PyTorch Підручник
⚡ Розумний підсумок
PyTorch — це фреймворк глибокого навчання з відкритим кодом від Meta, який у 2026 році лежить в основі 85 відсотків дослідницьких робіт зі штучного інтелекту. LessВони охоплюють встановлення, основи фреймворку, просту регресію, класифікацію зображень та розгортання AWS SageMaker.

Що таке PyTorh?
PyTorch є відкритим кодом TorБібліотека машинного навчання на основі ch для обробки природної мови з використанням PythonВін схожий на NumPy, але з потужною підтримкою графічних процесорів. Він пропонує динамічні обчислювальні графіки, які можна змінювати на ходу за допомогою автоградації. PyTorch також швидший за деякі інші фреймворки. Його розробила дослідницька група штучного інтелекту Facebook у 2016 році.
Знаючи, що PyTorch пропонує збалансований погляд на його сильні та недоліки.
PyTorПереваги та недоліки ch
Нижче наведено переваги та недоліки PyTorч:
Переваги PyTorch
- Проста бібліотека
PyTorКод ch простий. Його легко зрозуміти, і ви можете миттєво використовувати бібліотеку. Наприклад, погляньте на фрагмент коду нижче:
class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.layer = torch.nn.Linear(1, 1) def forward(self, x): x = self.layer(x) return x
Як згадувалося вище, ви можете легко визначити модель мережі, і ви можете швидко зрозуміти код без особливого навчання.
- Динамічний обчислювальний графік

Джерело зображення: Дослідження глибокого навчання за допомогою PyTorch
PyTorch пропонує динамічні обчислювальні графи (DAG). Обчислювальні графи – це спосіб вираження математичних виразів у графових моделях або теоріях, таких як вузли та ребра. Вузол виконує математичну операцію, а ребро – це тензор, який передається у вузли та несе вихідні дані вузла в тензорі.
DAG — це граф, який має довільну форму та може виконувати операції між різними вхідними графами. З кожною ітерацією створюється новий графік. Отже, можна мати таку саму структуру графа або створити новий графік з іншою операцією, або ми можемо назвати це динамічним графіком.
- Краща продуктивність
Спільноти та дослідники, тестуйте та порівнюйте фреймворки, щоб побачити, який із них швидший. Репо GitHub Порівняльний тест на основі глибокого навчання та GPU повідомив, що PyTorch швидший за інші фреймворки з точки зору обробки зображень за секунду.
Як ви можете бачити нижче, порівняльні графіки з vgg16 і resnet152


- рідний Python
PyTorch більше базується на Python. Наприклад, якщо ви хочете навчити модель, ви можете використовувати нативний потік керування, такий як loo.ping та рекурсії без необхідності додавати додаткові спеціальні змінні або сесії для їх запуску. Це дуже корисно для процесу навчання.
PyTorch також реалізує імперативне програмування, і воно безумовно гнучкіше. Отже, можливо вивести значення тензора посеред процесу обчислення.
Недолік PyTorch
PyTorch вимагає сторонніх програм для візуалізації. Також потрібен API-сервер для продакшену.
Далі в цьому PyTorУ цьому посібнику ми дізнаємося про різницю між PyTorch та TensorFlow.
PyTorch проти TensorFlow
| Параметр | PyTorch | TensorFlow |
|---|---|---|
| Визначення моделі | Модель визначена в підкласі та пропонує простий у використанні пакет | Модель визначається багатьма, і вам потрібно зрозуміти синтаксис |
| Підтримка GPU | Так | Так |
| Тип графіка | Dynamic | Статичний |
| Інструменти | Немає інструментів візуалізації | Ви можете використовувати інструмент візуалізації Tensorboard |
| Спільнота | Спільнота все ще зростає | Великі активні спільноти |
З огляду на порівняння, наступним кроком є отримання PyTorch працює локально або в хмарі.
