Kelime Gömme ve Word2Vec Örneği
⚡ Akıllı Özet
Kelime Gömme ve Word2Vec, metni yoğun sayısal vektörlere dönüştürerek makine öğrenimi modellerinin benzer anlama sahip kelimeleri tanımasını sağlar. Bu kaynak, tekniği, CBOW ve Skip-Gram mimarilerini, aktivasyon fonksiyonlarını ve gerçek uygulamalar için eksiksiz bir Gensim uygulamasını açıklamaktadır.
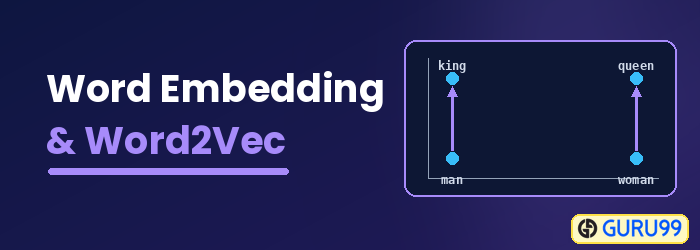
Kelime Gömme Nedir?
Kelime Gömme Kelime gömme, makine öğrenimi algoritmalarının benzer anlamlara sahip kelimeleri anlamasını sağlayan bir kelime temsil türüdür. Kelimeleri sinir ağları, olasılık modelleri veya kelime birlikte geçme matrisinde boyut indirgeme kullanarak gerçek sayılardan oluşan vektörlere eşleyen bir dil modelleme ve özellik öğrenme tekniğidir. Bazı kelime gömme modelleri Word2vec'tir (Google), GloVe (Stanford) ve fastText (Facebook).
Kelime gömme yöntemi, dağıtılmış anlamsal model, dağıtılmış temsil modeli, anlamsal vektör uzayı veya vektör uzayı modeli olarak da adlandırılır. Bu isimleri okuduğunuzda, kelimeyle karşılaşırsınız. anlamsalBu, benzer kelimeleri bir araya kategorize etmek anlamına gelir. Örneğin, elma, mango ve muz gibi meyveler birbirine yakın yerleştirilirken, kitaplar bu kelimelerden uzakta yerleştirilecektir. Daha geniş anlamda, kelime gömme, kitapların vektör temsilinden uzakta yer alan bir meyve vektörü oluşturacaktır.
Kelime Gömme nerede kullanılır?
Kelime gömme (word embedding) yöntemi, özellik oluşturma, belge kümeleme, metin sınıflandırma ve doğal dil işleme görevlerinde yardımcı olur. Bu uygulamaları listeleyelim ve her birini ayrıntılı olarak ele alalım.
- Benzer kelimeleri hesaplayın: Kelime gömme yöntemi, tahmin modeline tabi tutulan kelimeye benzer kelimeleri önermek için kullanılır. Bunun yanı sıra, benzer olmayan kelimeleri ve en yaygın kelimeleri de önerir.
- İlgili kelimelerden oluşan bir grup oluşturun: Semantik gruplar için kullanılır.pingBu yöntem, benzer özelliklere sahip şeyleri bir araya getirirken, benzer olmayan şeyleri birbirinden uzaklaştırır.
- Metin sınıflandırma özelliği: Metin, hem eğitim hem de tahmin için modele beslenen vektör dizilerine dönüştürülür. Metin tabanlı sınıflandırıcı modeller dizeler üzerinde eğitilemez, bu nedenle metin makine tarafından eğitilebilir bir forma dönüştürülür. Anlamsal yapı oluşturma özellikleri, metin tabanlı sınıflandırmaya daha da yardımcı olur.
- Belge kümeleme: Bu, Word Embedding ve Word2vec'in yaygın olarak kullanıldığı bir başka uygulama örneğidir.
- Doğal dil işleme: Kelime gömme yönteminin kullanışlı olduğu ve özellik çıkarma yöntemine göre daha üstün geldiği birçok uygulama vardır.tracSözcük türü etiketleme, duygu analizi ve sözdizimsel analiz gibi aşamalar.
