Word Embedding és Word2Vec példával
⚡ Okos összefoglaló
A Word Embedding és a Word2Vec a szöveget sűrű numerikus vektorokká alakítja, így a gépi tanulási modellek felismerik a hasonló jelentésű szavakat. Ez az anyag bemutatja a technikát, annak CBOW és Skip-Gram architektúráit, aktivációs függvényeit és egy teljes Gensim implementációt valós alkalmazásokhoz.
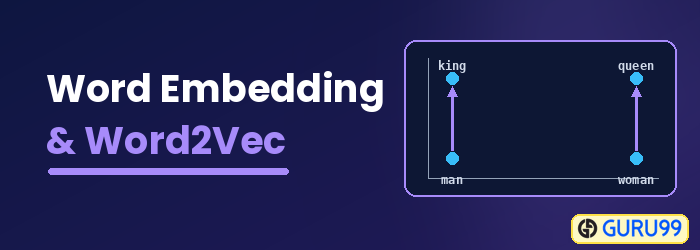
Mi az a Word-beágyazás?
Szó beágyazása egy szóreprezentációs típus, amely lehetővé teszi a gépi tanulási algoritmusok számára, hogy megértsék a hasonló jelentésű szavakat. Ez egy nyelvi modellezési és jellemzőtanulási technika, amely szavakat valós számok vektoraivá képez le neurális hálózatok, valószínűségi modellek vagy dimenziócsökkentés segítségével a szavak együttes előfordulási mátrixán. Néhány szóbeágyazási modell a Word2vec (Google), a GloVe (Stanford) és a fastText (Facebook).
A szóbeágyazást elosztott szemantikai modellnek, elosztott reprezentált modellnek, szemantikus vektortérnek vagy vektortér-modellnek is nevezik. Ezen nevek olvasása közben a következő szavakkal találkozhatunk: szemantikus, ami a hasonló szavak egy kategóriába sorolását jelenti. Például az olyan gyümölcsöket, mint az alma, a mangó és a banán, közel kell egymáshoz helyezni, míg a könyveket távol kell elhelyezni ezektől a szavaktól. Tágabb értelemben a szavak beágyazása a gyümölcsök egy olyan vektorát hozza létre, amely messze van a könyvek vektoros ábrázolásától.
Hol használják a Word-beágyazást?
A Word beágyazása segít a jellemzők generálásában, a dokumentumok klaszterezésében, a szöveg osztályozásában és a természetes nyelvi feldolgozási feladatokban. Soroljuk fel ezeket az alkalmazásokat, és beszéljük meg mindegyiket.
- Számíts ki hasonló szavakat: A szóbeágyazást arra használják, hogy hasonló szavakat javasoljanak a predikciós modellben szereplő szóhoz. Emellett eltérő szavakat, valamint a leggyakoribb szavakat is javasolja.
- Hozzon létre egy csoportot kapcsolódó szavakból: Szemantikai csoportosításra használják.ping, amely a hasonló tulajdonságokkal rendelkező dolgokat egy csoportba sorolja, és messze eltakarja az eltérő elemeket.
- A szövegbesorolás funkciója: A szöveget vektortömbökbe képezi le, amelyeket betanítás és predikció céljából betáplál a modellbe. A szövegalapú osztályozó modellek nem taníthatók karakterláncokon, így ez a módszer a szöveget géppel tanítható formává alakítja. Szemantikaépítő funkciói tovább segítik a szövegalapú osztályozást.
- Dokumentum klaszterezés: Ez egy másik alkalmazás, ahol a Word Embedding és a Word2vec széles körben használatos.
- Természetes nyelvfeldolgozás: Sok olyan alkalmazás van, ahol a szavak beágyazása hasznos és felülmúlja a funkciópéldányokat.tracciós fázisok, mint például a szófaji címkézés, a szentimentelemzés és a szintaktikai elemzés.
Most, hogy megértette, hol alkalmazzák a szóbeágyazást, nézzük meg a legnépszerűbb modellt, amelyet ezeknek a beágyazásoknak a létrehozására használnak.
Mi az a Word2vec?
