passaggio 2) Rimuovere scikit-learn utilizzando il comando conda
conda remove scikit-learn
Passaggio 3) Installa la versione per sviluppatori
Installa la versione per sviluppatori di scikit-learn insieme alle librerie necessarie.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
NOTA: Windows l'utente ha bisogno Microsoft Visivo C++ 14. Puoi ottenerlo Qui..
Esempio di Scikit-Learn con l'apprendimento automatico
Questo tutorial di Scikit è diviso in due parti:
- Apprendimento automatico con scikit-learn
- Come fidarti del tuo modello con LIME
La prima parte descrive in dettaglio come costruire una pipeline, creare un modello e ottimizzare gli iperparametri, mentre la seconda parte tratta l'interpretazione del modello.
Passaggio 1) Importa i dati
In questo tutorial di Scikit-learn, utilizzerai il dataset del censimento degli adulti.
Il file viene letto direttamente dal repository di apprendimento automatico dell'UCI nel codice seguente, quindi non è necessario alcun download manuale. Se sei interessato alle statistiche descrittive, vale la pena dare un'occhiata agli strumenti Dive e Overview. Fai riferimento a questo tutorial Per saperne di più sull'immersione e sulla panoramica generale.
È possibile importare il dataset con pandas. Si noti che è necessario convertire le variabili continue in formato float.
Questo set di dati include otto variabili categoriali, elencate in CATE_FEATURES:
- classe operaia
- continua
- coniugale
- occupazione
- rapporto
- gara
- sesso
- Paese d'origine
Include inoltre sei variabili continue, elencate in CONT._FEATURES:
- fnlwgt
- numero_istruzione
- plusvalenza
- perdita_capitale
- ore_settimana
Gli elenchi vengono compilati manualmente in modo da fornire un'idea più chiara delle colonne coinvolte. Un modo più rapido per creare un elenco di colonne categoriche o continue è il seguente:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Ecco il codice per importare i dati:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
La chiamata al metodo describe() sul frame restituisce le statistiche riassuntive per le sei colonne continue:
| fnlwgt | numero_istruzione | plusvalenza | perdita_capitale | ore_settimana | ||
|---|---|---|---|---|---|---|
| contare | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| significare | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| min | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
È possibile verificare il numero di valori univoci della caratteristica native_country. Solo una famiglia proviene dai Paesi Bassi. Tale famiglia non fornisce alcuna informazione e genererà un errore durante l'addestramento.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
È possibile escludere questa riga non informativa dal set di dati:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Successivamente, memorizzerai la posizione delle caratteristiche continue in un elenco. Ne avrai bisogno nel passaggio successivo per costruire la pipeline.
Il codice seguente scorre tutti i nomi delle colonne in CONTI_FEATURES, legge ogni posizione (ovvero, il suo numero di colonna) e la aggiunge a un elenco chiamato conti_features.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
Il blocco successivo svolge la stessa funzione per le variabili categoriche.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Ora osserviamo il dataset stesso. Ogni caratteristica categoriale è una stringa e un modello non può ricevere un valore stringa, quindi il dataset deve essere trasformato con variabili fittizie.
df_train.head(5)
In realtà, è necessaria una colonna per ogni gruppo in ogni feature. Innanzitutto, esegui il codice seguente per calcolare il numero totale di colonne necessarie.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
L'intero dataset contiene 101 gruppi, come mostrato sopra. La sola caratteristica "classe lavorativa" ha nove gruppi. È possibile elencare i nomi dei gruppi con il codice seguente; unique() restituisce i valori distinti di ciascuna caratteristica categoriale.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Il dataset di addestramento conterrà quindi 101 + 6 colonne: i gruppi one-hot più le sei caratteristiche continue.
Scikit-learn può occuparsi della conversione in due fasi:
- Converti la stringa in un ID. State-gov diventa ID 1, Self-emp-not-inc diventa ID 2 e così via. LabelEncoder lo fa per te.
