Scikit-Learn Eğitimi: Nasıl Kurulur ve Scikit-Learn Örnekleri
⚡ Akıllı Özet
Scikit-learn açık kaynaklı bir yazılımdır. Python Veri ön işleme, sınıflandırma, regresyon, kümeleme ve model seçimini tek bir tutarlı tahminci arayüzü altında birleştiren kütüphane; bu sayede ham verilerden puanlanmış tahminlere kadar eksiksiz bir makine öğrenimi iş akışı kısa, okunabilir ve tekrarlanabilir hale gelir.

Scikit-learn nedir?
Scikit-öğrenme açık kaynaklı Python için kütüphane makine öğrenmeKNN, gradyan artırma, rastgele orman ve SVM gibi iyi bilinen algoritmaları destekler ve bunların üzerine inşa edilmiştir. Dizi Scikit-learn, Kaggle yarışmalarında ve önde gelen teknoloji şirketlerinde yaygın olarak kullanılmaktadır. Ön işleme, boyut indirgeme, sınıflandırma, regresyon, kümeleme ve model seçimi gibi konuları kapsar.
Scikit-learn, açık kaynaklı kütüphaneler arasında en iyi dokümantasyona sahip olanlardan biridir. Hatta etkileşimli bir tahmin grafiği bile sunmaktadır. Doğru tahminciyi seçmekBu, veri setinizin boyutundan yola çıkarak denemeye değer algoritmaların kısa bir listesini oluşturmanıza yardımcı olur.
Aşağıdaki şekil, Scikit-learn'ün nasıl çalıştığını göstermektedir.
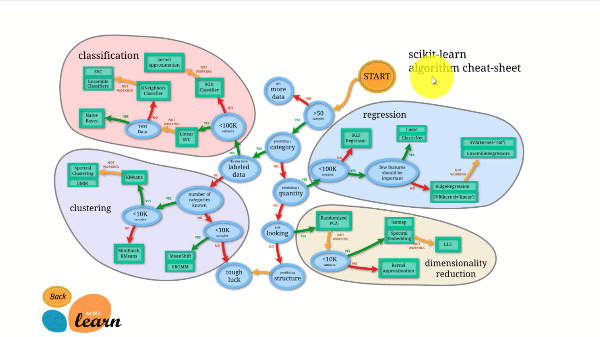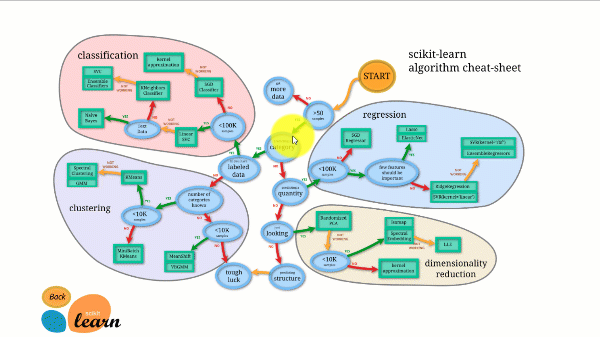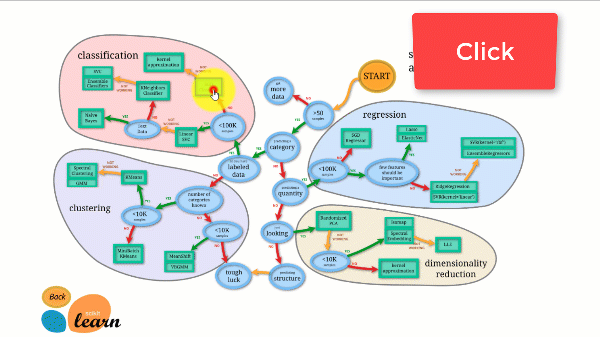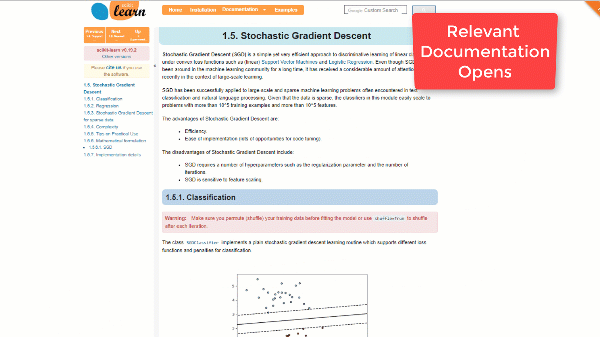
Scikit-learn kullanımı zor değildir ve mükemmel sonuçlar verir. Ancak, işlemci üzerinde eğitim yapar: iş, GPU yerine n_jobs argümanı ile çekirdekler arasında paralelleştirilir. Bununla derin öğrenme algoritması çalıştırmak mümkündür, ancak özellikle nasıl kullanılacağını zaten biliyorsanız, nadiren en uygunudur. TensorFlow.
