词嵌入和 Word2Vec 示例
⚡ 智能摘要
词嵌入和 Word2Vec 将文本转换为稠密的数值向量,以便机器学习模型识别含义相近的词语。本资源解释了这项技术,包括其 CBOW 和 Skip-Gram 架构、激活函数,以及一个完整的 Gensim 实现,可用于实际应用。
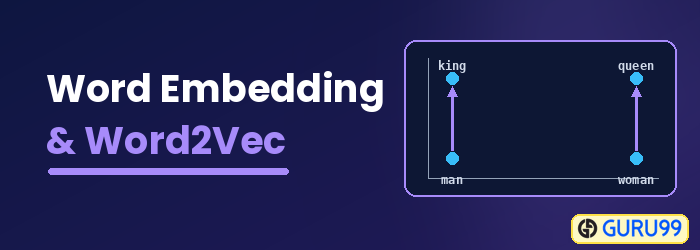
什么是词嵌入?
单词嵌入 词嵌入是一种词表示类型,它允许机器学习算法理解含义相近的词语。它是一种语言建模和特征学习技术,利用神经网络、概率模型或对词共现矩阵进行降维,将词语映射到实数向量。一些词嵌入模型包括 Word2vec(Google)、GloVe(斯坦福大学)和fastText(Facebook)。
词嵌入也称为分布式语义模型、分布式表示模型、语义向量空间或向量空间模型。当你阅读这些名称时,你会遇到“词”这个词。 语义这意味着将相似的词语归类在一起。例如,苹果、芒果和香蕉等水果应该放在一起,而书籍则会远离这些词语。更广义地说,词嵌入会创建一个水果向量,该向量与书籍的向量表示相距甚远。
Word Embedding 用在什么地方?
词嵌入有助于特征生成、文档聚类、文本分类和自然语言处理等任务。让我们列举这些应用并逐一讨论。
- 计算相似的词: 词嵌入用于向预测模型预测的词语推荐相似词。此外,它还会推荐不相似的词语以及最常用的词语。
- 创建一组相关词: 它用于语义组ping它将具有相似特征的事物归为一类,并将不相似的事物推到一边。
- 文本分类的特征: 文本被映射到向量数组,这些数组被输入到模型中进行训练和预测。基于文本的分类器模型无法直接在字符串上进行训练,因此需要将文本转换为机器可训练的形式。其语义构建功能进一步有助于基于文本的分类。
- 文档聚类: 这是词嵌入和 Word2vec 被广泛应用的另一个领域。
- 自然语言处理: 在许多应用中,词嵌入都非常有用,并且优于特征提取。trac词性标注、情感分析和句法分析等分析阶段。
既然你已经了解了词嵌入的应用领域,那么让我们来看看用于创建这些嵌入的最流行的模型。
什么是 Word2vec?
词向量 词嵌入是一种用于生成词向量的技术或模型,旨在更好地表示词语。它是一种自然语言处理方法,能够捕捉大量精确的句法和语义词语关系。它是一个浅层的两层神经网络,经过训练后,可以检测同义词并为不完整的句子提供补充词语建议。
在继续之前,请先看一下浅层神经网络和深度神经网络之间的区别,如下图所示的词嵌入示例图:
浅层神经网络仅在输入层和输出层之间包含一个隐藏层,而深度神经网络则在输入层和输出层之间包含多个隐藏层。输入层由节点组成,而隐藏层和输出层均包含神经元。
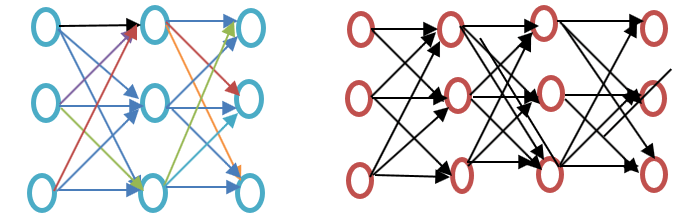
Word2vec 是一个两层网络,其中包含一个输入层、一个隐藏层和一个输出层。
Word2vec是由Tomas Mikolov领导的一组研究人员开发的。 GoogleWord2vec 比潜在语义分析模型更好、更高效。
为什么使用 Word2vec?
