Вбудовування слів та Word2Vec з прикладом
⚡ Розумний підсумок
Word Embedding та Word2Vec перетворюють текст на щільні числові вектори, завдяки чому моделі машинного навчання розпізнають слова зі схожим значенням. У цьому ресурсі пояснюється методика, її архітектури CBOW та Skip-Gram, функції активації та повна реалізація Gensim для реальних застосувань.
Що таке вбудовування Word?
Вбудоване слово — це тип представлення слів, який дозволяє алгоритмам машинного навчання розуміти слова зі схожими значеннями. Це метод моделювання мови та навчання ознак для відображення слів у вектори дійсних чисел за допомогою нейронних мереж, ймовірнісних моделей або зменшення розмірності матриці спільної появи слів. Деякі моделі вбудовування слів — це Word2vec (Google), GloVe (Стенфорд) та fastText (Facebook).
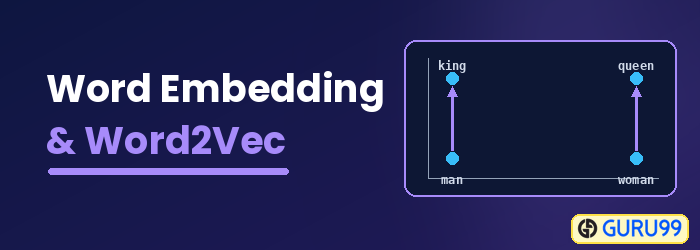
Вбудовування слів також називають розподіленою семантичною моделлю, розподілено представленою моделлю, семантичним векторним простором або моделлю векторного простору. Читаючи ці назви, ви зустрічаєте слово смисловий, що означає категоризацію подібних слів разом. Наприклад, фрукти, такі як яблуко, манго та банан, слід розміщувати близько один до одного, тоді як книги будуть розміщені далеко від цих слів. У ширшому сенсі, вбудовування слів створить вектор фруктів, який розміщено далеко від векторного представлення книг.
Де використовується Word Embedding?
Вбудовування слів допомагає у створенні ознак, кластеризації документів, класифікації тексту та завданнях обробки природної мови. Давайте перерахуємо ці застосування та обговоримо кожне з них.
- Обчисліть схожі слова: Вбудовування слів використовується для пропонування слів, схожих на слово, яке піддається моделі прогнозування. Поряд з цим, вона також пропонує несхожі слова, а також найпоширеніші слова.
- Створіть групу споріднених слів: Використовується для семантичної групиping, який групує речі зі схожими характеристиками та відсуває несхожі елементи подалі.
- Функція класифікації тексту: Текст відображається в масиви векторів, які подаються до моделі як для навчання, так і для прогнозування. Текстові моделі класифікаторів не можна навчати на рядках, тому це перетворює текст у форму, придатну для машинного навчання. Його функції семантичного формування додатково допомагають у класифікації на основі тексту.
- Кластеризація документів: Це ще один додаток, де широко використовуються Word Embedding та Word2vec.
- Обробка природної мови: Існує багато застосувань, де вбудовування слів є корисним і переважає над функціональними можливостями.tracфази розв’язання, такі як позначка частин мови, аналіз настрою та синтаксичний аналіз.
Тепер, коли ви розумієте, де застосовується вбудовування слів, давайте розглянемо найпопулярнішу модель, яка використовується для створення цих вбудовувань.
Що таке Word2vec?
Word2vec – це техніка або модель, яка створює вбудовування слів для кращого представлення слів. Це метод обробки природної мови, який фіксує велику кількість точних синтаксичних та семантичних зв'язків між словами. Це поверхнева двошарова нейронна мережа, яка може виявляти синонімічні слова та пропонувати додаткові слова для часткових речень після навчання.
Перш ніж продовжити, будь ласка, розгляньте різницю між поверхневою та глибокою нейронною мережею, як показано на діаграмі-прикладі вбудовування Word нижче:
Поверхнева нейронна мережа складається лише з одного прихованого шару між входом і виходом, тоді як глибока нейронна мережа містить кілька прихованих шарів між входом і виходом. Вхід обробляється вузлами, тоді як прихований шар, як і вихідний шар, містить нейрони.
