Навчання з підкріпленням: що таке, Algorithms, типи та приклади
Що таке навчання з підкріпленням?
Навчання зміцненню визначається як метод машинного навчання, який стосується того, як програмні агенти повинні виконувати дії в середовищі. Навчання з підкріпленням є частиною методу глибокого навчання, який допомагає вам максимізувати частину сукупної винагороди.
Цей метод навчання нейронної мережі допомагає вам навчитися досягати складної мети або максимізувати певний вимір за багато кроків.
Важливі компоненти методу глибокого навчання з підкріпленням
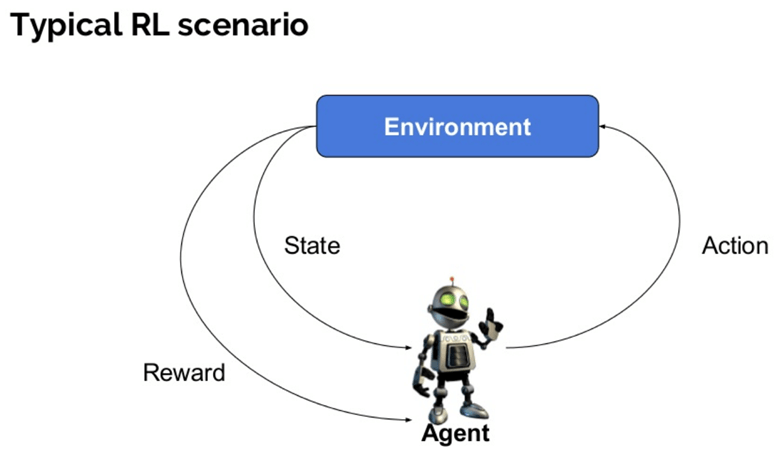
Ось деякі важливі терміни, які використовуються в Reinforcement AI:
- Агент: Це припущена сутність, яка виконує дії в середовищі, щоб отримати певну винагороду.
- Середовище (e): Сценарій, з яким доводиться стикатися агенту.
- Нагорода (R): Негайна віддача, яку отримує агент, коли він або вона виконує певну дію чи виконує завдання.
- Штат(и): Стан відноситься до поточної ситуації, повернутої середовищем.
- Політика (π): Це стратегія, яку застосовує агент, щоб вирішити наступну дію на основі поточного стану.
- Значення (V): Очікується довгострокова віддача зі знижкою порівняно з короткостроковою винагородою.
- Функція значення: Він визначає значення стану, яке є загальною сумою винагороди. Це агент, якого слід очікувати, починаючи з цього стану.
- Модель середовища: Це імітує поведінку навколишнього середовища. Це допомагає вам зробити висновки, а також визначити, як поводитиметься середовище.
- Методи на основі моделі: Це метод розв’язання проблем навчання з підкріпленням, який використовує методи на основі моделі.
- Значення Q або значення дії (Q): Значення Q дуже схоже на значення. Єдина відмінність між ними полягає в тому, що він приймає додатковий параметр як поточну дію.
Як працює навчання з підкріпленням?
Давайте розглянемо простий приклад, який допоможе вам проілюструвати механізм навчання з підкріпленням.
Розгляньте сценарій навчання вашого кота новим трюкам
- Оскільки кішка не розуміє англійської чи будь-якої іншої людської мови, ми не можемо сказати їй, що робити. Натомість ми дотримуємося іншої стратегії.
- Ми моделюємо ситуацію, і кіт намагається відповісти різними способами. Якщо відповідь кішки буде бажаною, ми дамо їй рибу.
- Тепер щоразу, коли кіт потрапляє в таку саму ситуацію, кіт виконує подібну дію з ще більшим ентузіазмом, очікуючи отримати більше винагороди (їжі).
- Це як дізнатися, що кіт отримує від «що робити» з позитивного досвіду.
- У той же час кіт також дізнається, чого не робити, коли стикається з негативним досвідом.
Приклад навчання з підкріпленням
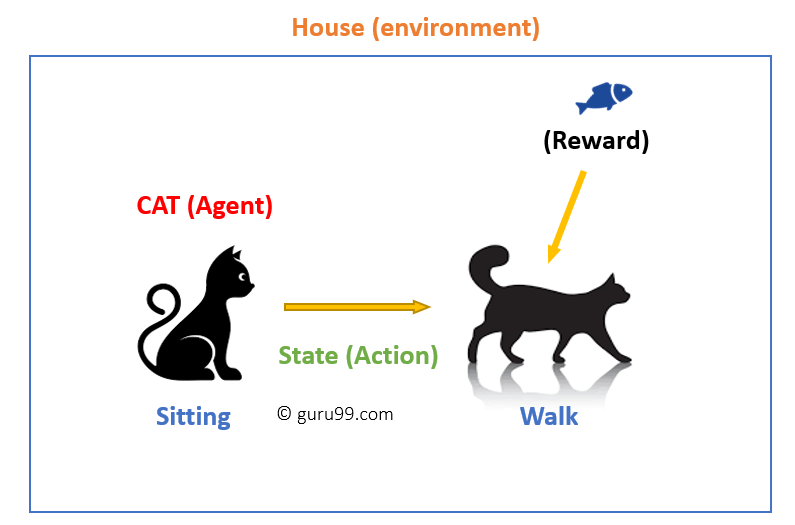
В цьому випадку,
- Ваша кішка є агентом, який піддається впливу навколишнього середовища. В даному випадку це ваш будинок. Прикладом стану може бути ваш кіт, який сидить, і ви використовуєте певне слово для позначення кота гуляти.