Word2vec 将词语表示为向量空间形式。词语以向量的形式呈现,向量的排列方式使得含义相近的词语彼此靠近,含义不同的词语则彼此远离。这也被称为语义关系。神经网络无法理解文本,它们只能理解数字。词嵌入提供了一种将文本转换为数值向量的方法。
Word2vec 能够重构词语的语言语境。在深入探讨之前,我们先来了解一下什么是语言语境。通常情况下,当我们说话或写作进行交流时,其他人会试图理解句子的目的。例如,“印度的气温是多少?” 这句话的语境是用户想知道“印度的气温”。简而言之,句子的主要目的是提供语境。围绕口语或书面语的词语或句子有助于确定语境的含义。Word2vec 正是通过这些语境来学习词语的向量表示。
Word2vec 的作用是什么?
词嵌入之前
了解词嵌入出现之前使用的方法及其缺点至关重要,接下来我们将探讨词嵌入如何利用 Word2vec 方法克服这些缺点。最后,我们将深入讲解 Word2vec 的工作原理,因为理解其运作机制非常重要。
潜在语义分析方法
这是词嵌入出现之前使用的方法。它采用了词袋模型(Bag of Words)的概念,将单词表示为编码向量。这是一种稀疏向量表示,其维度等于词汇表的大小。如果单词出现在词典中,则计入统计;否则,不计入统计。要了解更多信息,请参阅下面的程序。
Word2vec 示例

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
输出:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code 说明
- CountVectorizer 模块用于根据单词的拟合情况存储词汇表。该模块是从 sklearn 导入的。
- 使用 CountVectorizer 类创建对象。
- 将要拟合到 CountVectorizer 中的数据写入列表。
- 数据适合于从 CountVectorizer 类创建的对象。
- 使用词袋模型,根据词汇表统计数据中的词数。如果某个词或词元不在词汇表中,则将其索引位置设为零。
- 第 5 行的变量 x 被转换为数组(x 有一个可用的方法)。这样就得到了第 3 行提供的句子或列表中每个标记的出现次数。
- 这显示了使用第 4 行数据拟合词汇表时所包含的特征。
在潜在语义方法中,行代表唯一词,列代表该词在文档中出现的次数。它以文档矩阵的形式表示词。词频-逆文档频率(TF-IDF)用于计算词在文档中的出现频率,即词在文档中的出现频率除以该词在整个语料库中的出现频率。
词袋方法的缺点
- 它忽略单词的顺序;例如, 这不好 = 这很糟糕.
- 它忽略了词语的上下文。假设我们写出句子“他热爱书籍。教育的最佳途径在于书籍。”它会创建两个向量:一个代表“他热爱书籍”,另一个代表“教育的最佳途径在于书籍”。它会将这两个向量视为正交向量,这使得它们相互独立,但实际上,它们是相关的。
为了克服这些局限性,人们开发了词嵌入技术,而 Word2vec 就是实现该技术的一种方法。
Word2vec 如何工作?
Word2vec 通过预测单词的上下文来学习单词。例如,我们来看单词“He”。 爱 足球。”
我们想要计算单词的 Word2vec: 爱.
假设:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
这个单词 爱 遍历语料库中的每个词。词与词之间的句法关系和语义关系都被编码。这有助于查找相似词和类比词。
单词的所有随机特征 爱 计算这些特征。借助某种方法,这些特征会根据相邻词或上下文词进行更改或更新。 反向传播 方法。
另一种学习方法是,如果两个词的语境相似,或者两个词具有相似的特征,那么这些词就是相关的。
词向量 Archi质地
Word2vec 使用两种架构:
- 连续词袋(CBOW)
- 跳过语法
在深入探讨之前,我们先来讨论一下从词表示的角度来看,这些架构或模型为何如此重要。词表示的学习本质上是无监督的,但训练模型需要目标/标签。Skip-gram 和 CBOW 将无监督的词表示转换为有监督的形式,以便进行模型训练。
在 CBOW 中,使用周围上下文窗口的窗口来预测当前单词。例如,如果 wI-1,WI-2,Wi + 1,Wi + 2 给定单词或上下文,该模型将提供 wi.