Word2vec egy olyan technika vagy modell, amely szóbeágyazásokat hoz létre a jobb szóreprezentáció érdekében. Ez egy természetes nyelvi feldolgozási módszer, amely nagyszámú pontos szintaktikai és szemantikai szókapcsolatot rögzít. Ez egy sekély, kétrétegű neurális hálózat, amely képes szinonim szavak felismerésére, és további szavakat javasolni a részmondatokhoz, miután betanították.
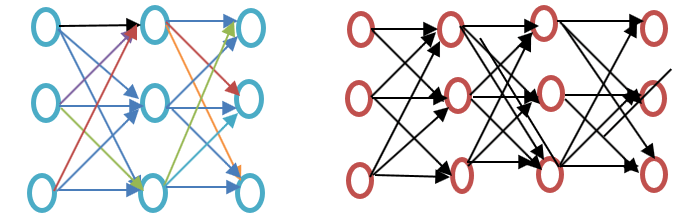
Mielőtt továbbmennénk, kérjük, tekintse meg a sekély és a mély neurális hálózat közötti különbséget, ahogy az az alábbi Word-beágyazási példa diagramon látható:
A sekély neurális hálózat csak egy rejtett rétegből áll a bemenet és a kimenet között, míg egy mély neurális hálózat több rejtett réteget tartalmaz a bemenet és a kimenet között. A bemenet csomópontoknak van kitéve, míg a rejtett réteg, akárcsak a kimeneti réteg, neuronokat tartalmaz.
A Word2vec egy kétrétegű hálózat, ahol van egy bemenet, egy rejtett réteg és egy kimenet.
A Word2vec-et Tomas Mikolov vezette kutatócsoport fejlesztette ki. GoogleA Word2vec jobb és hatékonyabb, mint a látens szemantikai elemzési modell.
Miért Word2vec?
A Word2vec módszer a szavakat vektortérben reprezentálja. A szavak vektorok formájában vannak ábrázolva, és az elhelyezés úgy történik, hogy a hasonló jelentésű szavak együtt jelenjenek meg, az eltérő szavak pedig távol helyezkedjenek el egymástól. Ezt szemantikai kapcsolatnak is nevezik. A neurális hálózatok nem értik a szöveget, ehelyett csak a számokat értik. A szóbeágyazás lehetővé teszi a szöveg numerikus vektorrá konvertálását.
A Word2vec rekonstruálja a szavak nyelvi kontextusát. Mielőtt továbbmennénk, nézzük meg, mi is a nyelvi kontextus. Általános esetben, amikor beszélünk vagy írunk a kommunikációhoz, mások megpróbálják kitalálni a mondat célját. Például: „Mennyi India hőmérséklete?” Itt a kontextus az, hogy a felhasználó tudni akarja „India hőmérsékletét”. Röviden, a mondat fő célja a kontextus. A beszélt vagy írott nyelvet körülvevő szavak vagy mondatok segítenek a kontextus jelentésének meghatározásában. A Word2vec ezeken a kontextusokon keresztül tanulja meg a szavak vektoros reprezentációját.
Mit csinál a Word2vec?
Word beágyazás előtt
Fontos tudni, hogy melyik megközelítést használták a szóbeágyazás előtt, és mik a hátrányai, majd meglátjuk, hogyan küszöböli ki ezeket a hátrányokat a Word2vec megközelítéssel történő szóbeágyazás. Végül rátérünk arra, hogyan működik a Word2vec, mert fontos megérteni a működését.
A látens szemantikai elemzés megközelítése
Ez a megközelítés volt az, amelyet a szóbeágyazások előtt alkalmaztak. A szózsák koncepcióját alkalmazta, ahol a szavakat kódolt vektorok formájában ábrázolták. Ez egy ritka vektoros reprezentáció, ahol a dimenzió megegyezik a szókincs méretével. Ha a szó előfordul a szótárban, akkor megszámolja a program; egyébként nem. További információkért lásd az alábbi programot.
Word2vec példa

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
output:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Magyarázat
- A CountVectorizer egy modul, amely a szavak illeszkedése alapján tárolja a szókincset. Ez az sklearn-ből importált.
- Készítse el az objektumot a CountVectorizer osztály használatával.
- Írd be a listába azokat az adatokat, amelyeket a CountVectorizerbe kell illeszteni.
