50년 SQL 인터뷰 질문 2026개 및 답변
신입생을 위한 SQL 인터뷰 질문
1. DBMS란?
데이터베이스 관리 시스템(DBMS)은 데이터베이스의 생성, 유지 관리 및 사용을 제어하는 프로그램입니다. DBMS는 데이터를 파일 시스템에 저장하지 않고 데이터베이스에 관리하는 파일 관리자(File Manager)라고 할 수 있습니다.
👉 무료 PDF 다운로드: SQL 인터뷰 질문 및 답변 >>
2. RDBMS 란 무엇입니까?
RDBMS는 관계형 데이터베이스 관리 시스템을 의미합니다. RDBMS는 테이블의 열 사이의 공통 필드로 관련된 테이블 컬렉션에 데이터를 저장합니다. 또한 테이블에 저장된 데이터를 조작하기 위한 관계 연산자도 제공합니다.
예: SQL Server.
3. SQL이란 무엇입니까?
SQL은 Structured Query Language의 약자로 데이터베이스와 통신하는 데 사용됩니다. 데이터베이스에서 데이터 검색, 업데이트, 삽입 및 삭제와 같은 작업을 수행하는 데 사용되는 표준 언어입니다.
Standard SQL 명령 선택하세요.
4. 데이터베이스란 무엇입니까?
데이터베이스는 데이터의 쉬운 접근, 저장, 검색, 관리를 위해 조직화된 형태의 데이터일 뿐입니다. 이는 다양한 방법으로 접근할 수 있는 구조화된 형태의 데이터라고도 합니다.
예: 학교 관리 데이터베이스, 은행 관리 데이터베이스.
5. 테이블과 필드란 무엇입니까?
테이블은 열과 행으로 구성된 모델로 구성된 데이터 집합입니다. 열은 세로로, 행은 가로로 분류할 수 있습니다. 테이블에는 필드라는 지정된 수의 열이 있지만 레코드라는 행은 무제한으로 포함될 수 있습니다.
예시:.
테이블: 직원.
필드: 직원 ID, 직원 이름, 생년월일.
데이터: 201456, 데이비드, 11년 15월 1960일.
6. 기본 키란 무엇입니까?
A 기본 키 행을 고유하게 지정하는 필드의 조합입니다. 이는 특별한 종류의 고유 키이며 암시적 NOT NULL 제약 조건을 갖습니다. 즉, 기본 키 값은 NULL이 될 수 없습니다.
7. 고유키란 무엇입니까?
고유 키 제약 조건은 데이터베이스의 각 레코드를 고유하게 식별합니다. 이는 열 또는 열 집합에 고유성을 제공합니다.
기본 키 제약 조건에는 자동 고유 제약 조건이 정의되어 있습니다. 그러나 고유 키의 경우에는 그렇지 않습니다.
테이블당 많은 고유 제약 조건이 정의될 수 있지만, 테이블당 기본 키 제약 조건은 하나만 정의됩니다.
8. 외래 키란 무엇입니까?
외래 키는 다른 테이블의 기본 키와 관련될 수 있는 하나의 테이블입니다. 두 테이블 사이에는 다른 테이블의 기본 키와 외래 키를 참조하여 관계를 생성해야 합니다.
9. 조인이란 무엇입니까?
테이블의 필드 간의 관계를 기반으로 더 많은 테이블의 데이터를 쿼리하는 데 사용되는 키워드입니다. JOIN을 사용할 때 키는 중요한 역할을 합니다.
10. 조인의 종류는 무엇이며, 각각에 대해 설명해주세요.
다음의 다양한 종류의 조인 이는 데이터를 검색하는 데 사용될 수 있으며 테이블 간의 관계에 따라 다릅니다.
- 내부 조인.
내부 조인은 테이블 간에 일치하는 행이 하나 이상 있으면 행을 반환합니다.
- 오른쪽 가입.
