NLTK Tokenize:带有示例的单词和句子标记器
⚡ 智能摘要
NLTK Tokenize 将大段文本分割成称为词元 (token) 的小单元,这是自然语言处理的基础步骤。该工具包提供了 word_tokenize 用于将句子拆分成单词,以及 sent_tokenize 用于将文本拆分成单个句子。

什么是令牌化?
符号化 是将大量文本划分为称为标记的较小部分的过程。这些标记对于查找模式非常有用,并且被视为词干提取和词形还原的基础步骤。标记化还有助于用非敏感数据元素替换敏感数据元素。
自然语言处理用于构建文本分类等应用程序, 智能聊天机器人、情感分析、语言翻译等。理解文本中的模式对于实现上述目的至关重要。
暂时不要担心词干提取和词形还原,而是将它们视为使用 NLP(自然语言处理)进行文本数据清理的步骤。我们将在本教程的后面讨论词干提取和词形还原。诸如 文本分类或垃圾邮件过滤 利用 NLP 和 Keras 等深度学习库 Tensorflow.
自然语言工具包中有非常重要的模块NLTK 令牌化 句子还包括子模块
- 单词标记
- 句子标记化
单词标记
我们使用的方法 word_tokenize() 将句子拆分成单词。单词标记化的输出可以转换为数据框,以便在机器学习应用中更好地理解文本。它还可以作为进一步的文本清理步骤的输入,例如标点符号删除、数字字符删除或词干提取。机器学习模型需要数字数据进行训练并做出预测。单词标记化成为文本(字符串)到数字数据转换的关键部分。请阅读 词袋或 CountVectorizer。请参考下面的单词 tokenize NLTK 示例以更好地理解该理论。
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
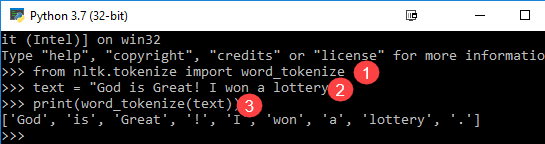
Code 说明
- word_tokenize 模块从 NLTK 库导入。
- 变量“text”用两个句子初始化。
- 文本变量传入 word_tokenize 模块并打印结果。该模块用标点符号拆分每个单词,您可以在输出中看到这些标点符号。
句子标记化
上述可用的子模块是 sent_tokenize。你脑海中一个显而易见的问题是 为什么当我们可以选择单词标记时,还需要句子标记。假设您需要计算每个句子的平均单词数,您将如何计算?为了完成这样的任务,您需要 NLTK 句子标记器和 NLTK 单词标记器来计算比率。这种输出是机器训练的重要特征,因为答案将是数字。
查看下面的 NLTK 标记器示例,了解句子标记化与单词标记化的区别。
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
我们有 12 的话和 两句话 对于相同的输入。
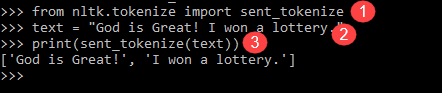
程序说明
- 与上一个程序类似,在一行中导入了 sent_tokenize 模块。
- 我们取了同一句话。NLTK 模块中的进一步句子标记器解析了该句子并显示输出。很明显,这个函数分解了每个句子。
上述单词标记器 Python 例子是理解单词和句子标记机制的良好基础。