GLM v R: Zobecněný lineární model a logistická regrese
⚡ Chytré shrnutí
Zobecněný lineární model (GLM) v jazyce R rozšiřuje běžnou regresi na výsledky, které jsou binární, založené na počtu nebo nenormální. Tento návod vytváří logistický GLM na datové sadě o příjmech dospělých a vyhodnocuje jej s přesností, precizností, úplností a ROC.

Co je to zobecněný lineární model (GLM) v jazyce R?
A Zobecněný lineární model (GLM) rozšiřuje běžnou lineární regresi tak, že odezvová proměnná může sledovat jiné rozdělení než normální. V R, vejde se vám jeden s vestavěným glm() funkce ze statistického balíčku.
Každý GLM je definován třemi složkami:
- Náhodná složka: rozdělení pravděpodobnosti odezvy proměnné, převzaté z exponenciální rodiny (binomické, Poissonovo, gama, Gaussovo a další).
- Systematická složka: lineární prediktor, což je vážená kombinace vašich vysvětlujících proměnných.
- Funkce odkazu: funkce, která spojuje průměr odezvy s lineárním prediktorem, například logitový odkaz pro binární data nebo logaritmický odkaz pro počty.
Tato struktura dělá model „zobecněným“. Místo vynucování normálně rozděleného výsledku deklarujete správné rozdělení prostřednictvím rodina argument a R odhaduje koeficienty metodou maximální věrohodnosti. Logistická regrese je jednoduše GLM s binomickou rodinou a logitovým propojením, takže je přirozeným výchozím bodem.
Co je logistická regrese v jazyce R?
Logistická regrese se používá k predikci třídy, tj. pravděpodobnosti. Logistická regrese dokáže přesně předpovědět binární výsledek.
Představte si, že chcete předpovědět, zda bude půjčka zamítnuta/přijata na základě mnoha atributů. Logistická regrese má tvar 0/1. y = 0, pokud je půjčka zamítnuta, y = 1, pokud je přijata.
Logistický regresní model se liší od lineárního regresního modelu dvěma způsoby.
- Za prvé, logistická regrese akceptuje pouze dichotomický (binární) vstup jako závisle proměnnou (tj. vektor 0 a 1).
- Za druhé, výsledek je mapován pomocí pravděpodobnostní spojovací funkce zvané sigmatu (logistická) funkce díky svému tvaru písmene S:

Výstup funkce je vždy mezi 0 a 1. Zkontrolujte obrázek níže
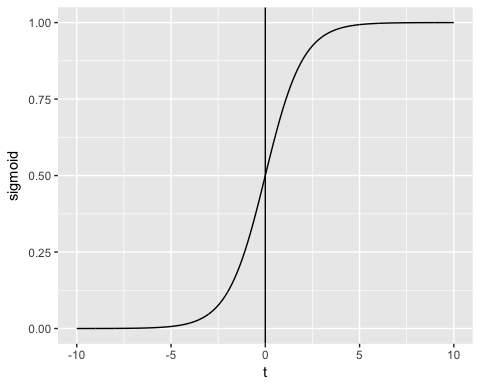
Funkce sigmoid vrací hodnoty od 0 do 1. Pro klasifikační úlohu potřebujeme diskrétní výstup 0 nebo 1.
Pro převod spojitého toku na diskrétní hodnotu můžeme nastavit rozhodovací hranici na 0.5. Všechny hodnoty nad touto hranicí jsou klasifikovány jako 1

