Hướng dẫn cách tải xuống và cài đặt NLTK
⚡ Tóm tắt thông minh
Tải xuống và cài đặt NLTK trên Windows, Mac, hoặc Linux bằng cách cài đặt Python đầu tiên, sau đó thêm Natural Language ToolSử dụng bộ công cụ thông qua pip hoặc Anaconda và tải xuống các tập dữ liệu ngữ liệu.

Cài đặt NLTK trong Windows
Tìm hiểu cách thiết lập NLTK trên Windows từ dấu nhắc lệnh. Các hướng dẫn bên dưới giả định Python Ứng dụng chưa được cài đặt, vì vậy bước đầu tiên là cài đặt nó. Python.
Cài đặt Python in Windows
Bước 1) Mở liên kết https://www.python.org/downloads/, và chọn phiên bản mới nhất Windows phát hành.
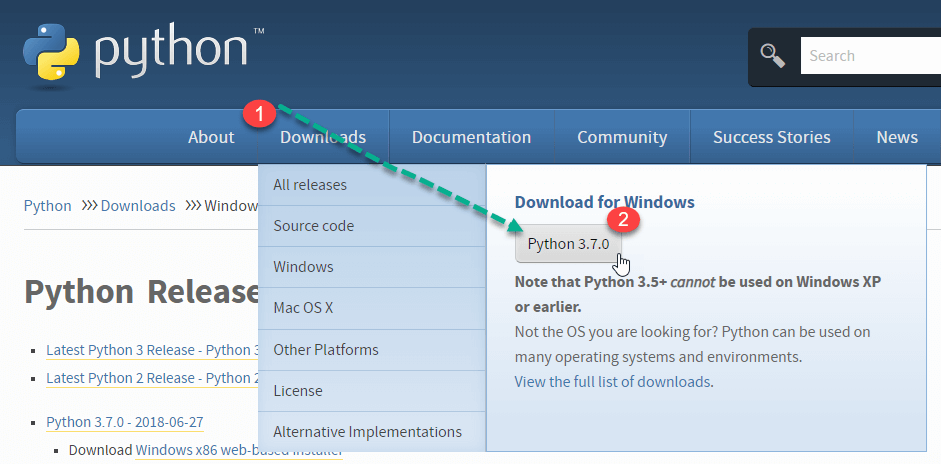
Lưu ýĐể xem phiên bản cũ hơn, hãy truy cập tab Tải xuống để xem tất cả các bản phát hành.

Bước 2) Nhấp vào tệp cài đặt đã tải xuống.

Bước 3) Chọn Tùy chỉnh cài đặt.
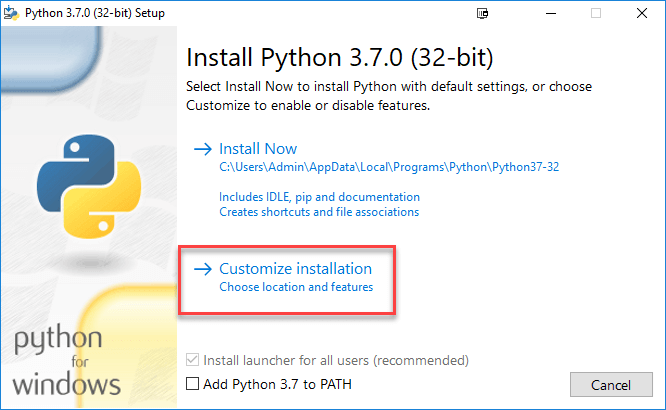
Bước 4) Bấm tiếp.

Bước 5) Trên màn hình tiếp theo:
- Chọn các tùy chọn nâng cao.
- Cung cấp vị trí cài đặt tùy chỉnh. Trong ví dụ này, một thư mục trên ổ C được chọn để dễ truy cập hơn.
- Nhấp vào Cài đặt.

Bước 6) Nhấp vào nút Đóng sau khi quá trình cài đặt hoàn tất.

Bước 7) Sao chép đường dẫn của thư mục Tập lệnh của bạn.

Bước 8) Trong tạp chí Windows dấu nhắc lệnh:
- Điều hướng đến vị trí của thư mục pip.
- Nhập lệnh để cài đặt NLTK:
pip3 install nltk
- Quá trình cài đặt sẽ hoàn tất thành công.

LƯU ÝCó mặt Python 2, sử dụng lệnh pip2 install nltk.
Bước 9) Từ Windows Menu Bắt đầu, tìm kiếm và mở Python Vỏ.