- Наш агент реагує, виконуючи перехід дії з одного «стану» в інший «стан».
- Наприклад, ваша кішка переходить від сидіння до ходьби.
- Реакція агента — це дія, а політика — це метод вибору дії в певному стані в очікуванні кращих результатів.
- Після переходу вони можуть отримати винагороду або штраф у відповідь.
Навчання зміцненню Algorithms
Існує три підходи до впровадження алгоритму навчання з підкріпленням.
На основі цінностей
У методі навчання з підкріпленням на основі цінностей ви повинні спробувати максимізувати функцію цінності V(s). У цьому методі агент очікує довгострокового повернення поточних станів за політикою π.
На основі політики
У методі RL на основі політики ви намагаєтеся придумати таку політику, щоб дія, виконана в кожному стані, допомагала вам отримати максимальну винагороду в майбутньому.
Два типи методів на основі політики:
- Детермінований: для будь-якого стану така сама дія створюється політикою π.
- Стохастичний: кожна дія має певну ймовірність, яка визначається наступним рівнянням. Стохастична політика:
n{a\s) = P\A, = a\S, =S]
На основі моделі
У цьому методі Reinforcement Learning вам потрібно створити віртуальну модель для кожного середовища. Агент вчиться діяти в цьому конкретному середовищі.
Характеристики навчання з підкріпленням
Ось важливі характеристики навчання з підкріпленням
- Немає супервізора, тільки реальне число або сигнал винагороди
- Послідовне прийняття рішень
- Час відіграє вирішальну роль у проблемах підкріплення
- Зворотний зв’язок завжди з запізненням, а не миттєвим
- Дії агента визначають подальші дані, які він отримує
Типи навчання з підкріпленням
Два типи методів навчання з підкріпленням:
Позитивні:
Воно визначається як подія, що відбувається через певну поведінку. Це збільшує силу та частоту поведінки та позитивно впливає на дію агента.
Цей тип підсилення допомагає вам максимізувати продуктивність і підтримувати зміни протягом більш тривалого періоду. Однак занадто велике посилення може призвести до надмірної оптимізації стану, що може вплинути на результати.
Негативний:
Негативне підкріплення визначається як посилення поведінки, яке виникає через негативний стан, який слід було припинити або уникнути. Це допоможе вам визначити мінімальну продуктивність. Однак недоліком цього методу є те, що він забезпечує достатньо для досягнення мінімальної поведінки.
Вивчення моделей підкріплення
У навчанні з підкріпленням є дві важливі моделі навчання:
- Марковський процес прийняття рішень
- Q навчання
Марковський процес прийняття рішень
Для отримання рішення використовуються такі параметри:
- Набір дій - А
- Набір станів -S
- Нагорода - Р
- Політика- н
- Значення - В
Математичний підхід до картиping Рішення в навчанні з підкріпленням реконструюється як процес прийняття рішень Марковом або (MDP).
Q-навчання
Q-навчання — це заснований на цінностях метод надання інформації для інформування про те, яку дію повинен виконати агент.
Давайте розберемо цей метод на наступному прикладі:
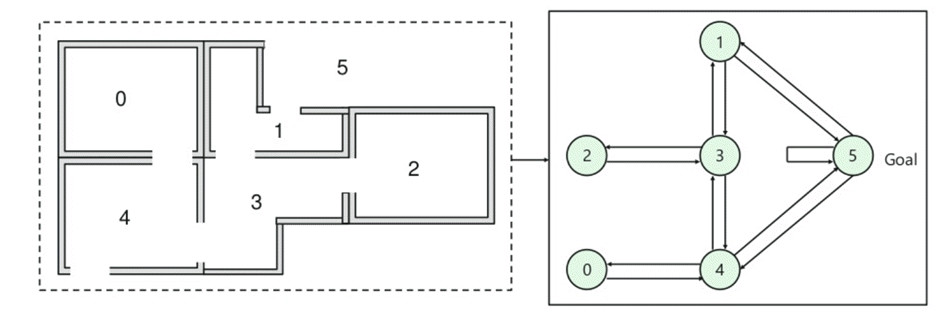
- У будівлі є п'ять кімнат, які з'єднані дверима.
