SQLite 查询:选择、Where、LIMIT、OFFSET、计数、分组
⚡ 智能摘要
SQLite 查询使用 SELECT、FROM、WHERE、GROUP BY、ORDER BY 和 LIMIT 子句检索和筛选数据。将这些子句与运算符、聚合、子查询和集合运算结合使用,可以从任何数据库中读取、整理和汇总记录。 SQLite 数据库。

以下各节将逐步介绍如何使用 SELECT 和 FROM 读取数据、如何使用 WHERE 及其运算符筛选行、如何对结果进行排序和限制、聚合函数、GROUP BY 和 HAVING、子查询、集合操作、NULL 处理、CASE 表达式和公共表表达式。
来写 SQL查询 的 SQLite 数据库,您必须了解 SELECT、FROM、WHERE、GROUP BY、ORDER BY 和 LIMIT 子句的工作原理以及如何使用它们。
在本教程中,您将学习如何使用这些子句以及如何编写 SQLite 条款。
使用 Select 读取数据
SELECT 子句是用于查询 SQLite 数据库。在 SELECT 子句中,您可以声明要选择的内容。但在使用 select 子句之前,让我们先看看可以使用 FROM 子句从哪里选择数据。
FROM 子句用于指定要从哪里选择数据。在 from 子句中,您可以指定一个或多个表或子查询来从中选择数据,我们将在后面的教程中看到。
请注意,对于以下所有示例,您必须运行 sqlite3.exe 并打开与示例数据库的连接,如下所示:
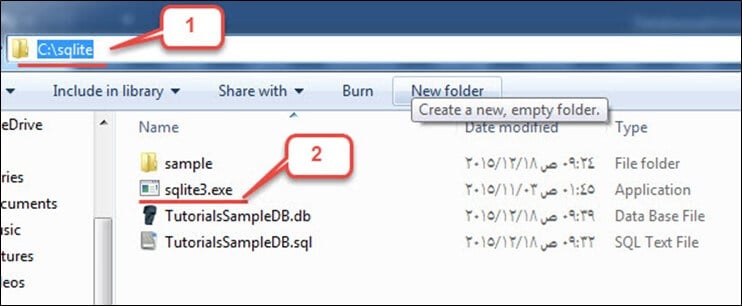
步骤1) 在此步骤中,
打开“我的电脑”,导航到以下目录“C:\sqlite”,然后打开“sqlite3.exe”:
步骤2) 使用以下命令打开数据库“TutorialsSampleDB.db”:
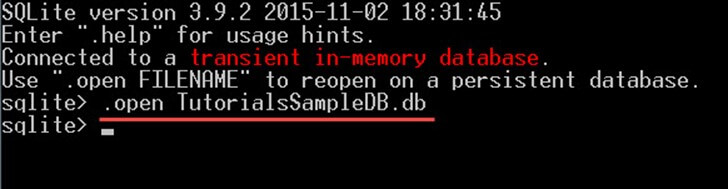
现在您已准备好在数据库上运行任何类型的查询。
在 SELECT 子句中,您不仅可以选择列名,还可以使用许多其他选项来指定要选择的内容。 如下所示:
SELECT *
此命令将从 FROM 子句中引用的所有表(或子查询)中选择所有列。例如:
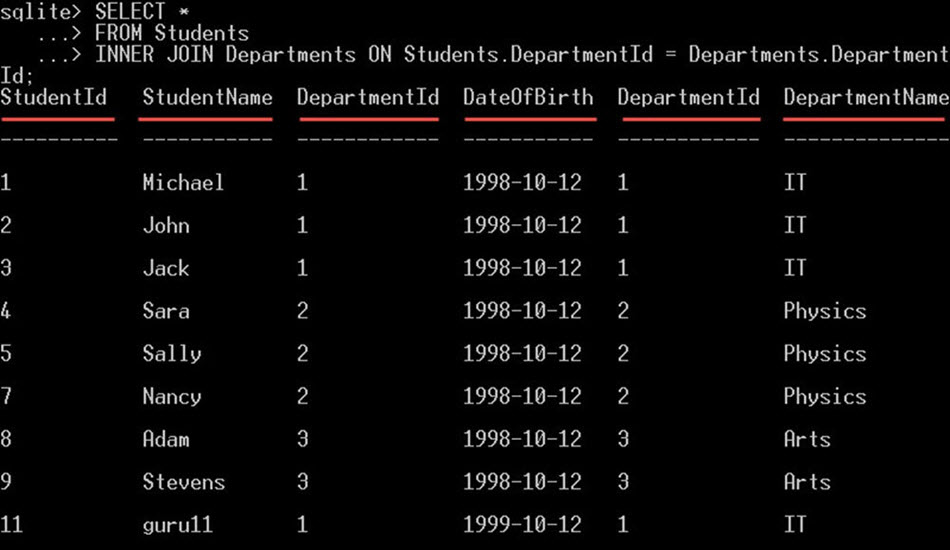
SELECT * FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
这将从学生表和部门表中选择所有列:
选择表名。*
这将仅从表“tablename”中选择所有列。例如:
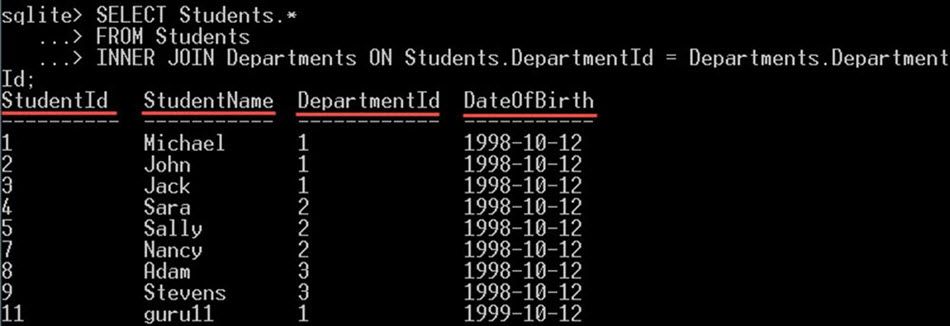
SELECT Students.* FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
这将仅从学生表中选择所有列:
文字值
文字值是可以在 select 语句中指定的常量值。您可以像在 SELECT 子句中使用列名一样正常使用文字值。这些文字值将显示在 SQL 查询返回的行中的每一行中。
以下是一些您可以选择的不同文字值的示例:
- 数字文字——任何格式的数字,如 1、2.55……等等。
- 字符串文字 - 任何字符串“USA”、“这是示例文本”等。
- NULL — NULL 值。
- Current_TIME – 它将为您提供当前时间。
- CURRENT_DATE – 这将为您提供当前日期。
在您必须为所有返回的行选择一个常量值的情况下,这可能很方便。例如,如果您想从学生表中选择所有学生,并使用一个名为“国家/地区”的新列,其中包含值“USA”,您可以执行以下操作:
SELECT *, 'USA' AS Country FROM Students;
这将为您提供所有学生的专栏,加上一个新专栏“国家”,如下所示:
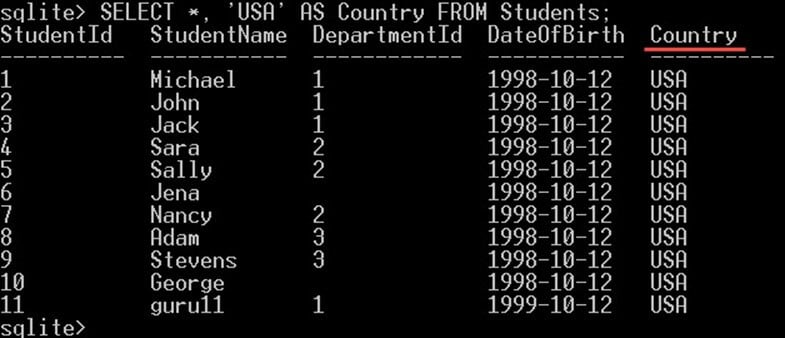
请注意,这个新列 Country 实际上并不是添加到表中的新列。它是一个虚拟列,在查询中创建以显示结果,并且不会在表中创建。
姓名和别名
别名是列的新名称,可让您选择具有新名称的列。列别名使用关键字“AS”指定。
例如,如果您想要选择以“Student Name”而不是“StudentName”返回的 StudentName 列,您可以为其指定一个别名,如下所示:
SELECT StudentName AS 'Student Name' FROM Students;
这将为您提供学生姓名,名称为“学生姓名”而不是“StudentName”,如下所示:

请注意,列名仍然是“StudentName”;StudentName 列仍然相同,不会因别名而改变。
别名不会改变列名;它只会改变 SELECT 子句中的显示名称。
另外,请注意,关键字“AS”是可选的,您可以在不使用它的情况下输入别名,如下所示:
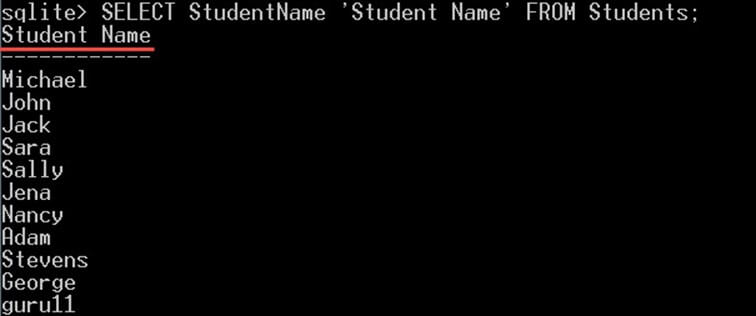
SELECT StudentName 'Student Name' FROM Students;
它将返回与上一个查询完全相同的输出:
您还可以为表指定别名,而不仅仅是列。使用相同的关键字“AS”。例如,您可以这样做:
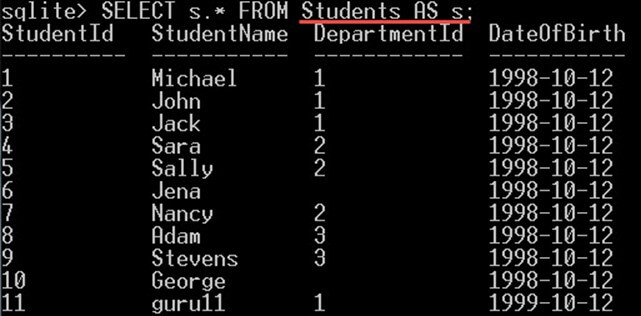
SELECT s.* FROM Students AS s;
这将为您提供学生表中的所有列:
如果您要连接多个表,这将非常有用;您可以为每个表指定一个简短的别名,而不必在查询中重复完整的表名。例如,在以下查询中:
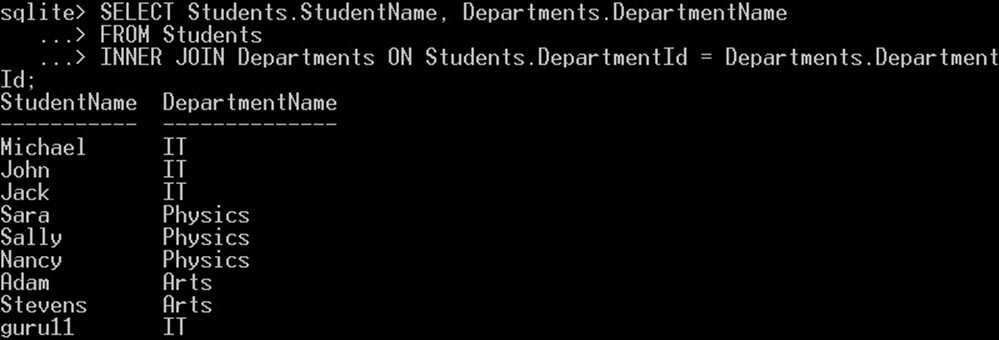
SELECT Students.StudentName, Departments.DepartmentName FROM Students INNER JOIN Departments ON Students.DepartmentId = Departments.DepartmentId;
此查询将从“学生”表中选择每个学生姓名,并从“部门”表中选择其部门名称:
但是,相同的查询可以这样写:
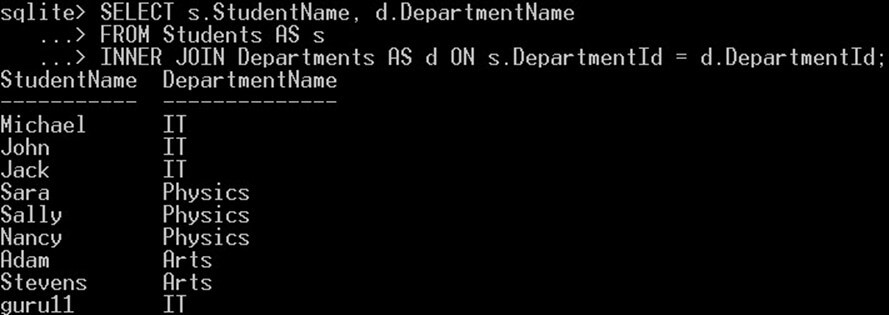
SELECT s.StudentName, d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
我们给 Students 表起了个别名“s”,给 departments 表起了个别名“d”。然后,我们不再使用表的完整名称,而是使用它们的别名来引用它们。INNER JOIN 使用条件将两个或多个表连接起来。在我们的示例中,我们使用 DepartmentId 列将 Students 表和 Departments 表连接起来。关于 INNER JOIN 的详细解释,请参阅“SQLite 加入“ 教程。
这将为您提供与上一个查询完全相同的输出:
NeoCity
像我们在上一节中看到的那样,使用 SELECT 子句和 FROM 子句编写 SQL 查询将为您提供表中的所有行。但是,如果您想过滤返回的数据,则必须添加“WHERE”子句。
WHERE 子句用于筛选 SQL 查询返回的结果集。WHERE 子句的工作原理如下:
- 在 WHERE 子句中,可以指定“表达式”。
- 将针对 FROM 子句中指定的表返回的每一行计算该表达式。
- 该表达式将被评估为布尔表达式,结果为 true、false 或 null。
- 然后,仅返回表达式评估为真值的行,而那些具有假或空结果的行将被忽略并且不包含在结果集中。
要使用 WHERE 子句过滤结果集,您必须使用表达式和运算符。
运营商列表 SQLite 以及如何使用它们
在下一节中,我们将解释如何使用表达式和运算符进行过滤。
表达式是一个或多个通过运算符相互组合的文字值或列。
请注意,您可以在 SELECT 子句和 WHERE 子句中使用表达式。
在以下示例中,我们将尝试 select 子句和 WHERE 子句中的表达式和运算符。以向您展示它们的性能。
您可以指定不同类型的表达式和运算符,如下所示:
SQLite 连接运算符“||”
此运算符用于将一个或多个文字值或列相互连接。它将从所有连接的文字值或列中生成一个结果字符串。例如:
SELECT 'Id with Name: '|| StudentId || StudentName AS StudentIdWithName FROM Students;
这将合并成一个新的别名“StudentIdWithName”:
- 字符串字面值“Id with Name: “
- 使用“StudentId”列的值
- 使用“StudentName”列中的值