Skip-Gram 算法与 CBOW 算法的作用相反,它根据单词预测给定的序列或上下文。你可以反过来理解这个例子。如果 wi 如果给定,这将预测上下文,或者 wI-1,WI-2,Wi + 1,Wi + 2.
Word2vec 提供了 CBOW(连续词袋模型)和 skip-gram 两种模型选择。这些参数在模型训练过程中设置。此外,还可以选择使用负采样或分层 softmax 层。
连续的词袋
让我们绘制一个简单的 Word2vec 示例图来理解连续词袋架构。

让我们用数学方法计算一下这些方程。假设 V 是词汇表大小,N 是隐藏层大小。输入定义为 { xI-1,XI-2,Xi + 1,Xi + 2 我们通过将 V * N 相乘得到权重矩阵。另一个矩阵是通过将输入向量与权重矩阵相乘得到的。这也可以用以下等式来理解。
h = xitW
其中 xit 其中 W 分别为输入向量和权重矩阵。
要计算上下文与下一个单词的匹配度,请参考以下公式。
u = 预测表示 * h
其中,预测表示是通过上述方程中的模型获得的。
Skip-Gram 模型
Skip-Gram 方法用于根据输入词预测句子。为了更好地理解它,让我们绘制如下 Word2vec 示例中所示的图表。

可以将其视为连续词袋模型的逆过程,其中输入是单词,模型提供上下文或序列。我们还可以得出结论,目标词被作为输入,输出层被多次复制以容纳选定数量的上下文词。所有输出层的误差向量被求和,并通过反向传播算法调整权重。
选择哪种型号?
CBOW 的速度比 skip-gram 快数倍,并且能更好地表示常用词的频率,而 skip-gram 只需要少量训练数据,甚至还能表示罕见词或短语。下表对这两种架构进行了简要比较。
| 方面 | CBOW | 跳格 |
|---|---|---|
| 预测 | 根据上下文预测目标词。 | 根据目标词预测上下文 |
| 训练速度 | 更快 | 比较慢 |
| 常用词 | 精度更高 | 精度较低 |
| 生僻词 | 代表性较弱 | 更强的代表性 |
| 训练数据 | 需要更多数据 | 数据量较少时也能正常工作 |
Word2vec 与 NLTK 的关系
NLTK 是天然的 Language Tool该工具包用于文本预处理。它可以执行各种操作,例如词性标注、词形还原、词干提取、停用词去除以及去除罕见词或极少使用的词。它有助于清理文本并从有效词中提取特征。另一方面,Word2vec 用于语义(将密切相关的项放在一起)和句法(序列)匹配。使用 Word2vec,可以查找相似词、不相似词、进行降维等等。Word2vec 的另一个重要功能是将文本的高维表示转换为低维向量。
在哪里使用 NLTK 和 Word2vec?
如果要完成一些如上所述的通用任务,如分词、词性标注和句法分析,则必须使用 NLTK;而要根据上下文、主题建模或文档相似性来预测单词,则必须使用 Word2vec。
通过代码说明 NLTK 与 Word2vec 的关系
NLTK 和 Word2vec 可以结合使用,以查找相似的词表示或进行句法匹配。NLTK 工具包可以加载 NLTK 自带的许多软件包,并可以使用 Word2vec 创建模型。之后,该模型可以用于实时词的测试。以下代码展示了二者的结合应用。在进行后续处理之前,请先查看 NLTK 提供的语料库。您可以使用以下命令下载:
nltk(nltk.download('all'))

请参阅屏幕截图中的代码。
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

输出:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
的解释 Code
- nltk 库已导入,您可以从中下载我们将在下一步中使用的 abc 语料库。
- Gensim 已导入。如果尚未安装 Gensim Word2vec,请使用命令“pip3 install gensim”进行安装。请参见以下屏幕截图。

- 导入已使用 nltk.download('abc') 下载的 abc 语料库。
- 将文件作为句子传递给 Word2vec 模型,该模型使用 Gensim 导入。
- 词汇以变量的形式存储。
- 该模型在样本词上进行了测试。 科学因为这些文件与科学相关。
- 模型预测这里出现的类似词语是“科学”。
激活器和 Word2Vec
神经元的激活函数定义了给定一组输入时该神经元的输出。它的灵感来源于我们大脑的活动,在大脑中,不同的神经元会因不同的刺激而被激活。让我们通过下图来理解激活函数。

这里 x1、x2、…、x4 是神经网络的节点。
w1、w2、w3 是节点的权重。
所有权重和节点值的总和(Σ)作为激活函数。
为什么要有激活函数?
