Kuidas Hadoopi installida UbuntuAllalaadimise ja seadistamise sammud
⚡ Nutikas kokkuvõte
Apache Hadoopi installimine Ubuntu See nõuab kahte etappi: lahtipakki väljalase spetsiaalse süsteemikonto alla paroolivaba SSH-ühenduse abil, seejärel redigeeri nelja XML-faili enne HDFS-i vormindamist ja ühesõlmelise klastri käivitamist.

Selles õpetuses juhendame teid samm-sammult Apache Hadoopi installimise protsessis Linuxi süsteemi (Ubuntu). See on kaheosaline protsess: esmalt laadige alla ja installige väljalase ning seejärel konfigureerige see.
Selleks on kaks eeltingimust:
- Sul peab olema Ubuntu paigaldatud ja jooksmine.
- Sul peab olema Java paigaldatud.
Hadoop 3.x versiooni märkmed selle seadistuse kohta
Selle juhendi ekraanipildid on jäädvustatud Hadoop 2.2.0-ga. Sammude järjestus on praegustes versioonides muutmata, kuid mõned nimed ja vaikesätted on muutunud. Enne mis tahes käsu sõna-sõnalt kopeerimist kontrollige allolevat tabelit.
| Seadistus või samm | Selles õpetuses (Hadoop 2.x) | Praegune Hadoop 3.x |
|---|---|---|
| Väljalaske arhiiv | hadoop-2.2.0.tar.gz |
hadoop-3.5.0.tar.gz, esimene stabiilne 3.5 väljalase, avaldatud 2. aprillil 2026 |
| Vaikimisi failisüsteemi omadus | fs.default.name proosas fs.defaultFS XML-is |
fs.defaultFS ainult; fs.default.name on aegunud |
| MapReduce'i omadus | mapreduce.jobtracker.address |
mapreduce.framework.name seatud yarnTööTracker ei eksisteeri enam, kui YARN töö ajastab |
| mapred-site.xml | Kopeeritud saidilt mapred-site.xml.template |
Saadetakse sisse etc/hadoop juba olemas, seega kopeerimise samm pole vajalik |
| NameNode veebiliidese port | 50070 | 9870 |
| Java | Java 6 või Java 7 | Java 8 või Java 11 |
Kõik muu selles juhendis käitub Hadoop 3-s samamoodi: spetsiaalne konto, SSH-võti, neli konfiguratsioonifaili ning käivitus- ja peatusskriptid.
Osa 1) Laadige alla ja installige Hadoop
1. samm) Lisage Hadoopi süsteemi kasutaja
Lisage Hadoopi süsteemi kasutaja alloleva käsu abil.
sudo addgroup hadoop_

sudo adduser --ingroup hadoop_ hduser_
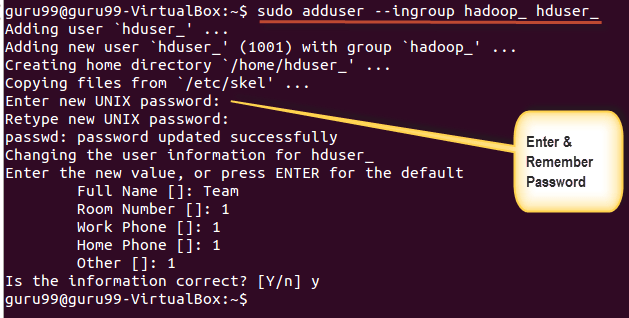
Sisestage oma parool, nimi ja muud andmed.
MÄRKUS: Selle seadistamis- ja installiprotsessi käigus on võimalik allpool mainitud tõrge.
"hduser ei ole sudoersi failis. Sellest juhtumist teatatakse."

Selle vea saab lahendada root-kasutajana sisse logides.

Käivitage käsk
sudo adduser hduser_ sudo

Re-login as hduser_

Samm 2) Konfigureerige SSH
Klastri sõlmede haldamiseks vajab Hadoop SSH-juurdepääsu.
Esmalt vahetage kasutajat ja sisestage järgmine käsk
su - hduser_

See käsk loob uue võtme.
ssh-keygen -t rsa -P ""

Luba selle võtme abil SSH-juurdepääs kohalikule masinale.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
![]()
Nüüd testige SSH seadistust, ühendudes localhostiga kasutajana 'hduser_'.
ssh localhost

Märge: Kui näete vastusena käsule „ssh localhost” allolevat veateadet, on võimalik, et SSH pole selles süsteemis saadaval.