SQLite CAST 运算符:
CAST 运算符用于将值从一种类型转换为另一种类型。 数据类型 转换为另一种数据类型。
例如,如果您有一个以字符串形式存储的数值,例如“'12.5'”,并且您想将其转换为数值,可以使用 CAST 运算符,例如“CAST('12.5' AS REAL)”。或者,如果您有一个十进制值,例如 12.5,并且您只需要获取其中的整数部分,则可以将其转换为整数,例如“CAST(12.5 AS INTEGER)”。
例如:
在以下命令中,我们将尝试将不同的值转换为其他数据类型:
SELECT CAST('12.5' AS REAL) ToReal, CAST(12.5 AS INTEGER) AS ToInteger;
这会给你:

执行结果如下:
- CAST('12.5' AS REAL) – 值 '12.5' 是一个字符串值,它将转换为 REAL 值。
- CAST(12.5 AS INTEGER) – 值 12.5 是十进制值,它将被转换为整数值。小数部分将被截断,变为 12。
SQLite 算术 Opera目的:
接受两个或多个数字字面值或数字列并返回一个数字值。支持的算术运算符 SQLite 是:
- 加法“+”——求两个操作数的和。
- 小组traction “–” – 子句tracts 是两个操作数的乘积,结果为差值。
- 乘法“*”——两个操作数的乘积。
- 取模运算符“%”表示一个操作数除以第二个操作数所得的余数。
- 除法“/”——返回左操作数除以右操作数所得的商。
计费示例:
在下面的示例中,我们将尝试在同一个 SELECT 子句中使用五个算术运算符来处理字面数值:
SELECT 25+6, 25-6, 25*6, 25%6, 25/6;
这会给你:

注意我们在这里使用了不带 FROM 子句的 SELECT 语句。这在 SQLite 只要我们选择文字值。
SQLite 比较运算符
将两个操作数相互比较并返回真或假,如下所示:
- “<” – 如果左操作数小于右操作数,则返回 true。
- “<=” – 如果左操作数小于或等于右操作数,则返回 true。
- “>” – 如果左操作数大于右操作数,则返回 true。
- “>=” – 如果左操作数大于或等于右操作数,则返回 true。
- “=”和“==”——如果两个操作数相等,则返回 true。请注意,这两个运算符是相同的,它们之间没有任何区别。
- “!=” 和 “<>”——如果两个操作数不相等,则返回 true。请注意,这两个运算符是相同的,它们之间没有任何区别。
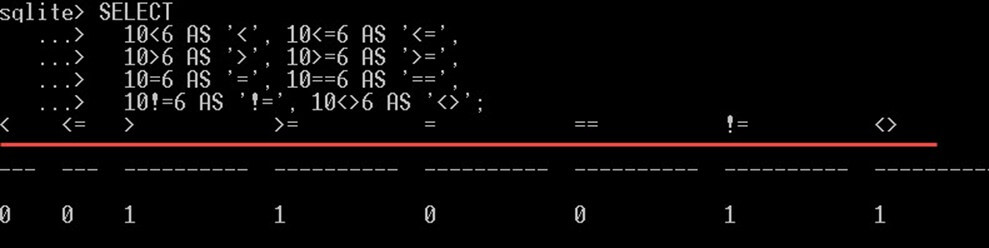
注意, SQLite 用1表示真实值,用0表示虚假值。
计费示例:
SELECT 10<6 AS '<', 10<=6 AS '<=', 10>6 AS '>', 10>=6 AS '>=', 10=6 AS '=', 10==6 AS '==', 10!=6 AS '!=', 10<>6 AS '<>';
这将得到如下结果:
SQLite 模式匹配运算符
“LIKE”用于模式匹配。使用“LIKE”,您可以搜索与使用通配符指定的模式相匹配的值。
左侧的操作数可以是字符串文字值,也可以是字符串列。模式可以指定如下:
- 包含特定模式。例如,StudentName LIKE '%a%' – 这将搜索 StudentName 列中任意位置包含字母“a”的学生姓名。
- 首先输入模式。例如,“StudentName LIKE 'a%'”——搜索姓名以字母“a”开头的学生。
- 以特定模式结尾。例如,“StudentName LIKE '%a'”——搜索姓名以字母“a”结尾的学生。
- 使用下划线“_”匹配字符串中的任意单个字符。例如,“StudentName LIKE 'J___'”——搜索长度为 4 个字符的学生姓名。姓名必须以字母“J”开头,并且“J”之后可以有任意三个字符。
模式匹配示例:
获取以字母“j”开头的学生姓名:
SELECT StudentName FROM Students WHERE StudentName LIKE 'j%';
结果:

获取学生姓名以字母“y”结尾:
SELECT StudentName FROM Students WHERE StudentName LIKE '%y';
结果:

获取包含字母‘n’的学生姓名:
SELECT StudentName FROM Students WHERE StudentName LIKE '%n%';
结果:

“GLOB”运算符与 LIKE 运算符功能相同,但 GLOB 区分大小写,而 LIKE 运算符则不区分大小写。例如,以下两个命令将返回不同的结果:
SELECT 'Jack' GLOB 'j%'; SELECT 'Jack' LIKE 'j%';
这会给你:

第一个语句返回 0(false),因为 GLOB 运算符区分大小写,所以 'j' 不等于 'J'。但是,第二个语句将返回 1(true),因为 LIKE 运算符不区分大小写,所以 'j' 等于 'J'。
其他运营商:
SQLite AND
组合一个或多个表达式的逻辑运算符。只有当所有表达式都得出“真”值时,它才会返回真。但是,只有当所有表达式都得出“假”值时,它才会返回假。
计费示例:
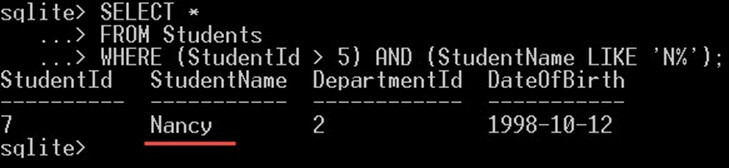
以下查询将搜索 StudentId > 5 且 StudentName 以字母 N 开头的学生,返回的学生必须满足两个条件:
SELECT * FROM Students WHERE (StudentId > 5) AND (StudentName LIKE 'N%');
作为输出,在上面的截图中,这将只给出“Nancy”。Nancy 是唯一一位同时满足两个条件的学生。
SQLite OR
逻辑运算符将一个或多个表达式组合在一起,如果组合运算符中的一个结果为真,则它将返回真。但是,如果所有表达式的结果为假,则它将返回假。
计费示例:
以下查询将搜索 StudentId > 5 或 StudentName 以字母 N 开头的学生,返回的学生必须满足至少一个条件:
SELECT * FROM Students WHERE (StudentId > 5) OR (StudentName LIKE 'N%');
这会给你:
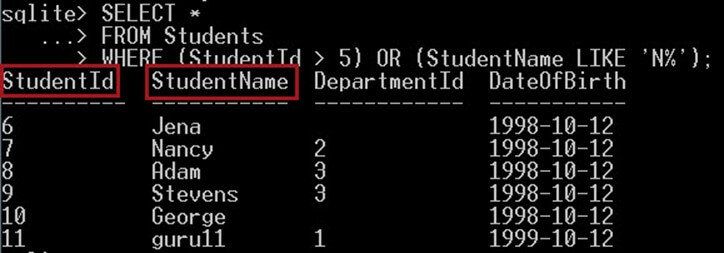
作为输出,在上面的屏幕截图中,这将为您提供名字中包含字母“n”的学生的姓名以及学生 ID 的值>5。
如您所见,结果与使用 AND 运算符的查询不同。
SQLite 之间
BETWEEN 函数用于选择介于两个值之间的值。例如,“X BETWEEN Y AND Z” 如果值 X 介于值 Y 和 Z 之间,则返回 true (1);否则返回 false (0)。“X BETWEEN Y AND Z” 等价于“X >= Y AND X <= Z”,其中 X 必须大于或等于 Y 且 X 小于或等于 Z。
计费示例:
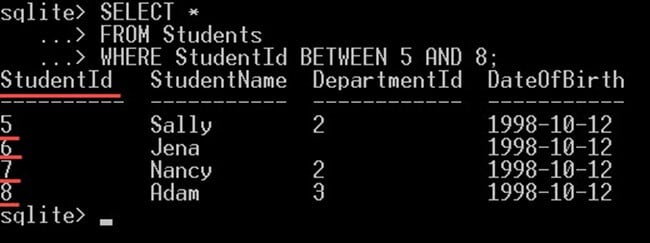
在下面的示例查询中,我们将编写一个查询来获取 Id 值在 5 到 8 之间的学生:
SELECT * FROM Students WHERE StudentId BETWEEN 5 AND 8;
这将仅显示 ID 为 5、6、7 和 8 的学生:
SQLite IN
采用一个操作数和一个操作数列表。如果第一个操作数值等于列表中的一个操作数值,则返回 true。如果操作数列表包含其值中的第一个操作数值,则 IN 运算符返回 true (1)。否则,它将返回 false (0)。
例如:“col IN(x, y, z)”。这等价于“(col=x)或(col=y)或(col=z)”。
计费示例:
以下查询将仅选择 ID 为 2、4、6、8 的学生:
SELECT * FROM Students WHERE StudentId IN(2, 4, 6, 8);
点赞此页 :

上面的查询将给出与以下查询完全相同的结果,因为它们是等效的:
SELECT * FROM Students WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);
两个查询都给出了准确的输出。但是,两个查询之间的区别在于,第一个查询我们使用了“IN”运算符。在第二个查询中,我们使用了多个“OR”运算符。
IN 运算符等价于使用多个 OR 运算符。“WHERE StudentId IN(2, 4, 6, 8)”等价于“WHERE (StudentId = 2) OR (StudentId = 4) OR (StudentId = 6) OR (StudentId = 8);”
点赞此页 :

SQLite 不在
“NOT IN”运算符与“IN”运算符相反,但语法相同:它接受一个操作数和一个操作数列表。如果第一个操作数的值不等于列表中的任何一个操作数的值,则返回 true。也就是说,如果操作数列表中不包含第一个操作数,则返回 true (0)。例如:“col NOT IN(x, y, z)”。这等价于“(col<>x) AND (col<>y) AND (col<>z)”。
计费示例:
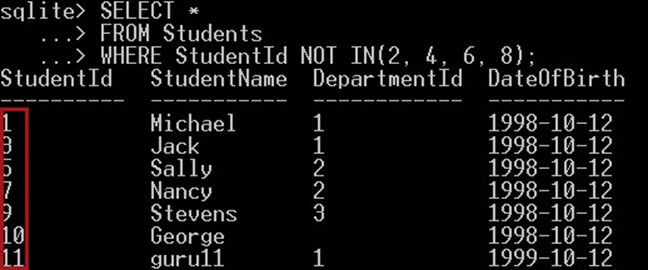
以下查询将选择 ID 不等于以下 ID 2、4、6、8 之一的学生:
SELECT * FROM Students WHERE StudentId NOT IN(2, 4, 6, 8);
这样
对于前一个查询,我们给出的结果与以下查询完全相同,因为它们是等效的:
SELECT * FROM Students WHERE (StudentId <> 2) AND (StudentId <> 4) AND (StudentId <> 6) AND (StudentId <> 8);
点赞此页 :
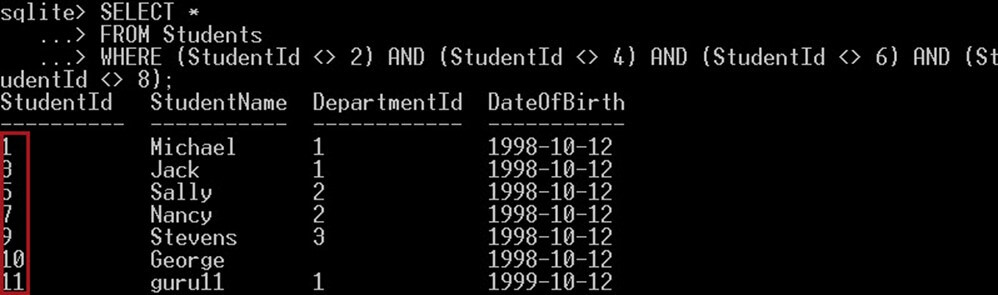
在上面的截图中,
我们使用多个不等于运算符“<>”来获取不等于以下 Id 2、4、6 或 8 的学生列表。此查询将返回除这些 Id 列表之外的所有其他学生。
SQLite EXISTS
EXISTS 运算符不接受任何操作数;它只接受其后的 SELECT 子句。如果 SELECT 子句返回任何行,则 EXISTS 运算符将返回 true (1);如果 SELECT 子句未返回任何行,则 EXISTS 运算符将返回 false (0)。
计费示例:
在下面的例子中,如果学生表中存在部门 ID,我们将选择部门的名称:
SELECT DepartmentName FROM Departments AS d WHERE EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
这会给你:

只会返回“IT、物理和艺术”这三个院系。院系名称“数学”不会被返回,因为该院系没有学生,所以学生表中不存在该院系的 ID。这就是为什么 EXISTS 运算符忽略了“数学”院系的原因。
SQLite 不是
Reverse是其后前面运算符的结果。例如:
- NOT BETWEEN – 如果 BETWEEN 返回 false,则它将返回 true,反之亦然。
- NOT LIKE – 如果 LIKE 返回 false,它将返回 true,反之亦然。
- NOT GLOB – 如果 GLOB 返回 false,它将返回 true,反之亦然。
- NOT EXISTS – 如果 EXISTS 返回 false,它将返回 true,反之亦然。
计费示例:
在下面的例子中,我们将使用 NOT 运算符和 EXISTS 运算符来获取 Students 表中不存在的部门名称,这是 EXISTS 运算符的反向结果。因此,搜索将通过 Department 表中不存在的 DepartmentId 进行。
SELECT DepartmentName FROM Departments AS d WHERE NOT EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
输出:

只会返回“数学”系。因为“数学”系是唯一一个在学生表中不存在的系。
限制和排序
SQLite 下单
SQLite 排序是通过一个或多个表达式对结果进行排序。要对结果集进行排序,您必须使用 ORDER BY 子句,如下所示:
- 首先,您必须指定 ORDER BY 子句。
- ORDER BY 子句必须在查询的末尾指定;只能在它之后指定 LIMIT 子句。
- 指定用于对数据进行排序的表达式,该表达式可以是列名或表达式。
- 表达式之后,您可以指定可选的排序方向。DESC(按降序排列数据)或 ASC(按升序排列数据)。如果您未指定任何一项,则数据将按升序排列。
- 您可以使用“,”在彼此之间指定更多表达式。
例如:
在下面的例子中,我们将选择所有按姓名降序排列的学生,然后按部门名称升序排列:
SELECT s.StudentName, d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId ORDER BY d.DepartmentName ASC , s.StudentName DESC;
这会给你:
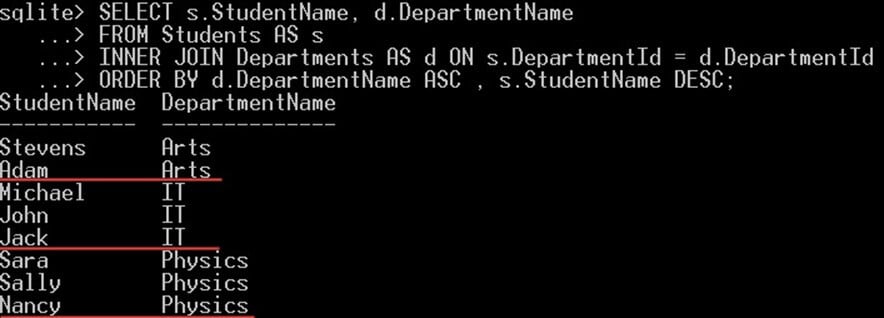
- SQLite 首先按院系名称升序对所有学生进行排序
- 然后针对每个部门名称,该部门名称下的所有学生将按姓名降序显示
SQLite 限制:
您可以使用 LIMIT 子句限制 SQL 查询返回的行数。例如,LIMIT 10 将仅返回 10 行,并忽略所有其他行。
在 LIMIT 子句中,您可以使用 OFFSET 子句选择从特定位置开始的特定行数。例如,“LIMIT 4 OFFSET 4”将忽略前 4 行,并从第 5 行开始返回 4 行,因此您将获得第 5、6、7 和 8 行。
请注意,OFFSET 子句是可选的,您可以像这样写“LIMIT 4, 4”,它将给出确切的结果。
计费示例:
在下面的例子中,我们将使用查询从学生 ID 3 开始仅返回 5 名学生:
SELECT * FROM Students LIMIT 4,3;
这将为您提供从第 5 行开始的三名学生。因此它将为您提供 StudentId 为 5、6 和 7 的行:

删除重复项
如果您的 SQL 查询返回重复值,您可以使用“DISTINCT”关键字删除这些重复项,并返回不同的值。您可以在 DISTINCT 关键字后指定多个列。
计费示例:
以下查询将返回重复的“部门名称值”:这里我们有名称为 IT、Physics 和 Arts 的重复值。
SELECT d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
这将为您提供部门名称的重复值:
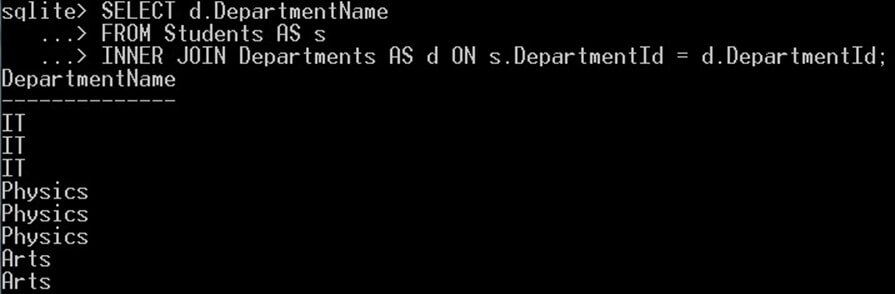
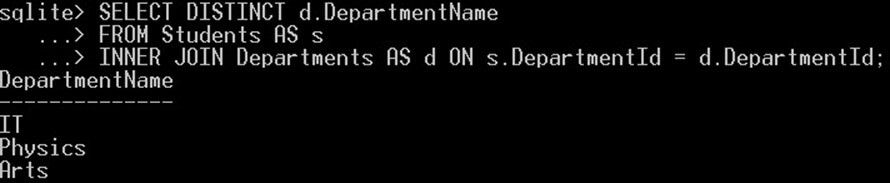
请注意,部门名称有重复值。现在,我们将使用 DISTINCT 关键字和相同的查询来删除这些重复项并仅获取唯一值。像这样:
SELECT DISTINCT d.DepartmentName FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
这将为部门名称列提供三个唯一值:
骨料
SQLite 聚合是定义在 SQLite 它将多行的多个值分组为一个值。
以下是支持的聚合 SQLite:
SQLite AVG()
返回所有 x 值的平均值。
计费示例:
在以下示例中,我们将获取学生所有考试的平均分数:
SELECT AVG(Mark) FROM Marks;
这将为您提供值“18.375”:

这些结果来自所有标记值的总和除以其计数。
COUNT() - COUNT(X) 或 COUNT(*)
返回 x 值出现的总次数。以下是您可以与 COUNT 一起使用的一些选项:
- COUNT(x):仅计算 x 值,其中 x 是列名。它将忽略 NULL 值。
- COUNT(*):计算所有列中的所有行。
- COUNT(DISTINCT x):您可以在 x 之前指定一个 DISTINCT 关键字,它将获取 x 的不同值的数量。
例如:
在以下示例中,我们将使用 COUNT(DepartmentId)、COUNT(*) 和 COUNT(DISTINCT DepartmentId) 获取部门总数以及它们的不同之处:
SELECT COUNT(DepartmentId), COUNT(DISTINCT DepartmentId), COUNT(*) FROM Students;
这会给你:

如下:
- COUNT(DepartmentId) 将为您提供所有部门 ID 的数量,并且它将忽略空值。
- COUNT(DISTINCT DepartmentId) 为您提供不同的 DepartmentId 值,只有 3 个。这是部门名称的三个不同值。请注意,学生姓名中有 8 个部门名称值。但只有三个不同的值,即数学、IT 和物理。
- COUNT(*) 计算学生表中的行数,10 名学生有 10 行。
GROUP_CONCAT() – GROUP_CONCAT(X) 或 GROUP_CONCAT(X,Y)
GROUP_CONCAT 聚合函数将多个值连接成一个值,并用逗号分隔。它具有以下选项:
- GROUP_CONCAT(X):这会将 x 的所有值连接成一个字符串,并使用逗号“,”作为值之间的分隔符。NULL 值将被忽略。
- GROUP_CONCAT(X, Y):这会将 x 的值连接成一个字符串,并使用 y 的值作为每个值之间的分隔符,而不是默认分隔符“,”。NULL 值也将被忽略。
- GROUP_CONCAT(DISTINCT X):这会将 x 的所有不同值连接成一个字符串,并使用逗号“,”作为值之间的分隔符。NULL 值将被忽略。
GROUP_CONCAT(DepartmentName) 示例
以下查询将把学生表和部门表中的所有部门名称值连接成一个以逗号分隔的字符串。因此,它不会返回值列表,而是每行返回一个值。它将在一行中仅返回一个值,所有值都以逗号分隔:
SELECT GROUP_CONCAT(d.DepartmentName) FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
这会给你:

这将为您提供 8 个部门的名称值列表,这些值连接成一个以逗号分隔的字符串。
GROUP_CONCAT(DISTINCT DepartmentName) 示例
以下查询将学生和部门表中的部门名称的不同值连接成一个以逗号分隔的字符串:
SELECT GROUP_CONCAT(DISTINCT d.DepartmentName) FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
这会给你:

请注意结果与之前的结果有何不同;仅返回三个值,即不同的部门名称,并且重复的值被删除。
GROUP_CONCAT(DepartmentName ,'&') 示例
以下查询将学生表和部门表中部门名称列的所有值连接为一个字符串,但使用字符“&”而不是逗号作为分隔符:
SELECT GROUP_CONCAT(d.DepartmentName, '&') FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId;
这会给你:

请注意,使用字符“&”代替默认字符“,”来分隔值。
SQLite MAX() 和 MIN()
MAX(X) 返回 X 值中的最高值。如果所有 x 值均为空,则 MAX 将返回 NULL 值。而 MIN(X) 返回 X 值中的最小值。如果所有 X 值均为空,则 MIN 将返回 NULL 值。
例如:
在以下查询中,我们将使用 MIN 和 MAX 函数从“Marks”表中获取最高分和最低分:
SELECT MAX(Mark), MIN(Mark) FROM Marks;
这会给你:

SQLite SUM(x),总计(x)
它们都将返回所有 x 值的总和。但它们在以下方面有所不同:
- 如果所有值都为空,则 SUM 将返回空值,但 Total 将返回 0。
- TOTAL 总是返回浮点值。如果所有 x 值都是整数,则 SUM 返回整数值。但是,如果值不是整数,它将返回浮点值。
例如:
在以下查询中,我们将使用 SUM 和 total 函数来获取“Marks”表中所有分数的总和:
SELECT SUM(Mark), TOTAL(Mark) FROM Marks;
这会给你:

如您所见,TOTAL 始终返回浮点数。但 SUM 返回整数值,因为“Mark”列中的值可能是整数。
SUM 和 TOTAL 之间的差异示例:
在以下查询中,我们将展示 SUM 和 TOTAL 在获取 NULL 值的 SUM 时的区别:
SELECT SUM(Mark), TOTAL(Mark) FROM Marks WHERE TestId = 4;
这会给你:

请注意,TestId = 4 没有分数,因此该测试为空值。SUM 返回空值作为空白,而 TOTAL 返回 0。
通过...分组
GROUP BY 子句用于指定一个或多个用于将行分组的列。具有相同值的行将聚集(排列)在一起组成组。
对于分组列中未包含的任何其他列,都可以对其使用聚合函数。
计费示例:
以下查询将为您提供每个部门的学生总数。
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId GROUP BY d. DepartmentName;
这会给你:
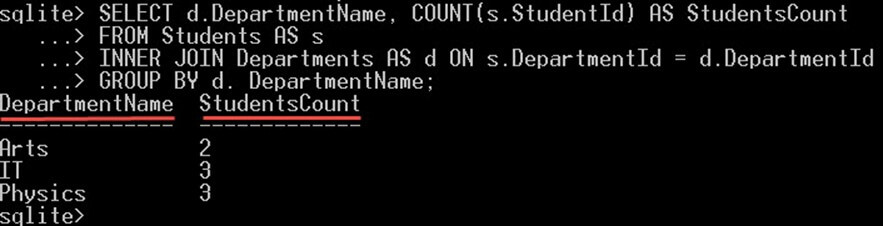
GROUPBY DepartmentName 子句会将所有学生按每个部门名称分组。对于每个“部门”组,它将统计其中的学生人数。
HAVING 子句
如果要筛选 GROUP BY 子句返回的组,则可以在 GROUP BY 后指定一个带有表达式的“HAVING”子句。该表达式将用于筛选这些组。
例如:
在以下查询中,我们将选择只有两名学生的部门:
SELECT d.DepartmentName, COUNT(s.StudentId) AS StudentsCount FROM Students AS s INNER JOIN Departments AS d ON s.DepartmentId = d.DepartmentId GROUP BY d. DepartmentName HAVING COUNT(s.StudentId) = 2;
这会给你:
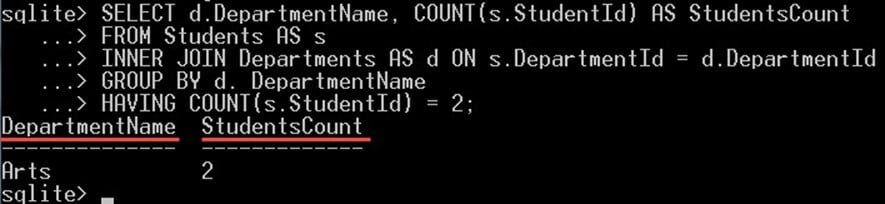
子句 HAVING COUNT(S.StudentId) = 2 将过滤返回的组,并仅返回包含两个学生的组。在我们的例子中,艺术系有 2 名学生,因此显示在输出中。
SQLite 查询和子查询
在任何查询中,您都可以在 SELECT、INSERT、DELETE、UPDATE 中或另一个子查询中使用另一个查询。
这种嵌套查询称为子查询。我们现在将看到一些在 SELECT 子句中使用子查询的示例。但是,在修改数据教程中,我们将看到如何将子查询与 INSERT、DELETE 和 UPDATE 语句一起使用。
在 FROM 子句中使用子查询示例
在以下查询中,我们将在 FROM 子句中包含一个子查询:
SELECT s.StudentName, t.Mark FROM Students AS s INNER JOIN ( SELECT StudentId, Mark FROM Tests AS t INNER JOIN Marks AS m ON t.TestId = m.TestId ) ON s.StudentId = t.StudentId;
查询:
SELECT StudentId, Mark FROM Tests AS t INNER JOIN Marks AS m ON t.TestId = m.TestId
上面的查询在这里被称为子查询,因为它嵌套在 FROM 子句中。请注意,我们给它起了一个别名“t”,以便我们可以在查询中引用从它返回的列。
此查询将为您提供:
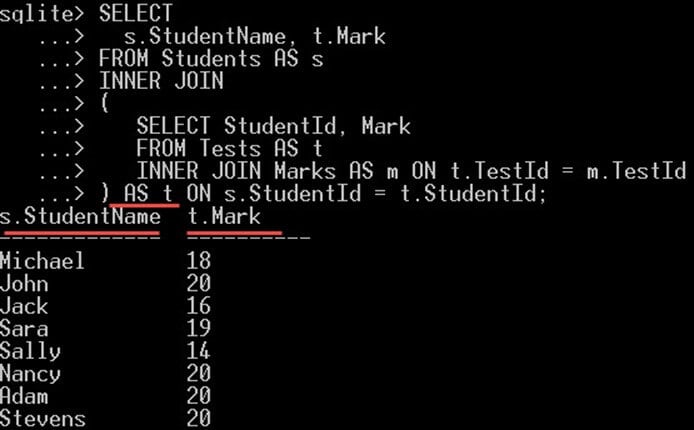
所以在我们的例子中,
- s.StudentName 是从提供学生姓名的主查询中选择的,并且
- t.Mark 是从子查询中选择的;它给出了每个学生获得的分数
在 WHERE 子句中使用子查询示例
在以下查询中,我们将在 WHERE 子句中包含一个子查询:
SELECT DepartmentName FROM Departments AS d WHERE NOT EXISTS (SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId);
查询:
SELECT DepartmentId FROM Students AS s WHERE d.DepartmentId = s.DepartmentId
上述查询在这里被称为子查询,因为它嵌套在 WHERE 子句中。子查询将返回运算符 NOT EXISTS 将使用的 DepartmentId 值。
此查询将为您提供:
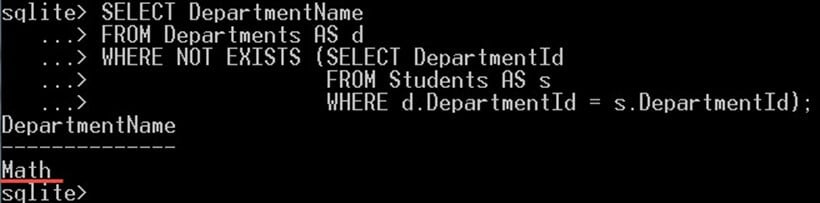
在上面的查询中,我们选择了没有学生就读的院系。也就是这里的“数学”院系。
米 Operations – UNION,Intersect
SQLite 支持以下 SET 操作:
工会和工会所有
它将多个 SELECT 语句返回的一个或多个结果集(一组行)合并为一个结果集。
UNION 将返回不同的值。但是,UNION ALL 不会返回不同的值,并且会包含重复项。
请注意,列名将是第一个 SELECT 语句中指定的列名。
UNION 示例
在下面的例子中,我们将从学生表中获取 DepartmentId 列表,并从同一列中的部门表中获取 DepartmentId 列表:
SELECT DepartmentId AS DepartmentIdUnioned FROM Students UNION SELECT DepartmentId FROM Departments;
这会给你:
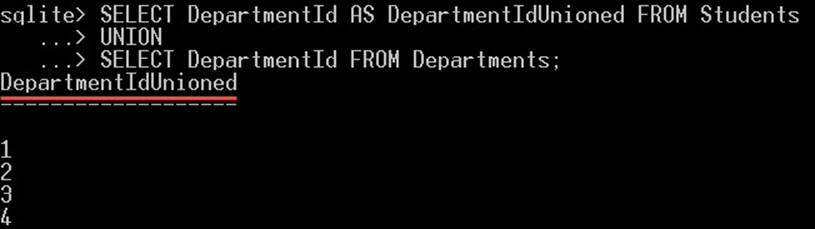
查询仅返回 5 行不同的部门 ID 值。请注意,第一个值是空值。
SQLite UNION ALL 示例
在下面的例子中,我们将从学生表中获取 DepartmentId 列表,并从同一列中的部门表中获取 DepartmentId 列表:
SELECT DepartmentId AS DepartmentIdUnioned FROM Students UNION ALL SELECT DepartmentId FROM Departments;
这会给你:
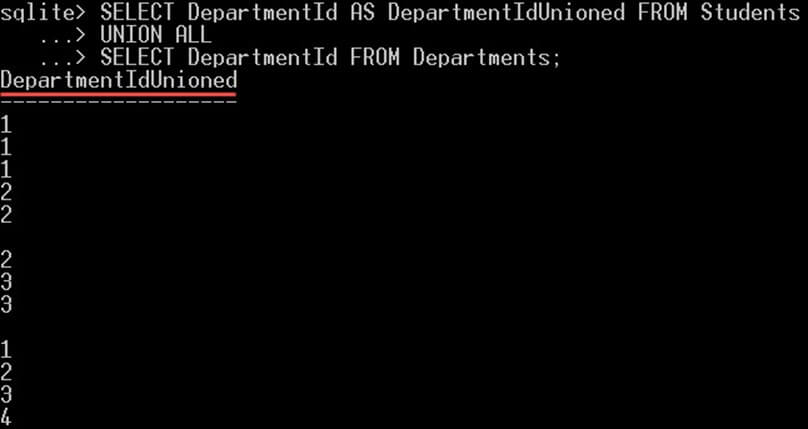
该查询将返回 14 行,其中 10 行来自 students 表,4 行来自 entities 表。请注意,返回的值中有重复项。另外请注意,列名是第一个 SELECT 语句中指定的列名。
现在,让我们看看如果将 UNION ALL 替换为 UNION,UNION all 会产生怎样的不同结果:
SQLite 相交
返回两个组合结果集中都存在的值。存在于其中一个组合结果集中的值将被忽略。
例如:
在以下查询中,我们将选择表 Students 和 Departments 中 DepartmentId 列中都存在的 DepartmentId 值:
SELECT DepartmentId FROM Students Intersect SELECT DepartmentId FROM Departments;
这会给你:
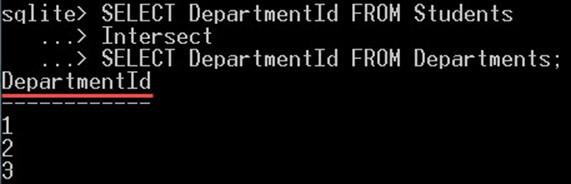
查询仅返回三个值 1、2 和 3。这些值在两个表中都存在。
但是,没有包括值 null 和 4,因为 null 值仅存在于 students 表中,而不存在于 institutions 表中。而且,值 4 存在于 entities 表中,而不存在于 students 表中。
这就是为什么值 NULL 和 4 都被忽略并且不包含在返回值中的原因。
除
假设您有两个行列表,list1 和 list2,并且您只想要 list1 中不存在于 list2 中的行,则可以使用“EXCEPT”子句。EXCEPT 子句比较这两个列表并返回 list1 中存在但不存在于 list2 中的行。
例如:
在以下查询中,我们将选择部门表中存在但学生表中不存在的 DepartmentId 值:
SELECT DepartmentId FROM Departments EXCEPT SELECT DepartmentId FROM Students;
这会给你:

查询仅返回值 4。这是部门表中存在的唯一值,但不存在于学生表中。
NULL 处理
“NULL”值是一个特殊值。 SQLite它用于表示未知值或缺失值。请注意,空值与“0”或空白值完全不同。因为0和空白值是已知值,而空值是未知值。
NULL 值需要特殊处理 SQLite,我们现在将看到如何处理 NULL 值。
搜索 NULL 值
您不能使用常规的等式运算符 (=) 来搜索空值。例如,以下查询搜索 DepartmentId 值为空的学生:
SELECT * FROM Students WHERE DepartmentId = NULL;
此查询不会给出任何结果:
![]()
因为 NULL 值不等于任何其他值(包括空值本身),所以它没有返回任何结果。
但是,为了使查询生效,您必须使用“IS NULL”运算符来查找空值,如下所示:
SELECT * FROM Students WHERE DepartmentId IS NULL;
这会给你:

查询将返回那些 DepartmentId 值为空的学生。
如果要获取非空值,则必须使用“IS NOT NULL”运算符,如下所示:
SELECT * FROM Students WHERE DepartmentId IS NOT NULL;
这会给你:
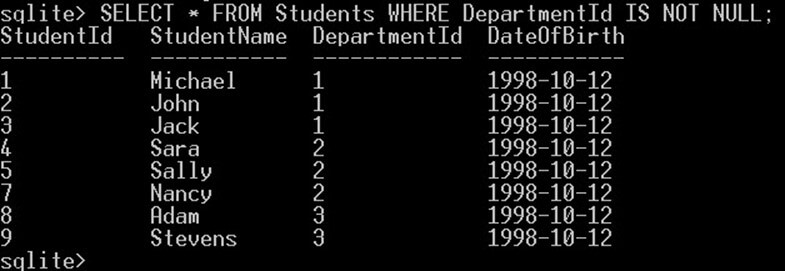
查询将返回那些没有 NULL DepartmentId 值的学生。
条件结果
如果您有一个值列表,并且想要根据某些条件选择其中任何一个值。为此,该特定值的条件必须为真才能被选中。
CASE 表达式将评估这些条件列表的所有值。如果条件为真,它将返回该值。
例如,如果您有一列“成绩”,并且您想要根据成绩值选择一个文本值,如下所示:
– 如果成绩高于 85 分,则为“优秀”。
– 如果成绩在 70 到 85 之间,则为“非常好”。
– 如果成绩在 60 到 70 之间,则为“良好”。
然后您可以使用 CASE 表达式来执行此操作。
这可用于在 SELECT 子句中定义一些逻辑,以便您可以根据某些条件(例如 if 语句)选择某些结果。
CASE 运算符可以用以下不同的语法定义:
您可以使用不同的条件:
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 WHEN condition3 THEN result3 … ELSE resultn END
或者,您可以只使用一个表达式并输入不同的可能值以供选择:
CASE expression WHEN value1 THEN result1 WHEN value2 THEN result2 WHEN value3 THEN result3 … ELSE restuln END
请注意,ELSE 子句是可选的。
例如:
在以下示例中,我们将使用 CASE 表达式,并将 Students 表中 department Id 列的值为 NULL,以显示文本“无系”,如下所示:
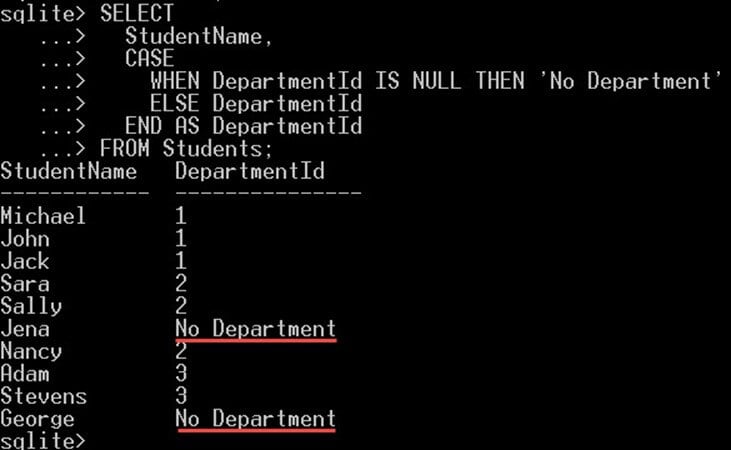
SELECT StudentName, CASE WHEN DepartmentId IS NULL THEN 'No Department' ELSE DepartmentId END AS DepartmentId FROM Students;
- CASE 运算符将检查 DepartmentId 的值是否为空。
- 如果它是一个 NULL 值,那么它将选择文字值“无部门”而不是 DepartmentId 值。
- 如果不是空值,那么它将选择 DepartmentId 列的值。
这将为您提供如下所示的输出:
公用表表达式
通用表表达式 (CTE) 是在 SQL 语句中用给定名称定义的子查询。
它比子查询有一个优势,因为它是在 SQL 语句之外定义的,并且可以使查询更易于阅读、维护和理解。
可以通过将 WITH 子句放在 SELECT 语句前面来定义公共表表达式,如下所示:
WITH CTEname AS ( SELECT statement ) SELECT, UPDATE, INSERT, or update statement here FROM CTE
“CTEname”是您为CTE指定的任何名称,您可以稍后使用它来引用该CTE。请注意,您可以在CTE上定义SELECT、UPDATE、INSERT或DELETE语句。
现在,让我们看一个如何在 SELECT 子句中使用 CTE 的例子。
例如:
在下面的例子中,我们将从 SELECT 语句定义一个 CTE,然后稍后在另一个查询中使用它:
WITH AllDepartments AS ( SELECT DepartmentId, DepartmentName FROM Departments ) SELECT s.StudentId, s.StudentName, a.DepartmentName FROM Students AS s INNER JOIN AllDepartments AS a ON s.DepartmentId = a.DepartmentId;
在这个查询中,我们定义了一个 CTE,并将其命名为“AllDepartments”。这个 CTE 是由一个 SELECT 查询定义的:
SELECT DepartmentId, DepartmentName FROM Departments
然后,我们定义了 CTE 之后,我们在之后的 SELECT 查询中使用它。
请注意,公用表表达式不会影响查询的输出。它是一种定义逻辑视图或子查询以便在同一查询中重用它们的方法。公用表表达式就像您声明的变量,并将其重用为子查询。只有 SELECT 语句会影响查询的输出。
此查询将为您提供:

高级查询
高级查询是包含复杂连接、子查询和一些聚合的查询。在下一节中,我们将看到一个高级查询的示例:
我们从哪里得到,
- 院系名称及各院系所有学生
- 学生姓名用逗号分隔,
- 显示该院系至少有三名学生
SELECT d.DepartmentName, COUNT(s.StudentId) StudentsCount, GROUP_CONCAT(StudentName) AS Students FROM Departments AS d INNER JOIN Students AS s ON s.DepartmentId = d.DepartmentId GROUP BY d.DepartmentName HAVING COUNT(s.StudentId) >= 3;
我们添加了一个 JOIN 子句,用于从 Departments 表中获取 DepartmentName。之后,我们添加了一个 GROUP BY 子句,其中包含两个聚合函数:
- “COUNT” 统计各院系组的学生人数。
- GROUP_CONCAT 将每个组的学生用逗号分隔成一个字符串。
在GROUP BY之后,我们使用HAVING子句来过滤部门,并且只选择那些至少有3名学生的部门。
结果如下:
