Як встановити Hadoop на UbuntuКроки завантаження та налаштування
⚡ Розумний підсумок
Встановлення Apache Hadoop на Ubuntu takes two passes: unpack the release under a dedicated system account with passwordless SSH, then edit four XML files before formatting HDFS and starting the single-node cluster.

У цьому посібнику ми покроково розглянемо процес встановлення Apache Hadoop на комп'ютер з Linux (Ubuntu). Це процес, що складається з двох частин: спочатку завантажте та встановіть реліз, а потім налаштуйте його.
Є дві передумови:
- Ви повинні бути Ubuntu встановлений і біг.
- Ви повинні бути Java встановлений.
Примітки до версії Hadoop 3.x для цієї установки
Знімки екрана в цьому покроковому посібнику були зроблені на Hadoop 2.2.0. Послідовність кроків не змінилася в поточних випусках, але деякі назви та значення за замовчуванням були переміщені. Перевірте таблицю нижче, перш ніж дослівно копіювати будь-яку команду.
| Налаштування або крок | У цьому посібнику (Hadoop 2.x) | Поточна версія Hadoop 3.x |
|---|---|---|
| Архів релізів | hadoop-2.2.0.tar.gz |
hadoop-3.5.0.tar.gz, перший стабільний реліз 3.5, опублікований 2 квітня 2026 року |
| Властивість файлової системи за замовчуванням | fs.default.name in the prose, fs.defaultFS у XML-файлі |
fs.defaultFS тільки; fs.default.name є застарілим |
| Властивість MapReduce | mapreduce.jobtracker.address |
mapreduce.framework.name встановлений в yarnРоботаTracker більше не існує, як тільки YARN планує роботу |
| mapred-site.xml | Скопійовано з mapred-site.xml.template |
Кораблі в etc/hadoop already, so the copy step is unnecessary |
| Порт веб-інтерфейсу NameNode | 50070 | 9870 |
| Java | Java 6 або Java 7 | Java 8 або Java 11 |
Все інше в цьому посібнику поводиться так само на Hadoop 3: виділений обліковий запис, ключ SSH, чотири файли конфігурації та сценарії запуску та зупинки.
Частина 1) Завантажте та встановіть Hadoop
Крок 1) Додайте користувача системи Hadoop
Додайте користувача системи Hadoop за допомогою команди нижче.
sudo addgroup hadoop_

sudo adduser --ingroup hadoop_ hduser_
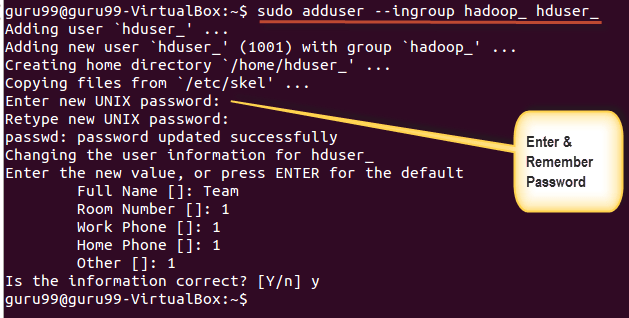
Введіть пароль, ім'я та інші дані.
ПРИМІТКА: Існує ймовірність виникнення нижчезгаданої помилки в цьому процесі налаштування та встановлення.
«hduser немає у файлі sudoers. Про цей інцидент буде повідомлено».

Цю помилку можна виправити, увійшовши в систему як користувач root.

Виконайте команду
sudo adduser hduser_ sudo

Re-login as hduser_

Крок 2) Налаштуйте SSH
Для керування вузлами в кластері Hadoop потребує доступу через SSH.
Спочатку змініть користувача, введіть таку команду
su - hduser_

Ця команда створить новий ключ.
ssh-keygen -t rsa -P ""

Enable SSH access to the local machine using this key.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
![]()
Тепер перевірте налаштування SSH, підключившись до localhost як користувач 'hduser_'.
ssh localhost

Примітка: Якщо ви бачите помилку нижче у відповідь на «ssh localhost», можливо, SSH недоступний у цій системі.

