Що таке Hadoop? ArchiСтруктура, екосистема та компоненти
⚡ Розумний підсумок
Apache Hadoop — це фреймворк з відкритим кодом, який зберігає величезні набори даних на кластерах звичайних машин і переносить логіку обробки на дані, тому аналіз масштабується шляхом додавання дешевих вузлів, а не більших серверів.

Що таке Hadoop?
Apache Hadoop — це платформа програмного забезпечення з відкритим вихідним кодом, яка використовується для розробки програм обробки даних, які виконуються в розподіленому обчислювальному середовищі.
Програми, створені за допомогою Hadoop, працюють на великих наборах даних, розподілених по кластерах звичайних комп'ютерів. Звичайні комп'ютери дешеві та широко доступні. Вони корисні переважно для досягнення більшої обчислювальної потужності за низькою ціною.
Подібно до даних, що зберігаються в локальній файловій системі персонального комп'ютера, в Hadoop дані зберігаються в розподіленій файловій системі, яка називається Розподілена файлова система HadoopМодель обробки базується на «Локальність даних» концепція, в якій обчислювальна логіка надсилається до вузлів кластера (серверів), що містять дані. Ця обчислювальна логіка є просто скомпільованою версією програми, написаної мовою високого рівня, такою як JavaТака програма обробляє дані, що зберігаються в Hadoop HDFS.
Чи знаєте ви? Комп'ютерний кластер складається з набору кількох процесорів (диск + процесор), які з'єднані один з одним і діють як єдина система.
Версія 3.5.0, опублікована 2 квітня 2026 року, є поточною стабільною версією; лінійка 3.4 все ще отримує оновлення для підтримки.
Екосистема та компоненти Hadoop
На діаграмі нижче показано різні компоненти екосистеми Hadoop, згруповані за завданнями, які виконує кожен з них — зберігання, обробка, а також інструменти запитів, прийому та координації.