오른쪽 조인은 테이블과 오른쪽 테이블의 모든 행 사이에 공통된 행을 반환합니다. 간단히 말해서, 왼쪽 테이블에 일치하는 항목이 없더라도 오른쪽 테이블의 모든 행을 반환합니다.
- 왼쪽 조인.
왼쪽 조인은 테이블과 왼쪽 테이블의 모든 행 간에 공통된 행을 반환합니다. 간단히 말해서, 오른쪽 테이블에 일치하는 항목이 없더라도 왼쪽 테이블의 모든 행을 반환합니다.
- 전체 가입.
전체 조인은 테이블 중 하나에 일치하는 행이 있는 경우 행을 반환합니다. 즉, 왼쪽 테이블의 모든 행과 오른쪽 테이블의 모든 행을 반환합니다.
3년 경력의 SQL 면접 질문
11. 정규화 란 무엇입니까?
정규화는 데이터베이스의 필드와 테이블을 구성하여 중복성과 종속성을 최소화하는 프로세스입니다. Normalization의 주요 목적은 단일 테이블에서 만들 수 있는 필드를 추가, 삭제, 수정하는 것입니다.
12. 비정규화란 무엇입니까?
비정규화는 더 높은 정규 형태의 데이터베이스에서 더 낮은 정규 형태로 데이터에 액세스하는 데 사용되는 기술입니다. 관련 테이블의 데이터를 통합하여 테이블에 중복성을 도입하는 프로세스이기도 합니다.
13. 다양한 정규화란 무엇입니까?
데이터베이스 정규화 사례연구를 통해 쉽게 이해할 수 있습니다. 정규형은 6가지 형태로 나누어지며, 이에 대한 설명은 아래와 같습니다. -.
.png)
- 첫 번째 정규형(1NF):.
이렇게 하면 테이블에서 중복된 열이 모두 제거됩니다. 관련 데이터에 대한 테이블 생성 및 고유 열 식별.
- 두 번째 정규형(2NF):.
첫 번째 정규형의 모든 요구 사항을 충족합니다. 데이터의 하위 집합을 별도의 테이블에 배치하고 기본 키를 사용하여 테이블 간의 관계를 생성합니다.
- 제3정규형(XNUMXNF):.
이는 2NF의 모든 요구 사항을 충족해야 합니다. 기본 키 제약 조건에 종속되지 않는 열을 제거합니다.
- 제4정규형(XNUMXNF):.
데이터베이스 테이블 인스턴스에 관련 엔터티를 설명하는 두 개 이상의 독립적이고 다중값 데이터가 포함되어 있지 않으면 4에 해당합니다.th 노멀폼.
- 다섯 번째 정규형(5NF):.
테이블은 5NF인 경우에만 4차 정규형이고 데이터 손실 없이 더 작은 수의 테이블로 분해될 수 없습니다.
- 여섯 번째 정규형(6NF):.
6차 정규형은 표준화되지 않았지만 데이터베이스 전문가들 사이에서 한동안 논의되고 있습니다. 가까운 시일 내에 6차 정규형에 대한 명확하고 표준화된 정의가 나올 수 있기를 바랍니다.
14. 뷰란 무엇입니까?
뷰는 테이블에 포함된 데이터의 하위 집합으로 구성된 가상 테이블입니다. 뷰는 실제로 존재하지 않으며 저장하는 데 공간이 덜 필요합니다. 뷰는 하나 이상의 테이블의 데이터를 결합할 수 있으며, 이는 관계에 따라 달라집니다.
15. 인덱스란 무엇입니까?
인덱스는 테이블에서 레코드를 더 빠르게 검색할 수 있도록 하는 성능 튜닝 방법입니다. 인덱스는 각 값에 대한 항목을 생성하며 데이터를 더 빨리 검색할 수 있습니다.
16. 다양한 유형의 인덱스에는 어떤 것이 있나요?