Nyní, když je funkce spojnice jasná, porovnejte zobecněný model s běžným lineárním modelem, který již znáte.
GLM vs. lineární regrese: Klíčové rozdíly v R
Než začnete psát jakýkoli kód, je užitečné vědět přesně, kdy bude standard lineární regrese Funkce lm() již není vhodná a měla by ji nahradit funkce glm().
| Kritéria | Lineární regrese (lm) | Zobecněný lineární model (glm) |
|---|---|---|
| Proměnná odezvy | Nepřetržitý a neomezený | Binární, početní, úměrný nebo kladný spojitý |
| Rozložení chyb | Pouze normální | Jakýkoli exponenciální člen rodiny |
| Funkce propojení | Identita (implicitní) | Explicitní: logit, logaritm, inverzní, probit |
| Metoda odhadu | Obyčejné nejmenší čtverce | Maximální pravděpodobnost (IRLS) |
| Předpoklad rozptylu | Konstantní napříč pozorováními | Povoleno záviset na průměru |
| Měření shody | R-kvadrát | AIC a reziduální odchylka |
| R funkce | lm(vzorec, data) | glm(vzorec, data, rodina) |
Stručně řečeno, zvolte lm(), když je výsledkem normálně distribuované měření, a glm() vždy, když je výsledkem rozhodnutí ano/ne, což je úkol, který byste jinak mohli svěřit... rozhodovací strom klasifikátor, počet událostí nebo striktně kladná veličina, jejíž rozptyl roste s její střední hodnotou.
Jak vytvořit zobecněný lineární model (GLM) v jazyce R
Po ujasnění teorie zbytek tohoto tutoriálu aplikuje binomický GLM kompletně na reálnou datovou sadu.
Pojďme použít dospělý Datová sada pro ilustraci logistické regrese. „Dospělý“ je skvělou datovou sadou pro klasifikační úkol. Cílem je předpovědět, zda roční příjem jednotlivce v amerických dolarech přesáhne 50 000. Datová sada obsahuje 48 842 pozorování a deset proměnných:
- věk: věk jedince. Numerický
- vzdělání: Vzdělanostní úroveň jedince. Faktor.
- rodinný.stav: Maristav jednotlivce. Faktor, tj. nikdy nevdaná, vdaná-občanská manželka, …
- pohlaví: Pohlaví jednotlivce. Faktor, tedy Muž nebo Žena
- příjem: Target variabilní. Příjem nad nebo pod 50 tis. Faktor, tj. >50K, <=50K
mimo jiné
library(dplyr) data_adult <-read.csv("https://raw.githubusercontent.com/guru99-edu/R-Programming/master/adult.csv") glimpse(data_adult)
Výstup:
Observations: 48,842 Variables: 10 $ x <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15,... $ age <int> 25, 38, 28, 44, 18, 34, 29, 63, 24, 55, 65, 36, 26... $ workclass <fctr> Private, Private, Local-gov, Private, ?, Private,... $ education <fctr> 11th, HS-grad, Assoc-acdm, Some-college, Some-col... $ educational.num <int> 7, 9, 12, 10, 10, 6, 9, 15, 10, 4, 9, 13, 9, 9, 9,... $ marital.status <fctr> Never-married, Married-civ-spouse, Married-civ-sp... $ race <fctr> Black, White, White, Black, White, White, Black, ... $ gender <fctr> Male, Male, Male, Male, Female, Male, Male, Male,... $ hours.per.week <int> 40, 50, 40, 40, 30, 30, 40, 32, 40, 10, 40, 40, 39... $ income <fctr> <=50K, <=50K, >50K, >50K, <=50K, <=50K, <=50K, >5...
Budeme postupovat následovně:
- Krok 1: Zkontrolujte spojité proměnné
- Krok 2: Zkontrolujte proměnné faktoru
- Krok 3: Funkce
- Krok 4: Souhrnná statistika
- Krok 5: Trénink/testovací sada
- Krok 6: Sestavte model
- Krok 7: Posuďte výkon modelu
- Krok 8: Vylepšete model
Vaším úkolem je předpovědět, která osoba bude mít tržby vyšší než 50 tisíc.
V tomto tutoriálu bude každý krok podrobně popsán k provedení analýzy skutečné datové sady.
Krok 1) Zkontrolujte spojité proměnné
V prvním kroku můžete vidět rozložení spojitých proměnných.
continuous <-select_if(data_adult, is.numeric) summary(continuous)
Code Vysvětlení
- kontinuální <- select_if(data_adult, is.numeric): Pomocí funkce select_if() z knihovny dplyr vyberte pouze číselné sloupce
- souhrn (nepřetržitý): Tisk souhrnné statistiky
Výstup:
## X age educational.num hours.per.week ## Min. : 1 Min. :17.00 Min. : 1.00 Min. : 1.00 ## 1st Qu.:11509 1st Qu.:28.00 1st Qu.: 9.00 1st Qu.:40.00 ## Median :23017 Median :37.00 Median :10.00 Median :40.00 ## Mean :23017 Mean :38.56 Mean :10.13 Mean :40.95 ## 3rd Qu.:34525 3rd Qu.:47.00 3rd Qu.:13.00 3rd Qu.:45.00 ## Max. :46033 Max. :90.00 Max. :16.00 Max. :99.00
Z výše uvedené tabulky můžete vidět, že data mají úplně jiná měřítka a hodiny za týden mají velké odlehlé hodnoty (např. podívejte se na poslední kvartil a maximální hodnotu).
Můžete si s tím poradit ve dvou krocích:
- Vykreslete rozložení hodin za týden
- Standardizujte spojité proměnné
- Zakreslete distribuci
Podívejme se blíže na rozložení hodin.za.týden
# Histogram with kernel density curve library(ggplot2) ggplot(continuous, aes(x = hours.per.week)) + geom_density(alpha = .2, fill = "#FF6666")
Výstup:

Proměnná má mnoho odlehlých hodnot a není dobře definovaná distribuce. Tento problém můžete částečně vyřešit odstraněním horních 0.01 procenta hodin týdně.
Základní syntaxe kvantilu:
quantile(variable, percentile) arguments: -variable: Select the variable in the data frame to compute the percentile -percentile: Can be a single value between 0 and 1 or multiple value. If multiple, use this format: `c(A,B,C, ...) - `A`,`B`,`C` and `...` are all integer from 0 to 1.
Vypočítáváme 99. percentil týdenní pracovní doby.
top_one_percent <- quantile(data_adult$hours.per.week, .99)
top_one_percent
Code Vysvětlení
- kvantil(data_adult$hours.per.week, .99): Vypočítá 99. percentil týdenní pracovní doby
Výstup:
## 99% ## 80
99 procent populace pracuje pod 80 hodin týdně.
Pozorování můžete pustit nad tuto hranici. Používáte filtr z dplyr knihovna.
data_adult_drop <-data_adult %>% filter(hours.per.week<top_one_percent) dim(data_adult_drop)
Výstup:
## [1] 45537 10
- Standardizujte spojité proměnné
Každý sloupec můžete standardizovat, abyste zlepšili výkon, protože vaše data nemají stejné měřítko. Můžete použít funkci mutate_if z knihovny dplyr. Základní syntaxe je:
mutate_if(df, condition, funs(function)) arguments: -`df`: Data frame used to compute the function - `condition`: Statement used. Do not use parenthesis - funs(function): Return the function to apply. Do not use parenthesis for the function
Číselné sloupce můžete standardizovat následovně:
data_adult_rescale <- data_adult_drop %>% mutate_if(is.numeric, funs(as.numeric(scale(.)))) head(data_adult_rescale)
Code Vysvětlení
- mutate_if(is.numeric, funs(scale)): Podmínka je pouze číselný sloupec a funkce je měřítko
Výstup:
## X age workclass education educational.num ## 1 -1.732680 -1.02325949 Private 11th -1.22106443 ## 2 -1.732605 -0.03969284 Private HS-grad -0.43998868 ## 3 -1.732530 -0.79628257 Local-gov Assoc-acdm 0.73162494 ## 4 -1.732455 0.41426100 Private Some-college -0.04945081 ## 5 -1.732379 -0.34232873 Private 10th -1.61160231 ## 6 -1.732304 1.85178149 Self-emp-not-inc Prof-school 1.90323857 ## marital.status race gender hours.per.week income ## 1 Never-married Black Male -0.03995944 <=50K ## 2 Married-civ-spouse White Male 0.86863037 <=50K ## 3 Married-civ-spouse White Male -0.03995944 >50K ## 4 Married-civ-spouse Black Male -0.03995944 >50K ## 5 Never-married White Male -0.94854924 <=50K ## 6 Married-civ-spouse White Male -0.76683128 >50K
Krok 2) Zkontrolujte proměnné faktoru
Tento krok má dva cíle:
- Zkontrolujte úroveň v každém kategorickém sloupci
- Definujte nové úrovně
Tento krok rozdělíme na tři části:
- Vyberte kategorické sloupce
- Uložte sloupcový graf každého sloupce do seznamu
- Vytiskněte grafy
Sloupce faktoru můžeme vybrat pomocí kódu níže:
# Select categorical column factor <- data.frame(select_if(data_adult_rescale, is.factor)) ncol(factor)
Code Vysvětlení
- data.frame(select_if(data_adult, is.factor)): Sloupce faktoru ukládáme faktorem v typu datového rámce. Knihovna ggplot2 vyžaduje objekt datového rámce.
Výstup:
## [1] 6
Dataset obsahuje 6 kategoriálních proměnných
Druhý krok je náročnější. Chcete vykreslit sloupcový graf pro každý sloupec v datovém rámci. Je pohodlnější proces automatizovat, zejména v případě velkého množství sloupců.
library(ggplot2) # Create graph for each column graph <- lapply(names(factor), function(x) ggplot(factor, aes(get(x))) + geom_bar() + theme(axis.text.x = element_text(angle = 90)))
Code Vysvětlení
- lapply(): Použijte funkci lapply() k předání funkce ve všech sloupcích datové sady. Výstup uložíte do seznamu
- function(x): Funkce bude zpracována pro každé x. Zde x jsou sloupce
- ggplot(factor, aes(get(x))) + geom_bar()+ theme(axis.text.x = element_text(angle = 90)): Vytvořte pruhový znakový graf pro každý x prvek. Všimněte si, že chcete-li vrátit x jako sloupec, musíte jej zahrnout do get()
Poslední krok je poměrně snadný. Chcete vytisknout 6 grafů.
# Print the graph
graph
Výstup:
## [[1]]