Встановлення PyTorch
Linux
Його легко встановити в Linux. Ви можете вибрати використання віртуального середовища або встановити його безпосередньо з кореневим доступом. Введіть цю команду в терміналі
pip3 install --upgrade torch torchvision
AWS Sagemaker
Sagemaker є однією з платформ у Amazon Веб-сервіс який пропонує потужний механізм машинного навчання з попередньо встановленими конфігураціями глибокого навчання для вчених даних або розробників для створення, навчання та розгортання моделей будь-якого масштабу.
Спочатку відкрийте Amazon Шалфейник консолі та клацніть «Створити екземпляр блокнота» та введіть усі дані для свого блокнота.

На наступному кроці натисніть «Відкрити», щоб запустити екземпляр блокнота.

Нарешті, В JupyterНатисніть кнопку «Створити» та виберіть conda_pytorch_p36, і ви готові використовувати свій екземпляр блокнота з Py.Torch встановлено.
Далі в цьому PyTorУ цьому посібнику ми дізнаємося про Py.TorОснови фреймворку CH.
Встановлення на місці, наступним кроком є сам API.
PyTorОснови фреймворку ch
Давайте вивчимо основні концепції PyTorперш ніж ми заглибимося. PyTorch використовує тензор для кожної змінної, подібно до ndarray в numpy, але з підтримкою обчислень на GPU. Тут ми пояснимо мережеву модель, функцію втрат, зворотне просування та оптимізатор.
Модель мережі
Мережа може бути побудована за допомогою підкласу torch.nn. Є 2 основні частини,
- Перша частина полягає у визначенні параметрів і шарів, які ви будете використовувати
- Друга частина — це основне завдання, яке називається прямим процесом, який приймає вхідні дані та прогнозує вихідні дані.
Import torch import torch.nn as nn import torch.nn.functional as F class Model(nn.Module): def __init__(self): super(Model, self).__init__() self.conv1 = nn.Conv2d(3, 20, 5) self.conv2 = nn.Conv2d(20, 40, 5) self.fc1 = nn.Linear(320, 10) def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = x.view(-1, 320) x = F.relu(self.fc1(x)) return F.log_softmax(x) net = Model()
Як ви бачите вище, ви створюєте клас nn.Module під назвою Model. Він містить 2 шари Conv2d і лінійний шар. Перший шар conv2d приймає вхідні значення 3 і вихідну форму 20. Другий шар прийматиме вхідні дані 20 і вироблятиме вихідну форму 40. Останній шар є повністю зв’язаним шаром у формі 320 і вироблятиме вихід 10.
Прямий процес прийматиме вхідні дані X і передаватиме їх на рівень conv1 і виконуватиме функцію ReLU,
Подібним чином, він також буде живити рівень conv2. Після цього x буде змінено на (-1, 320) і подано в остаточний шар FC. Перш ніж надсилати вихідні дані, ви скористаєтеся функцією активації softmax.
Зворотний процес автоматично визначається autograd, тому вам потрібно лише визначити процес прямого.
Функція втрати
Функція втрат використовується для вимірювання того, наскільки добре модель прогнозування здатна передбачити очікувані результати. PyTorch вже має багато стандартних функцій втрат у модулі torch.nn. Наприклад, ви можете використовувати втрату перехресної ентропії для вирішення багатокласової задачі Py.TorЗадача класифікації ch. Визначити функцію втрат та обчислити втрати легко:
loss_fn = nn.CrossEntropyLoss() #training process loss = loss_fn(out, target)
Розрахунок функції втрат за допомогою Py легко виконати самостійно.Torглава
Задня опора
Щоб виконати зворотне поширення, ви просто викликаєте los.backward(). Помилка буде обчислена, але не забудьте очистити наявний градієнт за допомогою zero_grad()
net.zero_grad() # to clear the existing gradient loss.backward() # to perform backpropragation
Оптимізатор
Torch.optim надає загальні алгоритми оптимізації. Ви можете визначити оптимізатор за допомогою простого кроку:
optimizer = torch.optim.SGD(net.parameters(), lr = 0.01, momentum=0.9)
Вам потрібно передати параметри моделі мережі та швидкість навчання, щоб на кожній ітерації параметри оновлювалися після процесу резервної підтримки.