如果没有使用激活函数,输出将是线性的,但线性函数的功能有限。为了实现诸如目标检测、图像分类等复杂功能,需要使用激活函数。ping 对于使用语音的文本以及许多其他非线性输出,都需要激活函数。
词嵌入(Word2vec)中激活层的计算方式
Softmax 层(归一化指数函数)是输出层函数,用于激活或触发每个节点。另一种方法是分层 Softmax,其复杂度为 O(log )。2而 softmax 的复杂度为 O(V),其中 V 为词汇表大小。二者的区别在于分层 softmax 层的复杂度降低。要理解其功能,请参考以下词嵌入示例:

假设我们要计算观察到这个词的概率 爱 在给定特定上下文的情况下,从根节点到叶节点的流会首先流向节点 2,然后流向节点 5。因此,如果词汇量为 8,则只需要三次计算。这使得我们可以分解计算单个词的概率(爱).
除了 Hierarchical Softmax 之外还有哪些其他可用选项?
从总体上看,可用的词嵌入选项有:微分 Softmax、CNN-Softmax、重要性采样、自适应重要性采样、噪声对比估计、负采样、自归一化和不频繁归一化。
具体来说,对于 Word2vec,我们有负样本可用。
负采样是一种训练数据采样方法。它与随机梯度下降有些类似,但也有一些区别。负采样只寻找负样本作为训练数据。它基于噪声对比估计,随机采样上下文中不存在的词。这是一种快速的训练方法,并且随机选择上下文。如果预测词出现在随机选择的上下文中,则两个向量会彼此接近。
可以得出什么结论?
激活器就像我们的神经元在受到外部刺激时一样,能够激活神经元。在词嵌入中,Softmax 层是激活神经元的输出层函数之一。在 Word2vec 中,我们可以使用分层 Softmax 和负采样等选项。利用激活器,我们可以将线性函数转换为非线性函数,并利用这些函数实现复杂的机器学习算法。
什么是 Gensim?
金西姆 是一个开源主题建模和自然语言处理工具包,实现于 Python Gensim 工具包支持 Cython 和 Word2vec。用户可以通过导入 Word2vec 进行主题建模,从而发现文本正文中隐藏的结构。Gensim 不仅实现了 Word2vec,还实现了 Doc2vec 和 FastText。
本节重点介绍 Word2vec,因此我们将围绕当前主题展开讨论。
如何使用 Gensim 实现 Word2vec
到目前为止,我们已经讨论了 Word2vec 是什么、它的不同架构、为什么从词袋模型转向 Word2vec、Word2vec 与 NLTK 以及实时代码和激活函数之间的关系。
以下是使用 Gensim 实现 Word2vec 的详细步骤:
步骤1)数据收集
实现任何机器学习模型或自然语言处理的第一步都是数据收集。
请观察数据来构建智能聊天机器人,如下面的 Gensim Word2vec 示例所示。
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
以下是我们从数据中得出的结论:
- 这些数据包含三部分:标签、模式和回复。标签代表意图(讨论的主题是什么)。
- 数据为 JSON 格式。
- 模式是指用户会向机器人提出的问题。
- 回复是指聊天机器人针对相应问题/模式提供的答案。
步骤2)数据预处理
处理原始数据非常重要。如果将清理过的数据输入到机器中,那么模型将做出更准确的反应,并更有效地学习数据。
此步骤包括移除停用词、词干提取、去除不必要的词语等。在继续操作之前,请务必加载数据并将其转换为数据框。请参阅以下代码。
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
的解释 Code:
- 由于数据为JSON格式,因此导入的是JSON数据。
- 文件存储在变量中。
- 文件已打开并加载到数据变量中。
数据已导入,现在需要将数据转换为数据框。请参考以下代码了解下一步操作。
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
的解释 Code:
1. 使用上面导入的 pandas 将数据转换为数据框。
2. 它将列模式中的列表转换为字符串。
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code 说明:
1. 使用 nltk 工具包中的停用词模块导入英语停用词。
2. 使用 for 循环和 lambda 函数将文本中的所有单词转换为小写。 拉姆达函数 是一个匿名函数。