Kelime gömme yönteminin nerede uygulandığını anladığınıza göre, bu gömme vektörlerini oluşturmak için kullanılan en popüler modele bakalım.
Word2vec nedir?
Word2vec Kelime temsilini iyileştirmek için kelime gömüleri üreten bir teknik veya modeldir. Çok sayıda kesin sözdizimsel ve anlamsal kelime ilişkisini yakalayan bir doğal dil işleme yöntemidir. Eğitildikten sonra eş anlamlı kelimeleri tespit edebilen ve kısmi cümleler için ek kelimeler önerebilen sığ, iki katmanlı bir sinir ağıdır.
Devam etmeden önce, lütfen aşağıdaki kelime gömme örneği diyagramında gösterildiği gibi sığ ve derin sinir ağları arasındaki farka bakın:
Sığ sinir ağları, giriş ve çıkış arasında yalnızca bir gizli katmandan oluşurken, derin sinir ağları giriş ve çıkış arasında birden fazla gizli katman içerir. Giriş düğümlere tabi tutulurken, gizli katman ve çıkış katmanı nöronlar içerir.
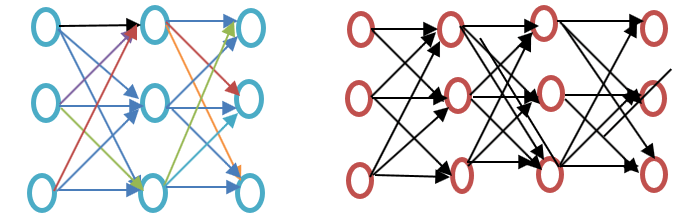
Word2vec, bir giriş, bir gizli katman ve bir çıkıştan oluşan iki katmanlı bir ağdır.
Word2vec, Tomas Mikolov liderliğindeki bir araştırma grubu tarafından geliştirilmiştir. GoogleWord2vec, latent semantik analiz modelinden daha iyi ve daha verimlidir.
Neden Word2vec?
Word2vec, kelimeleri vektör uzayında temsil eder. Kelimeler vektörler şeklinde temsil edilir ve yerleştirme, benzer anlamlı kelimelerin bir arada, farklı anlamlı kelimelerin ise uzakta yer alması şeklinde yapılır. Buna anlamsal ilişki de denir. Sinir ağları metni anlamaz; bunun yerine yalnızca sayıları anlarlar. Kelime Gömme (Word Embedding), metni sayısal bir vektöre dönüştürmenin bir yolunu sağlar.
Word2vec, kelimelerin dilsel bağlamını yeniden oluşturur. Daha ileri gitmeden önce, dilsel bağlamın ne olduğunu anlayalım. Genel bir senaryoda, iletişim kurmak için konuştuğumuzda veya yazdığımızda, diğer insanlar cümlenin amacını anlamaya çalışırlar. Örneğin, "Hindistan'ın sıcaklığı nedir?" Burada bağlam, kullanıcının "Hindistan'ın sıcaklığını" bilmek istemesidir. Kısacası, bir cümlenin temel amacı bağlamdır. Konuşulan veya yazılan dili çevreleyen kelimeler veya cümleler, bağlamın anlamını belirlemeye yardımcı olur. Word2vec, bu bağlamlar aracılığıyla kelimelerin vektör temsilini öğrenir.
Word2vec ne yapar?
Kelime Yerleştirmeden Önce
Kelime gömme yönteminden önce hangi yaklaşımın kullanıldığını ve dezavantajlarının neler olduğunu bilmek önemlidir; daha sonra Word2vec yaklaşımı kullanılarak kelime gömme yönteminin bu dezavantajları nasıl aştığını göreceğiz. Son olarak, Word2vec'in nasıl çalıştığını anlamak önemli olduğu için, çalışma prensibine geçeceğiz.
