K-berarti Clustering di R dengan Contoh
Apa itu Cluster analisis?
Cluster analisis adalah bagian dari belajar tanpa pengawasan. Cluster adalah sekelompok data yang memiliki fitur serupa. Kita dapat mengatakan, analisis clustering lebih tentang penemuan daripada prediksi. Mesin mencari kesamaan dalam data. Misalnya, Anda dapat menggunakan analisis cluster untuk aplikasi berikut:
- Segmentasi pelanggan: Mencari kesamaan antar kelompok pelanggan
- Pengelompokan Pasar Saham: Mengelompokkan saham berdasarkan kinerja
- Mengurangi dimensi dataset dengan cara mengelompokkanping pengamatan dengan nilai serupa
ClusterAnalisis ini tidak terlalu sulit untuk diterapkan dan bermakna serta dapat ditindaklanjuti untuk bisnis.
Perbedaan yang paling mencolok antara pembelajaran yang diawasi dan tidak diawasi terletak pada hasilnya. Pembelajaran tanpa pengawasan menciptakan variabel baru, label, sedangkan pembelajaran dengan pengawasan memprediksi suatu hasil. Mesin tersebut membantu praktisi dalam upaya memberi label pada data berdasarkan keterkaitan yang erat. Terserah analis untuk memanfaatkan grup tersebut dan memberi nama pada grup tersebut.
Mari kita buat contoh untuk memahami konsep pengelompokan. Untuk mempermudah, kita bekerja dalam dua dimensi. Anda memiliki data tentang total pengeluaran pelanggan dan usia mereka. Untuk meningkatkan iklan, tim pemasaran ingin mengirim email yang lebih tertarget kepada pelanggan mereka.
Pada grafik berikut, Anda memetakan total pengeluaran dan usia pelanggan.
library(ggplot2)
df <- data.frame(age = c(18, 21, 22, 24, 26, 26, 27, 30, 31, 35, 39, 40, 41, 42, 44, 46, 47, 48, 49, 54),
spend = c(10, 11, 22, 15, 12, 13, 14, 33, 39, 37, 44, 27, 29, 20, 28, 21, 30, 31, 23, 24)
)
ggplot(df, aes(x = age, y = spend)) +
geom_point()

Sebuah pola terlihat pada titik ini
- Di kiri bawah, Anda dapat melihat generasi muda dengan daya beli lebih rendah
- Kelompok menengah ke atas mencerminkan masyarakat dengan pekerjaan yang mampu mereka belanjakan lebih banyak
- Terakhir, lansia dengan anggaran lebih rendah.

Pada gambar di atas, Anda mengelompokkan pengamatan secara manual dan menentukan masing-masing dari ketiga kelompok tersebut. Contoh ini cukup jelas dan sangat visual. Jika observasi baru ditambahkan ke kumpulan data, Anda dapat memberi label pada observasi tersebut di dalam lingkaran. Anda menentukan lingkaran berdasarkan penilaian kami. Sebagai gantinya, Anda bisa menggunakan Pembelajaran mesin untuk mengelompokkan data secara objektif.
Dalam tutorial ini, Anda akan mempelajari cara menggunakan k-berarti algoritma.
Algoritma K-means
K-mean tidak diragukan lagi merupakan metode pengelompokan yang paling populer. Para peneliti merilis algoritma ini beberapa dekade yang lalu, dan banyak perbaikan telah dilakukan pada k-means.
Algoritma mencoba mencari kelompok dengan meminimalkan jarak antar pengamatan, disebut optimal lokal solusi. Jarak diukur berdasarkan koordinat pengamatan. Misalnya, dalam ruang dua dimensi, koordinatnya sederhana dan .