3. 检查数据框中所有文本行的字符串标点符号,并筛选掉这些行。
4. 使用正则表达式删除数字或点号等字符。
5. Digits 从文本中删除。
6. 在此阶段,停用词被删除。
7. 现在对词语进行过滤,并使用词形还原法去除同一词语的不同形式。至此,数据预处理完成。
输出:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
步骤3)使用Word2vec构建神经网络
现在是时候使用 Gensim Word2vec 模块构建模型了。我们需要从 Gensim 导入 Word2vec 模块。导入完成后,我们将构建模型,并在最后阶段使用实时数据验证模型。
from gensim.models import Word2Vec
现在我们可以成功地使用 Word2Vec 构建模型了。请参考下一行代码,了解如何使用 Word2Vec 创建模型。模型接收的文本以列表的形式提供,因此我们将使用以下代码将数据框中的文本转换为列表。
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
的解释 Code:
1. 创建了更大的列表,并将内部列表追加到其中。这是提供给 Word2Vec 模型的数据格式。
2. 实现一个循环,并遍历数据框中 patterns 列的每个条目。
3. 列模式的每个元素都被拆分并存储在内部列表 li 中。
4. 将内部列表与外部列表合并。
5. 此列表提供给 Word2Vec 模型。让我们来了解一下这里提供的一些参数。
最小计数: 它会忽略所有总频率低于此值的词语。
规格: 它告诉了词向量的维数。
工人: 这些是用于训练模型的线程。
还有其他一些选择,下面将解释其中一些重要的选择。
窗口: 句子中当前单词和预测单词之间的最大距离。
新加坡: 这是一个训练算法:1 代表 skip-gram 模型,0 代表连续词袋模型。我们已在前面详细讨论过这些内容。
HS: 如果该值为 1,则表示我们使用分层 softmax 进行训练;如果该值为 0,则表示使用负采样。
Α: 初始学习率。
让我们在下面显示最终的代码:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
步骤4)模型保存
模型可以保存为二进制文件(bin)或模型文件。二进制文件是二进制格式。请参考以下代码保存模型。
model.save("word2vec.model") model.save("model.bin")
上面代码的解释
1. 模型以 .model 文件的形式保存。
2. 模型以 .bin 文件的形式保存。
我们将使用此模型进行实时测试,例如相似词、不相似词和最常用词。
步骤5)加载模型并进行实时测试
使用以下代码加载模型:
model = Word2Vec.load('model.bin')
如果要打印其中的词汇表,可以使用以下命令:
vocab = list(model.wv.vocab)
请看结果:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
步骤 6)检查最相似的单词
让我们实际地实施这些事情:
similar_words = model.most_similar('thanks') print(similar_words)
请看结果:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
步骤 7) 与提供的单词不匹配
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
我们已经提供了文字 再见,谢谢光临。这段代码会打印出这些单词中最不相似的单词。让我们运行这段代码,看看结果如何。
上述代码执行后的结果:
Thanks
步骤 8)查找两个单词之间的相似度
这部分结果以两个词相似度的概率形式呈现。请参考以下代码了解如何执行此部分。
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
上述代码的运行结果如下:
0.13706
您还可以通过执行以下代码查找更相似的词语:
similar = model.similar_by_word('kind') print(similar)
上述代码的输出结果:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]