NLTK Tokenize: szavak és mondatok tokenizálója példával
⚡ Okos összefoglaló
Az NLTK Tokenize a nagy szövegeket kisebb egységekre, úgynevezett tokenekre bontja, ami a természetes nyelvi feldolgozás alapvető lépése. Az eszközkészlet a word_tokenize eszközt biztosítja a mondatok szavakra bontásához, a sent_tokenize eszközt pedig a szöveg egyes mondatokra osztásához.

Mi az a tokenizálás?
tokenizálás Az a folyamat, amelynek során nagy mennyiségű szöveget kisebb részekre osztanak, amelyeket tokennek neveznek. Ezek a tokenek nagyon hasznosak a minták megtalálásához, és a szárképzés és a lemmatizálás alaplépésének tekinthetők. A tokenizálás az érzékeny adatelemek nem érzékeny adatelemekkel való helyettesítését is segíti.
A természetes nyelvi feldolgozást olyan építési alkalmazásokhoz használják, mint a szövegosztályozás, intelligens chatbot, szentimentális elemzés, nyelvi fordítás stb. A fent említett cél eléréséhez elengedhetetlen a szövegben található minta megértése.
Egyelőre ne törődj a törzsszóval és a lemmatizálással, hanem tekintsd ezeket a szöveges adatok NLP-vel (természetes nyelvi feldolgozás) történő tisztításának lépéseiként. Az oktatóanyag későbbi részében a szárképzésről és a lemmatizálásról fogunk beszélni. Feladatok, mint pl Szövegbesorolás vagy spamszűrés használja az NLP-t olyan mély tanulási könyvtárakkal együtt, mint a Keras és tenzor áramlás.
A Natural Language eszközkészletnek nagyon fontos NLTK modulja van tokenizálni mondatok, amelyek további almodulokat tartalmaznak
- szó tokenizál
- mondat tokenizálása
A szavak tokenizálása
A módszert használjuk word_tokenize() egy mondatot szavakra bontani. A szótokenizálás kimenete Data Frame-be konvertálható a jobb szövegértés érdekében a gépi tanulási alkalmazásokban. Bemenetként is szolgálhat további szövegtisztítási lépésekhez, mint például az írásjelek eltávolításához, a numerikus karakterek eltávolításához vagy a szárképzéshez. A gépi tanulási modelleknek numerikus adatokra van szükségük a betanításhoz és az előrejelzésekhez. A szavak tokenizálása a szöveg (karakterlánc) numerikus adatokká konvertálásának döntő részévé válik. Kérjük, olvassa el Szavak zsákja vagy CountVectorizer. Kérjük, tekintse meg az alábbi szó tokenize NLTK példát, hogy jobban megértse az elméletet.
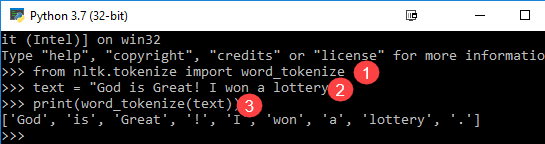
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
Code Magyarázat
- A word_tokenize modult az NLTK könyvtárból importálták.
- A „text” változót két mondattal inicializálják.
- A szöveges változót a word_tokenize modul adja át, és kinyomtatja az eredményt. Ez a modul minden szót írásjelekkel tör meg, amelyeket a kimenetben láthat.
Mondatok tokenizálása
A fentiekhez elérhető almodul a send_tokenize. Nyilvánvaló kérdés lenne a fejedben miért van szükség a mondat tokenizálására, amikor lehetőségünk van szó tokenizálásra. Képzelje el, hogy mondatonként átlagos szavakat kell számolnia, hogyan fogja kiszámítani? Egy ilyen feladat elvégzéséhez az arány kiszámításához mind az NLTK mondatjelzőre, mind az NLTK szójelzőre van szükség. Az ilyen kimenet fontos jellemzője a gépi képzésnek, mivel a válasz numerikus lenne.
Tekintse meg az alábbi NLTK tokenizáló példát, hogy megtudja, miben különbözik a mondat tokenizálás a szavak tokenizálásától.
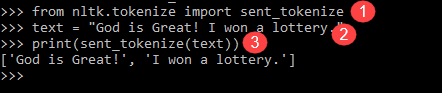
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
Nekünk van 12 szavak és két mondat ugyanarra a bemenetre.
A program magyarázata
- Az előző programhoz hasonló sorban importálta a sent_tokenize modult.
- Ugyanazt a mondatot vettük fel. Az NLTK modul további mondattokenizátora elemezte ezeket a mondatokat és megjeleníti a kimenetet. Nyilvánvaló, hogy ez a függvény minden mondatot megszakít.
A szó tokenizátor felett Python A példák jó beállítási kövek a szó és mondat tokenizálásának mechanikájának megértéséhez.