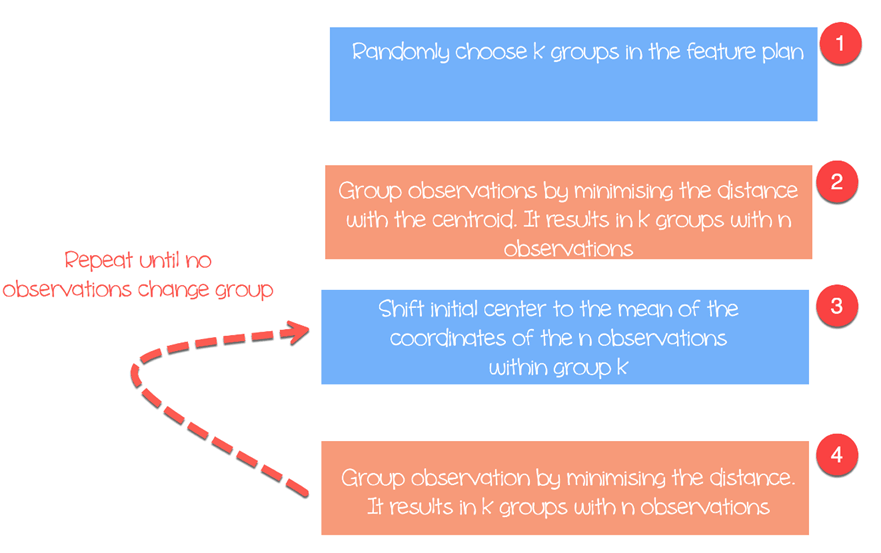
Algoritmanya bekerja sebagai berikut:
- Langkah 1: Pilih grup dalam paket fitur secara acak
- Langkah 2: Minimalkan jarak antara pusat cluster dan observasi yang berbeda (pusat). Ini menghasilkan kelompok dengan observasi
- Langkah 3: Shift pusat massa awal dengan rata-rata koordinat dalam suatu grup.
- Langkah 4: Minimalkan jarak sesuai dengan centroid baru. Batasan baru tercipta. Dengan demikian pengamatan akan berpindah dari satu kelompok ke kelompok lainnya
- Ulangi sampai tidak ada observasi yang mengubah kelompok
K-means biasanya mengambil jarak Euclidean antara fitur dan fitur :

Tersedia ukuran berbeda seperti jarak Manhattan atau jarak Minlowski. Perhatikan bahwa, K-mean mengembalikan grup yang berbeda setiap kali Anda menjalankan algoritme. Ingatlah bahwa tebakan awal pertama bersifat acak dan hitung jaraknya hingga algoritme mencapai homogenitas dalam kelompok. Artinya, k-mean sangat sensitif terhadap pilihan pertama, dan kecuali jumlah observasi dan kelompoknya kecil, hampir tidak mungkin mendapatkan pengelompokan yang sama.
Pilih jumlah cluster
Kesulitan lain yang ditemukan dengan k-mean adalah pemilihan jumlah cluster. Anda dapat menetapkan nilai yang tinggi, yaitu sejumlah besar grup, untuk meningkatkan stabilitas, namun Anda mungkin akan mengalami hal tersebut pakaian luar data. Overfitting berarti kinerja model menurun drastis untuk data baru yang masuk. Mesin mempelajari detail kecil dari kumpulan data dan kesulitan untuk menggeneralisasi pola keseluruhan.
Jumlah cluster bergantung pada sifat kumpulan data, industri, bisnis, dan sebagainya. Namun, ada aturan praktis untuk memilih jumlah cluster yang sesuai:
![]()
dengan sama dengan jumlah observasi dalam dataset.
Secara umum, menarik untuk meluangkan waktu mencari nilai terbaik yang sesuai dengan kebutuhan bisnis.
Kami akan menggunakan kumpulan data Harga Komputer Pribadi untuk melakukan analisis pengelompokan. Dataset ini berisi 6259 observasi dan 10 fitur. Kumpulan data tersebut mengamati harga 1993 komputer pribadi di AS dari tahun 1995 hingga 486. Variabelnya antara lain harga, kecepatan, ram, layar, cd.
