Sõna manustamine ja Word2Vec koos näitega
⚡ Nutikas kokkuvõte
Sõnade manustamine ja Word2Vec teisendavad teksti tihedateks numbrilisteks vektoriteks, et masinõppe mudelid tunneksid ära sarnase tähendusega sõnad. See ressurss selgitab tehnikat, selle CBOW ja Skip-Grami arhitektuure, aktiveerimisfunktsioone ja täielikku Gensimi implementatsiooni reaalsetes rakendustes.
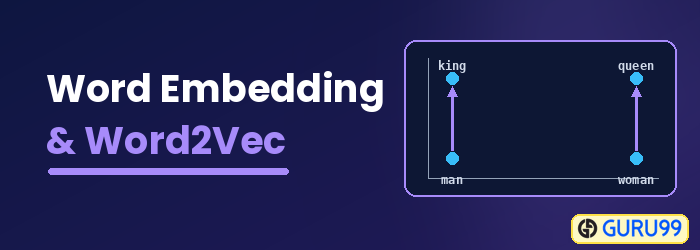
Mis on Wordi manustamine?
Sõna kinnistamine on sõnaesituse tüüp, mis võimaldab masinõppe algoritmidel mõista sarnase tähendusega sõnu. See on keele modelleerimise ja tunnuste õppimise tehnika, mis kaardistab sõnad reaalarvude vektoriteks, kasutades närvivõrke, tõenäosusmudeleid või dimensiooni vähendamist sõnade koosesinemise maatriksi põhjal. Mõned sõnade manustamise mudelid on Word2vec (Google), GloVe (Stanford) ja fastText (Facebook).
Sõna "embedding" nimetatakse ka hajutatud semantiliseks mudeliks, hajutatud esitusmudeliks, semantiliseks vektorruumiks või vektorruumi mudeliks. Neid nimetusi lugedes puutute kokku sõnaga semantiline, mis tähendab sarnaste sõnade liigitamist ühte kohta. Näiteks puuviljad nagu õun, mango ja banaan tuleks paigutada lähestikku, samas kui raamatud paigutatakse neist sõnadest kaugele. Laiemas mõttes loob sõnade manustamine puuviljade vektori, mis paigutatakse raamatute vektorkujutisest kaugele.
Kus Wordi manustamist kasutatakse?
Sõnade manustamine aitab funktsioonide genereerimisel, dokumentide klasterdamisel, teksti klassifitseerimisel ja loomuliku keele töötlemise ülesannetes. Loetleme need rakendused ja arutame igaüht neist.
- Arvutage sarnased sõnad: Sõnade manustamist kasutatakse sarnaste sõnade pakkumiseks ennustusmudelile allutatud sõnale. Lisaks pakub see välja ka erinevaid sõnu ja ka kõige levinumaid sõnu.
- Looge seotud sõnade rühm: Seda kasutatakse semantilise grupeerimise jaoks.ping, mis koondab sarnaste omadustega asjad kokku ja lükkab erinevad esemed kaugele eemale.
- Teksti klassifitseerimise funktsioon: Tekst kaardistatakse vektorite massiivideks, mis suunatakse mudelile nii treenimiseks kui ka ennustamiseks. Tekstipõhiseid klassifikaatorimudeleid ei saa stringide põhjal treenida, seega teisendab see teksti masinõpetatavaks vormiks. Selle semantilise loomise funktsioonid aitavad tekstipõhises klassifitseerimises veelgi kaasa.
- Dokumentide rühmitamine: See on veel üks rakendus, kus Word Embeddingut ja Word2veci kasutatakse laialdaselt.
- Loomuliku keele töötlemine: On palju rakendusi, kus sõnade manustamine on kasulik ja võidab funktsiooninäite ees.tractsioonifaasid, näiteks kõneosade märgistamine, sentimendianalüüs ja süntaktiline analüüs.
Nüüd, kui saate aru, kus sõnade manustamist rakendatakse, vaatame kõige populaarsemat mudelit, mida nende manustamise loomiseks kasutatakse.