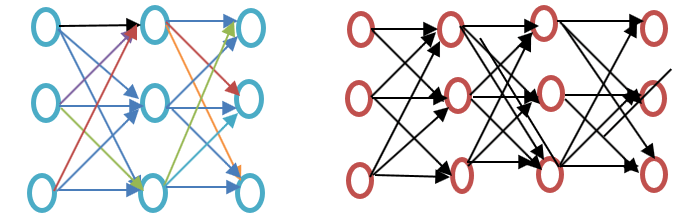
Word2vec — це двошарова мережа, де є вхід, один прихований шар і вихід.
Word2vec був розроблений групою дослідників на чолі з Томашем Міколовим у GoogleWord2vec кращий та ефективніший, ніж модель латентного семантичного аналізу.
Чому Word2vec?
Word2vec представляє слова у векторному просторовому представленні. Слова представлені у вигляді векторів, а розміщення здійснюється таким чином, що слова зі схожим значенням з'являються разом, а різні слова розташовані далеко одне від одного. Це також називається семантичним зв'язком. Нейронні мережі не розуміють текст; натомість вони розуміють лише числа. Вбудовування слів (Word Embedding) надає спосіб перетворення тексту в числовий вектор.
Word2vec реконструює лінгвістичний контекст слів. Перш ніж продовжити, давайте зрозуміємо, що таке лінгвістичний контекст. У загальному випадку, коли ми говоримо або пишемо для спілкування, інші люди намагаються з'ясувати мету речення. Наприклад, «Яка температура в Індії?» Тут контекст полягає в тому, що користувач хоче знати «температуру Індії». Коротше кажучи, головною метою речення є контекст. Слова або речення, що оточують розмовну чи письмову мову, допомагають визначити значення контексту. Word2vec вивчає векторне представлення слів через ці контексти.
Що робить Word2vec?
Перед вставленням Word
Важливо знати, який підхід використовувався до вбудовування слів і які його недоліки, а потім ми побачимо, як ці недоліки долаються за допомогою вбудовування слів за допомогою підходу Word2vec. Нарешті, ми перейдемо до того, як працює Word2vec, оскільки важливо зрозуміти його принцип роботи.
Підхід до латентного семантичного аналізу
Це підхід, який використовувався до появи вбудовування слів. Він використовував концепцію «мішка слів», де слова представлені у вигляді закодованих векторів. Це розріджене векторне представлення, де розмірність дорівнює розміру словника. Якщо слово зустрічається у словнику, воно враховується; інакше – ні. Щоб дізнатися більше, перегляньте програму нижче.
Приклад Word2vec

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
вихід:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Пояснення
- CountVectorizer – це модуль, який використовується для зберігання словникового запасу на основі підбору слів у ньому. Він імпортований зі sklearn.
- Створіть об’єкт за допомогою класу CountVectorizer.
- Запишіть дані у список, який потрібно підібрати до CountVectorizer.
- Дані вміщуються в об’єкт, створений з класу CountVectorizer.
- Застосуйте підхід «мішка слів» для підрахунку слів у даних за допомогою словника. Якщо слово або лексема недоступні у словнику, то така позиція індексу встановлюється на нуль.
- Змінна в рядку 5, яка є x, перетворюється на масив (метод, доступний для x). Це надає кількість кожної лексеми в реченні або списку, наведеному в рядку 3.
- Це показує ознаки, які є частиною словника, коли він підбирається з використанням даних у рядку 4.
У латентно-семантичному підході рядок представляє унікальні слова, тоді як стовпець – кількість разів, коли це слово з'являється в документі. Це представлення слів у формі матриці документа. Для підрахунку частоти слів у документі використовується метод TF-IDF (частота термінів – обернена частота документа), який дорівнює частоті терміна в документі, поділеній на частоту терміна в усьому корпусі.
Недолік методу «Мішок слів».
- Він ігнорує порядок слів; наприклад, це погано = погано це.
- Він ігнорує контекст слів. Припустимо, ми напишемо речення «Він любив книги. Освіту найкраще знайти в книгах». Це створить два вектори: один для «Він любив книги» та інший для «Освіту найкраще знайти в книгах». Це розглядатиме їх обидва як ортогональні, що робить їх незалежними, але насправді вони пов'язані один з одним.
