Apache Flume Tutorial: Vad är, Architecture & Hadoop Exempel
⚡ Smart sammanfattning
Apache Flume är en distribuerad tjänst för att samla in, aggregera och flytta stora volymer loggdata till HDFS, byggd kring agenter som länkar samman en källa, en kanal och en sink.

Vad är Apache Flume i Hadoop?
Apache Flume är ett pålitligt och distribuerat system för att samla in, aggregera och flytta stora mängder loggdata. Det har en enkel men flexibel arkitektur baserad på strömmande dataflöden. Apache Flume används för att samla in loggdata som finns i loggfiler från webbservrar och aggregera den till HDFS för analys.
Flume i Hadoop stöder flera källor, inklusive:
- 'tail' (som överför data från en lokal fil och skriver den till HDFS via Flume, liknande Unix-kommandot 'tail')
- Systemloggar
- Apache log4j (vilket möjliggör Java applikationer för att skriva händelser till filer i HDFS via Flume).
Den nuvarande utgåvan är Ränna 1.11.0, publicerad den 25 oktober 2022 och tillgänglig från Apache Flume nedladdningssidaDenna genomgång skrevs mot version 1.4.0, så flera steg nedan innehåller en anmärkning där en aktuell version beter sig annorlunda.
Flume Architecture
Ett Flume-medel är ett JVM process med tre komponenter – rännkälla, rännkanal och rännsänka – genom vilka händelser fortplantas efter att ha initierats vid en extern källa. Diagrammet nedan visar hur de är kopplade.
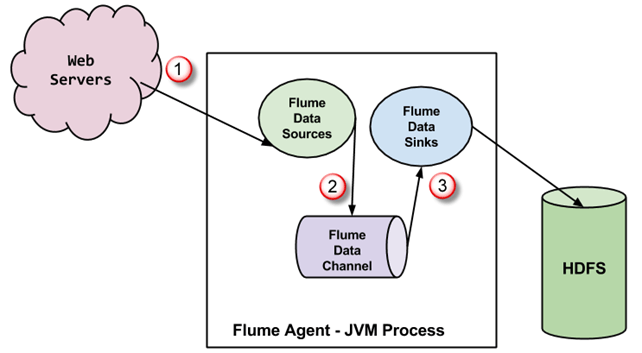
- Händelserna som genereras av den externa källan (en webbserver) förbrukas av Flume-källan. Den externa källan skickar händelser till Flume-källan i ett format som målkällan känner igen.
- Flume-källan tar emot en händelse och lagrar den i en eller flera kanaler. Kanalen fungerar som ett minne som lagrar händelsen tills den förbrukas av Flume-sinken. Denna kanal kan använda ett lokalt filsystem för att lagra dessa händelser.
- Flume-sinken tar bort händelsen från en kanal och lagrar den i ett externt datalager, till exempel HDFS. Det kan finnas flera Flume-agenter, i vilket fall Flume-sinken vidarebefordrar händelsen till Flume-källan för nästa agent i flödet.
Några viktiga funktioner hos Flume
- Flume har en flexibel design baserad på strömmande dataflöden. Den är feltolerant och robust, med flera redundans- och återställningsmekanismer. Flume erbjuder olika nivåer av tillförlitlighet, inklusive "leverans på bästa sätt" och 'end-to-end-leverans'. Bästa leverans tolererar inte något fel på Flume-noden, medan end-to-end leverans garanterar leverans även vid flera nodfel.
- Flume överför data mellan källor och sänkor. Denna datainsamling kan antingen vara schemalagd eller händelsestyrd. Flume har sin egen frågebehandlingsmotor, vilket gör det enkelt att transformera varje ny databatch innan den flyttas till den avsedda sänken.
- Möjligt Flume sjunker inkluderar HDFS och HBaseFlume kan också transportera händelsedata såsom nätverkstrafikdata, data som genereras av sociala medier och e-postmeddelanden.
Installation av flume, bibliotek och källkod
Innan vi börjar med själva processen, se till att du har Hadoop installerat; om inte, arbeta dig igenom hur man installerar Hadoop först. Ändra användaren till 'hduser' (det ID som användes vid konfiguration av Hadoop; du kan byta till det användar-ID som användes under din egen Hadoop-konfiguration).

Steg 1) Skapa en ny katalog med namnet 'FlumeTutorial'.
sudo mkdir FlumeTutorial
- Ge läs-, skriv- och körbehörigheter.
sudo chmod -R 777 FlumeTutorial
- Kopiera filerna MyTwitterSource.java och MyTwitterSourceForFlume.java in i den här katalogen.
Ladda ner indatafiler härifrån
Kontrollera filbehörigheterna för alla dessa filer, enligt nedan, och bevilja läsbehörighet om den saknas.

Steg 2) Ladda ner 'Apache Flume' från https://flume.apache.org/download.html.
Apache Flume 1.4.0 har använts i denna Flume-handledning.

