Урок за Apache Flume: Какво е, Archiтектура и пример за Hadoop
⚡ Умно обобщение
Apache Flume е разпределена услуга за събиране, агрегиране и преместване на големи обеми от лог данни в HDFS, изградена около агенти, които свързват източник, канал и приемник заедно.

Какво е Apache Flume в Hadoop?
Apache Flume е надеждна и разпределена система за събиране, агрегиране и преместване на огромни количества лог данни. Тя има проста, но гъвкава архитектура, базирана на стрийминг на потоци от данни. Apache Flume се използва за събиране на лог данни, налични в лог файлове от уеб сървъри, и агрегирането им в HDFS за анализ.
Flume в Hadoop поддържа множество източници, включително:
- „tail“ (която прехвърля данни от локален файл и ги записва в HDFS чрез Flume, подобно на Unix командата „tail“)
- Системни регистрационни файлове
- Apache log4j (което позволява Java приложения за запис на събития във файлове в HDFS чрез Flume).
Текущото издание е Flume 1.11.0, публикувано на 25 октомври 2022 г. и достъпно от Страница за изтегляне на Apache FlumeТова ръководство е написано за версия 1.4.0, така че няколко стъпки по-долу носят забележка, че текущата версия се държи различно.
воденичен улей Archiтекстура
Агентът на Flume е JVM процес с три компонента – източник на улей, канал на улей и поглъщател на улей – през които събитията се разпространяват, след като са инициирани от външен източник. Диаграмата по-долу показва как са свързани.
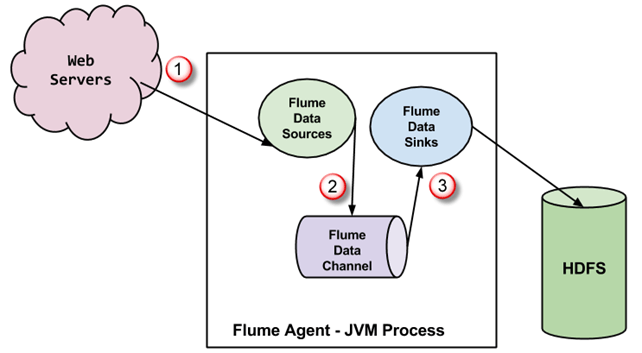
- Събитията, генерирани от външния източник (уеб сървър), се консумират от Flume източника. Външният източник изпраща събития към Flume източника във формат, който целевият източник разпознава.
- Източникът на Flume получава събитие и го съхранява в един или повече канали. Каналът действа като хранилище, което пази събитието, докато не бъде консумирано от приемника на Flume. Този канал може да използва локална файлова система за съхраняване на тези събития.
- Flume sink премахва събитието от канал и го съхранява във външно хранилище, като например HDFS. Може да има множество Flume агенти, като в този случай Flume sink препраща събитието към Flume източника на следващия агент в потока.
Някои важни характеристики на Flume
- Flume има гъвкав дизайн, базиран на стрийминг на потоци от данни. Той е устойчив на грешки и стабилен, с множество механизми за превключване при срив и възстановяване. Flume предлага различни нива на надеждност, включително „доставка с най-добри усилия“ намлява „доставка от край до край“. Доставка с най-добри усилия не толерира никаква повреда на възела на Flume, докато доставка от край до край гарантира доставка дори в случай на повреда на множество възли.
- Flume пренася данни между източници и приемници. Това събиране на данни може да бъде планирано или управлявано от събития. Flume има собствен механизъм за обработка на заявки, което улеснява трансформирането на всяка нова партида данни, преди да бъде преместена към желаната приемница.
- Възможен Мивки за канали включват HDFS и HBaseFlume може също да пренася данни за събития, като например данни за мрежовия трафик, данни, генерирани от уебсайтове на социални медии и имейл съобщения.
Настройка на канал, библиотека и изходен код
Преди да започнем с действителния процес, уверете се, че имате инсталиран Hadoop; ако не, продължете напред как да инсталирате Hadoop Първо. Променете потребителя на „hduser“ (идентификаторът, използван при конфигурирането на Hadoop; можете да превключите към потребителския идентификатор, използван по време на вашата собствена конфигурация на Hadoop).

Стъпка 1) Създайте нова директория с име „FlumeTutorial“.
sudo mkdir FlumeTutorial
- Дайте разрешения за четене, запис и изпълнение.
sudo chmod -R 777 FlumeTutorial
- Копирайте файловете MyTwitterSource.java намлява MyTwitterSourceForFlume.java в тази директория.
Изтеглете входните файлове от тук
Проверете разрешенията за достъп до всички тези файлове, както е показано по-долу, и предоставете разрешение за „четене“, ако липсва.

Стъпка 2) Изтеглете „Apache Flume“ от https://flume.apache.org/download.html.
Apache Flume 1.4.0 е използван в този урок за Flume.

След това кликнете върху огледало.

