Výukový program Apache Flume: Co je, ArchiPříklad tecture & Hadoop
⚡ Chytré shrnutí
Apache Flume je distribuovaná služba pro shromažďování, agregaci a přesun velkých objemů dat protokolů do HDFS, postavená na agentech, kteří řetězí zdroj, kanál a příjemce.

Co je Apache Flume v Hadoopu?
Apache Flume je spolehlivý a distribuovaný systém pro sběr, agregaci a přesun obrovského množství dat protokolů. Má jednoduchou, ale flexibilní architekturu založenou na streamování datových toků. Apache Flume se používá ke sběru dat protokolů přítomných v souborech protokolů z webových serverů a jejich agregaci do... HDFS pro analýzu.
Flume v Hadoopu podporuje více zdrojů, včetně:
- 'tail' (který přes Flume přesměruje data z lokálního souboru do HDFS, podobně jako příkaz 'tail' v Unixu)
- Protokoly systému
- Apache log4j (což umožňuje Java aplikace pro zápis událostí do souborů v HDFS přes Flume).
Aktuální vydání je Žlab 1.11.0, zveřejněno 25. října 2022 a dostupné na Stránka pro stažení Apache FlumeTento návod byl napsán pro verzi 1.4.0, takže několik kroků níže obsahuje poznámku, kde se aktuální verze chová odlišně.
Tok Architecture
Agent Flume je JVM proces se třemi složkami – zdrojem náhonu, kanálem náhonu a jímkou náhonu – kterými se šíří události po iniciaci z externího zdroje. Níže uvedený diagram ukazuje, jak jsou propojeny.
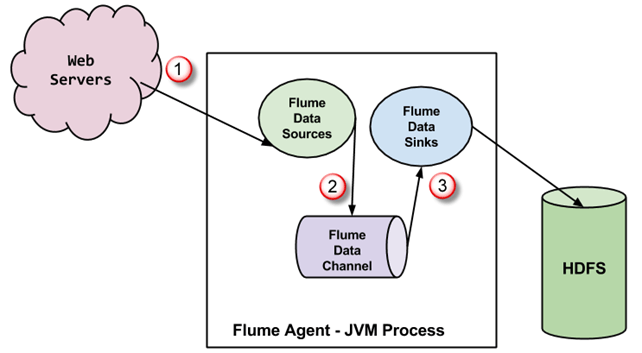
- Události generované externím zdrojem (webovým serverem) jsou spotřebovávány zdrojem Flume. Externí zdroj odesílá události do zdroje Flume ve formátu, který cílový zdroj rozpozná.
- Zdroj Flume přijme událost a uloží ji do jednoho nebo více kanálů. Kanál funguje jako úložiště, které uchovává událost, dokud ji nezpracuje zdroj Flume. Tento kanál může k ukládání těchto událostí používat lokální souborový systém.
- Jímka Flume odstraní událost z kanálu a uloží ji do externího repozitáře, jako je HDFS. Může existovat více agentů Flume, v takovém případě jímka Flume přepošle událost do zdroje Flume dalšího agenta v toku.
Některé důležité vlastnosti Flume
- Flume má flexibilní design založený na streamování datových toků. Je odolný vůči chybám a robustní s několika mechanismy pro přepnutí při selhání a obnovu. Flume nabízí různé úrovně spolehlivosti, včetně „doručení s maximální snahou“ a "doručování od začátku do konce". Doručení s maximální snahou netoleruje žádné selhání uzlu Flume, zatímco end-to-end doručení zaručuje doručení i v případě selhání více uzlů.
- Flume přenáší data mezi zdroji a úložištěm. Toto shromažďování dat může být buď plánované, nebo řízené událostmi. Flume má vlastní engine pro zpracování dotazů, který usnadňuje transformaci každé nové dávky dat před jejím přesunutím do zamýšleného úložiště.
- Možný Žlabové dřezy zahrnují HDFS a HBaseFlume může také přenášet data o událostech, jako jsou data o síťovém provozu, data generovaná webovými stránkami sociálních médií a e-mailové zprávy.
Nastavení kanálu, knihovny a zdrojového kódu
Než začneme s samotným procesem, ujistěte se, že máte nainstalovaný Hadoop; pokud ne, projděte si ho. jak nainstalovat Hadoop Nejprve. Změňte uživatele na 'hduser' (ID použité při konfiguraci Hadoopu; můžete přepnout na ID uživatele použité během vaší vlastní konfigurace Hadoopu).

