XPath 中 Selenium: 教程

XPath 是什么 Selenium?
XPath 中 Selenium 是用于在页面的 HTML 结构中导航的 XML 路径。它是一种使用 XML 路径表达式查找网页上任何元素的语法或语言。XPath 可用于 HTML 和 XML 文档,以使用 HTML DOM 结构查找网页上任何元素的位置。
In Selenium 如果使用 id、class、name 等常规定位器找不到元素,则使用 XPath 在网页上查找元素。
在本教程中,我们将学习 Xpath 和不同的 XPath 表达式来查找复杂或动态元素,这些元素的属性在刷新或任何操作时会动态变化。
XPath 语法
XPath 包含位于网页上的元素的路径。创建 XPath 的标准 XPath 语法是。
Xpath=//tagname[@attribute='value']
下面通过屏幕截图解释了 selenium 中 XPath 的基本格式。
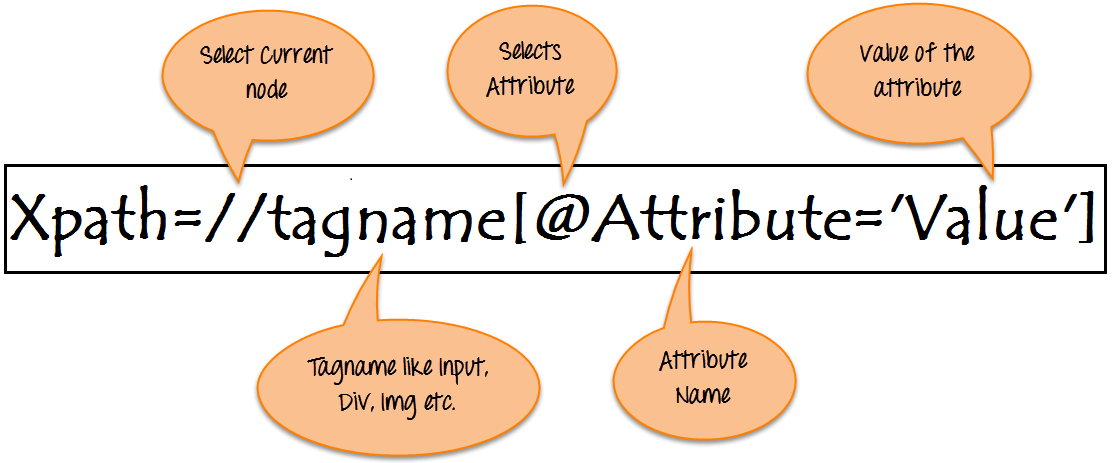
- // : 选择当前节点。
- 标签名称: 特定节点的标签名。
- @: 选择属性。
- 属性: 节点的属性名称。
- 价值: 属性的值。
为了准确地找到网页上的元素,有不同类型的定位器:
| XPath定位器 | 在网页上查找其他元素 |
|---|---|
| ID | 通过元素 ID 查找元素 |
| 班级名称 | 通过元素的类名查找元素 |
| 姓名 | 通过元素名称查找元素 |
| 链接文字 | 通过链接的文本查找元素 |
| XPath的 | 查找动态元素并在网页各个元素之间遍历所需的 XPath |
| CSS 路径 | CSS 路径还可以定位没有名称、类或 ID 的元素。 |
X-path 的类型
XPath 有两种类型:
1)绝对 XPath
2)相对 XPath
绝对 XPath
这是查找元素的直接方法,但绝对 XPath 的缺点是,如果元素的路径发生任何更改,那么 XPath 就会失败。
XPath 的关键特性是它以单个正斜杠(/)开头,这意味着您可以从根节点选择元素。
下面是屏幕中显示的元素的绝对 Xpath 表达式的示例。
注意:您可以在此处练习以下 XPath 练习 https://demo.guru99.com/test/selenium-xpath.html
点击 开始 如果视频无法访问
绝对 XPath:
/html/body/div[2]/div[1]/div/h4[1]/b/html[1]/body[1]/div[2]/div[1]/div[1]/h4[1]/b[1]