Щоб подолати ці обмеження, було розроблено вбудовування слів, і Word2vec є одним із підходів, що використовуються для його реалізації.
Як працює Word2vec?
Word2vec вивчає слово, передбачаючи його контекст. Наприклад, візьмемо слово «Він любить Футбол».
Ми хочемо обчислити Word2vec для слова: любить.
Припустимо:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Слово любить переміщується по кожному слову в корпусі. Кодуються як синтаксичні, так і семантичні зв'язки між словами. Це допомагає знаходити подібні та аналогічні слова.
Усі випадкові ознаки слова любить обчислюються. Ці ознаки змінюються або оновлюються відносно сусідніх або контекстних слів за допомогою Зворотне поширення метод.
Інший спосіб навчання полягає в тому, що якщо контексти двох слів схожі або два слова мають схожі ознаки, то такі слова є пов'язаними.
Word2vec Archiтектура
Word2vec використовує дві архітектури:
- Безперервний мішок слів (CBOW)
- Пропустити грам
Перш ніж продовжувати, обговоримо, чому ці архітектури або моделі важливі з точки зору представлення слів. Навчання представлення слів по суті відбувається без учителя, але для навчання моделі потрібні цілі/мітки. Skip-gram та CBOW перетворюють представлення без учителя у контрольовану форму для навчання моделі.
У CBOW поточне слово передбачається за допомогою вікна навколишніх контекстних вікон. Наприклад, якщо wI-1, ЖI-2, Жi + 1, Жi + 2 задані слова або контекст, ця модель забезпечить wi.
Skip-Gram виконує протилежну дію до CBOW, що означає, що він передбачає задану послідовність або контекст зі слова. Ви можете навести приклад у зворотному порядку, щоб зрозуміти його. Якщо wi задано, це передбачить контекст, або wI-1, ЖI-2, Жi + 1, Жi + 2.
Word2vec надає можливість вибору між CBOW (Continuous Bag of Words - безперервний мішок слів) та skip-gram. Такі параметри надаються під час навчання моделі. Можна використовувати негативну вибірку або ієрархічний шар softmax.
Безперервний мішок слів
Давайте намалюємо просту діаграму-приклад Word2vec, щоб зрозуміти архітектуру безперервного мішка слів.

Обчислимо рівняння математично. Припустимо, що V — це розмір словника, а N — розмір прихованого шару. Вхід визначається як { xI-1, хI-2, хi + 1, хi + 2 }. Ми отримуємо вагову матрицю множенням V * N. Інша матриця отримується множенням вхідного вектора на вагову матрицю. Це також можна зрозуміти за допомогою наступного рівняння.
h = xitW
де xit та W – вхідний вектор та вагова матриця відповідно.
Щоб обчислити відповідність між контекстом і наступним словом, зверніться до наведеного нижче рівняння.
u = прогнозоване представлення * h
де передбачуване представлення отримано з моделі у вищенаведеному рівнянні.
Модель Skip-Gram
Підхід Skip-Gram використовується для прогнозування речення на основі введеного слова. Щоб краще зрозуміти його, намалюємо діаграму, показану в прикладі Word2vec нижче.

Можна розглядати це як протилежність моделі «Безперервний мішок слів», де вхідними даними є слово, а модель надає контекст або послідовність. Також можна зробити висновок, що ціль подається на вхід, а вихідний шар реплікується кілька разів, щоб вмістити вибрану кількість контекстних слів. Вектор помилок з усіх вихідних шарів підсумовується для коригування ваг за допомогою методу зворотного поширення.
Яку модель вибрати?