Scikit-learn Nasıl İndirilir ve Kurulur
Şimdi bunda Python Bu Scikit-learn eğitiminde, Scikit-learn'ü nasıl indirip kuracağınızı öğreneceksiniz:
Seçenek 1: AWS
Scikit-learn, AWS üzerinde kullanılabilir. Scikit-learn'ün önceden yüklendiği bir Docker imajı, kurulum işini tamamen ortadan kaldırır.
Geliştirici sürümünü yüklemek için aşağıdaki komutu çalıştırın. Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Seçenek 2: Mac veya Windows Anaconda'yı kullanma
Anaconda kurulumu hakkında bilgi edinmek için lütfen şuraya bakın: TensorFlow nasıl indirilir ve kurulur?.
Bu kılavuz yazıldığı sırada scikit geliştiricileri, o zamanki mevcut sürümde bulunan sorunları gideren bir geliştirme sürümü yayınlamıştı, bu nedenle aşağıdaki adımlar bu geliştirme sürümünü kullanmaktadır. Bugün yeni bir makinede, mevcut kararlı sürüm zaten burada kullanılan tüm dönüştürücüleri içermektedir ve pip install -U scikit-learn yeterlidir.
Conda Environment ile scikit-learn nasıl kurulur
Scikit-learn'ü conda ortamıyla kurduysanız, 0.20 sürümüne güncellemek için aşağıdaki adımları izleyin.
Adım 1) TensorFlow ortamını etkinleştirin.
source activate hello-tf
Adım 2) conda komutunu kullanarak scikit-learn'ü kaldırın.
conda remove scikit-learn
3. Adım) Geliştirici sürümünü yükleyin
Gerekli kütüphanelerle birlikte scikit-learn geliştirici sürümünü yükleyin.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
NOT: Windows kullanıcıların ihtiyacı var Microsoft Görsel C++ 14. Bunu alabilirsiniz. okuyun.
Makine Öğrenimi ile Scikit-Learn Örneği
Bu Scikit eğitimi iki bölüme ayrılmıştır:
- Scikit-learn ile makine öğrenimi
- LIME ile modelinize nasıl güvenebilirsiniz?
Birinci bölüm, bir işlem hattı oluşturmayı, bir model yaratmayı ve hiperparametreleri ayarlamayı ayrıntılı olarak ele alırken, ikinci bölüm model yorumlamasını kapsamaktadır.
Adım 1) Verileri içe aktarın
Bu Scikit learn eğitiminde yetişkin nüfus sayımı veri setini kullanacaksınız.
Aşağıdaki kodda dosya doğrudan UCI Makine Öğrenimi Deposundan okunmaktadır, bu nedenle manuel indirmeye gerek yoktur. Tanımlayıcı istatistiklerle ilgileniyorsanız, Dive ve Overview araçlarına göz atmaya değer. Bkz. Bu eğitimde Dalış ve Genel Bakış hakkında daha fazla bilgi edinmek için.
Veri setini pandas ile içe aktarıyorsunuz. Sürekli değişkenleri ondalık sayı formatına dönüştürmeniz gerektiğini unutmayın.