Mis on Word2vec?
Word2vec on tehnika või mudel, mis loob sõnade manustamise parema sõnaesituse saavutamiseks. See on loomuliku keele töötlemise meetod, mis jäädvustab suure hulga täpseid süntaktilisi ja semantilisi sõnade seoseid. See on pealiskaudne kahekihiline närvivõrk, mis suudab tuvastada sünonüümseid sõnu ja pakkuda pärast treenimist lisasõnu osaliste lausete jaoks.
Enne edasiminekut vaadake palun erinevust madala ja sügava närvivõrgu vahel, nagu on näidatud alloleval Wordi manustamise näidisdiagrammil:
Madal närvivõrk koosneb ainult ühest peidetud kihist sisendi ja väljundi vahel, samas kui sügav närvivõrk sisaldab sisendi ja väljundi vahel mitut peidetud kihti. Sisend allub sõlmedele, samas kui peidetud kiht, nagu ka väljundkiht, sisaldab neuroneid.
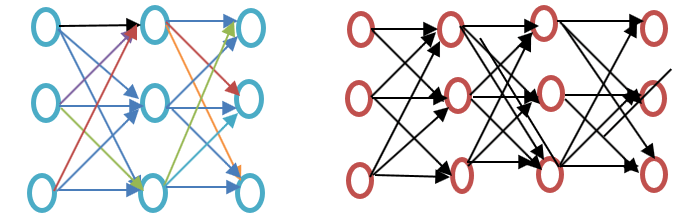
Word2vec on kahekihiline võrk, kus on sisend, üks peidetud kiht ja väljund.
Word2veci töötas välja Tomas Mikolovi juhitud teadlaste rühm aadressil GoogleWord2vec on parem ja tõhusam kui latentse semantilise analüüsi mudel.
Miks Word2vec?
Word2vec esitab sõnu vektorruumi esituses. Sõnu esitatakse vektorite kujul ja paigutus toimub nii, et sarnase tähendusega sõnad esinevad koos ja erinevad sõnad asuvad üksteisest kaugel. Seda nimetatakse ka semantiliseks seoseks. Neuraalvõrgud ei mõista teksti; selle asemel mõistavad nad ainult numbreid. Sõnade manustamine pakub viisi teksti teisendamiseks numbriliseks vektoriks.
Word2vec rekonstrueerib sõnade keelelise konteksti. Enne edasiminekut selgitame välja, mis on keeleline kontekst. Üldjuhul, kui me suhtlemiseks räägime või kirjutame, püüavad teised inimesed lause eesmärki välja mõelda. Näiteks: „Milline on India temperatuur?“. Siin on kontekstiks see, et kasutaja soovib teada „India temperatuuri“. Lühidalt öeldes on lause peamine eesmärk kontekst. Räägitud või kirjutatud keelega seotud sõnad või laused aitavad konteksti tähendust kindlaks teha. Word2vec õpib sõnade vektoresitust nende kontekstide kaudu.
Mida Word2vec teeb?
Enne Wordi manustamist
Oluline on teada, millist lähenemisviisi kasutati enne sõnade manustamist ja millised on selle puudused, ning seejärel vaatame, kuidas neid puudusi Word2veci lähenemisviisi abil sõnade manustamisega ületatakse. Lõpuks vaatame, kuidas Word2vec töötab, sest on oluline mõista selle toimimist.
Varjatud semantilise analüüsi lähenemisviis
Seda lähenemisviisi kasutati enne sõnade manustamist. See kasutas sõnade koti kontseptsiooni, kus sõnad on esitatud kodeeritud vektorite kujul. See on hõre vektori esitus, kus mõõde on võrdne sõnavara suurusega. Kui sõna esineb sõnastikus, siis see loendatakse; vastasel juhul mitte. Lisateabe saamiseks vaadake allolevat programmi.
Word2vec näide

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Väljund:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Selgitus
- CountVectorizer on moodul, mida kasutatakse sõnavara salvestamiseks vastavalt selles leiduvate sõnade sobivusele. See on imporditud sklearnist.