- Az adatok elférnek a CountVectorizer osztályból létrehozott objektumban.
- A szókincs alapján szózsákos megközelítést alkalmazunk az adatokban lévő szavak számlálására. Ha egy szó vagy token nem áll rendelkezésre a szókincsben, akkor az indexpozíció nullára van állítva.
- Az 5. sorban található x változót tömbbé alakítjuk (egy x-hez elérhető metódus). Ez visszaadja a 3. sorban megadott mondatban vagy listában szereplő egyes tokenek darabszámát.
- Ez azokat a jellemzőket mutatja, amelyek a szókincs részét képezik, amikor a 4. sorban található adatok felhasználásával illesztik.
A látens szemantikai megközelítésben a sor az egyedi szavakat jelöli, míg az oszlop azt, hogy a szó hányszor jelenik meg a dokumentumban. Ez a szavak ábrázolása egy dokumentummátrix formájában. A kifejezés gyakorisága-inverz dokumentumgyakoriság (TF-IDF) módszerrel számolják a szavak gyakoriságát a dokumentumban, ami a kifejezés dokumentumban való gyakoriságának osztva a kifejezés teljes korpuszban való gyakoriságával.
A Bag of Words módszer hiányossága
- Figyelmen kívül hagyja a szavak sorrendjét; például ez rossz = rossz ez.
- Figyelmen kívül hagyja a szavak kontextusát. Tegyük fel, hogy ezt a mondatot írjuk: „Szeretette a könyveket. A műveltség a könyvekben a legjobb.” Ez két vektort hozna létre: egyet a „Szeretette a könyveket” és egy másikat a „A műveltség a könyvekben a legjobb” kifejezéshez. Mindkettőt ortogonálisnak tekintené, ami függetlenné teszi őket, de valójában kapcsolatban állnak egymással.
Ezen korlátozások leküzdésére fejlesztették ki a szóbeágyazást, és a Word2vec az egyik megközelítés, amelyet ennek megvalósítására használnak.
Hogyan működik a Word2vec?
A Word2vec egy szót úgy tanul meg, hogy megjósolja a környező kontextust. Vegyük például a „He” szót. szeret Futball."
Ki akarjuk számolni a szó Word2vec értékét: szeret.
Tegyük fel:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
A szó szeret A korpuszban található minden egyes szó felett mozog. A szavak közötti szintaktikai és szemantikai kapcsolatokat is kódolja. Ez segít a hasonló és analóg szavak megtalálásában.
A szó összes véletlenszerű jellemzője szeret kiszámításra kerülnek. Ezeket a jellemzőket a szomszédos vagy kontextusszavakhoz képest módosítják vagy frissítik egy Vissza szaporítás módszer.
A tanulás egy másik módja az, hogy ha két szó kontextusa hasonló, vagy két szó hasonló jellemzőkkel rendelkezik, akkor az ilyen szavak rokonok.
Word2vec Architectúra
A Word2vec két architektúrát használ:
- Folyamatos Szavak Táskája (CBOW)
- Skip-gram
Mielőtt továbbmennénk, vitassuk meg, miért fontosak ezek az architektúrák vagy modellek a szóreprezentáció szempontjából. A szóreprezentáció tanulása lényegében felügyelet nélküli, de a modell betanításához célok/címkék szükségesek. A Skip-gram és a CBOW a felügyelet nélküli reprezentációt felügyelt formává alakítja a modell betanításához.
A CBOW-ban az aktuális szót a környező kontextusablakok ablaka alapján jelzi előre. Például ha wi-1, Wi-2, Wi + 1, Wi + 2 szavakat vagy szövegkörnyezetet kapunk, ez a modell w-t biztosíti.
A Skip-Gram a CBOW ellentéteként működik, ami azt jelenti, hogy a szóból megjósolja az adott sorozatot vagy kontextust. A példa megfordításával jobban megérthetjük. Ha wi ha adott, ez megjósolja a kontextust, vagyis wi-1, Wi-2, Wi + 1, Wi + 2.
A Word2vec lehetőséget biztosít a CBOW (Continuous Bag of Words) és a skip-gram közötti választásra. Ezeket a paramétereket a modell betanítása során adjuk meg. Lehetőség van negatív mintavételezés vagy hierarchikus softmax réteg használatára.