## ## [[2]]

## ## [[3]]

## ## [[4]]

## ## [[5]]

## ## [[6]]

Poznámka: Pomocí tlačítka Další přejděte na další graf

Krok 3) Inženýrství funkcí
Dvě kategoriální proměnné nesou více úrovní, než model potřebuje. Seskupíte je do širších, lépe zaplněných kategorií.
Přepracování vzdělávání
Z výše uvedeného grafu vidíte, že proměnná vzdělání má 16 úrovní. To je podstatné a některé úrovně mají relativně nízký počet pozorování. Pokud chcete zlepšit množství informací, které můžete z této proměnné získat, můžete ji přetvořit na vyšší úroveň. Totiž vytváříte větší skupiny s podobnou úrovní vzdělání. Nízká úroveň vzdělání bude například převedena na předčasný odchod. Vyšší stupně vzdělání se změní na mistrovské.
Zde je detail:
| Stará úroveň | Nová úroveň |
|---|---|
| Předškolní | výpadek |
| 10. | Výpadek |
| 11. | Výpadek |
| 12. | Výpadek |
| 1.-4 | Výpadek |
| 5th-6th | Výpadek |
| 7th-8th | Výpadek |
| 9. | Výpadek |
| HS-Grad | HighGrad |
| Některé vysoké školy | Naše projekty |
| Assoc-acdm | Naše projekty |
| Assoc-voc | Naše projekty |
| Bachelors | Bachelors |
| Masters | Masters |
| Prof-škola | Masters |
| Doktorát | PhD |
recast_data <- data_adult_rescale %>% select(-X) %>% mutate(education = factor(ifelse(education == "Preschool" | education == "10th" | education == "11th" | education == "12th" | education == "1st-4th" | education == "5th-6th" | education == "7th-8th" | education == "9th", "dropout", ifelse(education == "HS-grad", "HighGrad", ifelse(education == "Some-college" | education == "Assoc-acdm" | education == "Assoc-voc", "Community", ifelse(education == "Bachelors", "Bachelors", ifelse(education == "Masters" | education == "Prof-school", "Master", "PhD")))))))
Code Vysvětlení
- Používáme sloveso mutate z knihovny dplyr. Hodnoty vzdělání měníme výrokem ifelse
V níže uvedené tabulce vytvoříte souhrnnou statistiku, abyste v průměru viděli, kolik let vzdělání (hodnota z) je potřeba k dosažení bakalářského, magisterského nebo doktorského studia.
recast_data %>% group_by(education) %>% summarize(average_educ_year = mean(educational.num), count = n()) %>% arrange(average_educ_year)
Výstup:
## # A tibble: 6 x 3 ## education average_educ_year count ## <fctr> <dbl> <int> ## 1 dropout -1.76147258 5712 ## 2 HighGrad -0.43998868 14803 ## 3 Community 0.09561361 13407 ## 4 Bachelors 1.12216282 7720 ## 5 Master 1.60337381 3338 ## 6 PhD 2.29377644 557
Přepracovat Marital-stav
Je také možné vytvořit nižší úrovně pro rodinný stav. V následujícím kódu změníte úroveň následovně:
| Stará úroveň | Nová úroveň |
|---|---|
| Se nikdy neoženil | Není vdaná |
| Ženatý-manžel-nepřítomný | Není vdaná |
| Ženatý-AF-manžel | Ženatý |
| Ženatý občan | |
| Oddělil | Oddělil |
| Rozvedený | |
| Vdovy | Vdova |
# Change level marry recast_data <- recast_data %>% mutate(marital.status = factor(ifelse(marital.status == "Never-married" | marital.status == "Married-spouse-absent", "Not_married", ifelse(marital.status == "Married-AF-spouse" | marital.status == "Married-civ-spouse", "Married", ifelse(marital.status == "Separated" | marital.status == "Divorced", "Separated", "Widow")))))
Můžete zkontrolovat počet jednotlivců v každé skupině.
table(recast_data$marital.status)
Výstup:
## ## Married Not_married Separated Widow ## 21165 15359 7727 1286
Krok 4) Souhrnná statistika
Je čas zkontrolovat některé statistiky o našich cílových proměnných. V níže uvedeném grafu spočítáte procento jednotlivců, kteří vydělávají více než 50 tisíc vzhledem k jejich pohlaví.
# Plot gender income ggplot(recast_data, aes(x = gender, fill = income)) + geom_bar(position = "fill") + theme_classic()
Výstup:

Dále zkontrolujte, zda původ jednotlivce ovlivňuje jeho výdělky.
# Plot origin income ggplot(recast_data, aes(x = race, fill = income)) + geom_bar(position = "fill") + theme_classic() + theme(axis.text.x = element_text(angle = 90))
Výstup:
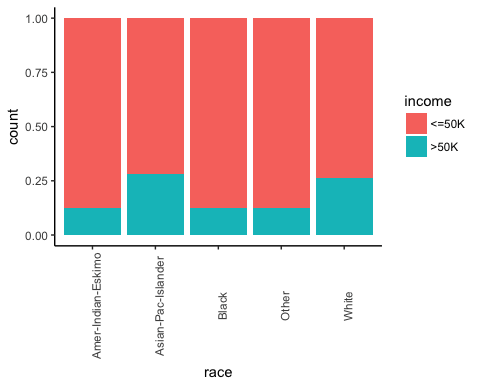
Počet hodin práce podle pohlaví.
# box plot gender working time ggplot(recast_data, aes(x = gender, y = hours.per.week)) + geom_boxplot() + stat_summary(fun.y = mean, geom = "point", size = 3, color = "steelblue") + theme_classic()
Výstup:

Krabicový graf potvrzuje, že rozložení pracovní doby vyhovuje různým skupinám. V krabicovém grafu nemají obě pohlaví homogenní pozorování.
Hustotu týdenní pracovní doby si můžete ověřit podle typu vzdělání. Rozložení má mnoho odlišných preferencí. Pravděpodobně to lze vysvětlit typem vzdělání.tract v USA.
# Plot distribution working time by education ggplot(recast_data, aes(x = hours.per.week)) + geom_density(aes(color = education), alpha = 0.5) + theme_classic()
Code Vysvětlení
- ggplot(recast_data, aes(x= hours.per.week)): Graf hustoty vyžaduje pouze jednu proměnnou
- geom_density(aes(barva = vzdělání), alfa =0.5): Geometrický objekt pro řízení hustoty
Výstup:

Chcete-li potvrdit své myšlenky, můžete provést jednosměrný postup Test ANOVA:
anova <- aov(hours.per.week~education, recast_data) summary(anova)
Výstup:
## Df Sum Sq Mean Sq F value Pr(>F) ## education 5 1552 310.31 321.2 <2e-16 *** ## Residuals 45531 43984 0.97 ## --- ## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Test ANOVA potvrzuje rozdíl v průměru mezi skupinami.
Nelinearita
Před spuštěním modelu můžete zjistit, zda počet odpracovaných hodin souvisí s věkem.
library(ggplot2) ggplot(recast_data, aes(x = age, y = hours.per.week)) + geom_point(aes(color = income), size = 0.5) + stat_smooth(method = 'lm', formula = y~poly(x, 2), se = TRUE, aes(color = income)) + theme_classic()
Code Vysvětlení
- ggplot(recast_data, aes(x = věk, y = hodiny.za.týden)): Nastavení estetiky grafu
- geom_point(aes(barva= příjem), velikost =0.5): Vytvořte bodový graf
- stat_smooth(): Přidejte trendovou linii s následujícími argumenty:
- method='lm': Vykreslete přizpůsobenou hodnotu, pokud je lineární regrese
- vzorec = y~poly(x,2): Fit polynomiální regrese
- se = TRUE: Přidá standardní chybu
- aes(barva= příjem): Rozdělte model podle příjmu
Výstup:

Stručně řečeno, můžete otestovat podmínky interakce v modelu, abyste zjistili nelineární efekt mezi týdenní pracovní dobou a dalšími funkcemi. Je důležité zjistit, za jakých podmínek se liší pracovní doba.
Korelace
Další kontrolou je vizualizace korelace mezi proměnnými. Typ úrovně faktoru převedete na numerický, abyste mohli vykreslit tepelnou mapu obsahující koeficient korelace vypočítaný Spearmanovou metodou.
library(GGally) # Convert data to numeric corr <- data.frame(lapply(recast_data, as.integer)) # Plot the graphggcorr(corr, method = c("pairwise", "spearman"), nbreaks = 6, hjust = 0.8, label = TRUE, label_size = 3, color = "grey50")
Code Vysvětlení
- data.frame(lapply(recast_data,as.integer)): Převede data na číselná
- ggcorr() vykresluje tepelnou mapu s následujícími argumenty:
- metoda: Metoda pro výpočet korelace
- nbreaks = 6: Počet přerušení
- hjust = 0.8: Kontrolní pozice názvu proměnné v grafu
- label = TRUE: Přidat štítky do středu oken
- label_size = 3: Velikost štítků
- barva = “šedá50”): Barva štítku
Výstup:
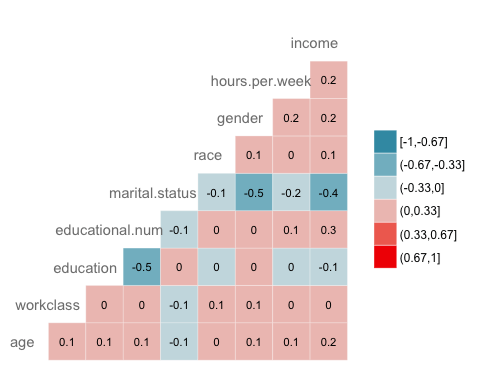
Krok 5) Trénink/testovací sada
Jakýkoli pod dohledem strojové učení Úkol vyžaduje rozdělení dat mezi vlakovou sadu a testovací sadu. K vytvoření vlakové/testovací sady můžete použít „funkci“, kterou jste vytvořili v jiných tutoriálech pro supervidované učení.
set.seed(1234) create_train_test <- function(data, size = 0.8, train = TRUE) { n_row = nrow(data) total_row = size * n_row train_sample <- 1: total_row if (train == TRUE) { return (data[train_sample, ]) } else { return (data[-train_sample, ]) } } data_train <- create_train_test(recast_data, 0.8, train = TRUE) data_test <- create_train_test(recast_data, 0.8, train = FALSE) dim(data_train)
Výstup:
## [1] 36429 9
dim(data_test)
Výstup:
## [1] 9108 9
Krok 6) Sestavte model
Chcete-li vidět, jak algoritmus funguje, použijte funkci glm() z balíčku stats. Zobecněný lineární model je sbírka modelů. Základní syntaxe je:
glm(formula, data=data, family=linkfunction() Argument: - formula: Equation used to fit the model- data: dataset used - Family: - binomial: (link = "logit") - gaussian: (link = "identity") - Gamma: (link = "inverse") - inverse.gaussian: (link = "1/mu^2") - poisson: (link = "log") - quasi: (link = "identity", variance = "constant") - quasibinomial: (link = "logit") - quasipoisson: (link = "log")
Jste připraveni odhadnout logistický model pro rozdělení úrovně příjmu mezi sadu funkcí.
formula <- income~. logit <- glm(formula, data = data_train, family = 'binomial') summary(logit)
Code Vysvětlení
- vzorec <- příjem ~ .: Vytvořte model tak, aby vyhovoval
- logit <- glm(vzorec, data = data_train, rodina = 'binomický'): Proložte logistický model (rodina = 'binomický') pomocí dat data_train.
- Summary(logit): Vytiskne souhrn modelu
Výstup:
## ## Call: ## glm(formula = formula, family = "binomial", data = data_train) ## ## Deviance Residuals: ## Min 1Q Median 3Q Max ## -2.6456 -0.5858 -0.2609 -0.0651 3.1982 ## ## Coefficients: ## Estimate Std. Error z value Pr(>|z|) ## (Intercept) 0.07882 0.21726 0.363 0.71675 ## age 0.41119 0.01857 22.146 < 2e-16 *** ## workclassLocal-gov -0.64018 0.09396 -6.813 9.54e-12 *** ## workclassPrivate -0.53542 0.07886 -6.789 1.13e-11 *** ## workclassSelf-emp-inc -0.07733 0.10350 -0.747 0.45499 ## workclassSelf-emp-not-inc -1.09052 0.09140 -11.931 < 2e-16 *** ## workclassState-gov -0.80562 0.10617 -7.588 3.25e-14 *** ## workclassWithout-pay -1.09765 0.86787 -1.265 0.20596 ## educationCommunity -0.44436 0.08267 -5.375 7.66e-08 *** ## educationHighGrad -0.67613 0.11827 -5.717 1.08e-08 *** ## educationMaster 0.35651 0.06780 5.258 1.46e-07 *** ## educationPhD 0.46995 0.15772 2.980 0.00289 ** ## educationdropout -1.04974 0.21280 -4.933 8.10e-07 *** ## educational.num 0.56908 0.07063 8.057 7.84e-16 *** ## marital.statusNot_married -2.50346 0.05113 -48.966 < 2e-16 *** ## marital.statusSeparated -2.16177 0.05425 -39.846 < 2e-16 *** ## marital.statusWidow -2.22707 0.12522 -17.785 < 2e-16 *** ## raceAsian-Pac-Islander 0.08359 0.20344 0.411 0.68117 ## raceBlack 0.07188 0.19330 0.372 0.71001 ## raceOther 0.01370 0.27695 0.049 0.96054 ## raceWhite 0.34830 0.18441 1.889 0.05894 . ## genderMale 0.08596 0.04289 2.004 0.04506 * ## hours.per.week 0.41942 0.01748 23.998 < 2e-16 *** ## ---## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 ## ## (Dispersion parameter for binomial family taken to be 1) ## ## Null deviance: 40601 on 36428 degrees of freedom ## Residual deviance: 27041 on 36406 degrees of freedom ## AIC: 27087 ## ## Number of Fisher Scoring iterations: 6
Shrnutí našeho modelu odhaluje zajímavé informace. Výkon logistické regrese se hodnotí pomocí specifických klíčových metrik.
- AIC (Akaike Information Criteria): Toto je ekvivalent R2 v logistické regresi. Měří přizpůsobení, když je na počet parametrů aplikována penalizace. Menší AIC hodnoty ukazují, že model je blíže pravdě.
- Nulová odchylka: Vyhovuje modelu pouze s průsečíkem. Stupeň volnosti je n-1. Můžeme ji interpretovat jako hodnotu Chí-kvadrát (proložená hodnota odlišná od testování hypotézy skutečné hodnoty).
- Reziduální odchylka: Model se všemi proměnnými. Je také interpretován jako testování hypotézy chí-kvadrát.
- Počet iterací Fisher Scoring: Počet iterací před konvergováním.
Výstup funkce glm() je uložen v seznamu. Níže uvedený kód zobrazuje všechny položky dostupné v proměnné logit, kterou jsme vytvořili pro vyhodnocení logistické regrese.
# Seznam je velmi dlouhý, vytiskněte pouze první tři prvky
lapply(logit, class)[1:3]
Výstup:
## $coefficients ## [1] "numeric" ## ## $residuals ## [1] "numeric" ## ## $fitted.values ## [1] "numeric"
Každou hodnotu lze extracse znakem $ následovaným názvem metriky. Například jste model uložili jako logit. Pro příkladtracPro kritéria AIC použijete:
logit$aic
Výstup:
## [1] 27086.65
Krok 7) Posuďte výkon modelu
Matice zmatků
Jedno matoucí matice je lepší volbou pro hodnocení výkonu klasifikace ve srovnání s různými metrikami, které jste viděli dříve. Obecnou myšlenkou je spočítat, kolikrát jsou skutečné instance klasifikovány jako nepravdivé.