Gizli Anlamsal Analiz Yaklaşımı
Bu, kelime gömme yöntemlerinden önce kullanılan yaklaşımdır. Kelimelerin kodlanmış vektörler şeklinde temsil edildiği Kelime Torbası kavramını kullanır. Boyutu kelime dağarcığının boyutuna eşit olan seyrek bir vektör gösterimidir. Kelime sözlükte geçiyorsa sayılır; geçmiyorsa sayılmaz. Daha fazla bilgi için lütfen aşağıdaki programa bakın.
Word2vec Örneği

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Çıktı:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code açıklama
- CountVectorizer, kelimeleri içine sığdırarak kelime dağarcığını depolamak için kullanılan modüldür. Bu modül sklearn'den içe aktarılmıştır.
- CountVectorizer sınıfını kullanarak nesneyi oluşturun.
- CountVectorizer'da kullanılacak verileri listeye yazın.
- Veriler CountVectorizer sınıfından oluşturulan nesneye sığdırılır.
- Verilerdeki kelimeleri saymak için kelime torbası yaklaşımını kullanın. Bir kelime veya belirteç sözlükte mevcut değilse, ilgili indeks konumu sıfır olarak ayarlanır.
- 5. satırdaki x değişkeni bir diziye dönüştürülür (x için mevcut bir yöntem). Bu, 3. satırda verilen cümle veya listedeki her bir belirtecin sayısını sağlar.
- Bu, 4. satırdaki veriler kullanılarak uyarlandığında kelime dağarcığının parçası olan özellikleri göstermektedir.
Gizli Anlamsal yaklaşımda, satır benzersiz kelimeleri, sütun ise o kelimenin belgede kaç kez geçtiğini temsil eder. Bu, kelimelerin belge matrisi biçiminde bir gösterimidir. Terim Sıklığı-Ters Belge Sıklığı (TF-IDF), belgedeki kelime sıklığını saymak için kullanılır; bu, terimin belgedeki sıklığının, terimin tüm metin kümesindeki sıklığına bölünmesiyle elde edilir.
Kelime Çantası yönteminin eksikliği
- Kelimelerin sırasını dikkate almaz; örneğin, Bu kötü = Bu ne kadar kötü?.
- Kelimelerin bağlamını göz ardı eder. Diyelim ki “Kitapları severdi. Eğitim en iyi kitaplarda bulunur.” cümlesini yazdık. Bu, iki vektör oluşturacaktır: biri “Kitapları severdi” için, diğeri “Eğitim en iyi kitaplarda bulunur.” Her ikisini de ortogonal olarak ele alacak, bu da onları bağımsız kılacaktır, ancak gerçekte birbirleriyle ilişkilidirler.
Bu sınırlamaların üstesinden gelmek için kelime gömme yöntemi geliştirildi ve Word2vec, bu yöntemi uygulamak için kullanılan yaklaşımlardan biridir.
Word2vec nasıl çalışır?
Word2vec, bir kelimeyi çevresindeki bağlamı tahmin ederek öğrenir. Örneğin, "He" kelimesini ele alalım. seviyor Futbol."
Kelimenin Word2vec değerini hesaplamak istiyoruz: seviyor.
Sanmak:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Kelime seviyor Metin kümesindeki her kelime üzerinde hareket eder. Kelimeler arasındaki sözdizimsel ve anlamsal ilişkiler kodlanır. Bu, benzer ve analog kelimeleri bulmaya yardımcı olur.
Kelimenin tüm rastgele özellikleri seviyor Bu özellikler hesaplanır. Bu özellikler, komşu veya bağlam kelimelerine göre bir yardımıyla değiştirilir veya güncellenir. Geri Yayılım yöntemi.
Öğrenmenin bir başka yolu da, iki kelimenin bağlamları benzerse veya iki kelime benzer özelliklere sahipse, bu kelimelerin birbiriyle ilişkili olduğudur.