Folyamatos Szavak zsákja
Rajzoljunk egy egyszerű Word2vec példadiagramot, hogy megértsük a folytonos szózsák architektúrát.

Számítsuk ki az egyenleteket matematikailag! Tegyük fel, hogy V a szókincs mérete, N pedig a rejtett réteg mérete. A bemenet definíciója: { xi-1, xi-2, xi + 1, xi + 2 }. A súlymátrixot a V * N szorzásával kapjuk. Egy másik mátrixot kapunk a bemeneti vektor és a súlymátrix szorzásával. Ez a következő egyenlettel is megérthető.
h = xitW
ahol xit és W rendre a bemeneti vektor és a súlymátrix.
A szövegkörnyezet és a következő szó közötti egyezés kiszámításához kérjük, tekintse meg az alábbi egyenletet.
u = előrejelzettreprezentáció * h
ahol az előrejelzett reprezentációt a fenti egyenletben szereplő modellből kapjuk.
Skip-Gram modell
A Skip-Gram megközelítést arra használják, hogy egy bemeneti szó alapján mondatot jósoljanak meg. A jobb megértés érdekében rajzoljuk meg az alábbi Word2vec példában látható ábrát.

Ez a Continuous Bag of Words modell fordítottjának tekinthető, ahol a bemenet a szó, a modell pedig a kontextust vagy a szekvenciát biztosítja. Azt is megállapíthatjuk, hogy a cél a bemenetre kerül, és a kimeneti réteg többször replikálódik, hogy elférjen a kiválasztott számú kontextusszó. Az összes kimeneti rétegből származó hibavektort összegzik a súlyok beállításához egy visszaterjesztési módszerrel.
Melyik modellt válasszuk?
A CBOW többszörösen gyorsabb, mint a skip-gram, és jobb gyakoriságot biztosít a gyakori szavakhoz, míg a skip-gram kis mennyiségű betanítási adatot igényel, és még a ritka szavakat vagy kifejezéseket is ábrázolja. Az alábbi táblázat egy pillantással összehasonlítja a két architektúrát.
| Aspect | CBOW | Skip-Gram |
|---|---|---|
| Jóslás | A szövegkörnyezetből jósolja meg a célszót | A célzott szóból megjósolja a kontextust |
| Képzési sebesség | Gyorsabb | lassabb |
| Gyakori szavak | Nagyobb pontosság | Alacsonyabb pontosság |
| Ritka szavak | Gyengébb képviselet | Erősebb képviselet |
| Képzési adatok | Több adatra van szükség | Kevesebb adattal működik |
A Word2vec és az NLTK kapcsolata
NLTK a Természetes Language Toolkészlet. Szöveg előfeldolgozására használják. Különböző műveleteket lehet vele végrehajtani, például szófaji címkézést, lemmatizálást, szótőzés elvégzését, stopszavak eltávolítását, valamint ritka vagy legkevésbé használt szavak eltávolítását. Segít a szöveg megtisztításában, valamint a hatékony szavakból jellemzők előkészítésében. Másrészt a Word2vec szemantikai (szorosan összefüggő elemek) és szintaktikai (szekvencia) egyeztetésre szolgál. A Word2vec segítségével hasonló szavakat, eltérő szavakat találhatunk, dimenziócsökkentést végezhetünk és sok mást. A Word2vec egy másik fontos funkciója, hogy a szöveg magasabb dimenziós reprezentációját alacsonyabb dimenziós vektorokká alakítja.
Hol használható az NLTK és a Word2vec?
Ha a fent említett általános célú feladatokat kell elvégezni, mint például a tokenizálás, a POS-címkézés és az elemzés, akkor az NLTK-t kell választani, míg a szavak kontextus, témamodellezés vagy dokumentum-hasonlóság szerinti előrejelzéséhez a Word2vec-et kell használni.