相对Xpath
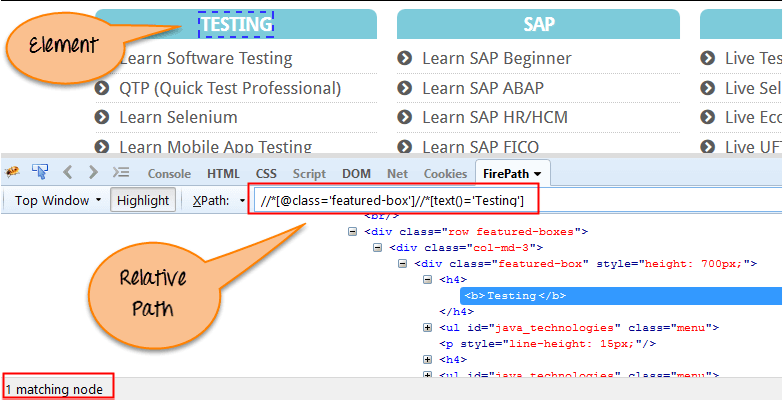
相对Xpath 从 HTML DOM 结构的中间开始。它以双斜杠 (//) 开头。它可以在网页上的任何位置搜索元素,这意味着无需编写长 xpath,您可以从 HTML DOM 结构的中间开始。始终首选相对 Xpath,因为它不是从根元素开始的完整路径。
下面是屏幕中显示的相同元素的相对 XPath 表达式的示例。这是通过 XPath 查找元素的常用格式。
点击 开始 如果视频无法访问
Relative XPath: //div[@class='featured-box cloumnsize1']//h4[1]//b[1]
什么是 XPath 轴?
XPath 轴从当前上下文节点开始搜索 XML 文档中的不同节点。XPath 轴用于查找动态元素,而常规 XPath 方法由于缺少 ID、类名、名称等信息,无法找到这些元素。XPath 中的 Selenium 包括 Contains、AND、Absolute XPath 和 Relative XPath 等几种方法,用于根据各种属性和条件识别和定位动态元素。
轴方法用于查找那些在刷新或任何其他操作时动态变化的元素。轴方法通常用于 Selenium 网络驱动程序 如孩子、父母、祖先、兄弟姐妹、前任、自我等。
如何编写动态 XPath Selenium 网络驱动程序
1)基本 XPath
XPath 表达式根据以下属性选择节点或节点列表: ID、姓名、班级名称等等,从如下所示的 XML 文档中获取。
Xpath=//input[@name='uid']
这是访问该页面的链接 https://demo.guru99.com/test/selenium-xpath.html

一些更基本的 xpath 表达式:
Xpath=//input[@type='text'] Xpath=//label[@id='message23'] Xpath=//input[@value='RESET'] Xpath=//*[@class='barone'] Xpath=//a[@href='https://demo.guru99.com/'] Xpath=//img[@src='//guru99.com/images/home/java.png']
2)包含()
Contains() 是 XPath 表达式中使用的方法。当任何属性的值动态变化时使用它,例如登录信息。
包含功能能够查找具有部分文本的元素,如下面的 XPath 示例所示。
在此示例中,我们尝试仅使用属性的部分文本值来识别元素。在下面的 XPath 表达式中,部分值“sub”用于代替提交按钮。可以观察到元素已成功找到。
‘Type’ 的完整值为 ‘submit’,但仅使用部分值 ‘sub’。
Xpath=//*[contains(@type,'sub')]
“name”的完整值是“btnLogin”,但仅使用部分值“btn”。
Xpath=//*[contains(@name,'btn')]
在上面的表达式中,我们将“name”作为属性,将“btn”作为部分值,如下面的屏幕截图所示。这将找到 2 个元素(LOGIN 和 RESET),因为它们的“name”属性以“btn”开头。

类似地,在下面的表达式中,我们将“id”作为属性,将“message”作为部分值。这将找到 2 个元素(“用户 ID 不能为空”和“密码不能为空”),因为其“id”属性以“message”开头。
Xpath=//*[contains(@id,'message')]

在下面的表达式中,我们将链接的“文本”作为属性,将“here”作为部分值,如下面的屏幕截图所示。这将找到链接(“here”),因为它显示文本“here”。
Xpath=//*[contains(text(),'here')]
Xpath=//*[contains(@href,'guru99.com')]

3)使用 OR 和 AND
在 OR 表达式中,使用两个条件,第一个条件或第二个条件是否应为真。如果任何一个条件为真或两个条件都为真,它也适用。意味着任何一个条件都必须为真才能找到元素。
在下面的 XPath 表达式中,它标识单个或两个条件都为真的元素。
Xpath=//*[@type='submit' or @name='btnReset']
将两个元素分别突出显示为具有“type”属性的“LOGIN”元素和具有“name”属性的“RESET”元素。

在 AND 表达式中,使用两个条件,两个条件都必须为真才能找到元素。如果任何一个条件为假,则无法找到元素。
Xpath=//input[@type='submit' and @name='btnLogin']
在下面的表达式中,突出显示“LOGIN”元素,因为它同时具有属性“type”和“name”。