Chcete-li vypočítat matici zmatků, musíte mít nejprve sadu předpovědí, aby je bylo možné porovnat se skutečnými cíli.
predict <- predict(logit, data_test, type = 'response') # confusion matrix table_mat <- table(data_test$income, predict > 0.5) table_mat
Code Vysvětlení
- forecast(logit,data_test, type = 'response'): Vypočítejte předpověď na testovací sadě. Nastavte typ = 'response' pro výpočet pravděpodobnosti odpovědi.
- table(data_test$income, forecast > 0.5): Vypočtěte matici zmatků. predikovat > 0.5 znamená, že vrátí 1, pokud jsou předpokládané pravděpodobnosti vyšší než 0.5, jinak 0.
Výstup:
## ## FALSE TRUE ## <=50K 6310 495 ## >50K 1074 1229
Každý řádek v matici zmatku představuje skutečný cíl, zatímco každý sloupec představuje předpokládaný cíl. První řádek této matice zohledňuje příjem nižší než 50 tisíc (negativní třída): 6 310 pozorování bylo správně klasifikováno jako osoby s příjmem nižším než 50 tisíc (Pravda negativní), zatímco 495 bylo chybně klasifikováno jako osoby starší 50 tisíc (Falešně pozitivní). Druhý řádek zohledňuje příjem nad 50 tisíc: 1 229 bylo správně identifikováno (Pravda pozitivní), zatímco 1 074 bylo zmeškáno (Falešně negativní).
Můžete vypočítat model přesnost sečtením skutečných kladných + skutečných záporných hodnot z celkového pozorování