NLTK és Word2vec kapcsolata kód segítségével
Az NLTK és a Word2vec együttesen használható hasonló szóreprezentációk vagy szintaktikai egyezések keresésére. Az NLTK eszközkészlettel számos, az NLTK-val érkező csomag betölthető, és egy modell is létrehozható a Word2vec segítségével. Ez aztán valós idejű szavakon tesztelhető. Nézzük meg a kettő kombinációját a következő kódban. A további feldolgozás előtt kérjük, tekintse meg az NLTK által biztosított korpuszokat. Letöltheti a következő paranccsal:
nltk(nltk.download('all'))

Kérjük, tekintse meg a képernyőképet a kódhoz.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

output:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Magyarázat Code
- Az nltk könyvtár importálva van, ahonnan letöltheted az abc korpuszt, amelyet a következő lépésben fogunk használni.
- A Gensim importálva van. Ha a Gensim Word2vec nincs telepítve, kérjük, telepítse a „pip3 install gensim” paranccsal. Lásd az alábbi képernyőképet.

- Importálja az nltk.download('abc') használatával letöltött abc korpuszt.
- Add át a fájlokat mondatokként a Gensim segítségével importált Word2vec modellnek.
- A szókincset változó formájában tároljuk.
- A modellt a minta szón tesztelik. tudomány, mivel ezek a fájlok a tudománnyal kapcsolatosak.
- Itt a modell a „tudomány” hasonló szót jósolja meg.
Aktivátorok és Word2Vec
Egy neuron aktivációs függvénye meghatározza az adott neuron kimenetét egy bemeneti halmaz alapján. Biológiailag az agyunk aktivitása inspirálja, ahol a különböző neuronok különböző ingerekre aktiválódnak. Értsük meg az aktivációs függvényt a következő ábra segítségével.

Itt x1, x2, … x4 a neurális hálózat csomópontjai.
A w1, w2 és w3 a csomópontok súlyai.
Az összes súly és csomópontérték összegzése (Σ) aktivációs függvényként működik.
Miért az aktiválási funkció?
Ha nem használunk aktivációs függvényt, a kimenet lineáris lenne, de egy lineáris függvény funkcionalitása korlátozott. Az olyan összetett funkciók eléréséhez, mint az objektumészlelés, a képosztályozás, a típus...ping szöveg hanggal történő feldolgozásához és sok más nemlineáris kimenethez aktiválási függvényre van szükség.
Hogyan történik az aktiválási réteg kiszámítása a szóbeágyazásban (Word2vec)
A Softmax réteg (normalizált exponenciális függvény) az a kimeneti rétegbeli függvény, amely aktiválja vagy elindítja az egyes csomópontokat. Egy másik alkalmazott megközelítés a hierarchikus softmax, ahol a komplexitást az O(log2V), míg a softmaxban ez O(V), ahol V a szókincs mérete. A kettő közötti különbség a hierarchikus softmax réteg komplexitásának csökkentése. A működésének megértéséhez tekintse meg az alábbi Word beágyazási példát:

Tegyük fel, hogy ki akarjuk számítani a szó megfigyelésének valószínűségét szerelem adott kontextusban. A gyökérből a levélcsomópontba vezető áramlás először a 2., majd az 5. csomópontba mozog. Tehát, ha a szókincs mérete 8, akkor csak három számításra van szükség. Ez lehetővé teszi egy szó valószínűségének kiszámításának felbontását (szerelem).
Milyen egyéb lehetőségek állnak rendelkezésre a Hierarchical Softmaxon kívül?
Általános értelemben a rendelkezésre álló szóbeágyazási lehetőségek a következők: differenciált Softmax, CNN-Softmax, fontossági mintavételezés, adaptív fontossági mintavételezés, zajkontrasztív becslés, negatív mintavételezés, önnormalizálás és ritka normalizálás.
Konkrétan a Word2vec-ről szólva, negatív mintavételezéssel rendelkezünk.
A negatív mintavételezés egy módja a tanulóadatok mintavételezésének. Ez némileg hasonlít a sztochasztikus gradiens süllyedés módszeréhez, de van némi különbség. A negatív mintavételezés csak negatív tanulópéldákat keres. Zaj kontrasztív becslésen alapul, és véletlenszerűen mintavételezi a kontextuson kívüli szavakat. Ez egy gyors tanulómódszer, és véletlenszerűen választja ki a kontextust. Ha a jósolt szó a véletlenszerűen kiválasztott kontextusban jelenik meg, akkor mindkét vektor közel van egymáshoz.