Apache Hadoop складається з двох підпроектів –
- Hadoop MapReduce: MapReduce — це обчислювальна модель і програмна основа для написання програм, які запускаються на Hadoop. Ці програми MapReduce здатні обробляти величезні дані паралельно на великих кластерах обчислювальних вузлів.
- HDFS (Розподілена файлова система Hadoop): HDFS піклується про частину зберігання програм Hadoop. Програми MapReduce споживають дані з HDFS. HDFS створює кілька реплік блоків даних і розподіляє їх на обчислювальних вузлах у кластері. Цей розподіл забезпечує надійні та надзвичайно швидкі обчислення.
Поточні релізи містять два додаткові основні модулі. Пряжа Hadoop, доданий у Hadoop 2.x, планує роботу на кластері та Хадуп Коммон має спільний Java бібліотеки, від яких залежить кожен модуль. YARN – це те, що дозволяє таким рушіям, як Spark, Tez та Flink працюють разом із MapReduce.
Хоча Hadoop найбільш відомий завдяки MapReduce та його розподіленій файловій системі HDFS, цей термін також використовується для позначення сімейства пов'язаних проектів, що підпадають під поняття розподілених обчислень та великомасштабної обробки даних. Інші пов'язані з Hadoop проекти на Apache включають Вулик, HBase, Mahout, Сквуп, Флюмта ЗооКеепер.
Hadoop Archiтектура
Hadoop має архітектуру master-slave для зберігання даних та розподіленої обробки даних. MapReduce і методи HDFS. На діаграмі нижче ці ролі розташовані поруч, де рівень зберігання знаходиться з одного боку, а рівень обробки — з іншого.
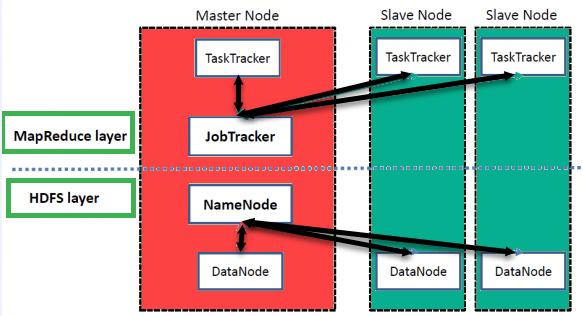
Hadoop високого рівня Archiтектура
NameNode
NameNode зберігає метадані для кожного файлу та каталогу, що використовуються в просторі імен, включаючи блоки, з яких складається кожен файл, та де ці блоки знаходяться.
DataNode
Вузол даних (DataNode) керує станом вузла HDFS та дозволяє взаємодіяти з блоками, які він зберігає, повідомляючи NameNode про періодичні звіти про блоки та серцеві скорочення.
Головний вузол
Головний вузол дозволяє проводити паралельну обробку даних за допомогою Hadoop MapReduce.
Ведений вузол
Підлеглі вузли – це додаткові машини в кластері Hadoop, які дозволяють зберігати дані та виконувати складні обчислення. Більше того, кожен підлеглий вузол виконує завдання.Tracker та DataNode. Це дозволяє синхронізувати процеси з NameNode та JobTracкер відповідно.
У Hadoop головні або підлеглі системи можна налаштувати в хмарі або локально.
Одне зауваження щодо назви: роботаTracКер та ЗавданняTracКер належать до середовища виконання MapReduce першого покоління (MRv1). Починаючи з Hadoop 2.x, YARN розподіляє свої обов'язки між кластерним Менеджер ресурсів, то NodeManager на одного працівника та один Майстер додатків для кожного завдання. NameNode та DataNode залишаються незмінними.
Особливості Hadoop
Підходить для аналізу великих даних
As Великий даних Оскільки кластери Hadoop, як правило, розподілені та неструктуровані, вони найкраще підходять для аналізу великих даних. Оскільки до обчислювальних вузлів надходить логіка обробки (а не самі дані), споживається менше пропускної здатності мережі. Це називається концепція локальності даних, і це допомагає підвищити ефективність застосунків на базі Hadoop.
масштабованість
Кластери Hadoop можна легко масштабувати до будь-якої міри, додаючи додаткові вузли кластера, що дозволяє розширювати обсяг великих даних. Крім того, масштабування не вимагає змін у логіці застосунку.
Відмовостійкість
Екосистема Hadoop має можливість реплікації вхідних даних на інші вузли кластера. Таким чином, у разі збою вузла кластера, обробка даних може продовжуватися з використанням даних, що зберігаються на іншому вузлі кластера. HDFS за замовчуванням зберігає три копії кожного блоку, значення, встановлене dfs.replication властивість, а NameNode повторно реплікує будь-який блок, кількість якого падає нижче цієї кількості.
Топологія мережі в Hadoop
Топологія (організація) мережі впливає на продуктивність кластера Hadoop зі зростанням його розміру. Окрім продуктивності, також необхідно дбати про високу доступність та обробку збоїв. Для досягнення цього формування кластера Hadoop використовує топологію мережі.
Наведене нижче дерево показує, як змодельовано цю схему розташування, від центру обробки даних до вузлів усередині кожної стійки.

Зазвичай, пропускна здатність мережі є важливим фактором, який слід враховувати під час формування будь-якої мережі. Однак, оскільки вимірювання пропускної здатності може бути складним, у Hadoop мережа представлена у вигляді дерева, а відстань між вузлами цього дерева (кількість стрибків) вважається важливим фактором у формуванні кластера Hadoop. Тут відстань між двома вузлами дорівнює сумі їхніх відстаней до найближчого спільного предка.
Кластер Hadoop складається з центру обробки даних, стійки та вузла, який фактично виконує завдання. Тут центр обробки даних складається з стійок, а стійка складається з вузлів. Пропускна здатність мережі, доступна для процесів, залежить від розташування процесів. Тобто, доступна пропускна здатність зменшується, коли ми віддаляємося від...
- Процеси на одному вузлі
- Різні вузли на одній стійці
- Вузли на різних стійках одного центру обробки даних
- Вузли в різних дата-центрах
Усвідомлення стійки використовує те саме дерево: HDFS розміщує репліки на кількох стійках, тому втрата комутатора стійки не призводить до втрати кожної копії даних.