Найчистіший спосіб вивчити API – це невеликий, повний приклад.
Проста регресія з PyTorch
Давайте вивчимо просту регресію за допомогою PyTorприклади головних імен:
Крок 1) Створення нашої моделі мережі
Наша мережева модель є простим лінійним шаром із вхідною та вихідною формою 1.
from __future__ import print_function import torch import torch.nn as nn import torch.nn.functional as F from torch.autograd import Variable class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.layer = torch.nn.Linear(1, 1) def forward(self, x): x = self.layer(x) return x net = Net() print(net)
І вихід мережі повинен бути таким
Net( (hidden): Linear(in_features=1, out_features=1, bias=True) )
Крок 2) Тестові дані
Перш ніж почати навчальний процес, вам необхідно знати наші дані. Ви створюєте випадкову функцію, щоб перевірити нашу модель. Y = x3 sin(x)+ 3x+0.8 ранд(100)
# Visualize our data import matplotlib.pyplot as plt import numpy as np x = np.random.rand(100) y = np.sin(x) * np.power(x,3) + 3*x + np.random.rand(100)*0.8 plt.scatter(x, y) plt.show()
Ось діаграма розсіювання нашої функції:

Перш ніж розпочати процес навчання, вам потрібно конвертувати масив numpy у змінні, які підтримуються Torch та автоград, як показано на рисунку нижче PyTorПриклад ch-регресії.
# convert numpy array to tensor in shape of input size x = torch.from_numpy(x.reshape(-1,1)).float() y = torch.from_numpy(y.reshape(-1,1)).float() print(x, y)
Крок 3) Оптимізатор і втрати
Далі вам слід визначити оптимізатор і функцію втрати для нашого процесу навчання.
# Define Optimizer and Loss Function optimizer = torch.optim.SGD(net.parameters(), lr=0.2) loss_func = torch.nn.MSELoss()
Крок 4) Навчання
Тепер давайте почнемо наш навчальний процес. З епохою 250 ви будете повторювати наші дані, щоб знайти найкраще значення для наших гіперпараметрів.
inputs = Variable(x) outputs = Variable(y) for i in range(250): prediction = net(inputs) loss = loss_func(prediction, outputs) optimizer.zero_grad() loss.backward() optimizer.step() if i % 10 == 0: # plot and show learning process plt.cla() plt.scatter(x.data.numpy(), y.data.numpy()) plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=2) plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 10, 'color': 'red'}) plt.pause(0.1) plt.show()
Крок 5) Результат
Як ви можете бачити нижче, ви успішно виконали PyTorch регресія за допомогою нейронної мережі. Фактично, на кожній ітерації червона лінія на графіку оновлюватиметься та змінюватиме своє положення відповідно до даних. Але на цьому зображенні показано лише кінцевий результат, як показано на рисунку нижче Py.Torприклад ch:

Регресія – це розминка; класифікація зображень тренує м'язи глибокого навчання PyTorглава
Приклад класифікації зображень за допомогою PyTorch
Один із популярних методів вивчення основ глибоке навчання з набором даних MNIST. Це «Hello World» у глибокому навчанні. Набір даних містить рукописні числа від 0 до 9 із загальною кількістю 60,000 10,000 навчальних зразків і 28 28 тестових зразків, які вже позначені розміром XNUMX×XNUMX пікселів.

Крок 1) Попередня обробка даних
На першому кроці цього PyTorУ прикладі класифікації ch ви завантажите набір даних за допомогою модуля torchvision.