Щоб вирішити це –
Очистити SSH за допомогою,
sudo apt-get purge openssh-server
It is good practice to purge before starting the installation.

Встановіть SSH за допомогою команди-
sudo apt-get install openssh-server

Крок 3) Завантажте Hadoop
Наступний крок – завантажити Hadoop з Сторінка випусків Apache Hadoop.

Виберіть Стабільний

Виберіть файл tar.gz (не файл, що закінчується на src).

Після завершення завантаження перейдіть до каталогу, що містить tar-файл.
![]()
Enter,
sudo tar xzf hadoop-2.2.0.tar.gz
![]()
Тепер перейменуйте hadoop-2.2.0 на hadoop.
sudo mv hadoop-2.2.0 hadoop
![]()
Нарешті, передайте папку новому обліковому запису.
sudo chown -R hduser_:hadoop_ hadoop
![]()
Substitute the version you actually downloaded for hadoop-2.2.0 у трьох командах вище.
Частина 2) Налаштуйте Hadoop
Крок 1) Змініть файл ~/.bashrc
Додайте наступні рядки в кінець файлу ~/.bashrc.
#Set HADOOP_HOME export HADOOP_HOME=<Installation Directory of Hadoop> #Set JAVA_HOME export JAVA_HOME=<Installation Directory of Java> # Add bin/ directory of Hadoop to PATH export PATH=$PATH:$HADOOP_HOME/bin
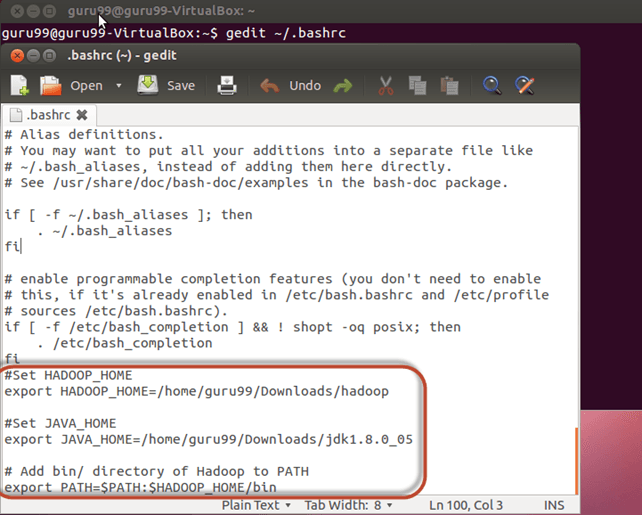
Тепер отримайте цю конфігурацію середовища за допомогою команди нижче.
. ~/.bashrc
![]()
Крок 2) Конфігурації, пов'язані з HDFS
Встановіть JAVA_HOME у файлі $HADOOP_HOME/etc/hadoop/hadoop-env.sh, як показано нижче.
![]()

З

У файлі $HADOOP_HOME/etc/hadoop/core-site.xml є два параметри, які потрібно встановити:
1. «hadoop.tmp.dir» – Використовується для визначення каталогу, який Hadoop використовуватиме для зберігання своїх файлів даних.
2. «fs.defaultFS» – це параметр, що вказує на файлову систему за замовчуванням. Старіша назва для тієї ж властивості, «fs.default.name», є застарілою.
Щоб встановити ці параметри, відкрийте core-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/core-site.xml
![]()
Copy the lines below in between the <configuration></configuration> tags.
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>

Navigate to the directory $HADOOP_HOME/etc/hadoop.

Тепер створіть каталог, згаданий у core-site.xml.
sudo mkdir -p <Path of Directory used in above setting>
![]()
Надайте дозволи для каталогу.
sudo chown -R hduser_:Hadoop_ <Path of Directory created in above step>
![]()
sudo chmod 750 <Path of Directory created in above step>
![]()
Крок 3) Налаштування MapReduce
Перш ніж розпочати ці налаштування, давайте встановимо шлях HADOOP_HOME.
sudo gedit /etc/profile.d/hadoop.sh
І Enter
export HADOOP_HOME=/home/guru99/Downloads/Hadoop