Klicka sedan vidare till en spegel.

Steg 3) Kopiera den nedladdade tarball-filen till valfri katalog och t.ex.tracinnehållet med följande kommando.
sudo tar -xvf apache-flume-1.4.0-bin.tar.gz

Detta skapar en ny katalog med namnet apache-flume-1.4.0-bin och extracts filerna till den. Den katalogen kallas i resten av artikeln.
Steg 4) Installation av Flume-biblioteket. Kopiera twitter4j-core-4.0.1.jar, flume-ng-configuration-1.4.0.jar, flume-ng-core-1.4.0.jar och flume-ng-sdk-1.4.0.jar till
/lib/
En eller alla kopierade JAR-filer kan ha körningsbehörigheten uppsatt, vilket kan orsaka problem med kompileringen av kod, så återkalla den. I mitt fall hade twitter4j-core-4.0.1.jar körningsbehörigheten. Jag återkallade den enligt nedan.
sudo chmod -x twitter4j-core-4.0.1.jar

Efter detta ger kommandot nedan alla läsbehörighet på twitter4j-core-4.0.1.jar.
sudo chmod +rrr /usr/local/apache-flume-1.4.0-bin/lib/twitter4j-core-4.0.1.jar
Observera att jag laddade ner twitter4j-core-4.0.1.jar från Maven-arkivetoch alla Flume JAR-filer, dvs. flume-ng-*-1.4.0.jar, från org.apache.flume-artefakterna.
Ladda data från Twitter med Flume
Steg 1) Gå till katalogen som innehåller källkodsfilerna.
Steg 2) Ställ in CLASSPATH till att innehålla /lib/* och ~/FlumeTutorial/flume/mytwittersource/*.
export CLASSPATH="/usr/local/apache-flume-1.4.0-bin/lib/*:~/FlumeTutorial/flume/mytwittersource/*"

Steg 3) Kompilera källkoden med kommandot nedan.
javac -d . MyTwitterSourceForFlume.java MyTwitterSource.java

Steg 4) Skapa en JAR-fil. Skapa först en Manifest.txt-fil med en textredigerare du väljer och lägg till raden nedan i den.
Main-Class: flume.mytwittersource.MyTwitterSourceForFlume
Här är flume.mytwittersource.MyTwitterSourceForFlume namnet på huvudklassen. Observera att du måste trycka på Enter-tangenten i slutet av den här raden, som visas nedan.

Skapa nu JAR-filen 'MyTwitterSourceForFlume.jar' enligt följande.
jar cfm MyTwitterSourceForFlume.jar Manifest.txt flume/mytwittersource/*.class

Steg 5) Kopiera denna JAR till /lib/.
sudo cp MyTwitterSourceForFlume.jar <Flume Installation Directory>/lib/

Steg 6) Gå till Flumes konfigurationskatalog, /konf.
Om flume.conf inte finns, kopiera flume-conf.properties.template och byt namn på den till flume.conf.
sudo cp flume-conf.properties.template flume.conf

Om flume-env.sh inte finns, kopiera flume-env.sh.template och byt namn på den till flume-env.sh.
sudo cp flume-env.sh.template flume-env.sh

Skapa en Twitter-applikation
Läs detta först. V1.1-strömningen statuses/filter slutpunkten som twitter4j 4.0.1 behöver togs bort den 9 mars 2023, och API v2-filtrerade strömmen som ersatte den, nu på utvecklare.x.com, ligger bakom en betald nivå. Behandla skärmarna nedan som ett anpassat källkodsmönster och peka sedan samma agent mot en fil, exec eller Kafka-källkod.
Steg 1) Skapa en Twitter-applikation genom att logga in på utvecklarportalen.


Steg 2) Gå till "Mina program" (det här alternativet visas när du klickar på "Ägget"-knappen i det övre högra hörnet).

Steg 3) Skapa en ny applikation genom att klicka på "Skapa ny app".
Steg 4) Fyll i ansökningsuppgifterna genom att ange ansökans namn, en beskrivning och en webbplats. Du kan läsa informationen under varje inmatningsruta.
Steg 5) Scrolla ner på sidan, acceptera villkoren genom att markera "Ja, jag godkänner" och klicka på knappen "Skapa din Twitter-applikation".

Steg 6) I fönstret för den nyskapade applikationen, gå till fliken "API-nycklar", skrolla ner på sidan och klicka på knappen "Skapa min åtkomsttoken".


Steg 7) Uppdatera sidan.
Steg 8) Klicka på "Testa OAuth". Detta visar programmets "OAuth"-inställningar.

Steg 9) Ändra 'flume.conf' med dessa OAuth-inställningar. Stegen för att ändra 'flume.conf' ges nedan.