Стъпка 3) Копирайте изтегления tarball в избраната от вас директория и след товаtracсъдържанието, използвайки следната команда.
sudo tar -xvf apache-flume-1.4.0-bin.tar.gz

Това създава нова директория с име apache-flume-1.4.0-bin и extracts файловете в него. Тази директория се нарича в останалата част на статията.
Стъпка 4) Настройка на библиотеката Flume. Копирайте twitter4j-core-4.0.1.jar, flume-ng-configuration-1.4.0.jar, flume-ng-core-1.4.0.jar и flume-ng-sdk-1.4.0.jar в
/lib/
Един или всички копирани JAR файлове може да имат зададено разрешение за изпълнение, което може да причини проблем с компилирането на код, така че го отменете. В моя случай, twitter4j-core-4.0.1.jar имаше разрешение за изпълнение. Отнех го, както е показано по-долу.
sudo chmod -x twitter4j-core-4.0.1.jar

След това, командата по-долу дава разрешение за „четене“ на twitter4j-core-4.0.1.jar на всички.
sudo chmod +rrr /usr/local/apache-flume-1.4.0-bin/lib/twitter4j-core-4.0.1.jar
Моля, обърнете внимание, че изтеглих twitter4j-core-4.0.1.jar от Maven хранилищеи всички Flume JAR файлове, т.е. flume-ng-*-1.4.0.jar, от артефактите на org.apache.flume.
Заредете данни от Twitter с помощта на Flume
Стъпка 1) Отидете в директорията, съдържаща файловете с изходния код.
Стъпка 2) Задайте CLASSPATH да съдържа /lib/* и ~/FlumeTutorial/flume/mytwittersource/*.
export CLASSPATH="/usr/local/apache-flume-1.4.0-bin/lib/*:~/FlumeTutorial/flume/mytwittersource/*"

Стъпка 3) Компилирайте изходния код, използвайки командата по-долу.
javac -d . MyTwitterSourceForFlume.java MyTwitterSource.java

Стъпка 4) Създайте JAR файл. Първо, създайте файл Manifest.txt, използвайки текстов редактор по ваш избор, и добавете реда по-долу към него.
Main-Class: flume.mytwittersource.MyTwitterSourceForFlume
Тук flume.mytwittersource.MyTwitterSourceForFlume е името на основния клас. Моля, обърнете внимание, че трябва да натиснете клавиша Enter в края на този ред, както е показано по-долу.

Сега създайте JAR файла „MyTwitterSourceForFlume.jar“, както следва.
jar cfm MyTwitterSourceForFlume.jar Manifest.txt flume/mytwittersource/*.class

Стъпка 5) Копирайте този JAR файл в /lib/.
sudo cp MyTwitterSourceForFlume.jar <Flume Installation Directory>/lib/

Стъпка 6) Отидете в конфигурационната директория на Flume, /конф.
Ако flume.conf не съществува, копирайте flume-conf.properties.template и го преименувайте на flume.conf.
sudo cp flume-conf.properties.template flume.conf

Ако flume-env.sh не съществува, копирайте flume-env.sh.template и го преименувайте на flume-env.sh.
sudo cp flume-env.sh.template flume-env.sh

Създаване на Twitter приложение
Прочетете това първо. Стриймингът v1.1 statuses/filter Крайната точка, от която се нуждае twitter4j 4.0.1, беше оттеглена на 9 март 2023 г., а филтрираният поток от API v2, който я замени, сега е на developer.x.com, се намира зад платен слой. Третирайте екраните по-долу като шаблон за персонализиран изходен код, след което насочете същия агент към файл, изпълнителен файл или изходен код на Kafka.
Стъпка 1) Създайте приложение за Twitter, като влезете в портала за разработчици.


Стъпка 2) Отидете на „Моите приложения“ (тази опция се появява, когато щракнете върху бутона „Яйце“ в горния десен ъгъл).

Стъпка 3) Създайте ново приложение, като кликнете върху „Създаване на ново приложение“.
Стъпка 4) Попълнете данните за приложението, като посочите името на приложението, описание и уебсайт. Можете да се обърнете към бележките, дадени под всяко поле за въвеждане.
Стъпка 5) Превъртете надолу по страницата, приемете условията, като маркирате „Да, съгласен съм“ и кликнете върху бутона „Създайте свое Twitter приложение“.

Стъпка 6) В прозореца на новосъздаденото приложение отидете на раздела „API ключове“, превъртете надолу по страницата и кликнете върху бутона „Създаване на моя токен за достъп“.


Стъпка 7) Опреснете страницата.
Стъпка 8) Кликнете върху „Тестване на OAuth“. Това показва настройките за „OAuth“ на приложението.

Стъпка 9) Променете „flume.conf“, използвайки тези OAuth настройки. Стъпките за промяна на „flume.conf“ са дадени по-долу.