Далі введіть
sudo chmod +x /etc/profile.d/hadoop.sh
![]()
Вийдіть з терміналу та перезапустіть його.
Введіть echo $HADOOP_HOME, щоб перевірити шлях.
![]()
Тепер скопіюйте файли
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
![]()
Відкрийте файл mapred-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml
![]()
Add the settings below in between the <configuration> and </configuration> tags.
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>MapReduce job tracker runs at this host and port. </description> </property>

Відкрийте файл $HADOOP_HOME/etc/hadoop/hdfs-site.xml, як показано нижче,
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml
![]()
Додайте наведені нижче налаштування між і теги.
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>

Створіть каталог, зазначений у налаштуваннях вище.
sudo mkdir -p <Path of Directory used in above setting>
sudo mkdir -p /home/hduser_/hdfs
![]()
Потім надайте право власності та дозволи на нього.
sudo chown -R hduser_:hadoop_ <Path of Directory created in above step>
sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs
![]()
sudo chmod 750 <Path of Directory created in above step>
sudo chmod 750 /home/hduser_/hdfs
![]()
Крок 4) Форматування HDFS
Before we start Hadoop for the first time, format HDFS using the command below.
$HADOOP_HOME/bin/hdfs namenode -format

Крок 5) Запустіть одновузловий кластер Hadoop
Запустіть одновузловий кластер Hadoop за допомогою команди нижче.
$HADOOP_HOME/sbin/start-dfs.sh
Вивід вищевказаної команди показано нижче.

Потім запустіть демони YARN.
$HADOOP_HOME/sbin/start-yarn.sh

За допомогою інструменту «jps» перевірте, чи всі процеси, пов’язані з Hadoop, запущено.
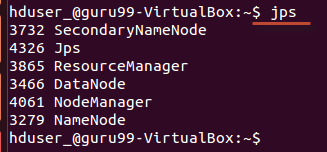
Якщо Hadoop успішно запустився, у виводі jps має бути перераховано NameNode, NodeManager, ResourceManager, SecondaryNameNode та DataNode.
Крок 6) Зупинкаping Hadoop
Shut the cluster down in the reverse order.
$HADOOP_HOME/sbin/stop-dfs.sh

$HADOOP_HOME/sbin/stop-yarn.sh

Як перевірити, чи працює Hadoop, та виправити поширені помилки
The jps output confirms that processes started, but not that the cluster is usable. Four extra checks settle that question.
- Відкрийте веб-інтерфейс NameNode за адресою
http://localhost:9870(порт 50070 на Hadoop 2.x) та підтвердьте зведені звіти про один активний вузол. - Відкрийте інтерфейс ResourceManager за адресою
http://localhost:8088щоб підтвердити, що YARN прийняв NodeManager. - прогін
hdfs dfsadmin -reportдля ємності, активних вузлів даних та будь-яких недореплікованих блоків. - Напишіть щось:
hdfs dfs -mkdir /testподальшоюhdfs dfs -ls /доводить, що простір імен приймає зміни.
Більшість невдач, що трапляються вперше, потрапляють в одну з п'яти категорій.
| симптом | Викликати | виправляти |
|---|---|---|
| JAVA_HOME не встановлено та не знайдено | Змінна експортується у .bashrc, але не у hadoop-env.sh | Також встановіть абсолютний шлях JDK всередині hadoop-env.sh |
| Відмовлено в доступі (відкритий ключ, пароль) на локальному хості ssh | authorized_keys відсутній або занадто дозвільний | Знову додайте id_rsa.pub, а потім виконайте chmod 600 на ~/.ssh/authorized_keys |
| З'єднання відмовлено на порту 22 | Сервер openssh не встановлено або не працює | Встановіть openssh-сервер та запустіть службу ssh |
| Вузла даних відсутній у JPS після переформатування | Cluster Невідповідність ідентифікаторів між відформатованим NameNode та старим каталогом DataNode | Очистіть папку dfs.datanode.data.dir, а потім ще раз відформатуйте її |
| start-dfs.sh: команду не знайдено | HADOOP_HOME та PATH ніколи не використовувалися в поточній оболонці | Запустіть .~/.bashrc або відкрийте новий термінал |