Krok 1) Vytvořte nový adresář s názvem „FlumeTutorial“.
sudo mkdir FlumeTutorial
- Udělte oprávnění pro čtení, zápis a spuštění.
sudo chmod -R 777 FlumeTutorial
- Zkopírujte soubory MyTwitterSource.java a MyTwitterSourceForFlume.java do tohoto adresáře.
Stáhněte si vstupní soubory odtud
Zkontrolujte oprávnění všech těchto souborů, jak je uvedeno níže, a pokud chybí, udělte jim oprávnění „číst“.

Krok 2) Stáhněte si „Apache Flume“ z https://flume.apache.org/download.html.
V tomto tutoriálu Flume byl použit Apache Flume 1.4.0.

Dále klikněte na zrcadlo.

Krok 3) Zkopírujte stažený tarball do vámi vybraného adresáře a poté jejtracobsah pomocí následujícího příkazu.
sudo tar -xvf apache-flume-1.4.0-bin.tar.gz

Tím se vytvoří nový adresář s názvem apache-flume-1.4.0-bin a extraculoží soubory do něj. Tento adresář se označuje jako ve zbytku článku.
Krok 4) Nastavení knihovny Flume. Zkopírujte soubory twitter4j-core-4.0.1.jar, flume-ng-configuration-1.4.0.jar, flume-ng-core-1.4.0.jar a flume-ng-sdk-1.4.0.jar do
/lib/
Jeden nebo všechny zkopírované soubory JAR mohou mít nastavené oprávnění ke spuštění, což může způsobit problém s kompilací kódu, proto je zrušte. V mém případě měl soubor twitter4j-core-4.0.1.jar oprávnění ke spuštění. Zrušil jsem ho, jak je popsáno níže.
sudo chmod -x twitter4j-core-4.0.1.jar

Poté níže uvedený příkaz udělí všem oprávnění ke čtení souboru twitter4j-core-4.0.1.jar.
sudo chmod +rrr /usr/local/apache-flume-1.4.0-bin/lib/twitter4j-core-4.0.1.jar
Vezměte prosím na vědomí, že jsem si stáhl twitter4j-core-4.0.1.jar z Maven Repositorya všechny soubory Flume JAR, tj. flume-ng-*-1.4.0.jar, z artefakty org.apache.flume.
Načtěte data z Twitteru pomocí Flume
Krok 1) Přejděte do adresáře obsahujícího soubory zdrojového kódu.
Krok 2) Nastavit CLASSPATH tak, aby obsahoval /lib/* a ~/FlumeTutorial/flume/mytwittersource/*.
export CLASSPATH="/usr/local/apache-flume-1.4.0-bin/lib/*:~/FlumeTutorial/flume/mytwittersource/*"

Krok 3) Zkompilujte zdrojový kód pomocí níže uvedeného příkazu.
javac -d . MyTwitterSourceForFlume.java MyTwitterSource.java

Krok 4) Vytvořte soubor JAR. Nejprve vytvořte soubor Manifest.txt pomocí textového editoru dle vlastního výběru a přidejte do něj následující řádek.
Main-Class: flume.mytwittersource.MyTwitterSourceForFlume
Zde je flume.mytwittersource.MyTwitterSourceForFlume název hlavní třídy. Upozorňujeme, že na konci tohoto řádku musíte stisknout klávesu Enter, jak je znázorněno níže.

