什么是 Hadoop? Archi结构、生态系统及组成部分

什么是 Hadoop?
Apache Hadoop 是一个开源软件框架,用于开发在分布式计算环境中执行的数据处理应用程序。
使用 Hadoop 构建的应用程序运行在分布于通用计算机集群上的大型数据集上。通用计算机价格低廉且广泛可用,主要用于以低成本获得更强大的计算能力。
与个人计算机系统本地文件系统中存储的数据类似,在Hadoop中,数据存储在一个名为Hadoop文件系统的分布式文件系统中。 Hadoop分布式文件系统该处理模型基于 “数据局部性” 该概念是指将计算逻辑发送到包含数据的集群节点(服务器)。这种计算逻辑实际上是用高级语言(例如编程语言)编写的程序的编译版本。 Java这样的程序会处理存储在……中的数据。 Hadoop HDFS.
你知道吗? 计算机集群由多个相互连接的处理单元(存储磁盘+处理器)组成,这些处理单元作为一个单一系统运行。
版本 3.5.0 于 2026 年 4 月 2 日发布,是当前的稳定版本;3.4 系列仍会收到维护更新。
Hadoop 生态系统和组件
下图显示了 Hadoop 生态系统中的各种组件,并按每个组件执行的任务进行分组——存储、处理以及围绕它们的查询、摄取和协调工具。

Apache Hadoop 由两个子项目组成 -
- Hadoop MapReduce: MapReduce 是一种计算模型和软件框架,用于编写在 Hadoop 上运行的应用程序。这些 MapReduce 程序能够在大型计算节点集群上并行处理大量数据。
- 高密度文件系统 (Hadoop分布式文件系统): HDFS 负责 Hadoop 应用程序的存储部分。MapReduce 应用程序使用来自 HDFS 的数据。HDFS 创建数据块的多个副本并将它们分布在集群中的计算节点上。这种分布可实现可靠且极其快速的计算。
当前版本还包含两个核心模块。 Hadoop纱线(Hadoop 2.x 版本新增)负责调度集群上的工作, Hadoop 通用 持有共享 Java 每个模块都依赖于库。YARN 让诸如 YARN 之类的引擎能够运行。 SparkTez 和 Flink 与 MapReduce 并行运行。
尽管Hadoop最广为人知的是其MapReduce及其分布式文件系统HDFS,但该术语也用于指代一系列相关的项目,这些项目都属于分布式计算和大规模数据处理的范畴。Apache的其他Hadoop相关项目包括: 蜂房HBase、Mahout Sqoop,Flume以及 ZooKeeper。
Hadoop的 Archi质地
Hadoop 采用主从架构进行数据存储和分布式数据处理。 映射简化 以及HDFS方法。下图将这些角色并列展示,存储层位于一侧,处理层位于另一侧。
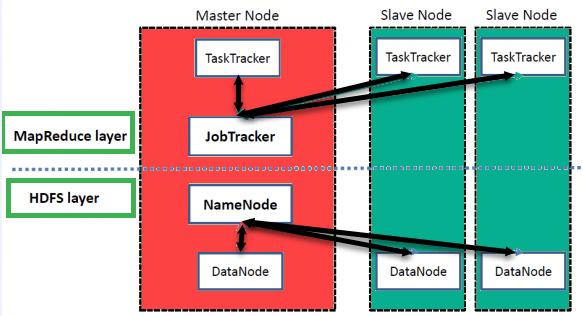
高级 Hadoop Archi质地
名称节点
NameNode 存储命名空间中使用的每个文件和目录的元数据,包括构成每个文件的块以及这些块的位置。
数据节点
DataNode 管理 HDFS 节点的状态,并允许您与它存储的数据块进行交互,通过定期的数据块报告和心跳向 NameNode 报告状态。
主节点
主节点允许您使用 Hadoop MapReduce 进行数据并行处理。
从节点
从节点是 Hadoop 集群中的附加机器,用于存储数据和运行复杂的计算。此外,每个从节点都会运行一个任务。Tracker 和 DataNode。这允许您将进程与 NameNode 和 Job 同步。Tracker 分别。
在 Hadoop 中,主系统或从系统可以设置在云端或本地。
命名说明: 工作TracKER 和 任务TracKER 属于第一代 MapReduce 运行时 (MRv1)。从 Hadoop 2.x 开始,YARN 将它们的职责拆分到集群范围内的各个层级。 资源管理器,以 节点管理器 每个工人,一个 ApplicationMaster 每个作业的 NameNode 和 DataNode 保持不变。
Hadoop的特性
适用于大数据分析
As 大数据 由于数据本质上往往是分布式和非结构化的,Hadoop 集群最适合用于大数据分析。因为流向计算节点的是处理逻辑(而非实际数据),所以消耗的网络带宽更少。这被称为…… 数据局部性概念这有助于提高基于 Hadoop 的应用程序的效率。
可扩展性
Hadoop集群可以通过添加额外的集群节点轻松扩展至任意规模,从而满足大数据增长的需求。此外,扩展无需修改应用程序逻辑。
容错
Hadoop 生态系统提供了一种将输入数据复制到其他集群节点的机制。这样,即使某个集群节点发生故障,数据处理仍然可以利用存储在其他集群节点上的数据继续进行。HDFS 默认会保留每个数据块的三个副本,这个值由……设定。 dfs复制 属性,并且 NameNode 会重新复制任何计数低于该值的块。
Hadoop中的网络拓扑
随着Hadoop集群规模的增长,网络拓扑结构(布局)会影响集群的性能。除了性能之外,还需要关注高可用性和故障处理。为了实现这些目标,Hadoop集群的构建会利用网络拓扑结构。
下图展示了这种架构的建模方式,从数据中心一直到每个机架内的节点。

通常,网络带宽是构建任何网络时需要考虑的重要因素。然而,由于带宽测量较为困难,Hadoop 将网络表示为一棵树,并将树中节点之间的距离(即跳数)视为构建 Hadoop 集群的重要因素。这里,两个节点之间的距离等于它们到最近共同祖先节点的距离之和。
Hadoop 集群由数据中心、机架和实际执行作业的节点组成。其中,数据中心由机架组成,机架又由节点组成。进程可用的网络带宽取决于进程的位置。也就是说,随着距离的增加,可用带宽会减少。
- 同一节点上的进程
- 同一机架上的不同节点
- 同一数据中心不同机架上的节点
- 不同数据中心的节点
机架感知使用同一棵树:HDFS 将副本放置在多个机架上,因此丢失一个机架交换机不会导致每个数据副本丢失。