Bu veri seti, CATE_FEATURES'da listelenen sekiz kategorik değişken içermektedir:
- çalışma sınıfı
- eğitim
- evlilik
- işgal
- ilişki
- yarış
- seks
- ana vatan
Ayrıca CONTI_FEATURES'da listelenen altı sürekli değişkeni de içerir:
- yaş
- fnlwgt
- eğitim_num
- Sermaye kazancı
- sermaye_kaybı
- saat_hafta
Burada listeler elle dolduruluyor, böylece hangi sütunların kullanıldığını daha net bir şekilde görebilirsiniz. Kategorik veya sürekli sütunların listesini oluşturmanın daha hızlı bir yolu şöyledir:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Verileri içe aktarmak için gereken kod:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
Çerçeve üzerinde describe() işlevini çağırmak, altı ardışık sütun için özet istatistikleri döndürür:
| yaş | fnlwgt | eğitim_num | Sermaye kazancı | sermaye_kaybı | saat_hafta | |
|---|---|---|---|---|---|---|
| saymak | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| ortalama | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| dk | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| maksimum | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
native_country özelliğinin benzersiz değerlerinin sayısını kontrol edebilirsiniz. Sadece bir hane Hollanda'dan geliyor. Bu hane hiçbir bilgi içermiyor ve eğitim sırasında hata verecektir.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Bu bilgilendirici olmayan satırı veri kümesinden çıkarabilirsiniz:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Daha sonra sürekli özelliklerin konumunu bir listede saklarsınız. Boru hattını oluşturmak için bir sonraki adımda buna ihtiyacınız olacak.
Aşağıdaki kod, CONTI_FEATURES tablosundaki tüm sütun adlarını döngüye alarak her bir konumu (yani sütun numarasını) okur ve bunu conti_features adlı bir listeye ekler.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
Sonraki blok, kategorik değişkenler için aynı işlemi gerçekleştirir.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Şimdi veri setinin kendisine bakalım. Her kategorik özellik bir metin dizesidir ve bir modele metin dizesi değeri verilemez, bu nedenle veri seti kukla değişkenlerle dönüştürülmelidir.
df_train.head(5)
Aslında, her özellik için her gruba bir sütun gerekiyor. Öncelikle, gereken toplam sütun sayısını hesaplamak için aşağıdaki kodu çalıştırın.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
Yukarıda gösterildiği gibi, veri setinin tamamı 101 grup içermektedir. Sadece "iş sınıfı" özelliği bile dokuz gruba sahiptir. Aşağıdaki kodla grupların adlarını listeleyebilirsiniz; unique() fonksiyonu her kategorik özelliğin farklı değerlerini döndürür.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Bu nedenle eğitim veri seti 101 + 6 sütun içerecektir: tekil kodlama grupları artı altı sürekli özellik.
Scikit-learn, dönüştürme işlemini iki adımda halledebilir:
- Dizeyi bir kimliğe dönüştürün. State-gov, ID 1 olur; Self-emp-not-inc, ID 2 olur ve bu şekilde devam eder. LabelEncoder bunu sizin için yapar.
- Her bir kimlik numarasını yeni bir sütuna taşıyın. Veri setinde 101 grup kimlik numarası olduğundan, her kategorik özellik grubunu yakalayan 101 sütun olacaktır. Scikit-learn bu işlem için OneHotEncoder'ı sağlar.
Adım 2) Eğitim/test setini oluşturun
Veri seti hazır olduğuna göre, onu 80/20 oranında bölün: %80'i eğitim seti, %20'si test seti.
`train_test_split` fonksiyonunu kullanabilirsiniz. İlk argüman özelliklerin veri çerçevesi, ikincisi ise etikettir. Test setinin boyutunu `test_size` ile ayarlarsınız.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Adım 3) Boru hattını oluşturun
Bu işlem hattı, modele tutarlı verilerle beslemeyi kolaylaştırır. Buradaki fikir, ham verileri her işlemi sırayla gerçekleştiren tek bir nesne üzerinden geçirmektir.