Перш ніж розпочати процес навчання, вам потрібно зрозуміти дані. Torchvision завантажить набір даних та трансформує зображення відповідно до вимог мережі, таких як форма та нормалізація зображень.
import torch import torchvision import numpy as np from torchvision import datasets, models, transforms # This is used to transform the images to Tensor and normalize it transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) training = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform) train_loader = torch.utils.data.DataLoader(training, batch_size=4, shuffle=True, num_workers=2) testing = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform) test_loader = torch.utils.data.DataLoader(testing, batch_size=4, shuffle=False, num_workers=2) classes = ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9') import matplotlib.pyplot as plt import numpy as np #create an iterator for train_loader # get random training images data_iterator = iter(train_loader) images, labels = data_iterator.next() #plot 4 images to visualize the data rows = 2 columns = 2 fig=plt.figure() for i in range(4): fig.add_subplot(rows, columns, i+1) plt.title(classes[labels[i]]) img = images[i] / 2 + 0.5 # this is for unnormalize the image img = torchvision.transforms.ToPILImage()(img) plt.imshow(img) plt.show()
Функція transform перетворює зображення в тензор і нормалізує значення. Функція torchvision.transforms.MNIST завантажить набір даних (якщо він недоступний) у каталозі, за потреби налаштує набір даних для навчання та виконає процес перетворення.
Щоб візуалізувати набір даних, ви використовуєте data_iterator, щоб отримати наступну партію зображень і міток. Ви використовуєте matplot, щоб побудувати ці зображення та їх відповідну мітку. Як ви можете бачити нижче, наші зображення та їхні мітки.
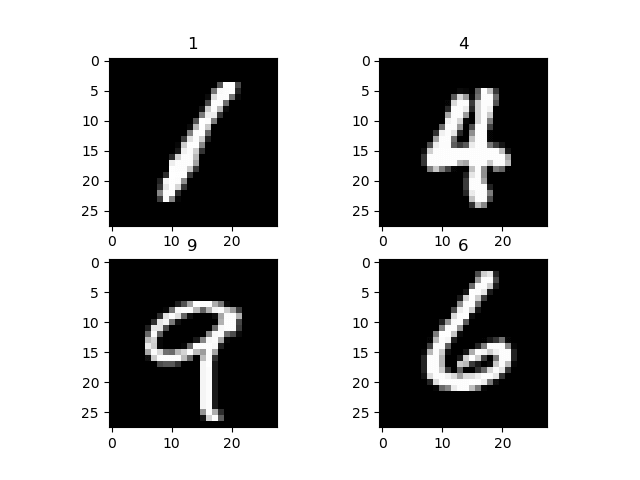
Крок 2) Конфігурація моделі мережі
Тепер у цьому PyTorНаприклад, ви створите просту нейронну мережу для PyTorкласифікація зображень ch.
Тут ми представляємо вам ще один спосіб створення мережевої моделі в Py.Torгл. Ми використовуватимемо nn.Sequential для створення моделі послідовності замість створення підкласу nn.Module.
import torch.nn as nn # flatten the tensor into class Flatten(nn.Module): def forward(self, input): return input.view(input.size(0), -1) #sequential based model seq_model = nn.Sequential( nn.Conv2d(1, 10, kernel_size=5), nn.MaxPool2d(2), nn.ReLU(), nn.Dropout2d(), nn.Conv2d(10, 20, kernel_size=5), nn.MaxPool2d(2), nn.ReLU(), Flatten(), nn.Linear(320, 50), nn.ReLU(), nn.Linear(50, 10), nn.Softmax(), ) net = seq_model print(net)
Ось результат нашої моделі мережі
Sequential( (0): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)) (1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (2): ReLU() (3): Dropout2d(p=0.5) (4): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)) (5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (6): ReLU() (7): Flatten() (8): Linear(in_features=320, out_features=50, bias=True) (9): ReLU() (10): Linear(in_features=50, out_features=10, bias=True) (11): Softmax() )
Пояснення мережі
- Послідовність полягає в тому, що перший рівень є шаром Conv2D із вхідною формою 1 і вихідною формою 10 із розміром ядра 5
- Далі у вас є шар MaxPool2D
- Функція активації ReLU
- шар вилучення, щоб викинути значення низької ймовірності.
- Потім другий Conv2d із вхідною формою 10 з останнього шару та вихідною формою 20 із розміром ядра 5
- Далі шар MaxPool2d
- Функція активації ReLU.
- Після цього ви зведете тензор перед подачею його на лінійний шар
- Лінійний шар відобразить наш вихід на другому лінійному шарі з функцією активації softmax
Крок 3) Навчіть модель
Перед початком процесу навчання необхідно налаштувати функцію критерію та оптимізатора.