CBOW у кілька разів швидший за skip-gram та забезпечує кращу частоту для поширених слів, тоді як skip-gram потребує невеликої кількості навчальних даних та представляє навіть рідкісні слова чи фрази. У таблиці нижче наведено короткий огляд порівняння обох архітектур.
| Аспект | CBOW | Скіп-Грам |
|---|---|---|
| Прогнозування | Передбачає цільове слово з контексту | Передбачає контекст на основі цільового слова |
| Швидкість навчання | Швидше | Повільніше |
| Часті слова | Вища точність | Низька точність |
| Рідкісні слова | Слабше представництво | Сильніше представництво |
| Дані навчання | Потрібно більше даних | Працює з меншою кількістю даних |
Зв'язок між Word2vec і NLTK
НЛТК є Природним Language Toolkit. Він використовується для попередньої обробки тексту. Можна виконувати різні операції, такі як позначення частин мови, лематизація, визначення стемінгу, видалення стоп-слів та видалення рідкісних або найменш вживаних слів. Це допомагає в очищенні тексту, а також підготовці ознак з ефективних слів. З іншого боку, Word2vec використовується для семантичного (тіснопов'язані елементи разом) та синтаксичного (послідовність) зіставлення. За допомогою Word2vec можна знаходити схожі слова, несхожі слова, скорочувати розмірність та багато іншого. Ще однією важливою функцією Word2vec є перетворення багатовимірного представлення тексту в маловимірні вектори.
Де використовувати NLTK і Word2vec?
Якщо потрібно виконати деякі завдання загального призначення, як згадано вище, такі як токенізація, тегування POS та парсинг, слід використовувати NLTK, тоді як для прогнозування слів відповідно до певного контексту, тематичного моделювання або подібності документів слід використовувати Word2vec.
Зв'язок NLTK і Word2vec за допомогою коду
NLTK та Word2vec можна використовувати разом для пошуку схожих представлень слів або синтаксичного зіставлення. Інструментарій NLTK можна використовувати для завантаження багатьох пакетів, що постачаються з NLTK, а модель можна створити за допомогою Word2vec. Потім її можна протестувати на словах у реальному часі. Давайте розглянемо комбінацію обох у наступному коді. Перш ніж продовжувати обробку, будь ласка, перегляньте корпуси, які надає NLTK. Ви можете завантажити їх за допомогою команди:
nltk(nltk.download('all'))

Перегляньте код на знімку екрана.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

вихід:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Пояснення Code
- Бібліотеку nltk імпортовано, звідки можна завантажити корпус abc, який ми використовуватимемо на наступному кроці.
- Gensim імпортовано. Якщо Gensim Word2vec не встановлено, будь ласка, встановіть його за допомогою команди «pip3 install gensim». Дивіться знімок екрана нижче.

- Імпортуйте корпус abc, який було завантажено за допомогою nltk.download('abc').
- Передайте файли до моделі Word2vec, яка імпортується за допомогою Gensim, як речення.
- Словник зберігається у вигляді змінної.
- Модель тестується на зразку слова наука, оскільки ці файли пов’язані з наукою.
- Тут модель передбачає подібне слово «наука».
Активатори та Word2Vec
Активаційна функція нейрона визначає вихідний сигнал цього нейрона за заданого набору вхідних сигналів. Вона біологічно обумовлена активністю в нашому мозку, де різні нейрони активуються за допомогою різних стимулів. Давайте розглянемо активаційну функцію за допомогою наступної діаграми.

Тут x1, x2, … x4 – це вузли нейронної мережі.
w1, w2, w3 – ваги вузлів.
Підсумовування (Σ) усіх вагових коефіцієнтів та значень вузлів працює як функція активації.
Чому функція активації?
Якщо не використовується функція активації, вихід буде лінійним, але функціональність лінійної функції обмежена. Для досягнення складної функціональності, такої як виявлення об'єктів, класифікація зображень, тиping Для отримання тексту за допомогою голосу та багатьох інших нелінійних виходів потрібна функція активації.
Як обчислюється рівень активації у вбудовуванні слів (Word2vec)
Шар Softmax (нормалізована експоненціальна функція) – це функція вихідного шару, яка активує або запускає кожен вузол. Інший підхід, що використовується, – це ієрархічний softmax, де складність обчислюється як O(log2V), тоді як у softmax це O(V), де V – розмір словника. Різниця між ними полягає у зменшенні складності на ієрархічному рівні softmax. Щоб зрозуміти його функціональність, будь ласка, перегляньте наведений нижче приклад вбудовування Word:

Припустімо, ми хочемо обчислити ймовірність спостереження слова любов за певного контексту. Потік від кореня до кінцевого вузла спочатку переміститься до вузла 2, а потім до вузла 5. Отже, якщо у нас є розмір словника 8, потрібно лише три обчислення. Це дозволяє розкласти обчислення ймовірності одного слова (любов).
