使用 Py 构建 Seq2seq(序列到序列)模型Torch

什么是NLP?
自然语言处理(NLP)是人工智能的一个热门分支,它帮助计算机理解、处理或回应人类的自然语言。NLP是人工智能背后的核心引擎。 Google Translate 这有助于我们理解其他语言。
什么是 Seq2Seq?
序列2 是一种基于编码器-解码器的机器翻译和语言处理方法,它将序列的输入映射到具有标签和注意值的序列的输出。其思想是使用 2 个 RNN,它们将与一个特殊标记一起工作,并尝试根据前一个序列预测下一个状态序列。
如何根据前一个序列预测下一个序列
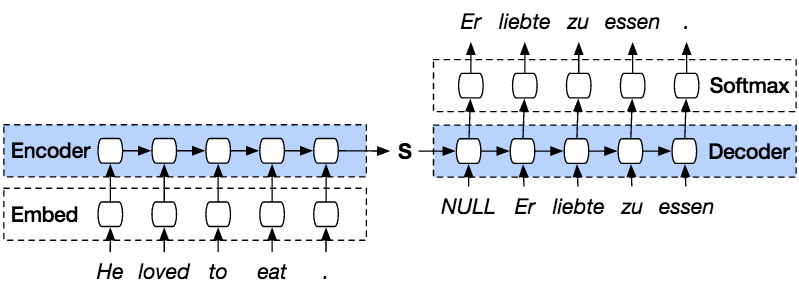
以下是使用 Py 从先前的序列预测下一个序列的步骤。TorCH。
步骤 1)加载数据
对于我们的数据集,你将使用来自 制表符分隔的双语句子对。这里我将使用英语到印尼语的数据集。你可以选择任何你喜欢的,但记得在代码中更改文件名和目录。
from __future__ import unicode_literals, print_function, division import torch import torch.nn as nn import torch.optim as optim import torch.nn.functional as F import numpy as np import pandas as pd import os import re import random device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
步骤2)数据准备
您不能直接使用数据集。您需要将句子拆分成单词,并将其转换为独热向量。每个单词都会在 Lang 类中被唯一索引,从而创建一个字典。Lang 类会存储每个句子,并使用 addSentence 函数逐词拆分句子。然后,通过索引每个未知单词来创建字典,以用于序列到序列模型。
SOS_token = 0 EOS_token = 1 MAX_LENGTH = 20 #initialize Lang Class class Lang: def __init__(self): #initialize containers to hold the words and corresponding index self.word2index = {} self.word2count = {} self.index2word = {0: "SOS", 1: "EOS"} self.n_words = 2 # Count SOS and EOS #split a sentence into words and add it to the container def addSentence(self, sentence): for word in sentence.split(' '): self.addWord(word) #If the word is not in the container, the word will be added to it, else, update the word counter def addWord(self, word): if word not in self.word2index: self.word2index[word] = self.n_words self.word2count[word] = 1 self.index2word[self.n_words] = word self.n_words += 1 else: self.word2count[word] += 1
Lang 类用于帮助我们创建词典。对于每种语言,每个句子都会被拆分成单词,然后添加到容器中。每个容器会将单词存储在相应的索引位置,统计单词出现次数,并将单词的索引添加到容器中,以便我们能够通过索引查找单词或根据索引查找单词。
因为我们的数据是用 TAB 分隔的,所以你需要使用 大熊猫 Pandas 作为我们的数据加载器。它会将数据读取为 DataFrame,并将其拆分为源句子和目标句子。对于每个句子,你需要将其转换为小写,移除所有非字符,将 Unicode 转换为 ASCII,并将句子拆分为包含每个单词的部分。
#Normalize every sentence def normalize_sentence(df, lang): sentence = df[lang].str.lower() sentence = sentence.str.replace('[^A-Za-z\s]+', '') sentence = sentence.str.normalize('NFD') sentence = sentence.str.encode('ascii', errors='ignore').str.decode('utf-8') return sentence def read_sentence(df, lang1, lang2): sentence1 = normalize_sentence(df, lang1) sentence2 = normalize_sentence(df, lang2) return sentence1, sentence2 def read_file(loc, lang1, lang2): df = pd.read_csv(loc, delimiter='\t', header=None, names=[lang1, lang2]) return df def process_data(lang1,lang2): df = read_file('text/%s-%s.txt' % (lang1, lang2), lang1, lang2) print("Read %s sentence pairs" % len(df)) sentence1, sentence2 = read_sentence(df, lang1, lang2) source = Lang() target = Lang() pairs = [] for i in range(len(df)): if len(sentence1[i].split(' ')) < MAX_LENGTH and len(sentence2[i].split(' ')) < MAX_LENGTH: full = [sentence1[i], sentence2[i]] source.addSentence(sentence1[i]) target.addSentence(sentence2[i]) pairs.append(full) return source, target, pairs
另一个你会用到的实用功能是将键值对转换为张量。这非常重要,因为我们的网络只读取张量类型的数据。此外,它还很重要,因为在这个部分,每个句子的末尾都会有一个标记,用来告诉网络输入已经结束。对于句子中的每个单词,网络都会从字典中获取对应单词的索引,并在句子末尾添加一个标记。
def indexesFromSentence(lang, sentence): return [lang.word2index[word] for word in sentence.split(' ')] def tensorFromSentence(lang, sentence): indexes = indexesFromSentence(lang, sentence) indexes.append(EOS_token) return torch.tensor(indexes, dtype=torch.long, device=device).view(-1, 1) def tensorsFromPair(input_lang, output_lang, pair): input_tensor = tensorFromSentence(input_lang, pair[0]) target_tensor = tensorFromSentence(output_lang, pair[1]) return (input_tensor, target_tensor)
Seq2Seq 模型

PyTorch Seq2seq 模型是一种使用 Py 的模型。Tor模型之上是编码器和解码器。编码器将句子逐词编码到词汇表或已知词索引中,解码器则按顺序解码输入,预测编码后的输出,并尽可能将上一个输入作为下一个输入。通过这种方法,还可以预测下一个输入以生成句子。每个句子都会被分配一个标记来标记序列的结束。在预测结束时,也会有一个标记来标记输出的结束。因此,编码器会将状态传递给解码器以预测输出。