Selle lahendamiseks –
Puhastage SSH, kasutades
sudo apt-get purge openssh-server
Enne paigaldamise alustamist on hea tava puhastada.

Installige SSH, kasutades käsku-
sudo apt-get install openssh-server

Samm 3) Laadige alla Hadoop
Järgmine samm on Hadoopi allalaadimine saidilt Apache Hadoopi väljaannete leht.

Valige Stabiilne

Valige fail tar.gz (mitte fail, mille laiendiks on src).

Kui allalaadimine on lõppenud, navigeerige kataloogi, kus asub tar-fail.
![]()
sisesta,
sudo tar xzf hadoop-2.2.0.tar.gz
![]()
Nüüd nimeta hadoop-2.2.0 ümber hadoopiks.
sudo mv hadoop-2.2.0 hadoop
![]()
Lõpuks andke kaust uuele kontole üle.
sudo chown -R hduser_:hadoop_ hadoop
![]()
Asenda see versioon, mille sa tegelikult alla laadisid hadoop-2.2.0 kolmes ülaltoodud käsus.
2. osa) Hadoopi konfigureerimine
1. samm) Muutke faili ~/.bashrc
Lisa faili ~/.bashrc lõppu järgmised read.
#Set HADOOP_HOME export HADOOP_HOME=<Installation Directory of Hadoop> #Set JAVA_HOME export JAVA_HOME=<Installation Directory of Java> # Add bin/ directory of Hadoop to PATH export PATH=$PATH:$HADOOP_HOME/bin
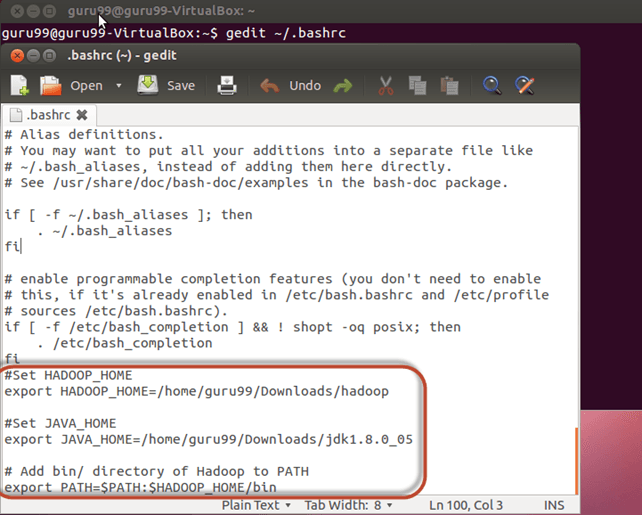
Nüüd hankige see keskkonnakonfiguratsioon alloleva käsu abil.
. ~/.bashrc
![]()
2. samm) HDFS-iga seotud konfiguratsioonid
Seadista JAVA_HOME faili $HADOOP_HOME/etc/hadoop/hadoop-env.sh, nagu allpool näidatud.
![]()

koos

Failis $HADOOP_HOME/etc/hadoop/core-site.xml on kaks parameetrit, mis tuleb määrata -
1. „hadoop.tmp.dir” – Kasutatakse kataloogi määramiseks, mida Hadoop kasutab oma andmefailide salvestamiseks.
2. „fs.defaultFS” – See määrab vaikimisi failisüsteemi. Sama atribuudi vanem nimi „fs.default.name” on aegunud.
Nende parameetrite määramiseks avage core-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/core-site.xml
![]()
Kopeeri allolevad read nende vahele sildid.
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>

Navigeeri kataloogi $HADOOP_HOME/etc/hadoop.

Nüüd looge failis core-site.xml mainitud kataloog.
sudo mkdir -p <Path of Directory used in above setting>
![]()
Andke kataloogile õigused.
sudo chown -R hduser_:Hadoop_ <Path of Directory created in above step>
![]()
sudo chmod 750 <Path of Directory created in above step>
![]()
3. samm) MapReduce'i seadistamine
Enne nende konfiguratsioonidega alustamist määrame HADOOP_HOME tee.
sudo gedit /etc/profile.d/hadoop.sh
Ja Sisestage
export HADOOP_HOME=/home/guru99/Downloads/Hadoop