Anda akan melanjutkan sebagai berikut:
- Impor data
- Latih modelnya
- Evaluasi modelnya
Impor data
K mean tidak cocok untuk variabel faktor karena didasarkan pada jarak dan nilai diskrit tidak menghasilkan nilai yang berarti. Anda dapat menghapus tiga variabel kategori dalam kumpulan data kami. Selain itu, tidak ada nilai yang hilang dalam dataset ini.
library(dplyr) PATH <-"https://raw.githubusercontent.com/guru99-edu/R-Programming/master/computers.csv" df <- read.csv(PATH) %>% select(-c(X, cd, multi, premium)) glimpse(df)
Keluaran
## Observations: 6, 259 ## Variables: 7 ## $ price < int > 1499, 1795, 1595, 1849, 3295, 3695, 1720, 1995, 2225, 2... ##$ speed < int > 25, 33, 25, 25, 33, 66, 25, 50, 50, 50, 33, 66, 50, 25, ... ##$ hd < int > 80, 85, 170, 170, 340, 340, 170, 85, 210, 210, 170, 210... ##$ ram < int > 4, 2, 4, 8, 16, 16, 4, 2, 8, 4, 8, 8, 4, 8, 8, 4, 2, 4, ... ##$ screen < int > 14, 14, 15, 14, 14, 14, 14, 14, 14, 15, 15, 14, 14, 14, ... ##$ ads < int > 94, 94, 94, 94, 94, 94, 94, 94, 94, 94, 94, 94, 94, 94, ... ## $ trend <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1...
Dari ringkasan statistik, Anda dapat melihat data tersebut memiliki nilai yang besar. Praktik yang baik dalam penghitungan k mean dan jarak adalah dengan mengubah skala data sehingga mean sama dengan satu dan deviasi standar sama dengan nol.
summary(df)
Keluaran:
## price speed hd ram ## Min. : 949 Min. : 25.00 Min. : 80.0 Min. : 2.000 ## 1st Qu.:1794 1st Qu.: 33.00 1st Qu.: 214.0 1st Qu.: 4.000 ` ## Median :2144 Median : 50.00 Median : 340.0 Median : 8.000 ## Mean :2220 Mean : 52.01 Mean : 416.6 Mean : 8.287 ## 3rd Qu.:2595 3rd Qu.: 66.00 3rd Qu.: 528.0 3rd Qu.: 8.000 ## Max. :5399 Max. :100.00 Max. :2100.0 Max. :32.000 ## screen ads trend ## Min. :14.00 Min. : 39.0 Min. : 1.00 ## 1st Qu.:14.00 1st Qu.:162.5 1st Qu.:10.00 ## Median :14.00 Median :246.0 Median :16.00 ## Mean :14.61 Mean :221.3 Mean :15.93 ## 3rd Qu.:15.00 3rd Qu.:275.0 3rd Qu.:21.50 ## Max. :17.00 Max. :339.0 Max. :35.00
Anda mengubah skala variabel dengan fungsi scale() dari perpustakaan dplyr. Transformasi ini mengurangi dampak outlier dan memungkinkan untuk membandingkan observasi tunggal terhadap mean. Jika nilai standar (atau skor-z) tinggi, Anda dapat yakin bahwa pengamatan ini memang berada di atas rata-rata (skor z yang besar menunjukkan bahwa titik ini jauh dari rata-rata dalam standar deviasi. Skor z dua menunjukkan nilainya 2 standar penyimpangan menjauhi mean. Perhatikan, skor-z mengikuti distribusi Gaussian dan simetris di sekitar mean.
