如何下载和安装 NLTK
⚡ 智能摘要
下载并安装 NLTK Windows通过安装,可在 Mac 或 Linux 系统上使用。 Python 首先,然后添加天然成分 Language Tool通过 pip 或 Anaconda 安装 kit 并下载语料库数据集。

在中安装 NLTK Windows
了解如何在系统上设置 NLTK Windows 从命令提示符运行。以下说明假设 Python 尚未安装,因此第一步是安装 Python.
安装 Python in Windows
步骤1) 打开链接 https://www.python.org/downloads/, 并选择最新信息 Windows 释放。
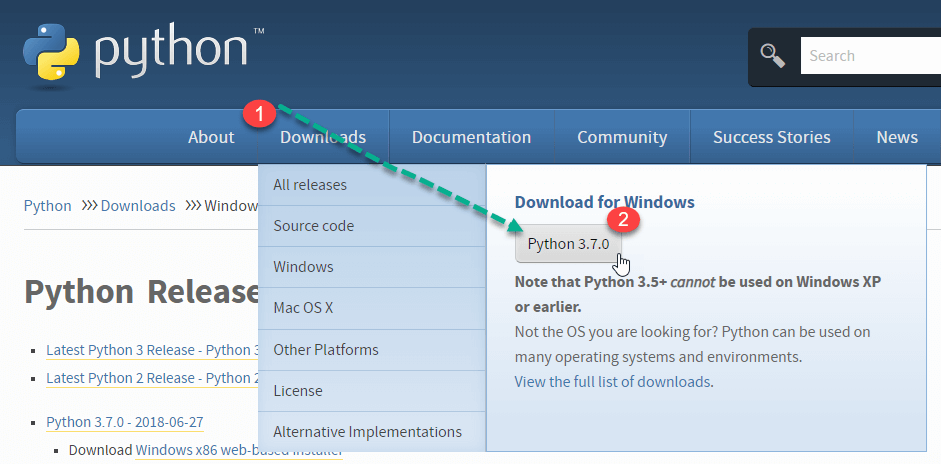
注意:如需旧版本,请访问“下载”选项卡查看所有版本。

步骤2) 点击下载的安装程序文件。

步骤3) 选择“自定义安装”。
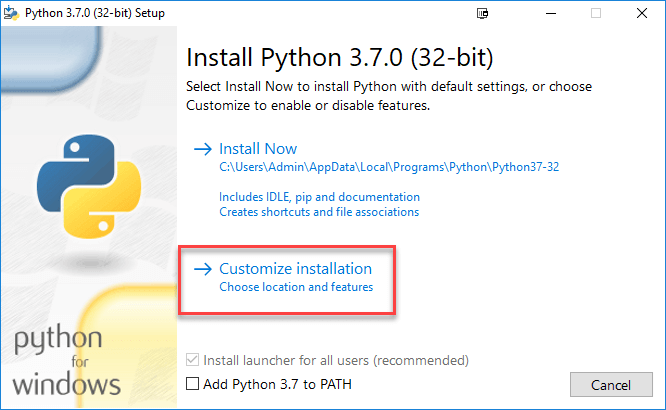
步骤4) 点击下一步。

步骤5) 在下一个屏幕上:
- 选择高级选项。
- 提供自定义安装位置。在本例中,为了方便访问,选择 C 盘上的一个文件夹。
- 点击“安装”。

步骤6) 安装完成后,点击“关闭”按钮。

步骤7) 复制脚本文件夹的路径。

步骤8) 在 Windows 命令提示符:
- 导航到 pip 文件夹所在的位置。
- 输入命令安装 NLTK:
pip3 install nltk
- 安装应该会顺利完成。

注意:对 Python 2,使用命令 pip2 install nltk.
步骤9) 来自 Windows 从开始菜单搜索并打开 Python 贝壳。

步骤10) 运行以下命令验证安装是否成功:
import nltk

如果没有出现错误,则安装完成。
在 Mac/Linux 中安装 NLTK
在 Mac 或 Linux 上安装 NLTK 需要 Python 软件包管理器 pip。如果 pip 尚未安装,请按照以下说明完成安装过程。
步骤1) 更新包索引ping 以下命令:
sudo apt update
步骤2) 安装 pip Python 3:
sudo apt install python3-pip
您也可以通过 easy_install 安装 pip:
sudo apt-get install python-setuptools python-dev build-essential
安装 easy_install 后,运行以下命令安装 pip:
sudo easy_install pip
步骤3) 使用以下命令安装 NLTK:
sudo pip install -U nltk sudo pip3 install -U nltk
通过 Anaconda 安装 NLTK
步骤1) 请访问以下链接安装 Anaconda https://www.anaconda.com/products/individual 并选择 Python 您需要的版本。

注意:请参阅本教程以了解详细步骤 安装 Anaconda.
步骤2) 在 Anaconda 提示符中:
- 输入命令:
conda install -c anaconda nltk
- Rev查看软件包升级、降级和安装信息,然后输入“是”。
- NLTK 已下载并安装。

NLTK 数据集
NLTK 模块附带许多数据集,使用前需要下载这些数据集。严格来说,每个数据集都称为一个数据块。 文集. 常见的例子包括 停用词, 古滕贝格, 框架网络_v15, 大型语法, 棕色和 字网.
如何下载 NLTK 的所有软件包
步骤1) 运行 Python 翻译员 in Windows 或Linux。
步骤2)
- 请输入以下命令:
import nltk nltk.download ()
- NLTK 下载器窗口打开。点击“下载”按钮获取数据集。此过程所需时间取决于您的网络连接速度。

注意: 您可以通过点击“文件”>“更改下载目录”来更改下载位置。

步骤3) 要测试已安装的数据,请使用以下代码:
>>> from nltk.corpus import brown >>>brown.words()
['富尔顿', '县', '大', '陪审团', '说', …]

运行 NLP 脚本
本节介绍自然语言处理 (NLP) 脚本如何在本地计算机上运行。选择合适的库取决于您的具体需求。请参阅官方列表。 自然语言处理库 其他替代方案包括 spaCy、gensim 和 TextBlob。
如何运行 NLTK 脚本
步骤1) 在您喜欢的代码编辑器中,复制代码并将文件另存为 NLTK示例:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)

Code 说明:
- 该程序的目标是从给定的文本中删除所有类型的标点符号。我们导入了“RegexpTokenizer”模块,该模块…… NLTK 它可以删除您选择的任何表达式、符号、字符或数值。
- 将正则表达式传递给“RegexpTokenizer”模块。
- 使用“tokenize”方法对文本进行分词,并将输出存储在“filterdText”变量中。
- 使用“print()”函数打印结果。
步骤2) 在命令提示符中:
- 找到你保存文件的位置。
- 运行该命令
python NLTKsample.py.

输出是:
['你好', 'Guru99', '你', '有', '建造', '一个', '非常', '好', '网站', '并且', '我', '喜欢', '访问', '你的', '网站']