4)Xpath 以...开头
XPath 以() 开头 是一个用于查找在刷新或网页上进行其他动态操作时属性值会发生变化的 Web 元素的函数。在此方法中,将匹配属性的起始文本以查找属性值动态变化的元素。您还可以查找属性值为静态(未更改)的元素。
例如:假设特定元素的 ID 动态变化,如下:
ID=”消息12″
ID=”消息345″
ID=”消息8769″
等等。但初始文本是相同的。在这种情况下,我们使用 Start-with 表达式。
在下面的表达式中,有两个元素的 id 以“message”开头(即“User-ID 不能为空”和“Password 不能为空”)。在下面的例子中,XPath 查找那些 'ID' 以 'message' 开头的元素。
Xpath=//label[starts-with(@id,'message')]

5)XPath Text() 函数
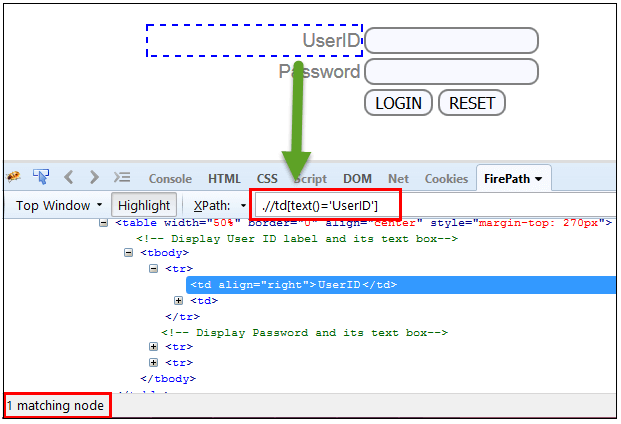
此 XPath text() 函数 是 selenium webdriver 的内置函数,用于根据 Web 元素的文本定位元素。它有助于找到准确的文本元素,并将元素定位在文本节点集内。要定位的元素应为字符串形式。
在此表达式中,使用文本函数,我们找到具有完全文本匹配的元素,如下所示。在我们的例子中,我们找到了带有文本“UserID”的元素。
Xpath=//td[text()='UserID']
XPath 轴方法
这些 XPath 轴方法用于查找复杂或动态元素。下面我们将看到其中一些方法。
为了说明这些 XPath 轴方法,我们将使用 Guru99家银行的演示网站。
1)正在关注
选择当前节点的文档中的所有元素()[UserID输入框是当前节点],如下图所示。
Xpath=//*[@type='text']//following::input

有 3 个“输入”节点使用“以下”轴进行匹配 - 密码、登录和重置按钮。如果您想关注任何特定元素,则可以使用以下 XPath 方法:
Xpath=//*[@type='text']//following::input[1]
您可以根据需要通过输入[1],[2]…………等来更改 XPath。
输入“1”后,下面的屏幕截图找到特定节点“密码”输入框元素。

2)祖先
祖先轴选择当前节点的所有祖先元素(祖父、父母等),如下面的屏幕所示。
在下面的表达式中,我们正在寻找当前节点(“ENTERPRISE TESTING”节点)的祖先元素。
Xpath=//*[text()='Enterprise Testing']//ancestor::div

有 13 个“div”节点使用“ancestor”轴进行匹配。如果您想要关注任何特定元素,则可以使用下面的 XPath,其中您可以根据需要更改数字 1、2:
Xpath=//*[text()='Enterprise Testing']//ancestor::div[1]
您可以根据需要通过输入[1],[2]…………等来更改 XPath。
3)儿童
选择当前节点的所有子元素 (Java),如下图所示。
Xpath=//*[@id='java_technologies']//child::li

有 71 个“li”节点使用“child”轴匹配。如果您想要关注任何特定元素,则可以使用以下 xpath:
Xpath=//*[@id='java_technologies']//child::li[1]
您可以根据需要通过输入[1],[2]…………等来更改xpath。
4) 前置
选择当前节点之前的所有节点,如下面的屏幕所示。
在下面的表达式中,它标识了“LOGIN”按钮之前的所有输入元素 用户身份 和 密码 输入元素。
Xpath=//*[@type='submit']//preceding::input
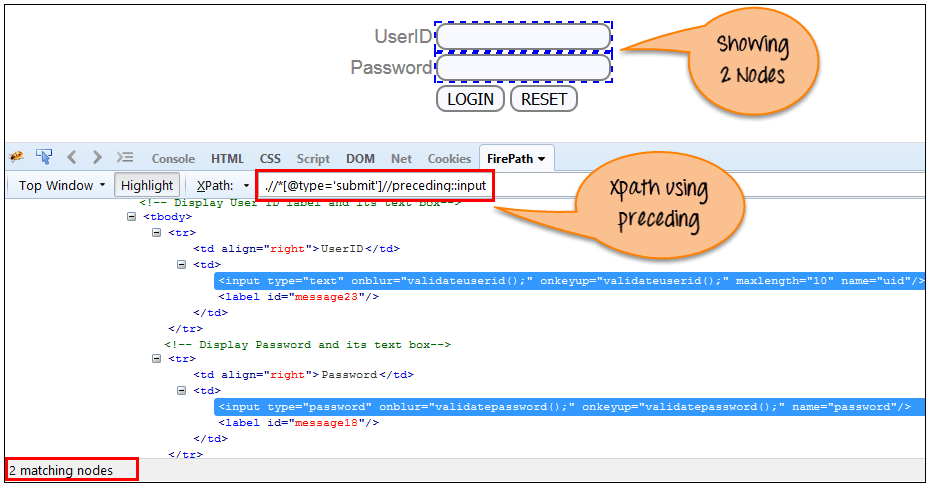
有 2 个“输入”节点使用“前一个”轴进行匹配。如果您想要关注任何特定元素,则可以使用以下 XPath:
Xpath=//*[@type='submit']//preceding::input[1]
您可以根据需要通过输入[1],[2]…………等来更改xpath。
5)跟随兄弟姐妹
选择上下文节点的以下兄弟节点。兄弟节点与当前节点处于同一级别,如下图所示。它将查找当前节点之后的元素。
xpath=//*[@type='submit']//following-sibling::input