Які інші варіанти доступні, крім Hierarchical Softmax?
У загальному сенсі, доступні варіанти вбудовування слів - це диференційований Softmax, CNN-Softmax, вибірка за важливістю, адаптивна вибірка за важливістю, шумова контрастна оцінка, негативна вибірка, самонормалізація та нечаста нормалізація.
Якщо говорити конкретно про Word2vec, у нас є негативна вибірка.
Негативна вибірка – це спосіб вибірки навчальних даних. Він дещо схожий на стохастичний градієнтний спуск, але з деякими відмінностями. Негативна вибірка шукає лише негативні навчальні приклади. Вона базується на оцінці контрасту шуму та випадковим чином вибірково вибирає слова, які не знаходяться в контексті. Це швидкий метод навчання, який випадковим чином вибирає контекст. Якщо передбачуване слово з'являється у випадково вибраному контексті, обидва вектори близькі один до одного.
Який висновок можна зробити?
Активатори збуджують нейрони так само, як наші нейрони збуджуються за допомогою зовнішніх стимулів. Шар Softmax – це одна з функцій вихідного шару, яка збуджує нейрони у випадку вбудовування слів. У Word2vec у нас є такі опції, як ієрархічний softmax та негативна вибірка. За допомогою активаторів можна перетворити лінійну функцію на нелінійну, і за допомогою таких функцій можна реалізувати складний алгоритм машинного навчання.
Що таке Gensim?
Gensim це набір інструментів для тематичного моделювання та обробки природної мови з відкритим кодом, реалізований у Python і Cython. Інструментарій Gensim дозволяє користувачам імпортувати Word2vec для тематичного моделювання, щоб виявити приховану структуру в тексті. Gensim надає не лише реалізацію Word2vec, але й Doc2vec та FastText.
Цей розділ зосереджений на Word2vec, тому ми будемо дотримуватися поточної теми.
Як реалізувати Word2vec за допомогою Gensim
Досі ми обговорювали, що таке Word2vec, його різні архітектури, чому відбувається перехід від пакета слів до Word2vec, зв'язок між Word2vec та NLTK з живим кодом, а також функції активації.
Нижче наведено покроковий метод реалізації Word2vec за допомогою Gensim:
Крок 1) Збір даних
Першим кроком у впровадженні будь-якої моделі машинного навчання або обробки природної мови є збір даних.
Перегляньте дані, щоб створити інтелектуальний чат-бот, як показано в наведеному нижче прикладі Gensim Word2vec.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Ось що ми розуміємо з даних:
- Ці дані містять три речі: тег, шаблон та відповіді. Тег – це намір (що є темою обговорення).
- Дані у форматі JSON.
- Шаблон – це питання, яке користувачі ставитимуть боту.
- Відповіді – це відповіді, які чат-бот надасть на відповідне запитання/шаблон.
Крок 2) Попередня обробка даних
Дуже важливо обробляти необроблені дані. Якщо очищені дані подаються на машину, то модель реагуватиме точніше та вивчатиме дані ефективніше.
Цей крок включає видалення стоп-слів, коротких слів, непотрібних слів тощо. Перш ніж продовжити, важливо завантажити дані та перетворити їх у фрейм даних. Будь ласка, ознайомтеся з наведеним нижче кодом для цього.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Пояснення Code:
- Оскільки дані знаходяться у форматі JSON, імпортується JSON.
- Файл зберігається у змінній.
- Файл відкривається та завантажується у змінну даних.
Тепер дані імпортовано, і настав час конвертувати їх у фрейм даних. Будь ласка, дивіться код нижче для наступного кроку.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Пояснення Code:
1. Дані перетворюються у фрейм даних за допомогою pandas, який було імпортовано вище.
2. Він перетворює список у шаблонах стовпців на рядок.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Пояснення:
1. Англійські стоп-слова імпортуються за допомогою модуля stop-word з інструментарію nltk.