- Loo objekt kasutades klassi CountVectorizer.
- Kirjuta loendisse andmed, mis tuleb CountVectorizerisse mahutada.
- Andmed mahuvad klassist CountVectorizer loodud objekti.
- Sõnade loendamiseks andmetes sõnade abil sõnade koti meetodit rakendatakse. Kui sõna või sümbol sõnavaras puudub, määratakse indeksipositsioon nulliks.
- 5. real olev muutuja, milleks on x, teisendatakse massiiviks (x jaoks saadaolev meetod). See annab iga märgi arvu 3. real antud lauses või loendis.
- See näitab tunnuseid, mis on osa sõnavarast, kui see on 4. rea andmete abil sobitatud.
Latentsemantilise lähenemisviisi puhul tähistab rida unikaalseid sõnu, veerg aga seda, mitu korda see sõna dokumendis esineb. See on sõnade esitus dokumendimaatriksi kujul. Terminisageduse-pöörddokumendisageduse (TF-IDF) meetodit kasutatakse dokumendis esinevate sõnade sageduse loendamiseks, mis on termini sagedus dokumendis jagatuna termini sagedusega kogu korpuses.
Sõnade koti meetodi puudujääk
- See ignoreerib sõnade järjekorda; näiteks see on halb = halb on see.
- See ignoreerib sõnade konteksti. Oletame, et kirjutame lause „Ta armastas raamatuid. Hariduse leiab kõige paremini raamatutest.“ See looks kaks vektorit: ühe lause „Ta armastas raamatuid“ ja teise lause „Hariduse leiab kõige paremini raamatutest“ jaoks. See käsitleks mõlemat ortogonaalsena, mis muudab nad sõltumatuks, kuid tegelikkuses on nad üksteisega seotud.
Nende piirangute ületamiseks töötati välja sõnade manustamine ja Word2vec on üks selle rakendamiseks kasutatud lähenemisviise.
Kuidas Word2vec töötab?
Word2vec õpib sõna, ennustades selle ümbritsevat konteksti. Näiteks võtame sõna „He armastab Jalgpall."
Me tahame arvutada sõna Word2vec väärtuse: armastab.
Oletame:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Sõna armastab liigub korpuses iga sõna kohal. Sõnade süntaktilised ja semantilised seosed kodeeritakse. See aitab leida sarnaseid ja analoogseid sõnu.
Kõik sõna juhuslikud tunnused armastab arvutatakse. Neid tunnuseid muudetakse või uuendatakse naaber- või kontekstisõnade suhtes, kasutades Tagasi paljundamine meetod.
Teine õppimisviis on see, et kui kahe sõna kontekst on sarnane või kahel sõnal on sarnased tunnused, siis on sellised sõnad seotud.
Word2vec Architektuur
Word2vec kasutab kahte arhitektuuri:
- Pidev sõnade kott (CBOW)
- Skip-gramm
Enne edasiminekut arutame, miks need arhitektuurid või mudelid on sõnaesituse seisukohast olulised. Sõnaesituse õppimine on sisuliselt järelevalveta, kuid mudeli treenimiseks on vaja sihtmärke/silte. Skip-gram ja CBOW teisendavad järelevalveta esituse mudeli treenimiseks järelevalve all olevasse vormi.
CBOW-s ennustatakse praegust sõna ümbritsevate kontekstiakende akna abil. Näiteks kui wi-1wi-2wi+1wi+2 kui on antud sõnad või kontekst, pakub see mudel wi.
Skip-Gram toimib CBOW-i vastandina, mis tähendab, et see ennustab sõna põhjal antud järjestust või konteksti. Näite mõistmiseks võite selle ümber pöörata. Kui wi kui see on antud, ennustab see konteksti ehk wi-1wi-2wi+1wi+2.
Word2vec pakub võimalust valida CBOW (pideva sõnade koti) ja skip-grammi vahel. Need parameetrid antakse mudeli treenimise ajal. Saab valida negatiivse valimi või hierarhilise softmax-kihi kasutamise vahel.