- Кожна кімната пронумерована від 0 до 4
- Зовнішня частина будівлі може бути однією великою зовнішньою зоною (5)
- Двері номер 1 і 4 ведуть в будівлю з кімнати 5
Далі вам потрібно прив’язати значення винагороди до кожної двері:
- Двері, які ведуть прямо до мети, отримують винагороду 100
- Двері, які безпосередньо не пов’язані з цільовою кімнатою, не дають винагороди
- Так як двері двосторонні, то для кожної кімнати призначено дві стрілки
- Кожна стрілка на зображенні вище містить значення миттєвої винагороди
Пояснення:
На цьому зображенні ви можете побачити, що кімната представляє стан
Переміщення агента з однієї кімнати в іншу являє собою дію
На наведеному нижче зображенні стан описано як вузол, тоді як стрілки показують дію.

Наприклад, агент проходить з кімнати № 2 до 5
- Початковий стан = стан 2
- Стан 2-> стан 3
- Стан 3 -> стан (2,1,4)
- Стан 4-> стан (0,5,3)
- Стан 1-> стан (5,3)
- Стан 0-> стан 4
Навчання з підкріпленням проти навчання під контролем
| Параметри | Навчання зміцненню | Навчання під наглядом |
|---|---|---|
| Стиль рішення | навчання з підкріпленням допомагає вам приймати рішення послідовно. | У цьому методі рішення приймається на основі вхідних даних, наведених на початку. |
| Працює на | Працює над взаємодією з навколишнім середовищем. | Працює на прикладах або заданих зразках даних. |
| Залежність від рішення | У методі RL рішення щодо навчання є залежним. Таким чином, ви повинні давати позначки всім залежним рішенням. | Навчання під наглядом рішень, які не залежать одне від одного, тому кожному рішенню надаються позначки. |
| Найкраще підходить | Підтримує та краще працює в ШІ, де переважає взаємодія людей. | Здебільшого він працює за допомогою інтерактивної програмної системи або програм. |
| Приклад | Гра в шахи | Розпізнавання об’єктів |
Застосування навчання з підкріпленням
Ось програми Reinforcement Learning:
- Робототехніка для промислової автоматизації.
- Планування бізнес-стратегії
- навчання за допомогою машини та обробка даних
- Це допомагає вам створювати системи навчання, які надають спеціальні інструкції та матеріали відповідно до вимог студентів.
- Керування літальним апаратом і керування рухом робота
Навіщо використовувати Reinforcement Learning?
Ось основні причини використання навчання з підкріпленням:
- Це допоможе вам визначити, яка ситуація потребує дії
- Допомагає визначити, яка дія приносить найбільшу винагороду протягом тривалого періоду.
- Навчання з підкріпленням також надає агенту навчання функцію винагороди.
- Це також дозволяє визначити найкращий спосіб отримання великих винагород.
Коли не слід використовувати навчання з підкріпленням?
Ви не можете застосувати модель навчання з підкріпленням – це вся ситуація. Ось деякі умови, коли не слід використовувати модель навчання з підкріпленням.
- Коли у вас достатньо даних, щоб вирішити проблему за допомогою методу навчання під наглядом
- Ви повинні пам’ятати, що навчання з підкріпленням потребує великих обчислень і часу. особливо коли простір дії великий.
Проблеми навчання з підкріпленням
Ось основні труднощі, з якими ви зіткнетеся під час заробітку на підкріпленні:
- Розробка функцій/винагород, яка має бути дуже залученою
- Параметри можуть впливати на швидкість навчання.
- Реалістичне середовище може частково спостерігатися.
- Занадто багато посилення може призвести до перевантаження станів, що може зменшити результати.
- Реалістичне середовище може бути нестаціонарним.
Резюме
- Навчання з підкріпленням – це метод машинного навчання
- Допомагає визначити, яка дія приносить найбільшу винагороду протягом тривалого періоду.
- Три методи навчання з підкріпленням: 1) на основі цінностей 2) на основі політики та навчання на основі моделі.
- Агент, стан, винагорода, середовище, функція цінності, модель середовища, методи, засновані на моделі, є деякими важливими термінами, які використовуються в методі навчання RL
- Приклад навчання з підкріпленням: ваша кішка є агентом, який піддається впливу навколишнього середовища.
- Найбільшою особливістю цього методу є відсутність супервізора, лише реальне число або сигнал винагороди
- Два типи навчання з підкріпленням: 1) Позитивне 2) Негативне
- Дві широко використовувані моделі навчання: 1) Марковський процес прийняття рішень 2) Q навчання
- Метод навчання з підкріпленням працює над взаємодією з навколишнім середовищем, тоді як контрольоване навчання метод працює на заданих вибіркових даних або прикладі.
- Застосування або підсилювальні методи навчання: Робототехніка для промислової автоматизації та планування бізнес-стратегії
- Ви не повинні використовувати цей метод, якщо у вас достатньо даних для вирішення проблеми
- Найбільша проблема цього методу полягає в тому, що параметри можуть впливати на швидкість навчання