rescale_df <- df % > %
mutate(price_scal = scale(price),
hd_scal = scale(hd),
ram_scal = scale(ram),
screen_scal = scale(screen),
ads_scal = scale(ads),
trend_scal = scale(trend)) % > %
select(-c(price, speed, hd, ram, screen, ads, trend))
Basis R mempunyai fungsi untuk menjalankan algoritma k mean. Fungsi dasar dari k mean adalah:
kmeans(df, k) arguments: -df: dataset used to run the algorithm -k: Number of clusters
Latih modelnya
Pada gambar tiga, Anda merinci cara kerja algoritme. Anda dapat melihat setiap langkah secara grafis dengan paket hebat yang dibuat oleh Yi Hui (juga pencipta Knit for Rmarkdown). Animasi paket tidak tersedia di perpustakaan conda. Anda dapat menggunakan cara lain untuk menginstal paket dengan install.packages (“animasi”). Anda dapat memeriksa apakah paket tersebut diinstal di folder Anaconda kami.
install.packages("animation")
Setelah Anda memuat perpustakaan, Anda menambahkan .ani setelah kmeans dan R akan merencanakan semua langkah. Sebagai ilustrasi, Anda hanya menjalankan algoritma dengan variabel hd dan ram yang diubah skalanya dengan tiga cluster.
set.seed(2345) library(animation) kmeans.ani(rescale_df[2:3], 3)
Code Penjelasan
- kmeans.ani(rescale_df[2:3], 3): Pilih kolom 2 dan 3 dari kumpulan data rescale_df dan jalankan algoritme dengan k set ke 3. Plot animasinya.


Anda dapat menafsirkan animasi sebagai berikut:
- Langkah 1: R memilih tiga titik secara acak
- Langkah 2: Hitung jarak Euclidean dan gambar clusternya. Anda memiliki satu cluster berwarna hijau di kiri bawah, satu cluster besar berwarna hitam di sebelah kanan dan satu cluster merah di antara mereka.
- Langkah 3: Hitung pusat massa, yaitu rata-rata cluster
- Ulangi sampai tidak ada perubahan data cluster
Algoritme menyatu setelah tujuh iterasi. Anda dapat menjalankan algoritma k-mean di dataset kami dengan lima cluster dan menyebutnya pc_cluster.
pc_cluster <-kmeans(rescale_df, 5)
- Daftar pc_cluster berisi tujuh elemen menarik:
- pc_cluster$cluster: Menunjukkan cluster dari setiap observasi
- pc_cluster$centers: Pusat cluster
- pc_cluster$totss: Jumlah total kuadrat
- pc_cluster$withinss: Dalam jumlah kuadrat. Jumlah komponen yang dikembalikan sama dengan `k`
- pc_cluster$tot.withinss: Jumlah dalam
- pc_clusterbetweenss: Jumlah total kuadrat dikurangi Dalam jumlah kuadrat
- pc_cluster$size: Jumlah observasi dalam setiap cluster
Anda akan menggunakan jumlah dari jumlah kuadrat (yaitu tot.withinss) untuk menghitung jumlah kluster yang optimal. Menemukan k memang merupakan tugas besar.
k optimal
Salah satu teknik untuk memilih k terbaik disebut metode siku. Metode ini menggunakan homogenitas dalam kelompok atau heterogenitas dalam kelompok untuk mengevaluasi variabilitas. Dengan kata lain, Anda tertarik dengan persentase varians yang dijelaskan oleh setiap cluster. Anda dapat mengharapkan variabilitas meningkat seiring dengan jumlah cluster, sebaliknya heterogenitas menurun. Tantangan kita adalah menemukan k yang melampaui hasil yang semakin berkurang. Menambahkan cluster baru tidak meningkatkan variabilitas data karena hanya sedikit informasi yang tersisa untuk dijelaskan.
Dalam tutorial ini, kita menemukan titik ini menggunakan ukuran heterogenitas. Jumlah kuadrat total dalam kluster adalah tot.withinss dalam daftar yang dikembalikan oleh kmean().