编码器会按顺序逐词对输入句子进行编码,并在句末添加一个标记来表示句子结束。编码器由嵌入层和门控循环单元(GRU)层组成。嵌入层是一个查找表,用于存储输入词在固定大小的字典中的嵌入向量。该查找表将被传递给GRU层。GRU层是一个多层门控循环单元。 RNN 这将计算序列输入。此层将从前一个计算隐藏状态,并更新重置、更新和新门。

解码器将编码器的输出解码为输入。它会尝试预测下一个输出,并在可能的情况下将其用作下一个输入。解码器由嵌入层、GRU 层和线性层组成。嵌入层会为输出创建一个查找表,并将其传递给 GRU 层以计算预测的输出状态。之后,线性层将帮助计算激活函数,以确定预测输出的真实值。
class Encoder(nn.Module): def __init__(self, input_dim, hidden_dim, embbed_dim, num_layers): super(Encoder, self).__init__() #set the encoder input dimesion , embbed dimesion, hidden dimesion, and number of layers self.input_dim = input_dim self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.num_layers = num_layers #initialize the embedding layer with input and embbed dimention self.embedding = nn.Embedding(input_dim, self.embbed_dim) #intialize the GRU to take the input dimetion of embbed, and output dimention of hidden and #set the number of gru layers self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) def forward(self, src): embedded = self.embedding(src).view(1,1,-1) outputs, hidden = self.gru(embedded) return outputs, hidden class Decoder(nn.Module): def __init__(self, output_dim, hidden_dim, embbed_dim, num_layers): super(Decoder, self).__init__() #set the encoder output dimension, embed dimension, hidden dimension, and number of layers self.embbed_dim = embbed_dim self.hidden_dim = hidden_dim self.output_dim = output_dim self.num_layers = num_layers # initialize every layer with the appropriate dimension. For the decoder layer, it will consist of an embedding, GRU, a Linear layer and a Log softmax activation function. self.embedding = nn.Embedding(output_dim, self.embbed_dim) self.gru = nn.GRU(self.embbed_dim, self.hidden_dim, num_layers=self.num_layers) self.out = nn.Linear(self.hidden_dim, output_dim) self.softmax = nn.LogSoftmax(dim=1) def forward(self, input, hidden): # reshape the input to (1, batch_size) input = input.view(1, -1) embedded = F.relu(self.embedding(input)) output, hidden = self.gru(embedded, hidden) prediction = self.softmax(self.out(output[0])) return prediction, hidden class Seq2Seq(nn.Module): def __init__(self, encoder, decoder, device, MAX_LENGTH=MAX_LENGTH): super().__init__() #initialize the encoder and decoder self.encoder = encoder self.decoder = decoder self.device = device def forward(self, source, target, teacher_forcing_ratio=0.5): input_length = source.size(0) #get the input length (number of words in sentence) batch_size = target.shape[1] target_length = target.shape[0] vocab_size = self.decoder.output_dim #initialize a variable to hold the predicted outputs outputs = torch.zeros(target_length, batch_size, vocab_size).to(self.device) #encode every word in a sentence for i in range(input_length): encoder_output, encoder_hidden = self.encoder(source[i]) #use the encoder's hidden layer as the decoder hidden decoder_hidden = encoder_hidden.to(device) #add a token before the first predicted word decoder_input = torch.tensor([SOS_token], device=device) # SOS #topk is used to get the top K value over a list #predict the output word from the current target word. If we enable the teaching force, then the next decoder input is the next word, else, use the decoder output highest value. for t in range(target_length): decoder_output, decoder_hidden = self.decoder(decoder_input, decoder_hidden) outputs[t] = decoder_output teacher_force = random.random() < teacher_forcing_ratio topv, topi = decoder_output.topk(1) input = (target[t] if teacher_force else topi) if(teacher_force == False and input.item() == EOS_token): break return outputs
步骤3)训练模型