Word2vec Archidoku
Word2vec tarafından kullanılan iki mimari vardır:
- Sürekli Kelime Torbası (CBOW)
- atlama gramı
Daha ileri gitmeden önce, bu mimarilerin veya modellerin kelime temsili açısından neden önemli olduğunu tartışalım. Kelime temsili öğrenimi esasen denetimsizdir, ancak modeli eğitmek için hedeflere/etiketlere ihtiyaç duyulur. Skip-gram ve CBOW, denetimsiz temsili model eğitimi için denetimli bir forma dönüştürür.
CBOW'da, geçerli sözcük, çevreleyen bağlam pencerelerinin penceresi kullanılarak tahmin edilir. Örneğin, wi-1w,i-2w,i + 1w,i + 2 kelimeler veya bağlam verilirse, bu model şunları sağlayacaktır:i.
Skip-Gram, CBOW'un tam tersini yapar; yani verilen kelime dizisini veya bağlamı tahmin eder. Bunu anlamak için örneği tersine çevirebilirsiniz. Eğer wi Eğer verilirse, bu bağlamı tahmin edecektir, ya da wi-1w,i-2w,i + 1w,i + 2.
Word2vec, CBOW (Sürekli Kelime Torbası) ve skip-gram arasında seçim yapma seçeneği sunar. Bu parametreler modelin eğitimi sırasında sağlanır. Negatif örnekleme veya hiyerarşik softmax katmanı kullanma seçeneği de mevcuttur.
Sürekli Kelime Torbası
Sürekli kelime torbası mimarisini anlamak için basit bir Word2vec örnek diyagramı çizelim.

Denklemleri matematiksel olarak hesaplayalım. V'nin sözcük boyutu ve N'nin gizli katman boyutu olduğunu varsayalım. Giriş şu şekilde tanımlanır: { xi-1, xi-2, xi + 1, xi + 2 V * N ile çarparak ağırlık matrisini elde ederiz. Diğer bir matris ise giriş vektörünü ağırlık matrisiyle çarparak elde edilir. Bu durum aşağıdaki denklemle de anlaşılabilir.
h = xitW
nerede xit ve W sırasıyla giriş vektörü ve ağırlık matrisidir.
Bağlam ile sonraki kelime arasındaki eşleşmeyi hesaplamak için lütfen aşağıdaki denkleme bakın.
u = tahmin edilen temsil * h
Burada tahmin edilen temsil, yukarıdaki denklemdeki modelden elde edilir.
Gram Atlama Modeli
Skip-Gram yaklaşımı, verilen bir kelimeye göre bir cümleyi tahmin etmek için kullanılır. Bunu daha iyi anlamak için, aşağıdaki Word2vec örneğinde gösterilen diyagramı çizelim.

Bunu, girdinin kelime olduğu ve modelin bağlamı veya diziyi sağladığı Sürekli Kelime Torbası modelinin tersi olarak düşünebiliriz. Ayrıca, hedefin girdiye beslendiği ve çıktı katmanının seçilen bağlam kelime sayısını karşılamak için birden fazla kez tekrarlandığı sonucuna da varabiliriz. Tüm çıktı katmanlarından gelen hata vektörü, geri yayılım yöntemiyle ağırlıkları ayarlamak için toplanır.
Hangi modeli seçmeli?
CBOW, skip-gram'dan birkaç kat daha hızlıdır ve sık kullanılan kelimeler için daha iyi bir frekans sağlar; oysa skip-gram az miktarda eğitim verisine ihtiyaç duyar ve nadir kelimeleri veya ifadeleri bile temsil eder. Aşağıdaki tablo, her iki mimariyi de bir bakışta karşılaştırmaktadır.