- Trasponi ciascun ID in una nuova colonna. Il dataset ha 101 ID di gruppo, quindi ci saranno 101 colonne che rappresentano ogni gruppo di caratteristiche categoriali. Scikit-learn fornisce OneHotEncoder per questa operazione.
Passaggio 2) Creare il set di treno/test
Ora che il dataset è pronto, dividiamolo in proporzione 80/20: l'80% per il set di addestramento e il 20% per il set di test.
È possibile utilizzare la funzione train_test_split. Il primo argomento è il dataframe delle caratteristiche e il secondo è l'etichetta. La dimensione del set di test viene impostata tramite test_size.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Passaggio 3) Costruisci la pipeline
La pipeline semplifica l'alimentazione del modello con dati coerenti. L'idea è di far passare i dati grezzi attraverso un unico oggetto che esegue ogni operazione in sequenza.
Con questo dataset è necessario standardizzare le variabili continue e convertire quelle categoriche. Ogni operazione può essere inserita all'interno di una pipeline: i valori mancanti possono essere sostituiti con la media o la mediana e si possono creare nuove variabili.
Hai due possibilità: codificare i due processi in modo statico oppure creare una pipeline. La codifica statica può comportare la presenza di dati di test nelle statistiche stimate e creare incongruenze nel tempo, quindi la pipeline è l'opzione migliore.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
La pipeline esegue due operazioni prima di alimentare il classificatore logistico:
- Standardizza la variabile: StandardScaler()
- Converti le caratteristiche categoriche: OneHotEncoder(sparse=False)
Entrambi i passaggi vengono eseguiti con make_column_transformer. Quando questa guida è stata scritta, la funzione non era presente nella versione rilasciata di scikit-learn (0.19), motivo per cui è stata utilizzata la build di sviluppo; è stata inclusa in ogni versione stabile a partire dalla 0.20.
make_column_transformer è semplice: si dichiarano le colonne da trasformare e la trasformazione da applicare. Per standardizzare le caratteristiche continue si passa:
- conti_features, StandardScaler() all'interno di make_column_transformer
- conti_features: l'elenco delle colonne continue
- StandardScaler: standardizza quelle colonne
L'oggetto OneHotEncoder all'interno di make_column_transformer codifica automaticamente le etichette.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Nota sulla versione: due argomenti nel blocco sopra sono stati spostati. Le versioni attuali prevedono prima il trasformatore e poi le colonne, e scarso è stato rinominato output sparso in scikit-learn 1.2 e rimosso nella 1.4, quindi il codice più recente legge OneHotEncoder(sparse_output=False).
È possibile verificare il funzionamento della pipeline con fit_transform. L'output dovrebbe avere le dimensioni 26048, 107.
preprocess.fit_transform(X_train).shape
(26048, 107)
Il trasformatore di dati è pronto. Si crea la pipeline con make_pipeline e, una volta trasformati i dati, li si alimenta alla regressione logistica.
model = make_pipeline(
preprocess,
LogisticRegression())
Addestrare un modello con scikit-learn è quindi banale: basta chiamare `fit` sulla pipeline. È possibile stampare l'accuratezza con il metodo `score`.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Infine, è possibile prevedere le classi con predict_proba, che restituisce la probabilità di ciascuna classe. Si noti che la somma delle due probabilità è pari a uno.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Passaggio 4) Utilizzo della nostra pipeline in una ricerca nella griglia
La messa a punto degli iperparametri, ovvero i valori che definiscono la struttura del modello, può essere un processo tedioso ed estenuante.
Un modo per valutare il modello sarebbe quello di modificare la dimensione del set di addestramento e misurare le prestazioni, ripetendo l'esercizio dieci volte per osservare la dispersione del punteggio. Si tratta di un lavoro manuale piuttosto impegnativo.
Invece, scikit-learn fornisce funzioni che eseguono per te la regolazione dei parametri e la convalida incrociata.