Anda dapat membuat grafik siku dan mencari k optimal sebagai berikut:
- Langkah 1: Buat fungsi untuk menghitung total jumlah kuadrat dalam cluster
- Langkah 2: Jalankan waktu algoritma
- Langkah 3: Buat bingkai data dengan hasil algoritma
- Langkah 4: Plot hasilnya
Langkah 1) Buatlah fungsi untuk menghitung total jumlah kuadrat dalam cluster
Anda membuat fungsi yang menjalankan algoritma k-mean dan menyimpan total dalam jumlah kuadrat cluster
kmean_withinss <- function(k) {
cluster <- kmeans(rescale_df, k)
return (cluster$tot.withinss)
}
Code Penjelasan
- function(k): Mengatur jumlah argumen dalam fungsi
- kmeans(rescale_df, k): Jalankan algoritma sebanyak k kali
- return(cluster$tot.withinss): Menyimpan total dalam cluster jumlah kuadrat
Anda dapat menguji fungsinya dengan sama dengan 2.
Keluaran:
## Try with 2 cluster
kmean_withinss(2)
Keluaran:
## [1] 27087.07
Langkah 2) Jalankan algoritma sebanyak n kali
Anda akan menggunakan fungsi sapply() untuk menjalankan algoritme pada rentang k. Teknik ini lebih cepat dibandingkan membuat loop dan menyimpan nilainya.
# Set maximum cluster max_k <-20 # Run algorithm over a range of k wss <- sapply(2:max_k, kmean_withinss)
Code Penjelasan
- max_k <-20: Tetapkan jumlah maksimum menjadi 20
- sapply(2:max_k, kmean_withinss): Jalankan fungsi kmean_withinss() pada rentang 2:max_k, yaitu 2 hingga 20.
Langkah 3) Buat bingkai data dengan hasil algoritma
Setelah pembuatan dan pengujian fungsi kami, Anda dapat menjalankan algoritme k-mean dalam rentang 2 hingga 20, menyimpan nilai tot.withinss.
# Create a data frame to plot the graph elbow <-data.frame(2:max_k, wss)
Code Penjelasan
- data.frame(2:max_k, wss): Membuat bingkai data dengan output dari penyimpanan algoritma di wss
Langkah 4) Gambarkan hasilnya
Anda memplot grafik untuk memvisualisasikan di mana titik sikunya
# Plot the graph with gglop
ggplot(elbow, aes(x = X2.max_k, y = wss)) +
geom_point() +
geom_line() +
scale_x_continuous(breaks = seq(1, 20, by = 1))

Dari grafik terlihat k optimal adalah tujuh, dimana kurva mulai mengalami penurunan return.
Setelah Anda mendapatkan k optimal, jalankan kembali algoritme dengan k sama dengan 7 dan evaluasi cluster.
Memeriksa cluster
pc_cluster_2 <-kmeans(rescale_df, 7)
Seperti disebutkan sebelumnya, Anda dapat mengakses informasi menarik lainnya dalam daftar yang dikembalikan oleh kmean().
pc_cluster_2$cluster pc_cluster_2$centers pc_cluster_2$size
Bagian evaluasi bersifat subyektif dan bergantung pada penggunaan algoritma. Tujuan kami di sini adalah mengumpulkan komputer dengan fitur serupa. Seorang ahli komputer dapat melakukan pekerjaan dengan tangan dan mengelompokkan komputer berdasarkan keahliannya. Namun, prosesnya akan memakan banyak waktu dan rawan kesalahan. Algoritme K-mean dapat mempersiapkan lapangan untuknya dengan menyarankan cluster.
Sebagai evaluasi sebelumnya, Anda dapat memeriksa ukuran cluster.
pc_cluster_2$size
Keluaran:
## [1] 608 1596 1231 580 1003 699 542
Cluster pertama terdiri dari 608 observasi, sedangkan cluster terkecil nomor 4 hanya memiliki 580 komputer. Homogenitas antar cluster mungkin bagus, jika tidak, persiapan data yang lebih rumit mungkin diperlukan.