Як критерій ви використовуватимете CrossEntropyLoss. Для оптимізатора ви використовуватимете SGD з коефіцієнтом навчання 0.001 та імпульсом 0.9, як показано на графіку Py нижче.Torприклад ch.
import torch.optim as optim criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
Попередній процес візьме вхідну форму та передасть її до першого рівня conv2d. Звідти його буде подано в maxpool2d і, нарешті, у функцію активації ReLU. Той самий процес відбуватиметься на другому рівні conv2d. Після цього вхідні дані буде змінено на (-1,320) і подано на рівень fc для прогнозування виходу.
Тепер ви почнете навчальний процес. Ви будете переглядати наш набір даних 2 рази або з епохою 2 і роздруковувати поточні втрати на кожній 2000 партії.
for epoch in range(2): #set the running loss at each epoch to zero running_loss = 0.0 # we will enumerate the train loader with starting index of 0 # for each iteration (i) and the data (tuple of input and labels) for i, data in enumerate(train_loader, 0): inputs, labels = data # clear the gradient optimizer.zero_grad() #feed the input and acquire the output from network outputs = net(inputs) #calculating the predicted and the expected loss loss = criterion(outputs, labels) #compute the gradient loss.backward() #update the parameters optimizer.step() # print statistics running_loss += loss.item() if i % 1000 == 0: print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 1000)) running_loss = 0.0
У кожній епосі нумератор отримає наступний кортеж вхідних даних і відповідні мітки. Перш ніж подати вхідні дані в нашу модель мережі, нам потрібно очистити попередній градієнт. Це необхідно, тому що після зворотного процесу (процесу зворотного поширення) градієнт буде накопичуватися, а не замінюватися. Потім ми обчислимо втрати від прогнозованого випуску з очікуваного випуску. Після цього ми виконаємо зворотне поширення, щоб обчислити градієнт, і, нарешті, ми оновимо параметри.
Ось результат тренувального процесу
[1, 1] loss: 0.002 [1, 1001] loss: 2.302 [1, 2001] loss: 2.295 [1, 3001] loss: 2.204 [1, 4001] loss: 1.930 [1, 5001] loss: 1.791 [1, 6001] loss: 1.756 [1, 7001] loss: 1.744 [1, 8001] loss: 1.696 [1, 9001] loss: 1.650 [1, 10001] loss: 1.640 [1, 11001] loss: 1.631 [1, 12001] loss: 1.631 [1, 13001] loss: 1.624 [1, 14001] loss: 1.616 [2, 1] loss: 0.001 [2, 1001] loss: 1.604 [2, 2001] loss: 1.607 [2, 3001] loss: 1.602 [2, 4001] loss: 1.596 [2, 5001] loss: 1.608 [2, 6001] loss: 1.589 [2, 7001] loss: 1.610 [2, 8001] loss: 1.596 [2, 9001] loss: 1.598 [2, 10001] loss: 1.603 [2, 11001] loss: 1.596 [2, 12001] loss: 1.587 [2, 13001] loss: 1.596 [2, 14001] loss: 1.603
Крок 4) Перевірте модель
Після того, як ви навчите нашу модель, вам потрібно протестувати або оцінити за допомогою інших наборів зображень.
Ми будемо використовувати ітератор для test_loader, і він створить пакет зображень і міток, які будуть передані в навчену модель. Прогнозований вихід буде відображено та порівняно з очікуваним результатом.
#make an iterator from test_loader #Get a batch of training images test_iterator = iter(test_loader) images, labels = test_iterator.next() results = net(images) _, predicted = torch.max(results, 1) print('Predicted: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4))) fig2 = plt.figure() for i in range(4): fig2.add_subplot(rows, columns, i+1) plt.title('truth ' + classes[labels[i]] + ': predict ' + classes[predicted[i]]) img = images[i] / 2 + 0.5 # this is to unnormalize the image img = torchvision.transforms.ToPILImage()(img) plt.imshow(img) plt.show()