accuracy_Test <- sum(diag(table_mat)) / sum(table_mat) accuracy_Test
Code Vysvětlení
- sum(diag(table_mat)): Součet úhlopříčky
- sum(table_mat): Součet matice.
Výstup:
## [1] 0.8277339
Zdá se, že model trpí jedním problémem: produkuje příliš mnoho falešně negativních výsledků. Tomu se říká paradox testu přesnostiUvedli jsme, že přesnost je poměr správných předpovědí k celkovému počtu případů. Můžeme mít relativně vysokou přesnost, ale model je nepoužitelný. To se stává, když existuje dominantní třída. Pokud se podíváte zpět na matici zmatku, uvidíte, že většina případů je klasifikována jako skutečně negativní. Představte si nyní, že model klasifikoval každé pozorování jako negativní (tj. nižší než 50 tisíc). Stále byste dosáhli přesnosti přibližně 75 procent (6 805 / 9 108). Váš model funguje lépe, ale má problém rozlišit skutečně pozitivní od skutečně negativního.
V takové situaci je vhodnější mít stručnější metriku. Můžeme se podívat na:
- Přesnost=TP/(TP+FP)
- Vyvolat=TP/(TP+FN)
Přesnost vs
Přesnost dívá se na přesnost pozitivní předpovědi. Odvolání je poměr pozitivních instancí, které jsou správně detekovány klasifikátorem;
Pro výpočet těchto dvou metrik můžete sestavit dvě funkce
- Konstrukční přesnost
precision <- function(matrix) { # True positive tp <- matrix[2, 2] # false positive fp <- matrix[1, 2] return (tp / (tp + fp)) }
Code Vysvětlení
- mat[1,1]: Vrátí první buňku prvního sloupce datového rámce, tj. true positive
- mat[1,2]; Vraťte první buňku druhého sloupce datového rámce, tj. falešně pozitivní
recall <- function(matrix) { # true positive tp <- matrix[2, 2]# false positive fn <- matrix[2, 1] return (tp / (tp + fn)) }
Code Vysvětlení
- mat[1,1]: Vrátí první buňku prvního sloupce datového rámce, tj. true positive
- mat[2,1]; Vraťte druhou buňku prvního sloupce datového rámce, tj. falešně negativní
Můžete otestovat své funkce
prec <- precision(table_mat) prec rec <- recall(table_mat) rec
Výstup:
## [1] 0.712877 ## [2] 0.5336518
Pečlivě si přečtěte tato dvě čísla. Přesnost je 0.71, takže když model uvádí, že jednotlivec vydělává více než 50 tisíc, je to správné v 71 procentech případů. Přesnost odvolání je 0.53, takže model detekuje pouze 53 procent jednotlivců, kteří skutečně vydělávají více než 50 tisíc.
Můžete vytvořit ![]() skóre na základě přesnosti a zapamatovatelnosti. The
skóre na základě přesnosti a zapamatovatelnosti. The ![]() je harmonický průměr těchto dvou metrik, což znamená, že dává větší váhu nižším hodnotám.
je harmonický průměr těchto dvou metrik, což znamená, že dává větší váhu nižším hodnotám.