Anda dapat melihat data lebih dalam dengan komponen tengah. Baris mengacu pada penomoran cluster dan kolom mengacu pada variabel yang digunakan oleh algoritma. Nilainya adalah skor rata-rata tiap cluster untuk kolom yang diminati. Standardisasi membuat penafsiran menjadi lebih mudah. Nilai positif menunjukkan skor-z untuk cluster tertentu berada di atas rata-rata keseluruhan. Misalnya, cluster 2 memiliki rata-rata harga tertinggi di antara semua cluster.
center <-pc_cluster_2$centers center
Keluaran:
## price_scal hd_scal ram_scal screen_scal ads_scal trend_scal ## 1 -0.6372457 -0.7097995 -0.691520682 -0.4401632 0.6780366 -0.3379751 ## 2 -0.1323863 0.6299541 0.004786730 2.6419582 -0.8894946 1.2673184 ## 3 0.8745816 0.2574164 0.513105797 -0.2003237 0.6734261 -0.3300536 ## 4 1.0912296 -0.2401936 0.006526723 2.6419582 0.4704301 -0.4132057 ## 5 -0.8155183 0.2814882 -0.307621003 -0.3205176 -0.9052979 1.2177279 ## 6 0.8830191 2.1019454 2.168706085 0.4492922 -0.9035248 1.2069855 ## 7 0.2215678 -0.7132577 -0.318050275 -0.3878782 -1.3206229 -1.5490909
Anda dapat membuat peta panas dengan ggplot untuk membantu kami menyoroti perbedaan antar kategori.
Warna default ggplot perlu diubah dengan perpustakaan RColorBrewer. Anda dapat menggunakan conda perpustakaan dan kode untuk diluncurkan di terminal:
conda install -cr r-rcolorbrewer
Untuk membuat peta panas, Anda melanjutkan dalam tiga langkah:
- Bangun bingkai data dengan nilai pusat dan buat variabel dengan jumlah cluster
- Bentuk ulang data dengan fungsi Gather() dari perpustakaan yang lebih rapi. Anda ingin mengubah data dari lebar ke panjang.
- Buat palet warna dengan warnaRampFungsi palet()
Langkah 1) Bangun kerangka data
Mari buat kumpulan data pembentukan ulang
library(tidyr) # create dataset with the cluster number cluster <- c(1: 7) center_df <- data.frame(cluster, center) # Reshape the data center_reshape <- gather(center_df, features, values, price_scal: trend_scal) head(center_reshape)
Keluaran:
## cluster features values ## 1 1 price_scal -0.6372457 ## 2 2 price_scal -0.1323863 ## 3 3 price_scal 0.8745816 ## 4 4 price_scal 1.0912296 ## 5 5 price_scal -0.8155183 ## 6 6 price_scal 0.8830191
Langkah 2) Bentuk ulang datanya
Kode di bawah ini membuat palet warna yang akan Anda gunakan untuk memplot peta panas.
library(RColorBrewer) # Create the palette hm.palette <-colorRampPalette(rev(brewer.pal(10, 'RdYlGn')),space='Lab')
Langkah 3) Visualisasikan
Anda dapat memplot grafik dan melihat seperti apa clusternya.
# Plot the heat map
ggplot(data = center_reshape, aes(x = features, y = cluster, fill = values)) +
scale_y_continuous(breaks = seq(1, 7, by = 1)) +
geom_tile() +
coord_equal() +
scale_fill_gradientn(colours = hm.palette(90)) +
theme_classic()

Ringkasan
Algoritma k-mean dapat kita rangkum pada tabel di bawah ini
| Paket | Tujuan | fungsi | Argumen |
|---|---|---|---|
| mendasarkan | Latih k-mean | kmeans () | df, k |
| Akses kluster | kmeans()$kluster | ||
| Cluster Pusat | kmeans()$pusat | ||
| Cluster ukuran | kmeans()$ukuran |