Seq2seq 模型的训练过程首先将每对句子根据其语言索引转换为张量。我们的序列到序列模型将使用随机梯度下降 (SGD) 作为优化器,并使用 NLLLoss 函数计算损失。训练过程从将句子对输入模型开始,以预测正确的输出。在每个步骤中,模型的输出将与真实词进行比较,以计算损失并更新参数。由于您将使用 75000 次迭代,因此我们的序列到序列模型将从数据集中生成 75000 个随机句子对。
teacher_forcing_ratio = 0.5 def clacModel(model, input_tensor, target_tensor, model_optimizer, criterion): model_optimizer.zero_grad() input_length = input_tensor.size(0) loss = 0 epoch_loss = 0 # print(input_tensor.shape) output = model(input_tensor, target_tensor) num_iter = output.size(0) print(num_iter) #calculate the loss from a predicted sentence with the expected result for ot in range(num_iter): loss += criterion(output[ot], target_tensor[ot]) loss.backward() model_optimizer.step() epoch_loss = loss.item() / num_iter return epoch_loss def trainModel(model, source, target, pairs, num_iteration=20000): model.train() optimizer = optim.SGD(model.parameters(), lr=0.01) criterion = nn.NLLLoss() total_loss_iterations = 0 training_pairs = [tensorsFromPair(source, target, random.choice(pairs)) for i in range(num_iteration)] for iter in range(1, num_iteration+1): training_pair = training_pairs[iter - 1] input_tensor = training_pair[0] target_tensor = training_pair[1] loss = clacModel(model, input_tensor, target_tensor, optimizer, criterion) total_loss_iterations += loss if iter % 5000 == 0: avarage_loss= total_loss_iterations / 5000 total_loss_iterations = 0 print('%d %.4f' % (iter, avarage_loss)) torch.save(model.state_dict(), 'mytraining.pt') return model
步骤4)测试模型
Seq2seq Py 的评估过程Tor步骤一是检查模型输出。每对序列到序列的模型都会被输入到模型中,并生成预测词。之后,你需要查看每个输出中的最大值,找到正确的索引。最后,你需要将结果与模型预测结果进行比较,以验证模型预测与真实句子的一致性。
def evaluate(model, input_lang, output_lang, sentences, max_length=MAX_LENGTH): with torch.no_grad(): input_tensor = tensorFromSentence(input_lang, sentences[0]) output_tensor = tensorFromSentence(output_lang, sentences[1]) decoded_words = [] output = model(input_tensor, output_tensor) # print(output_tensor) for ot in range(output.size(0)): topv, topi = output[ot].topk(1) # print(topi) if topi[0].item() == EOS_token: decoded_words.append('' ) break else: decoded_words.append(output_lang.index2word[topi[0].item()]) return decoded_words def evaluateRandomly(model, source, target, pairs, n=10): for i in range(n): pair = random.choice(pairs) print('source {}'.format(pair[0])) print('target {}'.format(pair[1])) output_words = evaluate(model, source, target, pair) output_sentence = ' '.join(output_words) print('predicted {}'.format(output_sentence))
现在,让我们开始使用 Seq to Seq 进行训练,迭代次数为 75000,RNN 层数为 1,隐藏层大小为 512。
lang1 = 'eng' lang2 = 'ind' source, target, pairs = process_data(lang1, lang2) randomize = random.choice(pairs) print('random sentence {}'.format(randomize)) #print number of words input_size = source.n_words output_size = target.n_words print('Input : {} Output : {}'.format(input_size, output_size)) embed_size = 256 hidden_size = 512 num_layers = 1 num_iteration = 100000 #create encoder-decoder model encoder = Encoder(input_size, hidden_size, embed_size, num_layers) decoder = Decoder(output_size, hidden_size, embed_size, num_layers) model = Seq2Seq(encoder, decoder, device).to(device) #print model print(encoder) print(decoder) model = trainModel(model, source, target, pairs, num_iteration) evaluateRandomly(model, source, target, pairs)
如你所见,我们预测的句子匹配得不是很好,所以为了获得更高的准确性,你需要用更多的数据进行训练,并尝试使用序列到序列学习添加更多的迭代和层数。
random sentence ['tom is finishing his work', 'tom sedang menyelesaikan pekerjaannya'] Input : 3551 Output : 4253 Encoder( (embedding): Embedding(3551, 256) (gru): GRU(256, 512) ) Decoder( (embedding): Embedding(4253, 256) (gru): GRU(256, 512) (out): Linear(in_features=512, out_features=4253, bias=True) (softmax): LogSoftmax() ) 5000 4.0906 10000 3.9129 15000 3.8171 20000 3.8369 25000 3.8199 30000 3.7957 75000 3.7044