Hive Join & SubQuery Навчальний посібник із прикладами
Приєднати запити
Запити на об’єднання можна виконувати для двох таблиць у Hive. Для розуміння Приєднуйтесь Concepts зрозуміло, тут ми створюємо дві таблиці,
- Sample_joins (пов’язані з деталями клієнтів)
- Sample_joins1 (пов’язано з деталями замовлень, виконаних працівниками)
Крок 1) Створення таблиці «sample_joins» з іменами стовпців ID, Name, Age, адресою та зарплатою співробітників

Крок 2) Завантаження та відображення даних
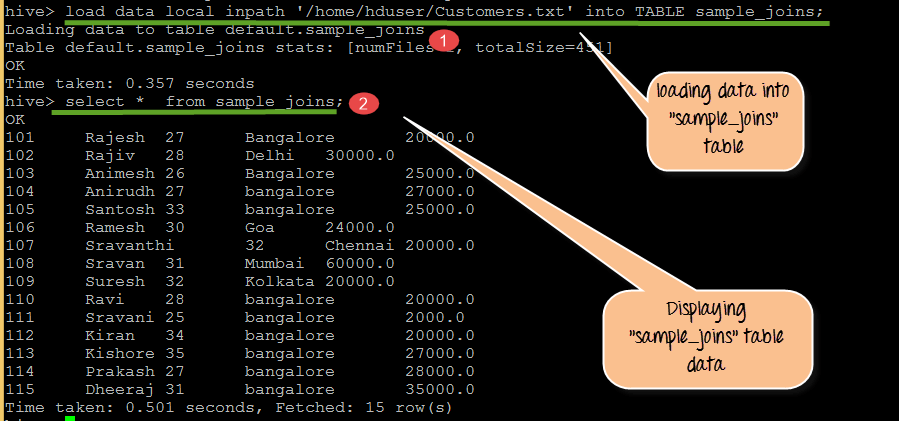
З наведеного вище знімка екрана
- Завантаження даних у sample_joins із Customers.txt
- Відображення вмісту таблиці sample_joins
Крок 3) Створення таблиці sample_joins1 і завантаження, відображення даних

З наведеного вище знімка екрана ми бачимо наступне
- Створення таблиці sample_joins1 зі стовпцями Orderid, Date1, Id, Amount
- Завантаження даних у sample_joins1 із orders.txt
- Відображення записів у sample_joins1
Рухаючись далі, ми побачимо різні типи об’єднань, які можна виконувати на створених нами таблицях, але перед цим ви повинні розглянути наступні моменти для об’єднань.
Деякі моменти, на які слід звернути увагу в Joins:
- У об’єднаннях дозволено лише об’єднання рівності
- В одному запиті можна об’єднати більше двох таблиць
- З’єднання LEFT, RIGHT, FULL OUTER існують, щоб забезпечити більше контролю над пропозицією ON, для якої немає відповідності
- Об'єднання не є комутативними
- Об’єднання є лівоасоціативними незалежно від того, є вони ЛІВИМИ чи ПРАВИМИ об’єднаннями
Різні типи з'єднань
З'єднання бувають 4 типів, це
- Внутрішнє з'єднання
- Ліве зовнішнє приєднання
- Правильне зовнішнє приєднання
- Повне Зовнішнє Приєднання
Внутрішнє з'єднання:
Записи, спільні для обох таблиць, будуть отримані за допомогою цього внутрішнього об’єднання.

З наведеного вище знімка екрана ми бачимо наступне
- Тут ми виконуємо запит на об’єднання за допомогою ключового слова JOIN між таблицями sample_joins і sample_joins1 із умовою відповідності (c.Id= o.Id).
- Результат відображає загальні записи, присутні в обох таблицях, перевіряючи умову, згадану в запиті
Запит:
SELECT c.Id, c.Name, c.Age, o.Amount FROM sample_joins c JOIN sample_joins1 o ON(c.Id=o.Id);
Ліве зовнішнє з’єднання:
- Мова запитів Hive LEFT OUTER JOIN повертає всі рядки з лівої таблиці, навіть якщо в правій таблиці немає збігів
- Якщо речення ON відповідає нулю записам у правій таблиці, об’єднання все одно повертає запис у результаті з NULL у кожному стовпці правої таблиці

З наведеного вище знімка екрана ми бачимо наступне
- Тут ми виконуємо запит на об’єднання за допомогою ключового слова «LEFT OUTER JOIN» між таблицями sample_joins і sample_joins1 із умовою відповідності (c.Id= o.Id).Наприклад тут ми використовуємо ідентифікатор працівника як довідник, він перевіряє, чи є ідентифікатор загальним у правій і лівій частині таблиці чи ні. Він діє як умова відповідності.
- Результат відображає загальні записи, присутні в обох таблицях, перевіряючи умову, згадану в запиті. Значення NULL у наведеному вище виводі є стовпцями без значень із правої таблиці, яка є sample_joins1
Запит:
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c LEFT OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
Праве зовнішнє приєднання:
- Мова запитів Hive RIGHT OUTER JOIN повертає всі рядки з правої таблиці, навіть якщо в лівій таблиці немає збігів
- Якщо речення ON відповідає нулю записам у лівій таблиці, об’єднання все одно повертає запис у результаті з NULL у кожному стовпці лівої таблиці
- Об’єднання RIGHT завжди повертає записи з правої таблиці та відповідні записи з лівої таблиці. Якщо в лівій таблиці немає значень, що відповідають стовпцю, вона поверне значення NULL у цьому місці.