Nyní vytvořte JAR soubor 'MyTwitterSourceForFlume.jar' následujícím způsobem.
jar cfm MyTwitterSourceForFlume.jar Manifest.txt flume/mytwittersource/*.class

Krok 5) Zkopírujte tento JAR do /knihovna/.
sudo cp MyTwitterSourceForFlume.jar <Flume Installation Directory>/lib/

Krok 6) Přejděte do konfiguračního adresáře Flume, /konf.
Pokud soubor flume.conf neexistuje, zkopírujte soubor flume-conf.properties.template a přejmenujte jej na flume.conf.
sudo cp flume-conf.properties.template flume.conf

Pokud soubor flume-env.sh neexistuje, zkopírujte soubor flume-env.sh.template a přejmenujte jej na flume-env.sh.
sudo cp flume-env.sh.template flume-env.sh

Vytvoření aplikace Twitter
Nejdřív si tohle přečtěte. Streamování v1.1 statuses/filter Koncový bod, který twitter4j 4.0.1 potřebuje, byl 9. března 2023 vyřazen a filtrovaný stream API v2, který jej nahradil, nyní na adrese developer.x.com, se nachází za placenou úrovní. Níže uvedené obrazovky považujte za vlastní zdrojový vzor a poté nasměrujte stejného agenta na soubor, spouštěcí soubor nebo Kafka zdrojový kód.
Krok 1) Vytvořte aplikaci Twitter přihlášením na portál pro vývojáře.


Krok 2) Přejděte do sekce „Moje aplikace“ (tato možnost se zobrazí po kliknutí na tlačítko „Vejce“ v pravém horním rohu).

Krok 3) Novou aplikaci vytvoříte kliknutím na tlačítko „Vytvořit novou aplikaci“.
Krok 4) Vyplňte podrobnosti o aplikaci uvedením názvu aplikace, popisu a webové stránky. Můžete se řídit poznámkami uvedenými pod každým vstupním polem.
Krok 5) Sjeďte dolů po stránce, přijměte podmínky zaškrtnutím políčka „Ano, souhlasím“ a klikněte na tlačítko „Vytvořit si aplikaci Twitter“.

Krok 6) V okně nově vytvořené aplikace přejděte na kartu „Klíče API“, sjeďte dolů po stránce a klikněte na tlačítko „Vytvořit můj přístupový token“.


Krok 7) Obnovte stránku.
Krok 8) Klikněte na „Test OAuth“. Zobrazí se nastavení „OAuth“ aplikace.

Krok 9) Upravte soubor „flume.conf“ pomocí těchto nastavení OAuth. Postup úpravy souboru „flume.conf“ je uveden níže.

Pro aktualizaci souboru 'flume.conf' musíme zkopírovat klíč spotřebitele, tajný klíč spotřebitele, přístupový token a tajný klíč přístupového tokenu.
Poznámka: Tyto hodnoty patří uživateli, a proto jsou důvěrné, takže by neměly být sdíleny.
Upravte soubor 'flume.conf'
Krok 1) Otevřete soubor 'flume.conf' v režimu zápisu a nastavte hodnoty níže uvedených parametrů.
sudo gedit flume.conf
Zkopírujte níže uvedený obsah.
MyTwitAgent.sources = Twitter MyTwitAgent.channels = MemChannel MyTwitAgent.sinks = HDFS MyTwitAgent.sources.Twitter.type = flume.mytwittersource.MyTwitterSourceForFlume MyTwitAgent.sources.Twitter.channels = MemChannel MyTwitAgent.sources.Twitter.consumerKey = <Copy consumer key value from Twitter App> MyTwitAgent.sources.Twitter.consumerSecret = <Copy consumer secret value from Twitter App> MyTwitAgent.sources.Twitter.accessToken = <Copy access token value from Twitter App> MyTwitAgent.sources.Twitter.accessTokenSecret = <Copy access token secret value from Twitter App> MyTwitAgent.sources.Twitter.keywords = guru99 MyTwitAgent.sinks.HDFS.channel = MemChannel MyTwitAgent.sinks.HDFS.type = hdfs MyTwitAgent.sinks.HDFS.hdfs.path = hdfs://localhost:54310/user/hduser/flume/tweets/ MyTwitAgent.sinks.HDFS.hdfs.fileType = DataStream MyTwitAgent.sinks.HDFS.hdfs.writeFormat = Text MyTwitAgent.sinks.HDFS.hdfs.batchSize = 1000 MyTwitAgent.sinks.HDFS.hdfs.rollSize = 0 MyTwitAgent.sinks.HDFS.hdfs.rollCount = 10000 MyTwitAgent.channels.MemChannel.type = memory MyTwitAgent.channels.MemChannel.capacity = 10000 MyTwitAgent.channels.MemChannel.transactionCapacity = 1000

Krok 2) Také nastavte TwitterAgent.sinks.HDFS.hdfs.path dle níže uvedeného postupu.
TwitterAgent.sinks.HDFS.hdfs.path = hdfs:// : / /flume/tweets/

Najít , a , viz hodnota parametru 'fs.defaultFS' nastavená v souboru $HADOOP_HOME/etc/hadoop/core-site.xml, zobrazená níže.

Krok 3) Aby bylo možné data včas ukládat do HDFS, smažte níže uvedenou položku, pokud existuje.
TwitterAgent.sinks.HDFS.hdfs.rollInterval = 600
Příklad: Streamování dat Twitteru pomocí Flume
Krok 1) Otevřete soubor 'flume-env.sh' v režimu zápisu a nastavte hodnoty níže uvedených parametrů.
JAVA_HOME=<Installation directory of Java>
FLUME_CLASSPATH="<Flume Installation Directory>/lib/MyTwitterSourceForFlume.jar"

Krok 2) Spusťte Hadoop.
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Krok 3) Dva soubory JAR z tarballu Flume nejsou kompatibilní s Hadoopem 2.2.0, takže v tomto příkladu Apache Flume postupujeme podle níže uvedených kroků, abychom zajistili kompatibilitu Flume s Hadoopem 2.2.0. Tato výměna JAR souborů je opravou z verze 1.4.0; Flume 1.11.0 již obsahuje aktuální sestavení Protobuf a Guava, takže moderní tarball je obvykle nepotřebuje.
a. Přesuňte soubor protobuf-java-2.4.1.jar z adresáře ' /lib'. Nejprve přejděte do tohoto adresáře.
CD /lib
sudo mv protobuf-java-2.4.1.jar ~/

b. Vyhledejte soubor JAR 'guava', jak je uvedeno níže.
find . -name "guava*"

Přesunout guava-10.0.1.jar z adresáře ' /knihovna'.
sudo mv guava-10.0.1.jar ~/

c. Stáhněte si soubor guava-17.0.jar z Maven Repository, je uvedeno níže.

Nyní zkopírujte tento stažený soubor JAR do ' /knihovna'.
Krok 4) Jdi na ' /bin' a spusťte Flume následujícím způsobem.
./flume-ng agent -n MyTwitAgent -c conf -f <Flume Installation Directory>/conf/flume.conf

Okno příkazového řádku, kde Flume načítá tweety, vypadá takto.

Z příkazového okna vidíme, že výstup je zapsán do adresáře /user/hduser/flume/tweets/. Nyní otevřete tento adresář pomocí webového prohlížeče.
Krok 5) Chcete-li zobrazit výsledek načtení dat, otevřete v prohlížeči adresu http://localhost:50070/, procházejte souborový systém a poté přejděte do adresáře, kam byla data načtena, tj.
/flume/tweets/
Port 50070 je webové uživatelské rozhraní NameNode na Hadoopu 2; Hadoop 3 přesunul stejnou stránku na port 9870.

Žlab je polovina požití: Sqoop importuje tabulky v dávkách, Flume streamuje události a poté Prase or Úl tvarovat soubory a Oozie plánuje řetězec. Viz také nástroje pro analýzu velkých dat, Jídla a čítače MapReduce a Talend.