Bu veri setiyle, sürekli değişkenleri standartlaştırmanız ve kategorik değişkenleri dönüştürmeniz gerekiyor. Herhangi bir işlem bir işlem hattı içinde yer alabilir: eksik değerler ortalama veya medyan ile değiştirilebilir ve yeni değişkenler oluşturulabilir.
İki seçeneğiniz var: iki işlemi de doğrudan kodlayabilirsiniz veya bir işlem hattı oluşturabilirsiniz. Doğrudan kodlama, test verilerinin istatistiklere sızmasına ve zaman içinde tutarsızlıklara yol açabilir, bu nedenle işlem hattı daha iyi bir seçenektir.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Bu işlem hattı, lojistik sınıflandırıcıya veri göndermeden önce iki işlem gerçekleştirir:
- Değişkeni standartlaştır: StandardScaler()
- Kategorik özellikleri dönüştürün: OneHotEncoder(sparse=False)
Her iki adımı da `make_column_transformer` fonksiyonuyla gerçekleştiriyorsunuz. Bu kılavuz yazıldığında, bu fonksiyon scikit-learn'ün yayınlanmış sürümünde (0.19) bulunmuyordu, bu nedenle geliştirici sürümü kullanıldı; 0.20'den beri her kararlı sürümde yer almaktadır.
`make_column_transformer` oldukça basittir: Hangi sütunları dönüştüreceğinizi ve hangi dönüşümü uygulayacağınızı belirtirsiniz. Sürekli özellikleri standartlaştırmak için şunları geçirirsiniz:
- make_column_transformer içindeki conti_features, StandardScaler()
- conti_features: ardışık sütunların listesi
- StandardScaler: bu sütunları standartlaştırır.
`make_column_transformer` içindeki `OneHotEncoder` nesnesi etiketleri otomatik olarak kodlar.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Sürüm notu: Yukarıdaki bloktaki iki argüman ilerledi. Mevcut sürümler önce transformatörü, sonra kolonları bekliyor ve seyrek yeniden adlandırıldı seyrek_çıktı scikit-learn 1.2'de vardı ve 1.4'te kaldırıldı, bu nedenle daha yeni kod şu şekilde okunuyor: OneHotEncoder(sparse_output=False).
İşlem hattının çalışıp çalışmadığını fit_transform ile test edebilirsiniz. Çıktının 26048, 107 şeklinde olması gerekir.
preprocess.fit_transform(X_train).shape
(26048, 107)
Veri dönüştürücü hazır. `make_pipeline` komutuyla işlem hattını oluşturuyorsunuz ve veriler dönüştürüldükten sonra lojistik regresyona besliyorsunuz.
model = make_pipeline(
preprocess,
LogisticRegression())
Scikit-learn ile bir model eğitmek oldukça kolaydır: işlem hattında fit fonksiyonunu çağırın. Doğruluk oranını score metodu ile yazdırabilirsiniz.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Son olarak, her sınıfın olasılığını döndüren predict_proba fonksiyonu ile sınıfları tahmin edebilirsiniz. İki olasılığın toplamının bire eşit olduğunu unutmayın.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Adım 4) Izgara aramasında boru hattımızı kullanma
Modelin yapısını belirleyen değerler olan hiperparametrelerin ayarlanması zahmetli ve yorucu olabilir.
Modeli değerlendirmenin bir yolu, eğitim veri setinin boyutunu değiştirmek ve performansı ölçmek, bu işlemi on kez tekrarlayarak puan dağılımını görmektir. Bu çok fazla manuel çalışma gerektirir.
Bunun yerine, scikit-learn sizin için parametre ayarlaması ve çapraz doğrulama işlemlerini gerçekleştiren fonksiyonlar sunar.
Çapraz doğrulama
Çapraz doğrulama, eğitim sırasında eğitim veri setinin n kez katmanlara ayrılması ve modelin n kez değerlendirilmesi anlamına gelir. Eğer cv 10 olarak ayarlanırsa, model on kez eğitilir ve değerlendirilir. Her turda sınıflandırıcı rastgele seçilen dokuz katman üzerinde eğitilir ve onuncu katman değerlendirme için saklanır.