Pidev sõnade kott
Joonistame lihtsa Word2vec näidisdiagrammi, et mõista pideva sõnade koti arhitektuuri.

Arvutame võrrandid matemaatiliselt. Oletame, et V on sõnavara suurus ja N on peidetud kihi suurus. Sisend on määratletud kui { xi-1, xi-2, xi+1, xi+2 }. Kaalumaatriksi saame V * N korrutamisel. Teine maatriks saadakse sisendvektori korrutamisel kaalumaatriksiga. Seda saab mõista ka järgmise võrrandi abil.
h = xitW
kus xit ja W on vastavalt sisendvektor ja kaalumaatriks.
Konteksti ja järgmise sõna vahelise vaste arvutamiseks vaadake allolevat võrrandit.
u = ennustatud esitus * h
kus ennustatud esitus saadakse ülaltoodud võrrandi mudelist.
Skip-Gram mudel
Skip-Gram meetodit kasutatakse lause ennustamiseks sisendsõna põhjal. Selle paremaks mõistmiseks joonistame allolevas Word2vec näites näidatud diagrammi.

Seda võib käsitleda kui pideva sõnade koti mudeli vastandit, kus sisendiks on sõna ja mudel pakub konteksti või jada. Samuti võime järeldada, et sihtmärk suunatakse sisendisse ja väljundkihti korratakse mitu korda, et mahutada valitud arvu kontekstisõnu. Kõigi väljundkihtide veavektor summeeritakse, et reguleerida kaalusid tagasilevitamise meetodi abil.
Millist mudelit valida?
CBOW on mitu korda kiirem kui skip-gram ja pakub paremat sagedust sagedaste sõnade jaoks, samas kui skip-gram vajab väikest hulka treeningandmeid ja esindab isegi haruldasi sõnu või fraase. Allolev tabel võrdleb mõlemat arhitektuuri lühidalt.
| Aspekt | CBOW | Skip-Gram |
|---|---|---|
| Ennustus | Ennustab sihtsõna konteksti põhjal | Ennustab sihtsõna konteksti |
| Treeningu kiirus | Kiiremini | Aeglasemalt |
| Sagedased sõnad | Suurem täpsus | Väiksem täpsus |
| Haruldased sõnad | Nõrgem esindatus | Tugevam esindatus |
| Treeningu andmed | Vajab rohkem andmeid | Töötab väiksema andmemahuga |
Word2veci ja NLTK seos
NLTK on loomulik Language Toolkomplekt. Seda kasutatakse teksti eeltöötluseks. Selle abil saab teha erinevaid toiminguid, näiteks kõneosade märgistamine, lemmatiseerimine, tüve loomine, stopp-sõnade eemaldamine ning haruldaste või harvemini kasutatud sõnade eemaldamine. See aitab teksti puhastada ja efektiivsetest sõnadest tunnuseid valmistada. Teisest küljest kasutatakse Word2veci semantiliseks (lähedaselt seotud elemendid omavahel) ja süntaktiliseks (järjestus) sobitamiseks. Word2veci abil saab leida sarnaseid sõnu, erinevaid sõnu, mõõtmete vähendamist ja palju muud. Word2veci teine oluline funktsioon on teksti kõrgemamõõtmelise esituse teisendamine madalamamõõtmelisteks vektoriteks.
Kus kasutada NLTK-d ja Word2veci?
Kui on vaja täita mõningaid üldotstarbelisi ülesandeid, nagu eespool mainitud, näiteks tokeniseerimine, POS-sildistamine ja parsimine, tuleb valida NLTK, samas kui sõnade ennustamiseks vastavalt kontekstile, teema modelleerimisele või dokumentide sarnasusele tuleb kasutada Word2veci.