| Görünüş | CBOW | Gram Atlama |
|---|---|---|
| Tahmin | Hedef kelimeyi bağlamdan tahmin eder. | Hedef kelimeden bağlamı tahmin eder. |
| Eğitim hızı | Daha hızlı | yavaş |
| sık kullanılan kelimeler | Daha yüksek doğruluk | Daha düşük doğruluk |
| Nadir kelimeler | Daha zayıf temsil | Daha güçlü temsil |
| Eğitim verileri | Daha fazla veriye ihtiyaç var. | Daha az veriyle çalışır. |
Word2vec ve NLTK arasındaki ilişki
NLTK Doğaldır Language ToolBu kit, metin ön işleme için kullanılır. Sözcük türü etiketleme, kök bulma, kök ayıklama, durdurma kelimelerini kaldırma ve nadir veya az kullanılan kelimeleri kaldırma gibi farklı işlemler gerçekleştirilebilir. Metni temizlemeye ve etkili kelimelerden özellikler hazırlamaya yardımcı olur. Öte yandan, Word2vec, anlamsal (yakından ilişkili öğeler) ve sözdizimsel (sıralama) eşleştirme için kullanılır. Word2vec kullanarak benzer kelimeleri, farklı kelimeleri, boyut indirgemeyi ve daha birçok şeyi bulabilirsiniz. Word2vec'in bir diğer önemli özelliği de metnin yüksek boyutlu gösterimini daha düşük boyutlu vektörlere dönüştürmesidir.
NLTK ve Word2vec nerede kullanılır?
Yukarıda bahsedilen tokenizasyon, POS etiketleme ve ayrıştırma gibi genel amaçlı görevleri yerine getirmek için NLTK tercih edilmelidir; ancak bağlama göre kelime tahmin etme, konu modelleme veya belge benzerliği gibi işlemler için Word2vec kullanılmalıdır.
NLTK ve Word2vec'in kod yardımıyla ilişkisi
NLTK ve Word2vec, benzer kelime temsillerini veya sözdizimsel eşleşmeyi bulmak için birlikte kullanılabilir. NLTK araç seti, NLTK ile birlikte gelen birçok paketi yüklemek için kullanılabilir ve Word2vec kullanılarak bir model oluşturulabilir. Daha sonra bu model gerçek zamanlı kelimeler üzerinde test edilebilir. Aşağıdaki kodda ikisinin birleşimini görelim. Daha fazla işleme geçmeden önce, lütfen NLTK'nın sağladığı veri kümelerine göz atın. Bunları şu komutla indirebilirsiniz:
nltk(nltk.download('all'))

Lütfen kod için ekran görüntüsüne bakın.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Çıktı:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Açıklaması Code
- nltk kütüphanesi içe aktarıldı; buradan bir sonraki adımda kullanacağımız abc metin kümesini indirebilirsiniz.
- Gensim içe aktarıldı. Eğer Gensim Word2vec kurulu değilse, lütfen "pip3 install gensim" komutunu kullanarak kurun. Lütfen aşağıdaki ekran görüntüsüne bakın.

- nltk.download('abc') komutu kullanılarak indirilen abc metin kümesini içe aktarın.
- Dosyaları, Gensim kullanılarak cümleler halinde içe aktarılan Word2vec modeline iletin.
- Sözlük, bir değişken biçiminde saklanır.
- Model, örnek kelime üzerinde test edilmiştir. BilimÇünkü bu dosyalar bilimle ilgili.
- Burada, model tarafından "bilim" kelimesinin benzeri tahmin ediliyor.
Aktivatörler ve Word2Vec
Bir nöronun aktivasyon fonksiyonu, belirli bir girdi kümesi verildiğinde o nöronun çıktısını tanımlar. Biyolojik olarak, farklı nöronların farklı uyaranlar kullanılarak aktive edildiği beynimizdeki aktiviteden esinlenilmiştir. Aşağıdaki diyagram aracılığıyla aktivasyon fonksiyonunu anlayalım.

Burada x1, x2, … x4 sinir ağının düğümleridir.
w1, w2, w3 düğümlerin ağırlıklarıdır.
Tüm ağırlıkların ve düğüm değerlerinin toplamı (Σ), aktivasyon fonksiyonu olarak işlev görür.
Neden Etkinleştirme işlevi?