З наведеного вище знімка екрана ми бачимо наступне
- Тут ми виконуємо запит на об’єднання за допомогою ключового слова «RIGHT OUTER JOIN» між таблицями sample_joins і sample_joins1 із умовою відповідності (c.Id= o.Id).
- Результат відображає загальні записи, присутні в обох таблицях, перевіряючи умову, згадану в запиті
Запит:
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c RIGHT OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
Повне зовнішнє приєднання:
Він поєднує записи обох таблиць sample_joins і sample_joins1 на основі умови JOIN, заданої в запиті.
Він повертає всі записи з обох таблиць і заповнює значення NULL для стовпців, у яких відсутні значення з обох сторін.

З наведеного вище знімка екрана ми можемо побачити наступне:
- Тут ми виконуємо запит на об’єднання за допомогою ключового слова «FULL OUTER JOIN» між таблицями sample_joins і sample_joins1 із умовою відповідності (c.Id= o.Id).
- Результат, що відображає всі записи, присутні в обох таблицях, шляхом перевірки умови, зазначеної в запиті. Нульові значення у вихідних даних тут вказують на відсутні значення в стовпцях обох таблиць.
Запит
SELECT c.Id, c.Name, o.Amount, o.Date1 FROM sample_joins c FULL OUTER JOIN sample_joins1 o ON(c.Id=o.Id)
Підзапити
Запит, присутній у Запиті, називається підзапитом. Основний запит залежатиме від значень, які повертаються підзапитами.
Підзапити можна класифікувати на два типи
- Підзапити в пункті FROM
- Підзапити в реченні WHERE
Коли користуватися:
- Щоб отримати конкретне значення, об’єднавши значення двох стовпців із різних таблиць
- Залежність значень однієї таблиці від інших таблиць
- Порівняльна перевірка значень одного стовпця з іншими таблицями
Синтаксис:
Subquery in FROM clause SELECT <column names 1, 2…n>From (SubQuery) <TableName_Main > Subquery in WHERE clause SELECT <column names 1, 2…n> From<TableName_Main>WHERE col1 IN (SubQuery);
приклад:
SELECT col1 FROM (SELECT a+b AS col1 FROM t1) t2
Тут t1 і t2 — імена таблиць. Пофарбований — підзапит, виконаний у таблиці t1. Тут a і b – це стовпці, які додаються в підзапит і присвоюються стовпцю 1. Стовпець 1 – це значення стовпця в головній таблиці. Цей стовпець «col1», присутній у підзапиті, еквівалентний запиту основної таблиці в стовпці col1.
Вбудовування власних скриптів
Вулик забезпечує можливість написання користувальницьких сценаріїв для вимог клієнта. Користувачі можуть написати власну карту та зменшити сценарії відповідно до вимог. Вони називаються вбудованими спеціальними сценаріями. Логіка кодування визначається в користувацьких сценаріях, і ми можемо використовувати цей сценарій під час ETL.
Коли вибрати вбудовані сценарії:
- Відповідно до вимог клієнта, розробники повинні писати та розгортати сценарії в Hive
- Там, де вбудовані функції Hive не працюватимуть для конкретних вимог домену
Для цього в Hive використовується речення TRANSFORM для вбудовування сценаріїв відображення та редуктора.
У цьому вбудованому користувацькому сценарії ми маємо дотримуватися наступних моментів
- Стовпці буде перетворено на рядок і розділено TAB перед тим, як передати його сценарію користувача
- Стандартний вихід сценарію користувача розглядатиметься як рядкові стовпці, розділені табуляцією
Зразок вбудованого сценарію,
FROM ( FROM pv_users MAP pv_users.userid, pv_users.date USING 'map_script' AS dt, uid CLUSTER BY dt) map_output INSERT OVERWRITE TABLE pv_users_reduced REDUCE map_output.dt, map_output.uid USING 'reduce_script' AS date, count;
З наведеного вище сценарію ми можемо помітити наступне
Це лише приклад сценарію для розуміння
- pv_users — це таблиця користувачів, яка містить такі поля, як ідентифікатор користувача та дата, як зазначено в map_script
- Сценарій скорочення, визначений для дати та кількості таблиць pv_users