NLTK ja Word2veci seos koodi abil
NLTK-d ja Word2veci saab koos kasutada sarnaste sõnade esituste või süntaktilise vaste leidmiseks. NLTK tööriistakomplekti saab kasutada paljude NLTK-ga kaasasolevate pakettide laadimiseks ning Word2veci abil saab luua mudeli. Seejärel saab seda reaalajas sõnade peal testida. Vaatleme mõlema kombinatsiooni järgmises koodis. Enne edasist töötlemist vaadake palun NLTK pakutavaid korpusi. Saate selle alla laadida järgmise käsuga:
nltk(nltk.download('all'))

Vaadake koodi ekraanipilti.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Väljund:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Selgitus Code
- Nltk teek imporditakse, kust saate alla laadida abc korpuse, mida me järgmises etapis kasutame.
- Gensim on imporditud. Kui Gensim Word2vec pole installitud, installige see käsuga „pip3 install gensim”. Vaadake allolevat ekraanipilti.

- Impordi abc korpus, mis on alla laaditud nltk.download('abc') abil.
- Edastage failid lausetena Word2vec mudelile, mis imporditakse Gensimi abil.
- Sõnavara salvestatakse muutuja kujul.
- Mudelit testitakse näidissõna peal teadus, kuna need failid on seotud teadusega.
- Siin ennustab mudel sarnast sõna „teadus“.
Aktivaatorid ja Word2Vec
Neuroni aktivatsioonifunktsioon määrab selle neuroni väljundi sisendite komplekti korral. See on bioloogiliselt inspireeritud meie aju aktiivsusest, kus erinevad neuronid aktiveeritakse erinevate stiimulite abil. Vaatleme aktivatsioonifunktsiooni järgmise diagrammi abil.

Siin x1, x2, … x4 on närvivõrgu sõlmed.
w1, w2, w3 on sõlmede kaalud.
Kõigi kaalude ja sõlmede väärtuste summa (Σ) toimib aktiveerimisfunktsioonina.
Miks aktiveerimisfunktsioon?
Kui aktiveerimisfunktsiooni ei kasutata, oleks väljund lineaarne, kuid lineaarfunktsiooni funktsionaalsus on piiratud. Kompleksse funktsionaalsuse, näiteks objektide tuvastamise, piltide klassifitseerimise, saavutamiseks...ping teksti edastamiseks hääle abil ja paljude muude mittelineaarsete väljundite jaoks on vaja aktiveerimisfunktsiooni.
Kuidas arvutatakse aktiveerimiskiht sõna manustamisel (Word2vec)
Softmaxi kiht (normaliseeritud eksponentsiaalfunktsioon) on väljundkihi funktsioon, mis aktiveerib või käivitab iga sõlme. Teine kasutatav lähenemisviis on hierarhiline softmax, kus keerukus arvutatakse O(log2V), samas kui softmaxis on see O(V), kus V on sõnavara suurus. Nende erinevus seisneb hierarhilise softmaxi kihi keerukuse vähendamises. Selle funktsionaalsuse mõistmiseks vaadake allolevat Wordi manustamise näidet:

Oletame, et tahame arvutada sõna vaatlemise tõenäosuse armastus Teatud konteksti korral liigub voog juurest lehesõlme esmalt sõlme 2 ja seejärel sõlme 5. Seega, kui meil on sõnavara suurus 8, on vaja ainult kolme arvutust. See võimaldab ühe sõna tõenäosuse arvutamise lahti võtta (armastus).
Milliseid muid valikuid on peale Hierarchical Softmaxi?
Üldiselt on saadaolevad sõnade manustamise valikud diferentseeritud Softmax, CNN-Softmax, olulisuse valim, adaptiivne olulisuse valim, müra kontrastiivne hindamine, negatiivne valim, enesenormaliseerimine ja harv normaliseerimine.
Täpsemalt Word2veci kohta rääkides on meil saadaval negatiivne valim.
Negatiivne valim on viis treeningandmete valimi võtmiseks. See sarnaneb mõnevõrra stohhastilise gradiendi laskumisega, kuid teatud erinevusega. Negatiivne valim otsib ainult negatiivseid treeningnäiteid. See põhineb müra kontrastiivsel hindamisel ja valib juhuslikult sõnu, mis kontekstis ei ole. See on kiire treeningmeetod ja valib konteksti juhuslikult. Kui ennustatud sõna esineb juhuslikult valitud kontekstis, on mõlemad vektorid üksteisele lähedal.