一个输入节点通过使用“following-sibling”轴进行匹配。
6)家长
选择当前节点的父节点,如下面的屏幕所示。
Xpath=//*[@id='rt-feature']//parent::div

有 65 个“div”节点使用“parent”轴匹配。如果您想要关注任何特定元素,则可以使用以下 XPath:
Xpath=//*[@id='rt-feature']//parent::div[1]
您可以根据需要通过输入[1],[2]…………等来更改 XPath。
7) 自我
选择当前节点或“自身”意味着它表示节点本身,如下面的屏幕所示。

使用“self”轴匹配一个节点。它始终只找到一个节点,因为它代表自身元素。
Xpath =//*[@type='password']//self::input
8)后代
选择当前节点的后代,如下面的屏幕所示。
在下面的表达式中,它标识了当前元素(“主体环绕”框架元素)的所有元素后代,即节点下方(子节点、孙节点等)。
Xpath=//*[@id='rt-feature']//descendant::a
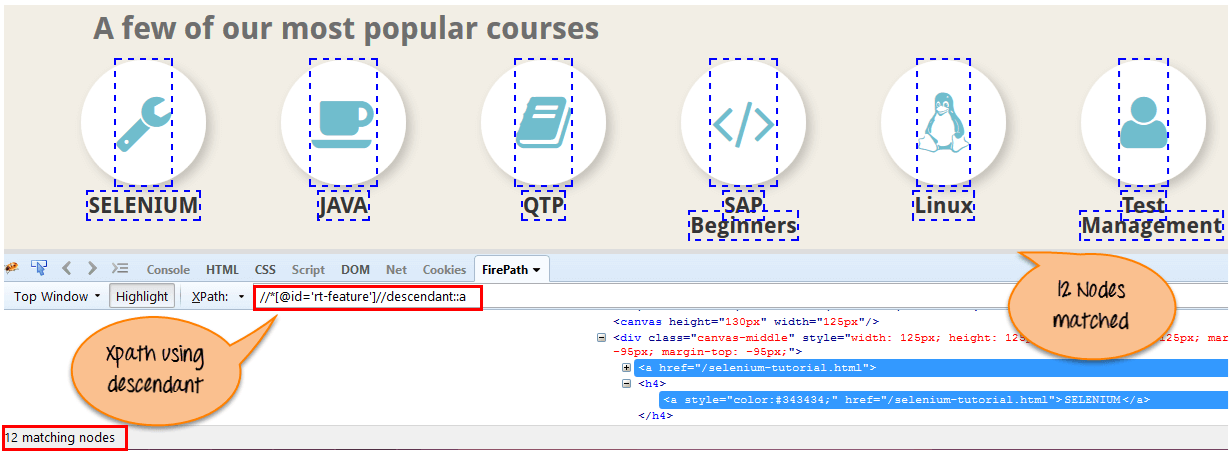
有 12 个“链接”节点使用“后代”轴进行匹配。如果您想要关注任何特定元素,则可以使用以下 XPath:
Xpath=//*[@id='rt-feature']//descendant::a[1]
您可以根据需要通过输入[1],[2]…………等来更改 XPath。
常见问题
结语
需要 XPath 来查找网页上的元素并对该特定元素执行操作。
- selenium XPath 有两种类型:
- 绝对 XPath
- 相对 XPath
- XPath 轴是用于查找动态元素的方法,否则无法通过常规 XPath 方法找到
- XPath 表达式根据 XML 文档中的 ID、Name、Classname 等属性选择节点或节点列表。