인덱스에는 세 가지 유형이 있습니다. -.
- 단일 인덱스.
이 인덱싱은 열이 고유하게 인덱싱된 경우 필드에 중복 값이 있는 것을 허용하지 않습니다. 기본 키가 정의되면 고유 인덱스가 자동으로 적용됩니다.
- Cluster에드 인덱스.
이 유형의 인덱스는 테이블의 물리적 순서를 재정렬하고 키 값을 기준으로 검색합니다. 각 테이블에는 클러스터형 인덱스가 하나만 있을 수 있습니다.
- 비Cluster에드 인덱스.
비Clustered Index는 테이블의 물리적 순서를 변경하지 않고 데이터의 논리적 순서를 유지합니다. 각 테이블은 999개의 비클러스터형 인덱스를 가질 수 있습니다.
17. 커서란 무엇입니까?
데이터베이스 커서는 테이블의 행이나 레코드를 탐색할 수 있게 해주는 컨트롤입니다. 이는 행 집합의 한 행에 대한 포인터로 볼 수 있습니다. 커서는 데이터베이스 레코드의 검색, 추가, 제거 등의 탐색에 매우 유용합니다.
18. 관계란 무엇이며 무엇입니까?
데이터베이스 관계는 데이터베이스의 테이블 간의 연결로 정의됩니다. 다양한 데이터 기반 관계가 있으며 다음과 같습니다.
- 일대일 관계.
- 일대다 관계.
- 다대일 관계.
- 자기 참조 관계.
19. 쿼리란 무엇입니까?
DB 쿼리는 데이터베이스에서 정보를 다시 가져오기 위해 작성된 코드입니다. 쿼리는 결과 집합에 대한 우리의 기대와 일치하는 방식으로 설계될 수 있습니다. 간단히 말해서, 데이터베이스에 대한 질문입니다.
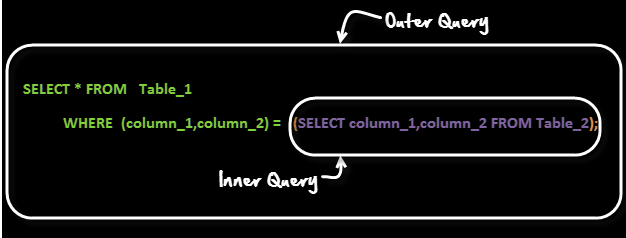
20. 서브쿼리란 무엇입니까?
하위 쿼리는 다른 쿼리 내의 쿼리입니다. 외부 쿼리를 메인 쿼리, 내부 쿼리를 서브 쿼리라고 합니다. 항상 하위 쿼리가 먼저 실행되고 하위 쿼리의 결과가 메인 쿼리로 전달됩니다.
하위 쿼리 구문을 살펴보겠습니다.
MyFlix 비디오 라이브러리의 일반적인 고객 불만은 영화 제목 수가 적다는 것입니다. 경영진은 타이틀 수가 가장 적은 카테고리의 영화를 구매하려고 합니다.
다음과 같은 쿼리를 사용할 수 있습니다.
SELECT category_name FROM categories WHERE category_id =( SELECT MIN(category_id) from movies);
5년 경력의 SQL 면접 질문
21. 하위 쿼리의 유형은 무엇입니까?
하위 쿼리에는 상관 관계와 비상관 쿼리의 두 가지 유형이 있습니다.
상관 서브 쿼리는 독립 쿼리로 간주할 수 없으나, 메인 쿼리 목록의 FROM에 나열된 테이블의 열을 참조할 수는 있습니다.
Non-Corlated 하위 쿼리는 독립 쿼리로 간주할 수 있으며 하위 쿼리의 출력이 기본 쿼리로 대체됩니다.
22. 저장 프로 시저 란 무엇입니까?
저장 프로시저(Stored Procedure)는 데이터베이스 시스템에 접근하기 위해 여러 개의 SQL 문으로 구성된 함수이다. 여러 SQL 문이 저장 프로시저로 통합되어 필요할 때마다 실행됩니다.
23. 트리거 란 무엇입니까?
DB 트리거는 데이터베이스의 테이블이나 뷰에 대한 일부 이벤트에 대한 응답으로 자동으로 실행되는 코드 또는 프로그램입니다. 주로 트리거는 데이터베이스의 무결성을 유지하는 데 도움이 됩니다.
예: 학생 데이터베이스에 새 학생이 추가되면 시험, 점수 및 출석 테이블과 같은 관련 테이블에 새 기록이 생성되어야 합니다.
24. DELETE 명령과 TRUNCATE 명령의 차이점은 무엇입니까?
DELETE 명령은 테이블에서 행을 제거하는 데 사용되며 WHERE 절은 조건부 매개 변수 집합에 사용될 수 있습니다. 삭제문 이후에 Commit과 Rollback이 가능합니다.
TRUNCATE는 테이블에서 모든 행을 제거합니다. Truncate 작업은 롤백할 수 없습니다.
25. 지역 변수와 전역 변수는 무엇이며 차이점은 무엇입니까?
지역변수는 함수 내부에서 사용되거나 존재할 수 있는 변수이다. 다른 함수에는 알려지지 않으며 해당 변수는 참조하거나 사용할 수 없습니다. 해당 함수가 호출될 때마다 변수가 생성될 수 있습니다.
전역 변수는 프로그램 전반에 걸쳐 사용되거나 존재할 수 있는 변수입니다. 전역에 선언된 동일한 변수는 함수에서 사용할 수 없습니다. 해당 함수가 호출될 때마다 전역 변수를 생성할 수 없습니다.
26. 제약이란 무엇입니까?
제약조건을 사용하여 테이블의 데이터 유형에 대한 제한을 지정할 수 있습니다. 테이블 문을 생성하거나 변경하는 동안 제약 조건을 지정할 수 있습니다. 제약 조건의 샘플은 다음과 같습니다.
- NULL이 아닙니다.
- 확인하다.
- 기본.
- 독특한.
- 기본 키.
- 외래 키.
27. 데이터란 무엇인가 Integrity?
Data Integrity 데이터베이스에 저장된 데이터의 정확성과 일관성을 정의합니다. 또한 데이터가 애플리케이션이나 데이터베이스에 입력될 때 비즈니스 규칙을 적용하기 위해 무결성 제약 조건을 정의할 수도 있습니다.
28. 자동 증분이란 무엇입니까?
자동 증가 키워드를 사용하면 사용자는 새 레코드가 테이블에 삽입될 때 생성될 고유 번호를 생성할 수 있습니다. AUTO INCREMENT 키워드는 다음에서 사용할 수 있습니다. Oracle 및 IDENTITY 키워드는 SQL SERVER에서 사용할 수 있습니다.
대부분 이 키워드는 PRIMARY KEY가 사용될 때마다 사용할 수 있습니다.
29. 차이점은 무엇입니까 Cluster 및 비Cluster 색인?
Clustered 인덱스는 레코드가 저장되는 방식을 변경하여 데이터베이스에서 데이터를 쉽게 검색하는 데 사용됩니다. 데이터베이스는 클러스터형 인덱스로 설정된 열에 따라 행을 정렬합니다.
비클러스터형 인덱스는 저장된 방식을 변경하지 않고 테이블 내에 완전히 별도의 객체를 만듭니다. 검색 후 원래 테이블 행을 가리킵니다.
30. 데이터웨어하우스란 무엇인가요?
Datawarehouse는 다양한 정보 소스의 데이터를 모아 놓은 중앙 저장소입니다. 이러한 데이터는 통합되고 변환되어 마이닝 및 온라인 처리에 사용할 수 있습니다. 웨어하우스 데이터에는 데이터 마트라는 데이터 하위 집합이 있습니다.
31. 셀프 조인(Self Join)이란 무엇입니까?
Self-join은 자신과 비교하는 데 사용되는 쿼리로 설정됩니다. 이는 동일한 테이블의 동일한 열에 있는 다른 값과 열의 값을 비교하는 데 사용됩니다. ALIAS ES는 동일한 테이블 비교에 사용될 수 있습니다.
32. 교차 조인(Cross Join)이란 무엇입니까?
교차 조인은 첫 번째 테이블의 행 수에 두 번째 테이블의 행 수를 곱한 데카르트 곱으로 정의됩니다. 교차 조인에 WHERE 절이 사용된다고 가정하면 쿼리는 INNER JOIN처럼 작동합니다.
33. 사용자 정의 함수란 무엇입니까?
사용자 정의 함수는 필요할 때마다 해당 논리를 사용하도록 작성된 함수입니다. 동일한 로직을 여러 번 작성할 필요는 없습니다. 대신 필요할 때마다 함수를 호출하거나 실행할 수 있습니다.
34. 사용자 정의 함수에는 어떤 유형이 있나요?
사용자 정의 함수에는 세 가지 유형이 있습니다.
- 스칼라 함수.
- 인라인 테이블 값 함수.
- 다중 문 값 함수.
스칼라는 단위를 반환하고 변형은 반환 절을 정의합니다. 다른 두 가지 유형은 테이블을 반환으로 반환합니다.
35. 대조란 무엇입니까?
데이터 정렬은 문자 데이터를 정렬하고 비교할 수 있는 방법을 결정하는 규칙 집합으로 정의됩니다. 이는 A와 다른 언어 문자를 비교하는 데 사용할 수 있으며 문자 너비에 따라 달라집니다.
ASCII 값을 사용하여 이러한 문자 데이터를 비교할 수 있습니다.
36. 데이터 정렬 민감도에는 어떤 유형이 있나요?
다음은 다양한 유형의 데이터 정렬 민감도입니다.
- 대소문자 구분 - A, a, B, b.
- 악센트 감도.
- 가나 감도 – 일본어 가나 문자입니다.
- 너비 감도 – 단일 바이트 문자 및 이중 바이트 문자.
37. 저장 프로시저의 장점과 단점은 무엇입니까?
저장 프로시저를 모듈식 프로그래밍으로 사용할 수 있습니다. 즉, 한 번 생성하고 필요할 때마다 여러 번 저장하고 호출하는 것을 의미합니다. 이는 여러 쿼리를 실행하는 대신 더 빠른 실행을 지원합니다. 이렇게 하면 네트워크 트래픽이 줄어들고 데이터 보안이 강화됩니다.
단점은 데이터베이스에서만 실행이 가능하고 데이터베이스 서버에서 더 많은 메모리를 사용한다는 점이다.
38. 온라인 거래 처리(OLTP)란 무엇입니까?
OLTP(온라인 트랜잭션 처리)는 데이터 입력, 데이터 검색 및 데이터 처리에 사용할 수 있는 트랜잭션 기반 애플리케이션을 관리합니다. OLTP는 데이터 관리를 간단하고 효율적으로 만듭니다. OLAP 시스템과 달리 OLTP 시스템의 목표는 실시간 트랜잭션을 제공하는 것입니다.
예 – 일일 은행 거래.
39. 조항이란 무엇입니까?
SQL 절은 쿼리에 조건을 제공하여 결과 집합을 제한하도록 정의됩니다. 이는 일반적으로 전체 레코드 집합에서 일부 행을 필터링합니다.
예 - WHERE 조건이 있는 쿼리
HAVING 조건이 있는 쿼리입니다.
40. 재귀 저장 프로시저란 무엇입니까?
일부 경계 조건에 도달할 때까지 자체적으로 호출하는 저장 프로시저입니다. 이 재귀 함수 또는 프로시저는 프로그래머가 동일한 코드 세트를 여러 번 사용할 수 있도록 도와줍니다.