Millise järelduse saab teha?
Aktivaatorid vallandavad neuroneid täpselt nagu meie neuronid vallanduvad väliste stiimulite mõjul. Softmaxi kiht on üks väljundkihi funktsioonidest, mis vallandab neuronid sõnade manustamise korral. Word2vecis on meil sellised valikud nagu hierarhiline softmax ja negatiivne valim. Aktivaatorite abil saab lineaarse funktsiooni teisendada mittelineaarseks funktsiooniks ja selliste funktsioonide abil saab rakendada keerukat masinõppe algoritmi.
Mis on Gensim?
Gensim on avatud lähtekoodiga teemade modelleerimise ja loomuliku keele töötlemise tööriistakomplekt, mida rakendatakse Python ja Cython. Gensimi tööriistakomplekt võimaldab kasutajatel importida Word2veci teemade modelleerimiseks, et avastada tekstis peidetud struktuuri. Gensim pakub lisaks Word2veci implementatsioonile ka Doc2veci ja FastTexti.
See osa keskendub Word2vecile, seega jääme praeguse teema juurde.
Word2veci rakendamine Gensimi abil
Seni oleme arutanud, mis on Word2vec, selle erinevaid arhitektuure, miks toimub üleminek sõnade kotilt Word2vecile, Word2veci ja NLTK vahelist seost reaalajas koodiga ning aktiveerimisfunktsioone.
Allpool on samm-sammult juhend Word2veci rakendamiseks Gensimi abil:
Samm 1) Andmete kogumine
Esimene samm mis tahes masinõppe mudeli või loomuliku keele töötlemise rakendamisel on andmete kogumine.
Järgige andmeid, et luua intelligentne vestlusrobot, nagu on näidatud allolevas Gensim Word2veci näites.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Siin on see, mida me andmetest aru saame:
- Need andmed sisaldavad kolme asja: silti, mustrit ja vastuseid. Silt on kavatsus (mis on arutelu teema).
- Andmed on JSON-vormingus.
- Muster on küsimus, mille kasutajad robotile esitavad.
- Vastused on vastused, mida vestlusrobot vastavale küsimusele/mustrile annab.
Etapp 2) Andmete eeltöötlus
Väga oluline on algandmete töötlemine. Kui puhastatud andmed sisestatakse masinasse, reageerib mudel täpsemalt ja õpib andmeid tõhusamalt õppima.
See samm hõlmab stoppsõnade, tüve moodustavate sõnade, ebavajalike sõnade jms eemaldamist. Enne jätkamist on oluline andmed laadida ja need andmeraamiks teisendada. Selle kohta vaadake allolevat koodi.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Selgitus Code:
- Kuna andmed on JSON-vormingus, imporditakse JSON.
- Fail salvestatakse muutujasse.
- Fail avatakse ja laaditakse andmemuutujasse.
Nüüd on andmed imporditud ja on aeg need andmeraamiks teisendada. Järgmise sammu kohta vaadake allolevat koodi.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Selgitus Code:
1. Andmed teisendatakse andmeraamiks, kasutades pandasid, mis imporditi eespool.
2. See teisendab veerumustrites oleva loendi stringiks.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Selgitus:
1. Ingliskeelsed stopp-sõnad imporditakse nltk tööriistakomplekti stopp-sõna mooduli abil.
2. Kõik teksti sõnad teisendatakse väiketähtedeks, kasutades for-tingimust ja lambda-funktsiooni. A Lambda funktsioon on anonüümne funktsioon.
3. Kõiki andmeraami tekstiridu kontrollitakse stringi kirjavahemärkide suhtes ja need filtreeritakse.
4. Tähemärgid, näiteks numbrid või punktid, eemaldatakse regulaaravaldise abil.
5. Digits on tekstist eemaldatud.
6. Selles etapis eemaldatakse stoppsõnad.
7. Sõnad filtreeritakse nüüd ja sama sõna erinevad vormid eemaldatakse lemmatiseerimise abil. Sellega oleme andmete eeltöötluse lõpetanud.