Milyen következtetést lehet levonni?
Az aktivátorok ugyanúgy aktiválják a neuronokat, mint ahogy a mi neuronjaink aktiválódnak külső ingerek hatására. A Softmax réteg az egyik kimeneti rétegbeli függvény, amely szóbeágyazások esetén aktiválja a neuronokat. A Word2vec-ben olyan opciók állnak rendelkezésre, mint a hierarchikus softmax és a negatív mintavételezés. Aktivátorok segítségével lineáris függvényeket nemlineáris függvényekké alakíthatunk, és ilyen függvények segítségével komplex gépi tanulási algoritmusok valósíthatók meg.
Mi az a Gensim?
Gensim egy nyílt forráskódú témamodellező és természetes nyelvi feldolgozó eszköztár, amely a Python és a Cython. A Gensim eszközkészlet lehetővé teszi a felhasználók számára a Word2vec importálását témamodellezéshez, hogy felfedezzék a szövegtörzs rejtett szerkezetét. A Gensim nemcsak a Word2vec, hanem a Doc2vec és a FastText implementációját is biztosítja.
Ez a rész a Word2vec-re összpontosít, így a jelenlegi témánál maradunk.
A Word2vec implementálása a Gensim használatával
Eddig arról beszéltünk, hogy mi is az a Word2vec, milyen architektúrái vannak, miért váltunk a szavakból álló zsákról a Word2vec-re, milyen a Word2vec és az NLTK kapcsolata az élő kóddal, valamint milyen aktiválási függvények működnek.
Az alábbiakban lépésről lépésre bemutatjuk a Word2vec megvalósítását a Gensim használatával:
1. lépés) Adatgyűjtés
Bármely gépi tanulási modell vagy természetes nyelvi feldolgozás megvalósításának első lépése az adatgyűjtés.
Kérjük, figyelje meg az adatokat egy intelligens chatbot felépítéséhez, amint az az alábbi Gensim Word2vec példában látható.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Íme, amit az adatokból megértettünk:
- Ez az adat három dolgot tartalmaz: címkét, mintát és válaszokat. A címke a szándék (mi a vita témája).
- Az adatok JSON formátumban vannak.
- A minta egy olyan kérdés, amelyet a felhasználók feltesznek a botnak.
- A válaszok azok a válaszok, amelyeket a chatbot ad a megfelelő kérdésre/mintára.
2. lépés) Adatok előfeldolgozása
Nagyon fontos a nyers adatok feldolgozása. Ha megtisztított adatokat adunk a géphez, akkor a modell pontosabban reagál, és hatékonyabban tanulja meg az adatokat.
Ez a lépés magában foglalja a stopszavak, a szótőzésből eredő szavak, a felesleges szavak stb. eltávolítását. Mielőtt továbblépnénk, fontos betölteni az adatokat és adatkeretté konvertálni azokat. Ehhez lásd az alábbi kódot.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Magyarázat Code:
- Mivel az adatok JSON formátumúak, a JSON importálásra kerül.
- A fájl a változóban tárolódik.
- A fájl megnyílik és betöltődik az adatváltozóba.
Most, hogy az adatok importálása megtörtént, itt az ideje, hogy adatkeretté alakítsuk őket. A következő lépéshez lásd az alábbi kódot.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Magyarázat Code:
1. Az adatokat a fent importált pandák segítségével adatkeretté alakítjuk.
2. Az oszlopmintákban található listát karakterlánccá alakítja.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Magyarázat:
1. Az angol stopszavak importálása az nltk eszközkészlet stop-word moduljával történik.
2. A szöveg összes szavát kisbetűssé alakítjuk egy for feltétel és egy lambda függvény segítségével. A Lambda funkció egy névtelen funkció.
3. Az adatkeretben található szöveg összes sorát ellenőrzi a rendszer karakterlánc-írásjelek szempontjából, és ezeket szűri.