Трябва да копираме потребителския ключ, потребителската тайна, токена за достъп и тайната на токена за достъп, за да актуализираме „flume.conf“.
Забележка: Тези стойности принадлежат на потребителя и следователно са поверителни, така че не трябва да се споделят.
Променете файла „flume.conf“.
Стъпка 1) Отворете 'flume.conf' в режим на запис и задайте стойности за параметрите по-долу.
sudo gedit flume.conf
Копирайте съдържанието по-долу.
MyTwitAgent.sources = Twitter MyTwitAgent.channels = MemChannel MyTwitAgent.sinks = HDFS MyTwitAgent.sources.Twitter.type = flume.mytwittersource.MyTwitterSourceForFlume MyTwitAgent.sources.Twitter.channels = MemChannel MyTwitAgent.sources.Twitter.consumerKey = <Copy consumer key value from Twitter App> MyTwitAgent.sources.Twitter.consumerSecret = <Copy consumer secret value from Twitter App> MyTwitAgent.sources.Twitter.accessToken = <Copy access token value from Twitter App> MyTwitAgent.sources.Twitter.accessTokenSecret = <Copy access token secret value from Twitter App> MyTwitAgent.sources.Twitter.keywords = guru99 MyTwitAgent.sinks.HDFS.channel = MemChannel MyTwitAgent.sinks.HDFS.type = hdfs MyTwitAgent.sinks.HDFS.hdfs.path = hdfs://localhost:54310/user/hduser/flume/tweets/ MyTwitAgent.sinks.HDFS.hdfs.fileType = DataStream MyTwitAgent.sinks.HDFS.hdfs.writeFormat = Text MyTwitAgent.sinks.HDFS.hdfs.batchSize = 1000 MyTwitAgent.sinks.HDFS.hdfs.rollSize = 0 MyTwitAgent.sinks.HDFS.hdfs.rollCount = 10000 MyTwitAgent.channels.MemChannel.type = memory MyTwitAgent.channels.MemChannel.capacity = 10000 MyTwitAgent.channels.MemChannel.transactionCapacity = 1000

Стъпка 2) Също така, задайте TwitterAgent.sinks.HDFS.hdfs.path както е посочено по-долу.
TwitterAgent.sinks.HDFS.hdfs.path = hdfs:// : / /flume/туитове/

Да намеря , и , вижте стойността на параметъра 'fs.defaultFS', зададен в $HADOOP_HOME/etc/hadoop/core-site.xml, показана по-долу.

Стъпка 3) За да прехвърлите данните в HDFS веднага щом постъпят, изтрийте записа по-долу, ако съществува.
TwitterAgent.sinks.HDFS.hdfs.rollInterval = 600
Пример: Поточно предаване на данни от Twitter с помощта на Flume
Стъпка 1) Отворете 'flume-env.sh' в режим на запис и задайте стойности за параметрите по-долу.
JAVA_HOME=<Installation directory of Java>
FLUME_CLASSPATH="<Flume Installation Directory>/lib/MyTwitterSourceForFlume.jar"

Стъпка 2) Стартирайте Hadoop.
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Стъпка 3) Два от JAR файловете от tarball-а на Flume не са съвместими с Hadoop 2.2.0, така че в този пример на Apache Flume следваме стъпките по-долу, за да направим Flume съвместим с Hadoop 2.2.0. Тази JAR замяна е корекция от ерата 1.4.0; Flume 1.11.0 вече доставя текущите компилации на protobuf и Guava, така че един съвременен tarball обикновено не се нуждае от нищо от това.
а. Преместете protobuf-java-2.4.1.jar извън ' /lib'. Първо отидете в тази директория.
cd /lib
sudo mv protobuf-java-2.4.1.jar ~/

б. Намерете JAR файла „guava“, както е показано по-долу.
find . -name "guava*"

Преместете guava-10.0.1.jar извън ' /lib'.
sudo mv guava-10.0.1.jar ~/

c. Изтеглете guava-17.0.jar от Maven хранилище, показано по-долу.

Сега копирайте този изтеглен JAR файл в ' /lib'.
Стъпка 4) Отидете на „ /bin' и стартирайте Flume както следва.
./flume-ng agent -n MyTwitAgent -c conf -f <Flume Installation Directory>/conf/flume.conf

Прозорецът на командния ред, където Flume извлича туитове, изглежда така.

От съобщението в командния прозорец виждаме, че изходът се записва в директорията /user/hduser/flume/tweets/. Сега отворете тази директория с помощта на уеб браузър.
Стъпка 5) За да видите резултата от зареждането на данни, отворете http://localhost:50070/ в браузър, прегледайте файловата система и след това отидете в директорията, където са заредени данните, т.е.
/flume/туитове/
Порт 50070 е уеб потребителският интерфейс на NameNode на Hadoop 2; Hadoop 3 премести същата страница на порт 9870.

Флумът е половината от поглъщането: Sqoop импортира таблици на партиди, Flume предава събития поточно, след което Прасе or Кошер оформете файловете и Узи планира веригата. Вижте също инструменти за анализ на големи данни, MapReduce съединения и броячи намлява Таленд.