Convalida incrociata
La convalida incrociata (CV) significa che durante l'addestramento il set di dati di addestramento viene suddiviso n volte in fold e il modello viene valutato n volte. Se CV è impostato a 10, il modello viene addestrato e valutato dieci volte. In ogni ciclo, il classificatore si addestra su nove fold scelti casualmente e il decimo fold viene mantenuto per la valutazione.
Ricerca a griglia
Ogni classificatore ha degli iperparametri da ottimizzare. È possibile provare i valori uno alla volta o impostare una griglia di parametri. La documentazione di scikit-learn elenca tutti i parametri accettati dal classificatore logistico. Per mantenere l'addestramento veloce, in questo esempio viene ottimizzato solo il parametro C, che controlla la regolarizzazione. Deve essere positivo e un valore piccolo attribuisce maggiore peso al regolarizzatore.
Si utilizza l'oggetto GridSearchCV, che accetta un dizionario degli iperparametri da ottimizzare. Elencare ciascun iperparametro seguito dai valori che si desidera provare. Per ottimizzare C si scrive:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — il nome del parametro è preceduto dal nome del classificatore in minuscolo e da due underscore.
Il modello proverà quattro valori diversi: 0.001, 0.01, 0.1 e 1. È addestrato con 10 fold, ovvero cv=10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Ora è possibile addestrare il modello utilizzando GridSearchCV con i parametri grid e cv.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Produzione:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Nota sulla versione: , il id L'argomento visibile in questo output è stato deprecato in scikit-learn 0.22 e rimosso nella versione 0.24, quindi dovrebbe essere semplicemente omesso dalla chiamata GridSearchCV nelle versioni attuali.
Per accedere ai parametri migliori, si utilizza best_params_.
grid_clf.best_params_
Produzione:
{'logisticregression__C': 1.0}
Dopo aver addestrato il modello con quattro diversi valori di regolarizzazione, il parametro ottimale risulta essere:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
migliore regressione logistica dalla ricerca sulla griglia: 0.850891
Per accedere alle probabilità previste:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
Modello XGBoost con scikit-learn
Ora prova uno dei classificatori più potenti sul mercato. XGBoost è un miglioramento del random forest basato sul gradient boosting. Il suo background teorico esula dall'ambito di questa trattazione. Python Questo tutorial di Scikit-learn illustra come utilizzare XGBoost, ma è importante ricordare che ha vinto numerose competizioni su Kaggle. Su un dataset di dimensioni medie, può ottenere prestazioni pari o superiori a quelle di un algoritmo di deep learning.
L'addestramento del classificatore è complesso perché presenta un elevato numero di parametri. Naturalmente, è possibile utilizzare GridSearchCV per selezionarli automaticamente.
Un'opzione migliore in questo caso è RandomizedSearchCV. GridSearchCV diventa lento quando la griglia è grande, perché lo spazio di ricerca cresce con ogni parametro aggiunto. RandomizedSearchCV, invece, campiona i valori di ciascun iperparametro in modo casuale a ogni iterazione, quindi 1,000 iterazioni valutano 1,000 combinazioni. Per il resto, funziona in modo molto simile a GridSearchCV.