4. A számokhoz vagy pontokhoz hasonló karaktereket reguláris kifejezéssel távolítjuk el.
5. Digit-k eltávolításra kerülnek a szövegből.
6. Ebben a szakaszban a stop szavakat eltávolítjuk.
7. A szavakat most szűrtük, és lemmatizáció segítségével eltávolítottuk ugyanazon szó különböző alakjait. Ezzel befejeztük az adatok előfeldolgozását.
output:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
3. lépés) Neurális hálózat kiépítése Word2vec használatával
Most itt az ideje, hogy felépítsünk egy modellt a Gensim Word2vec modul segítségével. Importálnunk kell a Word2vec-et a Gensimből. Tegyük meg ezt, majd felépítjük, és a végső szakaszban valós idejű adatokon ellenőrizzük a modellt.
from gensim.models import Word2Vec
Most már sikeresen felépíthetjük a modellt a Word2Vec használatával. A következő kódsorban megtudhatja, hogyan hozhat létre modellt a Word2Vec használatával. A modell szövege lista formájában kerül átadásra, ezért az adatkeretből származó szöveget az alábbi kód segítségével listává alakítjuk.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Magyarázat Code:
1. Létrehoztam a bigger_list-et, ahová a belső lista hozzáfűzésre kerül. Ez a formátum kerül a Word2Vec modellbe.
2. Megvalósítunk egy ciklust, és az adatkeret minták oszlopának minden bejegyzését iteráljuk.
3. Az oszlopminták minden elemét felosztjuk és a belső li listában tároljuk.
4. A belső listát a külső listával egészítjük ki.
5. Ez a lista a Word2Vec modellhez tartozik. Nézzük meg az itt megadott paraméterek egy részét.
Min_count: Figyelmen kívül hagyja az összes olyan szót, amelynek összesített gyakorisága ennél alacsonyabb.
Méret: Megmondja a szóvektorok dimenzióját.
munkások: Ezek a szálak a modell betanításához.
Vannak más lehetőségek is, és ezek közül néhány fontosabbat az alábbiakban ismertetünk.
ablak: Maximális távolság a mondaton belül az aktuális és a várható szó között.
Sg: Ez egy tanulóalgoritmus: 1 az átugrásos grammhoz és 0 a folytonos szókészlethez. Ezeket fentebb részletesen tárgyaltuk.
Hs: Ha ez 1, akkor hierarchikus softmaxot használunk a betanításhoz, ha 0, akkor negatív mintavételezést alkalmazunk.
Alpha: Kezdeti tanulási ráta.
Az alábbiakban jelenítsük meg a végső kódot:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
4. lépés) Modell mentése
A modell bin és modellfájl formájában menthető. A Bin bináris formátumú. A modell mentéséhez lásd az alábbi sorokat.
model.save("word2vec.model") model.save("model.bin")
A fenti kód magyarázata
1. A modell .model fájl formájában kerül mentésre.
2. A modell .bin fájl formájában kerül mentésre.
Ezt a modellt valós idejű tesztelésre fogjuk használni, például hasonló szavak, eltérő szavak és leggyakoribb szavak vizsgálatára.
5. lépés) Modell betöltése és valós idejű tesztelés
A modell betöltése az alábbi kóddal történik:
model = Word2Vec.load('model.bin')
Ha ki szeretnéd nyomtatni belőle a szókincset, akkor a következő paranccsal teheted meg:
vocab = list(model.wv.vocab)
Kérjük, nézze meg az eredményt:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
6. lépés) A legtöbb hasonló szó ellenőrzése
Valósítsuk meg a dolgokat a gyakorlatban:
similar_words = model.most_similar('thanks') print(similar_words)
Kérjük, nézze meg az eredményt:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
7. lépés) Nem egyezik a megadott szavakkal
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Megadtuk a szavakat 'Viszlát később, köszönöm a látogatást'Ez kinyomtatja a szavak közül a legkülönbözőbb szót. Futtassuk le a kódot, és keressük meg az eredményt.
Az eredmény a fenti kód végrehajtása után:
Thanks
8. lépés) Keresse meg a hasonlóságot két szó között
Ez két szó hasonlóságának valószínűségét adja meg az eredményként. Az alábbi kódrészlet bemutatja, hogyan kell végrehajtani ezt a szakaszt.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
A fenti kód eredménye a következő:
0.13706
Hasonló szavakat a következő kód futtatásával találhatsz:
similar = model.similar_by_word('kind') print(similar)
A fenti kód kimenete:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]