堆排序算法(使用 Code in Python 和 C++)
⚡ 智能摘要
堆排序算法通过构建二叉堆并重复执行来对数组进行排序。trac将其根值放入已排序的部分。本资源解释了堆化、最大堆和最小堆、伪代码以及完整的 Python 和 C++ 实现并进行时间复杂度分析。

什么是堆排序算法?
堆排序是一种流行且速度较快的排序算法。它基于完全二叉树数据结构。我们将寻找最大元素并将其放在最大堆的顶部,也就是二叉树的父节点上。
假设给定一个数组, 数据 = [10,5, 7, 9, 4, 11, 45, 17, 60].
在数组中,如果第 i 个索引(i=0,1,2,3 …)是父节点,则 (2i+1) 和 (2i+2) 将是左子节点和右子节点。使用此数组创建完全二叉树将如下所示:

我们将从数组的开头到结尾执行堆化过程。最初,如果我们将数组转换为树,它将看起来像上面那样。我们可以看到它没有维护任何堆属性(最小堆或最大堆)。我们将通过对所有节点执行堆化过程来获得排序后的数组。
堆排序的应用
下面是堆排序算法的一些用法:
- 构建“优先队列”需要进行堆排序。因为堆排序在每次插入后都会保持元素的排序。
- 堆数据结构可以高效地找到 kth 给定数组中的最大元素。
- Linux 内核默认使用堆排序 排序算法 因为它具有 O(1) 空间复杂度。
使用示例创建堆排序
在这里,我们将从以下完全二叉树构造一个最大堆。
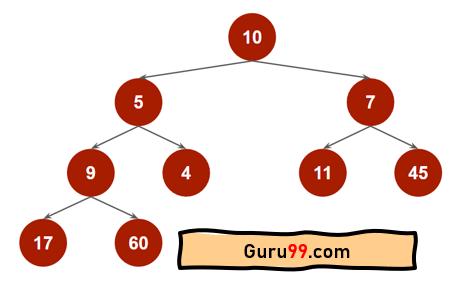
叶节点为 17、60、4、11 和 45。它们没有任何子节点。这就是它们成为叶节点的原因。因此,我们将从其父节点启动 heapify 方法。步骤如下:
步骤1) 选择最左边的子树。如果子节点更大,则将父节点与子节点交换。
此处父节点为 9。子节点为 17 和 60。由于 60 最大,因此将 60 和 9 进行交换以保持 最大堆.

步骤2) 现在,最左边的子树被堆化了。下一个父节点是 7。这个父节点有两个子节点,最大的是 45。因此,45 和 7 将被交换。


步骤3) 节点 60 和 4 有父节点 5。由于“5”小于子节点 60,因此将交换。


步骤4) 现在,节点 5 有子节点 17,9。这不保持最大堆属性。因此,5 将被替换为 17。

步骤5) 节点 10 将与 60 交换,然后与 17 交换。该过程如下所示。


步骤6) 到第 5 步为止,我们创建了最大堆。每个父节点都大于其子节点。根节点具有最大值 (60)。
注意: 为了创建排序数组,我们需要用它的后继节点替换最大值节点。
这个过程称为“extrac最大“。由于 60 是最大节点,我们将其位置固定为第 0 个索引,并创建不包含节点 60 的堆。


步骤7) 移除 60 后,下一个最大值是 45。我们将执行“Ex”过程。trac再次从节点 45 发出“t Max”指令。
这次我们将得到 45 并用其后继 17 替换根节点。
我们需要履行“Extract 最大值” 直到所有元素都排序完毕。
完成这些步骤后,直到我们完成trac取所有最大值,我们将得到以下数组。

什么是二叉堆?
二叉堆是一种完整的 二叉树 数据结构。在这种树结构中,父节点要么大于子节点,要么小于子节点。如果父节点较小,则堆称为“最小堆”,如果父节点较大,则堆称为“最大堆”。
这是最小堆和最大堆的示例。

在上图中,如果你注意到“最小堆”,父节点总是小于其子节点。在树的头部,我们可以找到最小值 10。
类似地,对于“最大堆”,父节点总是大于子节点。“最大堆”的最大元素位于头节点。
什么是“Heapify”?
“堆化”是堆的原理,保证了节点的位置。在堆化中,最大堆总是保持父子关系,即父节点会大于子节点。
例如,如果添加了一个新节点,我们需要重塑堆。但是,我们也可能需要更改或交换节点,或者重新排列数组。这个过程称为重塑。ping 堆被称为“堆化”。
下面是 heapify 如何工作的示例:

以下是 heapify 的步骤:
步骤1) 添加节点 65 作为节点 60 的右子节点。
步骤2) 检查新添加的节点是否大于父节点。
步骤3) 由于它大于父节点,我们将右子节点与其父节点交换。
如何构建堆
在构建堆或堆化树之前,我们需要知道如何存储它。由于堆是完全二叉树,因此最好使用 排列 保存堆的数据。
假设一个数组总共包含 n 个元素。如果第 i 个索引是父节点,则左节点将位于索引 (2i+1),并且正确的节点将位于索引 (2i+2)。我们假设数组索引从 0 开始。
使用这个,让我们将最大堆存储到类似下面的数组中:

heapify 算法保持了堆的特性,如果父节点没有极值(更小或者更大),那么会和最极端的子节点交换。
以下是最大堆堆化的步骤:
步骤1) 从叶节点开始。
步骤2) 找到父级和子级之间的最大值。
步骤3) 如果子节点的值大于父节点的值,则交换节点。
步骤4) 上升一级。
步骤5) 按照步骤 2,3,4、0、XNUMX,直到到达索引 XNUMX 或对整棵树进行排序。
以下是递归堆化(最大堆)的伪代码:
def heapify(): input→ array, size, i largest = i left = 2*i + 1 right = 2*i + 2 if left<n and array[largest ] < array[left]: largest = left if right<n and array[largest ] < array[right]: largest = right If largest not equals i: swap(array[i],array[largest]) heapify(array,n,largest)
昵称 Code 堆排序
以下是堆排序算法的伪代码:
Heapify(numbers as an array, n as integer, i as integer): largest = i left = 2i+1 right= 2i+2 if(left<=n) and (numbers[i]<numbers[left]) largest=left if(right<=n) and (numbers[i]<numbers[right]) largest=right if(largest != i) swap(numbers[i], numbers[largest]) Heapify(numbers,n,largest) HeapSort(numbers as an array): n= numbers.size() for i in range n/2 to 1 Heapify(numbers,n,i) for i in range n to 2 Swap numbers[i] with numbers[1] Heapify(numbers,i,0)
堆排序示例 Code in C++
#include <iostream> using namespace std; void display(int arr[], int n) { for (int i = 0; i < n; i++) { cout << arr[i] << "\t"; } cout << endl; } void heapify(int numbers[], int n, int i) { int largest = i; int left = 2 * i + 1; int right = 2 * i + 2; if (left < n && numbers[left] < numbers[largest]) { largest = left; } if (right < n && numbers[right] < numbers[largest]) { largest = right; } if (largest != i) { //uncomment the following line to see details in output //cout<<"Swapping "<< numbers[i]<< " and "<<numbers[largest]<<endl; swap(numbers[i], numbers[largest]); heapify(numbers, n, largest); } } void heapSort(int numbers[], int n) { for (int i = n/2 - 1; i >= 0; i--) { heapify(numbers, n, i); //uncomment the following line to see details in output //cout<<"Heapify:\t"; //display(numbers,n); } for (int i = n - 1; i >= 0; i--) { swap(numbers[0], numbers[i]); heapify(numbers, i, 0); } } int main() { int numbers[] = { 10,5, 7, 9, 4, 11, 45, 17, 60}; int size = sizeof(numbers) / sizeof(numbers[0]); cout<<"Initial Array:\t"; display(numbers,size); heapSort(numbers, size); cout<<"Sorted Array (descending order):\t"; display(numbers, size); }
输出:
Initial Array: 10 5 7 9 4 11 45 17 60 Sorted Array (descending order): 60 45 17 11 10 9 7 5 4
堆排序示例 Code in Python
def display(arr): for i in range(len(arr)): print(arr[i], end = "\t") print() def heapify(numbers, n, i): largest = i left = 2 * i + 1 right = 2 * i + 2 if left < n and numbers[left] < numbers[largest]: largest = left if right < n and numbers[right] < numbers[largest]: largest = right if largest != i: numbers[i], numbers[largest] = numbers[largest], numbers[i] heapify(numbers, n, largest) def heapSort(items, n): for i in range(n //2,-1,-1): heapify(items, n, i) for i in range(n - 1, -1, -1): items[0], items[i] = items[i], items[0] heapify(items, i, 0) numbers = [10, 5, 7, 9, 4, 11, 45, 17, 60] print("Initial List:\t", end = "") display(numbers) print("After HeapSort:\t", end = "") heapSort(numbers, len(numbers)) display(numbers)
输出:
Initial List: 10 5 7 9 4 11 45 17 60 After HeapSort: 60 45 17 11 10 9 7 5 4
堆排序的时间和空间复杂度分析
我们可以分析堆排序的时间复杂度和空间复杂度。对于时间复杂度,我们有以下情况:
- 最佳案例
- 平均情况
- 最糟糕的情况
堆是在完全二叉树上实现的。因此,二叉树的最底层将有最大数量的节点。如果最底层有 n 个节点,则上一层将有 n/2 个节点。

在此示例中,第 3 级有 2 个项目,第 1 级有 XNUMX 个项目,第 XNUMX 级有 XNUMX 个项目。如果总共有 n 个项目,则高度或总级别将为 历史记录2(n)。 因此,插入一个元素最多需要 Log(n) 次迭代。
当我们想从堆中取出最大值时,我们只需取根节点。然后再次运行 heapify。每次 heapify 都会取 历史记录2(n)的 时间。例如trac达到最大值需要 O(1) 时间。
堆排序算法的最佳时间复杂度
当数组中的所有元素都已排序时,构建堆将花费 O(n) 时间。因为如果列表已排序,则插入一个项目将花费常数时间,即 O(1)。
因此,在最佳情况下,创建最大堆或最小堆需要 O(n) 的时间。
堆排序算法的平均时间复杂度
插入物品或trac达到最大值需要 O(log(n)) 时间。因此,堆排序算法的平均时间复杂度为 O(n log(n))。
堆排序算法的最坏情况时间复杂度
与平均情况类似,在最坏情况下,我们可能需要执行 n 次堆化。每次堆化将花费 O(log(n)) 时间。因此,最坏情况下的时间复杂度将是 O(n log(n))。
堆排序算法的空间复杂度
堆排序是一种就地设计的算法。这意味着执行任务不需要额外或临时的内存。如果我们查看实现,我们会注意到我们使用 swap () 来执行节点的交换。不需要其他列表或数组。因此,空间复杂度为 O(1)。