Vi måste kopiera konsumentnyckeln, konsumenthemligheten, åtkomsttoken och åtkomsttokenhemligheten för att kunna uppdatera 'flume.conf'.
Obs: Dessa värden tillhör användaren och är därför konfidentiella, så de bör inte delas.
Ändra 'flume.conf'-filen
Steg 1) Öppna 'flume.conf' i skrivläge och ange värden för parametrarna nedan.
sudo gedit flume.conf
Kopiera innehållet nedan.
MyTwitAgent.sources = Twitter MyTwitAgent.channels = MemChannel MyTwitAgent.sinks = HDFS MyTwitAgent.sources.Twitter.type = flume.mytwittersource.MyTwitterSourceForFlume MyTwitAgent.sources.Twitter.channels = MemChannel MyTwitAgent.sources.Twitter.consumerKey = <Copy consumer key value from Twitter App> MyTwitAgent.sources.Twitter.consumerSecret = <Copy consumer secret value from Twitter App> MyTwitAgent.sources.Twitter.accessToken = <Copy access token value from Twitter App> MyTwitAgent.sources.Twitter.accessTokenSecret = <Copy access token secret value from Twitter App> MyTwitAgent.sources.Twitter.keywords = guru99 MyTwitAgent.sinks.HDFS.channel = MemChannel MyTwitAgent.sinks.HDFS.type = hdfs MyTwitAgent.sinks.HDFS.hdfs.path = hdfs://localhost:54310/user/hduser/flume/tweets/ MyTwitAgent.sinks.HDFS.hdfs.fileType = DataStream MyTwitAgent.sinks.HDFS.hdfs.writeFormat = Text MyTwitAgent.sinks.HDFS.hdfs.batchSize = 1000 MyTwitAgent.sinks.HDFS.hdfs.rollSize = 0 MyTwitAgent.sinks.HDFS.hdfs.rollCount = 10000 MyTwitAgent.channels.MemChannel.type = memory MyTwitAgent.channels.MemChannel.capacity = 10000 MyTwitAgent.channels.MemChannel.transactionCapacity = 1000

Steg 2) Ställ också in TwitterAgent.sinks.HDFS.hdfs.path enligt nedan.
TwitterAgent.sinks.HDFS.hdfs.path = hdfs:// : / /flume/tweets/

Att hitta , och , se värdet för parametern 'fs.defaultFS' som är inställd i $HADOOP_HOME/etc/hadoop/core-site.xml, som visas nedan.

Steg 3) För att spola data till HDFS när de kommer, radera posten nedan om den finns.
TwitterAgent.sinks.HDFS.hdfs.rollInterval = 600
Exempel: Streama Twitter-data med Flume
Steg 1) Öppna 'flume-env.sh' i skrivläge och ange värden för parametrarna nedan.
JAVA_HOME=<Installation directory of Java>
FLUME_CLASSPATH="<Flume Installation Directory>/lib/MyTwitterSourceForFlume.jar"

Steg 2) Starta Hadoop.
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Steg 3) Två av JAR-filerna från Flume-tarballen är inte kompatibla med Hadoop 2.2.0, så i detta Apache Flume-exempel följer vi stegen nedan för att göra Flume kompatibelt med Hadoop 2.2.0. Denna JAR-växling är en fix från 1.4.0-eran; Flume 1.11.0 levererar redan aktuella protobuf- och Guava-byggen, så en modern tarball behöver normalt inget av det.
a. Flytta protobuf-java-2.4.1.jar från ' /lib'. Gå till den katalogen först.
CD /lib
sudo mv protobuf-java-2.4.1.jar ~/

b. Hitta JAR-filen 'guava' enligt nedan.
find . -name "guava*"

Flytta guava-10.0.1.jar ut ur ' /lib'.
sudo mv guava-10.0.1.jar ~/

c. Ladda ner guava-17.0.jar från Maven-arkivet, visas nedan.

Kopiera nu den här nedladdade JAR-filen till ' /lib'.
Steg 4) Gå till ' /bin' och starta Flume enligt följande.
./flume-ng agent -n MyTwitAgent -c conf -f <Flume Installation Directory>/conf/flume.conf

Kommandotolksfönstret där Flume hämtar tweets ser ut så här.

Från kommandofönstrets meddelande kan vi se att utdata skrivs till katalogen /user/hduser/flume/tweets/. Öppna nu den här katalogen med en webbläsare.
Steg 5) För att se resultatet av datainläsningen, öppna http://localhost:50070/ i en webbläsare, bläddra i filsystemet och gå sedan till katalogen där data har laddats, det vill säga
/flume/tweets/
Port 50070 är NameNode-webbgränssnittet på Hadoop 2; Hadoop 3 flyttade samma sida till port 9870.

Flume är ena halvan av intag: Sqoop importerar tabeller i batchar, Flume strömmar händelser, sedan Pig or Bikupa forma filerna och Oozie schemalägger kedjan. Se även stora dataanalysverktyg, MapReduce-kopplingar och räknare och Talang.