ızgara arama
Her sınıflandırıcının ayarlanabilecek hiperparametreleri vardır. Değerleri tek tek deneyebilir veya bir parametre ızgarası ayarlayabilirsiniz. scikit-learn dokümantasyonu, lojistik sınıflandırıcının kabul ettiği tüm parametreleri listeler. Eğitimi hızlı tutmak için, bu örnek yalnızca düzenlemeyi kontrol eden C parametresini ayarlar. Bu parametre pozitif olmalıdır ve küçük bir değer, düzenleyiciye daha fazla ağırlık verir.
GridSearchCV nesnesini kullanırsınız; bu nesne, ayarlanacak hiperparametrelerin bir sözlüğünü alır. Her hiperparametreyi ve denemek istediğiniz değerleri listeleyin. C'yi ayarlamak için şunu yazarsınız:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — parametre adının önüne küçük harflerle yazılmış sınıflandırıcı adı ve iki alt çizgi eklenmiştir.
Model dört farklı değer deneyecek: 0.001, 0.01, 0.1 ve 1. 10 katlı çapraz doğrulama (cv=10) ile eğitiliyor.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Artık GridSearchCV fonksiyonunu grid ve cv parametreleriyle kullanarak modeli eğitebilirsiniz.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Çıktı:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Sürüm notu: the kimlik Bu çıktıda görünen argüman, scikit-learn 0.22 sürümünde kullanımdan kaldırılmış ve 0.24 sürümünde tamamen silinmiştir; bu nedenle mevcut sürümlerde GridSearchCV çağrısından basitçe çıkarılmalıdır.
En iyi parametrelere erişmek için best_params_ ifadesini kullanırsınız.
grid_clf.best_params_
Çıktı:
{'logisticregression__C': 1.0}
Modeli dört farklı düzenleme değeriyle eğittikten sonra, en uygun parametre şu şekilde elde edilir:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
grid aramasından en iyi lojistik regresyon: 0.850891
Tahmin edilen olasılıklara erişmek için:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
Scikit-learn ile XGBoost Modeli
Şimdi piyasadaki en güçlü sınıflandırıcılardan birini deneyelim. XGBoost, rastgele orman algoritmasının gradyan artırma yöntemiyle geliştirilmiş bir versiyonudur. Teorik altyapısı bu yazının kapsamı dışındadır. Python Scikit eğitimine bakabilirsiniz, ancak XGBoost'un birçok Kaggle yarışmasını kazandığını unutmayın. Ortalama büyüklükteki bir veri kümesinde, derin öğrenme algoritması kadar iyi veya daha iyi performans gösterebilir.
Sınıflandırıcıyı eğitmek zordur çünkü çok sayıda parametre içerir. Elbette, bu parametreleri sizin için seçmesi için GridSearchCV'yi kullanabilirsiniz.
Burada daha iyi bir seçenek RandomizedSearchCV'dir. GridSearchCV, ızgara büyük olduğunda yavaşlar çünkü arama alanı eklenen her parametreyle birlikte büyür. RandomizedSearchCV ise her yinelemede her hiperparametrenin değerlerini rastgele örnekler, böylece 1,000 yineleme 1,000 kombinasyonu değerlendirir. Bunun dışında GridSearchCV'ye çok benzer şekilde çalışır.