Väljund:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Samm 3) Närvivõrgu loomine Word2veci abil
Nüüd on aeg luua mudel, kasutades Gensim Word2vec moodulit. Peame importima Word2veci Gensimist. Teeme seda ja seejärel ehitame selle ning viimases etapis kontrollime mudelit reaalajas andmete peal.
from gensim.models import Word2Vec
Nüüd saame mudeli edukalt Word2Vec'i abil luua. Järgmisest koodireast leiate teavet selle kohta, kuidas Word2Vec'i abil mudelit luua. Tekst antakse mudelile loendi kujul, seega teisendame andmeraami teksti loendiks alloleva koodi abil.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Selgitus Code:
1. Loodud on bigger_list, kuhu sisemine loend lisatakse. See on vorming, mis edastatakse Word2Vec mudelile.
2. Rakendatakse tsükkel ja andmeraami mustrite veeru iga kirjet itereeritakse.
3. Veergude mustrite iga element jagatakse ja salvestatakse sisemisse loendisse li.
4. Sisemisele loendile lisatakse välimine loend.
5. See loend on esitatud Word2Vec mudeli jaoks. Vaatleme mõningaid siin esitatud parameetreid.
Min_count: See ignoreerib kõiki sõnu, mille kogusagedus on sellest madalam.
Suurus: See räägib sõna vektorite mõõtmelisusest.
Töötajad: Need on niidid mudeli treenimiseks.
Saadaval on ka teisi valikuid ja mõned olulised neist on selgitatud allpool.
Aken: Maksimaalne vahemaa praeguse ja ennustatud sõna vahel lauses.
Sg: See on treeningalgoritm: 1 vahelejätmisgrammi ja 0 pideva sõnade koti puhul. Oleme neid eespool üksikasjalikumalt käsitlenud.
Hs: Kui see on 1, siis kasutame treenimiseks hierarhilist softmaxi ja kui 0, siis negatiivset valimit.
Alfa: Esialgne õppimismäär.
Kuvame allpool lõpliku koodi:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Samm 4) Mudeli salvestamine
Mudelit saab salvestada prügikasti ja mudelifailina. Bin on binaarvorming. Mudeli salvestamiseks vaadake allolevaid ridu.
model.save("word2vec.model") model.save("model.bin")
Ülaltoodud koodi selgitus
1. Mudel salvestatakse .model-failina.
2. Mudel salvestatakse .bin-failina.
Kasutame seda mudelit reaalajas testimiseks, näiteks sarnaste sõnade, erinevate sõnade ja kõige levinumate sõnade testimiseks.
Samm 5) Mudeli laadimine ja reaalajas testimine
Mudel laaditakse järgmise koodi abil:
model = Word2Vec.load('model.bin')
Kui soovite sõnavara sealt välja printida, saate seda teha järgmise käsuga:
vocab = list(model.wv.vocab)
Palun vaadake tulemust:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
6. samm) Kõige sarnasemate sõnade kontrollimine
Rakendame asjad praktiliselt:
similar_words = model.most_similar('thanks') print(similar_words)
Palun vaadake tulemust:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Samm 7) Ei vasta sõnale esitatud sõnadest
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Oleme sõnad andnud "Näeme hiljem, tänan külastuse eest"See prindib nendest sõnadest kõige erinevama sõna. Käivitame selle koodi ja leiame tulemuse.
Tulemus pärast ülaltoodud koodi täitmist:
Thanks
8. samm) Kahe sõna sarnasuse leidmine
See näitab tulemust kahe sõna sarnasuse tõenäosuse kaudu. Selle jaotise täitmise kohta vaadake allolevat koodi.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Ülaltoodud koodi tulemus on järgmine:
0.13706
Sarnaseid sõnu saab leida ka järgmise koodi abil:
similar = model.similar_by_word('kind') print(similar)
Ülaltoodud koodi väljund:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]