Järgmisena sisestage
sudo chmod +x /etc/profile.d/hadoop.sh
![]()
Väljuge terminalist ja taaskäivitage uuesti.
Tee kinnitamiseks tippige echo $HADOOP_HOME.
![]()
Nüüd kopeerige failid
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
![]()
Avage fail mapred-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml
![]()
Lisage allolevad sätted vahele ja sildid.
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>MapReduce job tracker runs at this host and port. </description> </property>

Avage $HADOOP_HOME/etc/hadoop/hdfs-site.xml nagu allpool näidatud,
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml
![]()
Lisage allolevad sätted vahele ja sildid.
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>

Looge ülaltoodud seadistuses määratud kataloog.
sudo mkdir -p <Path of Directory used in above setting>
sudo mkdir -p /home/hduser_/hdfs
![]()
Seejärel andke sellele omandiõigus ja õigused.
sudo chown -R hduser_:hadoop_ <Path of Directory created in above step>
sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs
![]()
sudo chmod 750 <Path of Directory created in above step>
sudo chmod 750 /home/hduser_/hdfs
![]()
4. samm) HDFS-i vormindamine
Enne Hadoopi esmakordset käivitamist vormindage HDFS alloleva käsu abil.
$HADOOP_HOME/bin/hdfs namenode -format

5. samm) Käivitage Hadoopi ühe sõlme klaster
Käivitage Hadoopi ühe sõlme klaster alloleva käsuga.
$HADOOP_HOME/sbin/start-dfs.sh
Ülaltoodud käsu väljund on näidatud allpool.

Seejärel käivitage YARN-deemonid.
$HADOOP_HOME/sbin/start-yarn.sh

Kontrollige tööriista 'jps' abil, kas kõik Hadoopiga seotud protsessid töötavad.
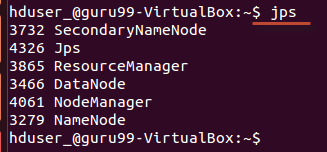
Kui Hadoop on edukalt käivitunud, peaks jps-i väljund kuvama NameNode, NodeManager, ResourceManager, SecondaryNameNode ja DataNode.
6. samm) Peatusping hadoop
Klapi sulgemine toimub vastupidises järjekorras.
$HADOOP_HOME/sbin/stop-dfs.sh

$HADOOP_HOME/sbin/stop-yarn.sh

Kuidas kontrollida, kas Hadoop töötab, ja parandada levinud vigu
jps-i väljund kinnitab protsesside käivitumist, kuid mitte klastri kasutatavust. Sellele küsimusele vastavad neli lisakontrolli.
- Ava NameNode veebiliides aadressil
http://localhost:9870(Hadoop 2.x-il port 50070) ja kinnitage, et kokkuvõte annab aru ühest aktiivsest sõlmest. - Avage ResourceManageri liides aadressil
http://localhost:8088et kinnitada, et YARN aktsepteeris NodeManageri. - jooks
hdfs dfsadmin -reportmahutavuse, reaalajas andmesõlmede ja kõigi alakasutatud plokkide puhul. - Kirjuta midagi:
hdfs dfs -mkdir /testjärgnevadhdfs dfs -ls /tõestab, et nimeruum aktsepteerib muudatusi.
Enamik esmakordseid ebaõnnestumisi jaguneb ühte viiest kategooriast.
| Sümptom | Põhjus | Määrama |
|---|---|---|
| JAVA_HOME pole määratud ja seda ei leitud | Muutuja eksporditakse faili .bashrc, aga mitte faili hadoop-env.sh | Määrake ka absoluutne JDK tee failis hadoop-env.sh |
| Luba keelatud (avalik võti, parool) ssh localhost'is | authorized_keys puudub või on liiga lubav | Lisa uuesti id_rsa.pub ja seejärel käivita chmod 600 failil ~/.ssh/authorized_keys |
| Ühendus keelatud pordil 22 | openssh-server pole installitud või ei tööta | Paigalda openssh-server ja käivita ssh-teenus |
| JPS-ist puudub pärast ümbervormindamist DataNode | Cluster Vormindatud NameNode'i ja vana DataNode'i kataloogi ID ei vasta nõuetele | Tühjenda kaust dfs.datanode.data.dir ja vorminda see uuesti. |
| start-dfs.sh: käsku ei leitud | HADOOP_HOME ja PATH ei olnud praeguses kestas kunagi allikana olemas | Käivita .~/.bashrc või ava uus terminal |