f1 <- 2 * ((prec * rec) / (prec + rec)) f1
Výstup:
## [1] 0.6103799
Přesnost vs Recall kompromis
Je nemožné mít současně vysokou přesnost a vysokou vybavitelnost.
Pokud zvýšíme přesnost, bude se lépe předpovídat správný jedinec, ale mnoho z nich bychom vynechali (nižší zapamatovatelnost). V některých situacích dáváme přednost vyšší přesnosti než vyvolání. Mezi přesností a vyvoláním je konkávní vztah.
- Představte si, že potřebujete předpovědět, zda má pacient nějakou nemoc. Chcete být co nejpřesnější.
- Pokud potřebujete odhalit potenciální podvodné lidi na ulici pomocí rozpoznávání obličeje, bylo by lepší chytit mnoho lidí označených jako podvodníci, i když je přesnost nízká. Policie bude moci nepodvedenou osobu propustit.
ROC křivka
Jedno Přijímač Operating Charakteristika křivka je dalším běžným nástrojem používaným s binární klasifikací. Je velmi podobná křivce přesnosti/vybavení, ale místo vynesení přesnosti versus vybavování ukazuje křivka ROC skutečnou pozitivní četnost (tj. vybavování) proti četnosti falešně pozitivních. Míra falešně pozitivních výsledků je poměr negativních instancí, které jsou nesprávně klasifikovány jako pozitivní. Rovná se jedné mínus skutečná záporná sazba. Skutečná záporná sazba se také nazývá specifičnost. Proto se vykresluje ROC křivka citlivost (odvolání) versus 1-specifičnost
Pro vykreslení ROC křivky potřebujeme nainstalovat balíček s názvem ROCR. Najdeme ho v souboru conda knihovna. Můžete zadat kód:
conda install -c r r-rocr --yes
ROC můžeme vykreslit pomocí funkcí forecast() a performance().
library(ROCR) ROCRpred <- prediction(predict, data_test$income) ROCRperf <- performance(ROCRpred, 'tpr', 'fpr') plot(ROCRperf, colorize = TRUE, text.adj = c(-0.2, 1.7))
Code Vysvětlení
- predikce(predikce, data_test$income): Knihovna ROCR potřebuje vytvořit objekt predikce pro transformaci vstupních dat
- performance(ROCRpred, 'tpr', 'fpr'): Vraťte dvě kombinace, které se mají vytvořit v grafu. Zde jsou konstruovány tpr a fpr. Pro přesnost vykreslování a vyvolání dohromady použijte „prec“, „rec“.
Výstup:
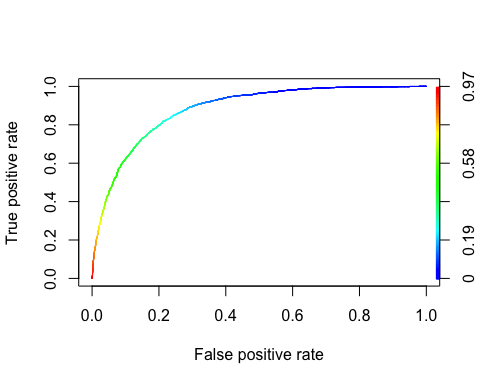
Krok 8) Vylepšete model
Můžete zkusit přidat do modelu nelinearitu s interakcí mezi nimi
- věk a hodiny.týdně
- pohlaví a hodiny.týdně.
Poté porovnáte skóre F1 obou modelů.
formula_2 <- income~age: hours.per.week + gender: hours.per.week + . logit_2 <- glm(formula_2, data = data_train, family = 'binomial') predict_2 <- predict(logit_2, data_test, type = 'response') table_mat_2 <- table(data_test$income, predict_2 > 0.5) precision_2 <- precision(table_mat_2) recall_2 <- recall(table_mat_2) f1_2 <- 2 * ((precision_2 * recall_2) / (precision_2 + recall_2)) f1_2
Výstup:
## [1] 0.6109181
Skóre F1 je o něco vyšší než to předchozí. Můžete pokračovat v práci na datech a pokusit se skóre překonat.
Jak interpretovat koeficienty GLM a poměry šancí v R
Souhrnná tabulka vytištěná v kroku 6 uvádí koeficienty pro logaritmické kurzy měřítko, což je obtížné vysvětlit netechnickému publiku. Jejich převod na poměry šancí usnadňuje sdělení modelu.
Postupujte podle těchto čtyř kroků.
- Umocněte koeficienty. Aplikujte exp() na každý odhad tak, aby se logaritmické poměry šancí staly multiplikativními poměry šancí.
- Přidejte interval spolehlivosti. Zabalte confint() do exp() pro získání 95procentního intervalu na stejné stupnici pravděpodobnosti.
- Porovnejte každou hodnotu s 1. Poměr šancí nad 1 zvyšuje pravděpodobnost pozitivní třídy, hodnota pod 1 ji snižuje a hodnota blízká 1 znamená, že prediktor přidává jen málo.
- Zkontrolujte statistickou významnost. Interpretujte pouze prediktory, jejichž p-hodnota v souhrnném výstupu je pod zvolenou prahovou hodnotou, obvykle 0.05.
# Convert log-odds coefficients into odds ratios odds_ratio <- exp(coef(logit)) round(odds_ratio, 3) # Odds ratios with 95% confidence intervals exp(cbind(OddsRatio = coef(logit), confint(logit)))
Čtení výstupu. Koeficient pro hodiny za týden v našem modelu je 0.41942. Jeho umocněním dostaneme exp(0.41942) = 1.52, což znamená, že zvýšení týdenní pracovní doby o jednu směrodatnou odchylku vynásobí pravděpodobnost výdělku nad 50 tisíc zhruba 1.5krát, přičemž všechny ostatní proměnné zůstávají konstantní.
Záporné koeficienty fungují stejným způsobem. marital.statusNot_married je -2.50346, takže exp(-2.50346) = 0.08: svobodní jedinci mají přibližně 8 procent šance na vdanou osobu. Protože spojité prediktory byly standardizovány v kroku 1, popište změny v jednotkách směrodatné odchylky, nikoli v hodinách.
Poznámka pro ostatní rodiny: Exponentované koeficienty jsou poměry šancí pouze v rámci binomické rodiny s logitovým propojením. S rodinou = „poisson“ a logaritmickým propojením se stejné hodnoty exp() čtou jako poměry šancí.
GLM v R: Rychlý přehled funkcí
Mějte tuto tabulku po ruce, zatímco programujete. Uvádí všechny funkce použité v osmi výše uvedených krocích, spolu s balíčkem, který je poskytuje, a očekávanými argumenty.
| Balíček | Objektivní | funkce | Argument |
|---|---|---|---|
| - | Vytvořte vlakovou/testovací datovou sadu | create_train_set() | údaje, velikost, vlak |
| glm | Trénujte zobecněný lineární model | glm() | vzorec, data, rodina* |
| glm | Shrňte model | souhrn() | namontovaný model |
| základna | Proveďte předpověď | předpovědět() | přizpůsobený model, datová sada, typ = 'odpověď' |
| základna | Vytvořte matici zmatků | stůl() | y, předpovědět() |
| základna | Vytvořte skóre přesnosti | součet(diag(tabulka())/součet(tabulka() | |
| ROCR | Vytvoření ROC: Krok 1 Vytvořte předpověď | předpověď() | předpovídat(), y |
| ROCR | Vytvořte ROC: Krok 2 Vytvořte výkon | výkon() | predikce(), 'tpr', 'fpr' |
| ROCR | Vytvořte ROC: Krok 3 Vykreslete graf | spiknutí() | výkon() |
Ostatní GLM rodiny dostupné prostřednictvím rodinného argumentu jsou:
- binomický: (link = „logit“)
- gaussovská: (link = „identita“)
- Gama: (link = „inverzní“)
- inverzní.gaussovská: (link = „1/mu^2“)
- poisson: (link = „log“)
- kvazi: (link = „identita“, variance = „konstanta“)
- kvazibinom: (link = „logit“)
- kvazipoisson: (link = „log“)