2. Усі слова тексту перетворюються на малі літери за допомогою умови for та лямбда-функції. A Лямбда-функція є анонімною функцією.
3. Усі рядки тексту у фреймі даних перевіряються на наявність розділових знаків у рядках, і вони фільтруються.
4. Такі символи, як цифри або крапки, видаляються за допомогою регулярного виразу.
5. Digits видаляються з тексту.
6. На цьому етапі стоп-слова видаляються.
7. Тепер слова фільтруються, а різні форми одного й того ж слова видаляються за допомогою лематизації. На цьому ми завершили попередню обробку даних.
вихід:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Крок 3) Побудова нейронної мережі за допомогою Word2vec
Тепер настав час побудувати модель за допомогою модуля Gensim Word2vec. Нам потрібно імпортувати Word2vec з Gensim. Давайте зробимо це, а потім ми побудуємо її, а на завершальному етапі перевіримо модель на даних реального часу.
from gensim.models import Word2Vec
Тепер ми можемо успішно створити модель за допомогою Word2Vec. Будь ласка, зверніться до наступного рядка коду, щоб дізнатися, як створити модель за допомогою Word2Vec. Текст надається моделі у вигляді списку, тому ми перетворимо текст з фрейму даних на список за допомогою наведеного нижче коду.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Пояснення Code:
1. Створено bigger_list, куди додається внутрішній список. Це формат, який передається до моделі Word2Vec.
2. Реалізовано цикл, і кожен запис стовпця patterns фрейму даних ітерується.
3. Кожен елемент шаблонів стовпців розділяється та зберігається у внутрішньому списку li.
4. Внутрішній список доповнюється зовнішнім списком.
5. Цей список надано для моделі Word2Vec. Давайте розглянемо деякі з наданих тут параметрів.
Min_count: Він ігнорує всі слова із загальною частотою нижчою за цю.
Розмір: Він говорить про розмірність векторів слів.
Робітники: Це потоки для навчання моделі.
Також доступні інші опції, деякі важливі з яких пояснюються нижче.
Вікно: Максимальна відстань між поточним і прогнозованим словом у реченні.
Sg: Це алгоритм навчання: 1 для skip-gram та 0 для безперервного мішка слів. Ми детально обговорили це вище.
Hs: Якщо це 1, то для навчання використовується ієрархічний softmax, а якщо 0, то використовується негативна вибірка.
Альфа: Початкова норма навчання.
Відобразимо остаточний код нижче:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Крок 4) Збереження моделі
Модель можна зберегти у форматі bin та файлу моделі. Bin – це двійковий формат. Будь ласка, дивіться наведені нижче рядки для збереження моделі.
model.save("word2vec.model") model.save("model.bin")
Пояснення наведеного вище коду
1. Модель зберігається у вигляді файлу .model.
2. Модель зберігається у вигляді файлу .bin.
Ми використовуватимемо цю модель для тестування в реальному часі, такого як схожі слова, несхожі слова та найпоширеніші слова.
Крок 5) Завантаження моделі та проведення тестування в реальному часі
Модель завантажується за допомогою наведеного нижче коду:
model = Word2Vec.load('model.bin')
Якщо ви хочете вивести словниковий запас з нього, це робиться за допомогою команди нижче:
vocab = list(model.wv.vocab)
Перегляньте результат:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Крок 6) Перевірка найбільш схожих слів
Давайте реалізуємо речі практично:
similar_words = model.most_similar('thanks') print(similar_words)
Перегляньте результат:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Крок 7) Не збігається слово з наданих слів
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Ми надали слова «До зустрічі, дякую за відвідування»Це виводить найбільш несхоже слово з цих слів. Давайте запустимо цей код і знайдемо результат.
Результат після виконання наведеного вище коду:
Thanks
Крок 8) Знаходження подібності між двома словами
Це показує результат з точки зору ймовірності подібності між двома словами. Будь ласка, дивіться код нижче, щоб дізнатися, як виконати цей розділ.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Результат виконання вищезазначеного коду виглядає наступним чином:
0.13706
Ви можете знайти подібні слова, виконавши наведений нижче код:
similar = model.similar_by_word('kind') print(similar)
Вивід наведеного вище коду:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]