10년 이상의 경험을 위한 SQL 인터뷰 질문
41. Union, minus, Interact 명령어란 무엇인가요?
UNION 연산자는 두 테이블의 결과를 결합하는 데 사용되며, 테이블에서 중복된 행을 제거합니다.
MINUS 연산자는 첫 번째 쿼리에서 행을 반환하지만 두 번째 쿼리에서는 반환하지 않는 데 사용됩니다. 첫 번째 및 두 번째 쿼리의 일치하는 레코드와 첫 번째 쿼리의 다른 행은 결과 집합으로 표시됩니다.
INTERSECT 연산자는 두 쿼리 모두에서 반환된 행을 반환하는 데 사용됩니다.
42. ALIAS 명령이란 무엇입니까?
테이블이나 컬럼에 ALIAS 이름을 부여할 수 있습니다. 이 별칭 이름은 다음에서 참조할 수 있습니다. WHERE 절 테이블이나 열을 식별합니다.
예-.
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
여기서 st는 학생 테이블의 별칭 이름을 나타내고, Ex는 시험 테이블의 별칭 이름을 나타냅니다.
43. TRUNCATE문과 DROP문의 차이점은 무엇입니까?
TRUNCATE는 테이블에서 모든 행을 제거하며 롤백할 수 없습니다. DROP 명령은 데이터베이스에서 테이블을 제거하며 작업을 롤백할 수 없습니다.
44. 집계 및 스칼라 함수란 무엇입니까?
집계 함수는 수학적 계산을 평가하고 단일 값을 반환하는 데 사용됩니다. 이는 테이블의 열에서 계산할 수 있습니다. 스칼라 함수는 입력 값을 기반으로 단일 값을 반환합니다.
예 -.
Aggregate – max(), count – 숫자를 기준으로 계산됩니다.
스칼라 – UCASE(), NOW() – 문자열을 기준으로 계산됩니다.
45. 기존 테이블에서 빈 테이블을 어떻게 만들 수 있나요?
예를 들면 -.
Select * into studentcopy from student where 1=2
여기서는 복사된 행 없이 동일한 구조를 가진 다른 테이블에 학생 테이블을 복사합니다.
46. 두 테이블에서 공통 레코드를 가져오는 방법은 무엇입니까?
공통 레코드 결과 세트는 -에 의해 달성될 수 있습니다.
Select studentID from student INTERSECT Select StudentID from Exam
47. 테이블에서 대체 레코드를 가져오는 방법은 무엇입니까?
홀수 및 짝수 행 번호에 대한 레코드를 가져올 수 있습니다.
짝수를 표시하려면-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
홀수를 표시하려면-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
from (학생에서 rowno, StudentId 선택) 여기서 mod(rowno,2)=1.[/sql]
48. 테이블에서 고유한 레코드를 선택하는 방법은 무엇입니까?
DISTINCT 키워드를 사용하여 테이블에서 고유한 레코드를 선택합니다.
Select DISTINCT StudentID, StudentName from Student.
49. 문자열의 처음 5자를 가져오는 데 사용되는 명령은 무엇입니까?
문자열의 처음 5자를 가져오는 방법에는 여러 가지가 있습니다. -.
Select SUBSTRING(StudentName,1,5) as studentname from student
Select LEFT(Studentname,5) as studentname from student
50. 패턴 매칭을 위한 쿼리에서 어떤 연산자를 사용합니까?
LIKE 연산자는 패턴 매칭에 사용되며, -로 사용될 수 있습니다.
- % – XNUMX개 이상의 문자와 일치합니다.
- _(밑줄) – 정확히 한 문자와 일치합니다.
예 -.
Select * from Student where studentname like 'a%'
Select * from Student where studentname like 'ami_'
이 인터뷰 질문은 당신의 비바(구술)에도 도움이 될 것입니다.