È necessario importare xgboost. Se la libreria non è installata, eseguire pip3 install xgboost oppure installarla dall'interno di un Jupyter notebook con:
use import sys
!{sys.executable} -m pip install xgboost
Successivamente, importa il classificatore e i due helper di ricerca:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Il prossimo passo in questo Scikit Python Il tutorial serve a specificare i parametri da regolare. La documentazione ufficiale di XGBoost li elenca tutti. Per il bene di questo Python Nel tutorial di Sklearn si scelgono solo due iperparametri con due valori ciascuno, perché l'addestramento di XGBoost richiede molto tempo e ogni punto aggiuntivo della griglia aumenta l'attesa.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Successivamente, si costruisce una nuova pipeline con il classificatore XGBoost e 600 stimatori. Il parametro n_estimators è a sua volta regolabile e un valore elevato può portare all'overfitting. È possibile provare altri valori, ma si tenga presente che l'operazione può richiedere diverse ore. Tutti gli altri parametri mantengono i valori predefiniti.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
È possibile migliorare la convalida incrociata con il validatore incrociato Stratified K-Folds. Qui vengono utilizzate solo tre fold per velocizzare il calcolo, a scapito della qualità; per risultati migliori, è possibile aumentare il numero di fold a 5 o 10 sulla propria macchina. Il modello viene addestrato su quattro iterazioni.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
La ricerca casuale è pronta, quindi puoi addestrare il modello.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Come potete vedere, XGBoost ottiene risultati migliori rispetto alla precedente regressione logistica.
print("migliori parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
migliori parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Crea DNN con MLPClassifier in scikit-learn
Infine, è possibile addestrare una rete neurale utilizzando direttamente scikit-learn. Il metodo è lo stesso di qualsiasi altro classificatore e l'algoritmo di stima è MLPClassifier.
from sklearn.neural_network import MLPClassifier
La rete sottostante è definita come:
- Adam risolutore
- Funzione di attivazione ReLU
- Alfa = 0.0001
- Dimensione del lotto: 150
- Due strati nascosti rispettivamente con 200 e 100 neuroni
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
È possibile modificare il numero di strati per migliorare il modello.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
Punteggio di regressione DNN: 0.821253
LIME: fidati del tuo modello
Ora che hai un buon modello, ti serve un modo per fidarti di esso. Gli algoritmi di apprendimento automatico, in particolare le foreste casuali e le reti neurali, sono noti come modelli a scatola nera: funzionano, ma nessuno può capire perché.
Tre ricercatori hanno creato uno strumento che mostra come il computer giunge a una previsione. Il loro articolo è “Perché dovrei fidarmi di te?”e l'algoritmo che hanno pubblicato si chiama Local Interpretable Model-Agnostic Explanations (LIME).
Facciamo un esempio. A volte non si sa se una previsione basata sull'apprendimento automatico sia affidabile. Un medico non può accettare una diagnosi solo perché è stata prodotta da un computer, e bisogna sapere se un modello è affidabile prima di metterlo in pratica.
Immaginate di poter capire perché un classificatore ha fatto una determinata previsione, anche per modelli complessi come reti neurali, foreste casuali o macchine a vettori di supporto (SVM) con un kernel arbitrario. Diventa molto più facile fidarsi di una previsione quando le ragioni che la sottendono sono visibili, ed è altrettanto facile decidere quando un modello non è affidabile. LIME vi mostra quali caratteristiche hanno influenzato la decisione del classificatore.
Preparazione dei dati
Ci sono un paio di cose che devi cambiare per eseguire LIME con PythonInnanzitutto, installa Lime nel terminale con il comando `pip install lime`.