Eğer aktivasyon fonksiyonu kullanılmazsa, çıktı doğrusal olur, ancak doğrusal bir fonksiyonun işlevselliği sınırlıdır. Nesne tespiti, görüntü sınıflandırması gibi karmaşık işlevleri elde etmek için,ping Ses kullanarak metin oluşturma ve diğer birçok doğrusal olmayan çıktı için bir etkinleştirme fonksiyonuna ihtiyaç duyulmaktadır.
Kelime yerleştirmede aktivasyon katmanı nasıl hesaplanır (Word2vec)
Softmax Katmanı (normalleştirilmiş üstel fonksiyon), her düğümü etkinleştiren veya tetikleyen çıkış katmanı fonksiyonudur. Kullanılan bir diğer yaklaşım ise Hiyerarşik softmax'tır; burada karmaşıklık O(log) olarak hesaplanır.2Softmax'te ise bu karmaşıklık O(V)'dir; burada V, kelime dağarcığı boyutudur. Aralarındaki fark, hiyerarşik softmax katmanındaki karmaşıklığın azalmasıdır. İşlevselliğini anlamak için lütfen aşağıdaki Kelime gömme örneğine bakın:

Kelimeyi gözlemleme olasılığını hesaplamak istediğimizi varsayalım. Aşk Belirli bir bağlam verildiğinde, kök düğümden yaprak düğüme giden akış önce 2. düğüme, ardından 5. düğüme geçecektir. Dolayısıyla, 8 kelimelik bir kelime dağarcığımız varsa, yalnızca üç hesaplama gereklidir. Bu, bir kelimenin olasılığının hesaplanmasını parçalara ayırmayı sağlar (Aşk).
Hiyerarşik Softmax dışında başka hangi seçenekler mevcut?
Genel anlamda, mevcut kelime gömme seçenekleri şunlardır: Farklılaştırılmış Softmax, CNN-Softmax, Önem Örneklemesi, Uyarlanabilir Önem Örneklemesi, Gürültü Kontrastlı Tahmini, Negatif Örnekleme, Kendiliğinden Normalizasyon ve Seyrek Normalizasyon.
Özellikle Word2vec'ten bahsedecek olursak, negatif örnekleme seçeneğimiz mevcuttur.
Negatif örnekleme, eğitim verilerini örneklemenin bir yoludur. Stokastik gradyan inişine biraz benzer, ancak bazı farklılıkları vardır. Negatif örnekleme yalnızca negatif eğitim örneklerini arar. Gürültü karşılaştırmalı tahminine dayanır ve bağlamda olmayan kelimeleri rastgele örnekler. Hızlı bir eğitim yöntemidir ve bağlamı rastgele seçer. Tahmin edilen kelime rastgele seçilen bağlamda görünüyorsa, her iki vektör de birbirine yakındır.
Ne gibi bir sonuç çıkarılabilir?
Aktivatörler, tıpkı dış uyaranlarla nöronlarımızın ateşlenmesi gibi, nöronları ateşler. Softmax katmanı, kelime gömme durumunda nöronları ateşleyen çıktı katmanı fonksiyonlarından biridir. Word2vec'te hiyerarşik softmax ve negatif örnekleme gibi seçeneklerimiz mevcuttur. Aktivatörler kullanılarak, doğrusal bir fonksiyon doğrusal olmayan bir fonksiyona dönüştürülebilir ve bu tür fonksiyonlar kullanılarak karmaşık bir makine öğrenme algoritması uygulanabilir.
Gensim nedir?
gensim uygulanan açık kaynaklı bir konu modelleme ve doğal dil işleme araç setidir. Python ve Cython. Gensim araç seti, kullanıcıların metin gövdesindeki gizli yapıyı keşfetmek için konu modellemesi amacıyla Word2vec'i içe aktarmalarına olanak tanır. Gensim, yalnızca Word2vec'in değil, aynı zamanda Doc2vec ve FastText'in de bir uygulamasını sunar.
Bu bölüm Word2vec'e odaklanmıştır, bu nedenle mevcut konuya bağlı kalacağız.
Gensim Kullanılarak Word2vec Nasıl Uygulanır?