Bước 10) Hãy kiểm tra xem quá trình cài đặt có hoạt động hay không bằng cách chạy lệnh sau:
import nltk

Nếu không có lỗi nào xuất hiện, quá trình cài đặt đã hoàn tất.
Cài đặt NLTK trên Mac/Linux
Việc cài đặt NLTK trên Mac hoặc Linux yêu cầu... Python Trình quản lý gói pip. Nếu pip chưa được cài đặt, hãy làm theo hướng dẫn bên dưới để hoàn tất quá trình cài đặt.
Bước 1) Cập nhật chỉ mục gói bằng typing lệnh dưới đây:
sudo apt update
Bước 2) Cài đặt pip cho Python 3:
sudo apt install python3-pip
Bạn cũng có thể cài đặt pip thông qua easy_install:
sudo apt-get install python-setuptools python-dev build-essential
Sau khi cài đặt easy_install, hãy chạy lệnh dưới đây để cài đặt pip:
sudo easy_install pip
Bước 3) Sử dụng lệnh sau để cài đặt NLTK:
sudo pip install -U nltk sudo pip3 install -U nltk
Cài đặt NLTK qua Anaconda
Bước 1) Cài đặt Anaconda bằng cách truy cập https://www.anaconda.com/products/individual và chọn Python phiên bản bạn cần.

Lưu ý: Tham khảo hướng dẫn này để biết các bước chi tiết cài đặt Anaconda.
Bước 2) Trong cửa sổ nhắc lệnh Anaconda:
- Nhập lệnh:
conda install -c anaconda nltk
- RevXem thông tin nâng cấp, hạ cấp và cài đặt gói, sau đó chọn Có.
- NLTK đã được tải xuống và cài đặt.

Bộ dữ liệu NLTK
Mô-đun NLTK đi kèm với nhiều tập dữ liệu mà bạn cần tải xuống trước khi sử dụng. Về mặt kỹ thuật, mỗi tập dữ liệu được gọi là một tập dữ liệu. văn thể. Các ví dụ phổ biến bao gồm ngưng từ, Gutenberg, framenet_v15, lớn_ngữ pháp, nâuvà mạng từ.
Cách tải xuống tất cả các gói của NLTK
Bước 1) Chạy Python thông dịch viên in Windows hoặc Linux.
Bước 2)
- Nhập các lệnh:
import nltk nltk.download ()
- Cửa sổ NLTK Downloader sẽ mở ra. Nhấp vào nút Download để tải xuống bộ dữ liệu. Quá trình này mất thời gian tùy thuộc vào tốc độ kết nối internet của bạn.

LƯU Ý: Bạn có thể thay đổi vị trí tải xuống bằng cách nhấp vào Tệp > Thay đổi thư mục tải xuống.

Bước 3) Để kiểm tra dữ liệu đã cài đặt, hãy sử dụng đoạn mã sau:
>>> from nltk.corpus import brown >>>brown.words()
['The', 'Fulton', 'Quận', 'Grand', 'Ban giám khảo', 'đã nói', …]

Chạy tập lệnh NLP
Phần này giải thích cách một kịch bản NLP chạy trên máy tính cá nhân. Việc lựa chọn thư viện phù hợp phụ thuộc vào yêu cầu của bạn. Xem danh sách chính thức của thư viện NLP Đối với các giải pháp thay thế như spaCy, gensim và TextBlob.
Cách chạy tập lệnh NLTK
Bước 1) Trong trình soạn thảo mã yêu thích của bạn, sao chép mã và lưu tệp dưới dạng NLTKsample.py:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)

Code Giải thích:
- Mục tiêu của chương trình này là loại bỏ mọi loại dấu câu khỏi một văn bản cho trước. Chúng tôi đã nhập “RegexpTokenizer”, một mô-đun của NLTK Công cụ này loại bỏ bất kỳ biểu thức, ký hiệu, ký tự hoặc giá trị số nào bạn chọn.
- Một biểu thức chính quy được truyền đến mô-đun “RegexpTokenizer”.
- Văn bản được phân tách thành các từ bằng phương thức “tokenize”, và kết quả được lưu trữ trong biến “filterdText”.
- Kết quả được in ra bằng hàm “print()”.
Bước 2) Trong cửa sổ dòng lệnh:
- Điều hướng đến vị trí bạn đã lưu tệp.
- Chạy lệnh
python NLTKsample.py.

Đầu ra là:
['Xin chào', 'Guru99', 'Bạn', 'đã', 'xây dựng', 'một', 'trang web', 'rất', 'tốt', và', 'tôi', 'thích', 'ghé thăm', 'trang web', 'của bạn']