Lime utilizza un oggetto LimeTabularExplainer per approssimare il modello localmente. Questo oggetto richiede:
- un set di dati in NumPy formato
- Il nome delle funzionalità: feature_names
- Il nome delle classi: class_names
- L'indice della colonna delle caratteristiche categoriche: categorical_features
- Il nome del gruppo per ogni caratteristica categoriale: categorical_names
Crea il set di treni NumPy
È possibile copiare e convertire facilmente la libreria df_train da pandas a NumPy.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Ottieni il nome della classe
L'etichetta è accessibile tramite unique(). Dovresti vedere:
- "<= 50 K"
- "> 50 K"
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Indicizza le colonne delle caratteristiche categoriali
Utilizza il metodo appreso in precedenza per ottenere il nome di ciascun gruppo. Codifica l'etichetta con LabelEncoder e ripeti l'operazione su ogni caratteristica categoriale.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Ora che il dataset è pronto, è possibile creare i diversi dataset mostrati negli esempi di Scikit-learn qui sotto. I dati vengono trasformati al di fuori della pipeline per evitare errori con LIME: il set di training passato a LimeTabularExplainer deve essere un array NumPy senza stringhe, e il metodo sopra descritto ne ha già prodotto uno.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
È possibile creare la pipeline utilizzando i parametri ottimali individuati da XGBoost.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Riceverai un avviso. Spiega che non è necessario creare un codificatore di etichette prima della pipeline. Se non stai usando LIME, il metodo descritto nella prima parte di questo tutorial sull'apprendimento automatico con Scikit-learn va bene. Altrimenti, mantieni questo approccio: prima crea un dataset codificato, poi applica il codificatore one-hot all'interno della pipeline.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Prima di utilizzare LIME, crea un array NumPy contenente le caratteristiche delle righe classificate erroneamente. Potrai utilizzare questo elenco in seguito per capire cosa ha tratto in inganno il classificatore.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
Successivamente, crei una funzione lambda che recupera la previsione dal modello per i nuovi dati. Ti servirà a breve.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Si converte il dataframe di pandas in un array NumPy.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Ora scegli una famiglia a caso dal set di test e osserva sia la previsione che il procedimento seguito dal computer per giungervi.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
È possibile utilizzare la funzione explainer con explain_instance per esaminare il ragionamento alla base del modello. Il grafico generato è mostrato di seguito.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Il sistema di classificazione ha previsto correttamente questo nucleo familiare: il reddito è effettivamente superiore a 50.
La prima cosa da notare è che il classificatore non è molto sicuro di sé. Prevede un reddito superiore a 50 con una probabilità del 64%, e questo 64% è determinato da plusvalenze e stato civile. Il colore blu contribuisce negativamente alla classe positiva e la linea arancione positivamente.
Il classificatore esita perché il guadagno in conto capitale di questo nucleo familiare è pari a zero, mentre il guadagno in conto capitale è solitamente un buon indicatore di ricchezza. Inoltre, il nucleo familiare lavora meno di 40 ore a settimana. Età, professione e sesso contribuiscono tutti positivamente.
Se lo stato civile fosse stato "celibe/nubile", il classificatore avrebbe previsto un reddito inferiore a 50 (0.64 – 0.18 = 0.46).
Ora prova con un altro nucleo familiare, uno che è stato classificato in modo errato. La tabella esplicativa si trova dopo il codice.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Il classificatore ha previsto un reddito inferiore a 50, il che è errato. Questo nucleo familiare è insolito: non ha né plusvalenze né minusvalenze, la persona è divorziata, ha quasi 60 anni ed è istruita, ovvero education_num > 12. Seguendo il modello generale, il classificatore ha collocato il nucleo familiare al di sotto di 50.
Provate a usare LIME e noterete numerosi errori grossolani da parte del classificatore. Il repository GitHub dell'autore della libreria contiene ulteriore documentazione per la classificazione di immagini e testo.
Riferimento ai comandi di Scikit-learn
Di seguito è riportato un elenco di comandi utili applicabili a scikit-learn versione 0.20 e successive.
| Task | Funzione o classe |
|---|---|
| Creare il set di dati di training/test | train_test_split |
| Costruisci una pipeline | |
| Seleziona le colonne e applica la trasformazione | make_column_transformer |
| Tipo di trasformazione | |
| Standardizzare | StandardScaler |
| Scalatura min-max | MinMaxScaler |
| Normalizzare | Normalizer |
| Imputare i valori mancanti | SimpleImputer |
| Converti categoriale | OneHotEncoder |
| Adattare e trasformare i dati | fit_transform |
| Realizza la conduttura | make_pipeline |
| Modello base | |
| Regressione logistica | Regressione logistica |
| XGBoost | Classificatore XGB |
| Rete neurale | Classificatore MLP |
| Ricerca a griglia | GrigliaRicercaCV |
| Ricerca randomizzata | CV randomizzato di ricerca |