Şimdiye kadar Word2vec'in ne olduğunu, farklı mimarilerini, kelime torbasından Word2vec'e geçişin nedenlerini, Word2vec ile NLTK arasındaki ilişkiyi (canlı kod kullanımıyla birlikte) ve aktivasyon fonksiyonlarını ele aldık.
Aşağıda Gensim kullanarak Word2vec'i uygulamak için adım adım yöntem verilmiştir:
Adım 1) Veri Toplama
Herhangi bir makine öğrenimi modelini uygulamaya koymanın veya doğal dil işlemeyi gerçekleştirmenin ilk adımı veri toplamadır.
Aşağıdaki Gensim Word2vec örneğinde gösterildiği gibi akıllı bir chatbot oluşturmak için lütfen verileri inceleyin.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Verilerden anladığımız kadarıyla durum şöyle:
- Bu veriler üç şey içerir: etiket, desen ve yanıtlar. Etiket, amacı (tartışmanın konusu nedir) belirtir.
- Veriler JSON formatındadır.
- Desen, kullanıcıların bota soracağı bir sorudur.
- Yanıtlar, sohbet robotunun ilgili soru/desen için vereceği cevaplardır.
Adım 2) Veri ön işleme
Ham verinin işlenmesi çok önemlidir. Temizlenmiş veriler makineye beslenirse model daha doğru yanıt verecek ve verileri daha verimli öğrenecektir.
Bu adımda durdurma sözcüklerini kaldırma, kök sözcük bulma, gereksiz sözcükleri ayıklama vb. işlemler yer almaktadır. Devam etmeden önce, verileri yüklemek ve bir veri çerçevesine dönüştürmek önemlidir. Bunun için lütfen aşağıdaki koda bakın.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Açıklaması Code:
- Veriler JSON formatında olduğundan, JSON dosyaları içe aktarılıyor.
- Dosya değişkene kaydedilir.
- Dosya açıldı ve veri değişkenine yüklendi.
Veriler artık içe aktarıldı ve verileri bir veri çerçevesine dönüştürme zamanı geldi. Sonraki adım için lütfen aşağıdaki koda bakın.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Açıklaması Code:
1. Veriler, yukarıda içe aktarılan pandas kullanılarak bir veri çerçevesine dönüştürülür.
2. Sütundaki "patterns" listesini bir dizeye dönüştürür.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Açıklama:
1. İngilizce durdurma sözcükleri, nltk araç setindeki durdurma sözcüğü modülü kullanılarak içe aktarılır.
2. Metnin tüm kelimeleri, bir for döngüsü ve bir lambda fonksiyonu kullanılarak küçük harfe dönüştürülür. A Lambda işlevi anonim bir işlevdir.
3. Veri çerçevesindeki metnin tüm satırları noktalama işaretleri açısından kontrol edilir ve bu işaretler filtrelenir.
4. Sayılar veya noktalar gibi karakterler, normal bir ifade kullanılarak kaldırılır.
5. Digit'ler metinden çıkarıldı.
6. Durdurucu kelimeler bu aşamada kaldırılır.
7. Kelimeler filtreleniyor ve aynı kelimenin farklı biçimleri kök sözcük bulma yöntemiyle kaldırılıyor. Böylece veri ön işleme tamamlanmış oluyor.
Çıktı:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Adım 3) Word2vec kullanarak Sinir Ağı oluşturma
Şimdi Gensim Word2vec modülünü kullanarak bir model oluşturmanın zamanı geldi. Word2vec'i Gensim'den içe aktarmamız gerekiyor. Bunu yapalım, ardından modeli derleyelim ve son aşamada modeli gerçek zamanlı veriler üzerinde test edelim.
from gensim.models import Word2Vec
Artık Word2Vec kullanarak modeli başarıyla oluşturabiliriz. Word2Vec kullanarak model oluşturmayı öğrenmek için lütfen bir sonraki kod satırına bakın. Metin modele liste şeklinde sağlandığı için, aşağıdaki kodu kullanarak veri çerçevesindeki metni listeye dönüştüreceğiz.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Açıklaması Code:
1. İç içe geçmiş listenin eklendiği daha büyük bir liste oluşturuldu. Bu, Word2Vec modeline beslenen formattır.
2. Bir döngü oluşturulur ve veri çerçevesinin "patterns" sütunundaki her bir girdi üzerinde yineleme yapılır.
3. Sütun kalıplarının her bir öğesi bölünür ve içteki li listesine kaydedilir.
4. İçteki liste, dıştaki listeye eklenir.
5. Bu liste Word2Vec modeline sağlanmıştır. Burada verilen bazı parametreleri anlayalım.
Min_count: Bu değerden daha düşük toplam frekansa sahip tüm kelimeleri yok sayar.
Alan: Kelime vektörlerinin boyutluluğunu anlatır.
İşçiler: Bunlar, modeli eğitmek için kullanılan kod parçalarıdır.
Başka seçenekler de mevcuttur ve bunlardan bazı önemli olanları aşağıda açıklanmıştır.
penceresi: Bir cümle içindeki mevcut ve tahmin edilen kelime arasındaki maksimum mesafe.
Sg: Bu bir eğitim algoritmasıdır: 1, skip-gram için; 0 ise Sürekli Kelime Torbası (Continuous Bag of Words) için kullanılır. Bunları yukarıda detaylı olarak ele aldık.
Hs: Bu değer 1 ise, eğitim için hiyerarşik softmax kullanıyoruz; 0 ise, negatif örnekleme kullanılıyor.
Alfa: İlk öğrenme oranı.
Son kodu aşağıda görüntüleyelim:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Adım 4) Model kaydetme
Model, ikili dosya (bin) ve model dosyası şeklinde kaydedilebilir. İkili dosya (bin) ikili veri biçimidir. Modeli kaydetmek için lütfen aşağıdaki satırlara bakın.
model.save("word2vec.model") model.save("model.bin")
Yukarıdaki kodun açıklaması
1. Model, .model dosyası biçiminde kaydedilir.
2. Model, .bin dosyası biçiminde kaydedilir.
Bu modeli, benzer kelimeler, farklı kelimeler ve en sık kullanılan kelimeler gibi gerçek zamanlı testler yapmak için kullanacağız.
Adım 5) Modelin yüklenmesi ve gerçek zamanlı testin gerçekleştirilmesi
Model aşağıdaki kod kullanılarak yüklenir:
model = Word2Vec.load('model.bin')
Eğer bu dosyadan kelime hazinesini yazdırmak istiyorsanız, aşağıdaki komutu kullanabilirsiniz:
vocab = list(model.wv.vocab)
Lütfen sonuca bakın:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Adım 6) En Benzer Kelimelerin Kontrolü
Gelin şunları uygulamalı olarak uygulayalım:
similar_words = model.most_similar('thanks') print(similar_words)
Lütfen sonuca bakın:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Adım 7) Sağlanan kelimelerdeki kelime eşleşmiyor
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Kelimeleri verdik 'Görüşmek üzere, ziyaretiniz için teşekkürler.'Bu kod, bu kelimeler arasından en az benzer olan kelimeyi yazdırır. Hadi bu kodu çalıştıralım ve sonucu bulalım.
Yukarıdaki kodun yürütülmesinden sonraki sonuç:
Thanks
Adım 8) İki kelime arasındaki benzerliği bulma
Bu, iki kelime arasındaki benzerlik olasılığı cinsinden sonucu gösterir. Bu bölümün nasıl çalıştırılacağına dair bilgi için lütfen aşağıdaki koda bakın.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Yukarıdaki kodun sonucu aşağıdaki gibidir:
0.13706
Aşağıdaki kodu çalıştırarak benzer kelimeleri daha detaylı olarak bulabilirsiniz:
similar = model.similar_by_word('kind') print(similar)
Yukarıdaki kodun çıktısı:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]