xgboost kütüphanesini içe aktarmanız gerekiyor. Eğer kütüphane kurulu değilse, pip3 install xgboost komutunu çalıştırın veya bir dosya içinden kurun. Jupyter İçinde şunlar bulunan bir defter:
use import sys
!{sys.executable} -m pip install xgboost
Ardından sınıflandırıcıyı ve iki arama yardımcısını içe aktarın:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Bu Scikit'teki bir sonraki adım Python Bu eğitimde amaç, ayarlanacak parametreleri belirtmektir. Resmi XGBoost dokümanında bunların tümü listelenmiştir. Bu eğitimin amacı doğrultusunda, Python Sklearn eğitiminde, XGBoost'un eğitimi uzun sürdüğü ve her ekstra ızgara noktasının bekleme süresini uzattığı için, her biri iki değere sahip yalnızca iki hiperparametre seçiyorsunuz.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Ardından XGBoost sınıflandırıcı ve 600 tahminleyici ile yeni bir işlem hattı oluşturursunuz. n_estimators değeri ayarlanabilir ve yüksek bir değer aşırı uyumlanmaya yol açabilir. Başka değerler de deneyebilirsiniz, ancak bunun saatler sürebileceğini unutmayın. Diğer tüm parametreler varsayılan değerlerini korur.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Katmanlı K-Katlı çapraz doğrulama yöntemiyle çapraz doğrulamayı iyileştirebilirsiniz. Burada hesaplamayı hızlandırmak için sadece üç katman kullanılmıştır, bu da kalite açısından bir miktar kayba yol açar; daha iyi sonuçlar için kendi makinenizde bunu 5 veya 10'a çıkarın. Model dört yineleme üzerinden eğitilir.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Rastgele arama hazır, artık modeli eğitebilirsiniz.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Gördüğünüz gibi, XGBoost, önceki lojistik regresyondan daha iyi performans gösteriyor.
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Scikit-learn'de MLPClassifier ile DNN oluşturun
Son olarak, scikit-learn'ün kendisiyle bir sinir ağı eğitebilirsiniz. Yöntem, diğer sınıflandırıcılar için olduğu gibidir ve tahminleyici MLPClassifier'dır.
from sklearn.neural_network import MLPClassifier
Aşağıdaki ağ şu şekilde tanımlanmıştır:
- Adem çözücü
- ReLU aktivasyon işlevi
- Alfa = 0.0001
- Parti büyüklüğü 150
- Sırasıyla 200 ve 100 nöronlu iki gizli katman
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Modelin performansını artırmak için katman sayısını değiştirebilirsiniz.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN regresyon puanı: 0.821253
LIME: Modelinize Güvenin
Artık iyi bir modeliniz olduğuna göre, ona güvenmenin bir yoluna ihtiyacınız var. Makine öğrenimi algoritmaları, özellikle rastgele ormanlar ve sinir ağları, kara kutu modelleri olarak bilinir: çalışırlar, ancak kimse neden çalıştıklarını göremez.
Üç araştırmacı, bilgisayarın bir tahmine nasıl ulaştığını gösteren bir araç geliştirdi. Makaleleri şu şekildedir: “Sana neden güvenmeliyim?”Yayınladıkları algoritma ise Yerel Yorumlanabilir Modelden Bağımsız Açıklamalar (LIME) olarak adlandırılıyor.
Bir örnek verelim. Bazen bir makine öğrenimi tahmininin güvenilir olup olmadığını bilemezsiniz. Bir doktor, bir bilgisayarın ürettiği bir teşhisi sırf bu yüzden kabul edemez ve bir modeli üretime geçirmeden önce güvenilir olup olmadığını bilmeniz gerekir.
Karmaşık sinir ağları, rastgele ormanlar veya keyfi çekirdeğe sahip SVM'ler gibi modeller için bile, herhangi bir sınıflandırıcının neden bir tahminde bulunduğunu görebildiğinizi hayal edin. Arkasındaki nedenler görünür olduğunda bir tahmine güvenmek çok daha kolaylaşır ve bir modele ne zaman güvenilmemesi gerektiğine karar vermek de aynı derecede kolaylaşır. LIME, sınıflandırıcının kararını hangi özelliklerin yönlendirdiğini size söyler.
Veri Hazırlama
LIME'ı çalıştırmak için değiştirmeniz gereken birkaç şey var. PythonÖncelikle, pip install lime komutuyla terminale lime'ı kurun.
Lime, modeli yerel olarak yaklaşık olarak hesaplamak için bir LimeTabularExplainer nesnesi kullanır. Bu nesne şunları gerektirir:
- bir veri kümesi Dizi biçim
- Özelliklerin adı: feature_names
- Sınıfların adı: class_names
- Kategorik özellikler sütununun dizini: categorical_features
- Her bir kategorik özellik için grup adı: categorical_names
NumPy eğitim setini oluşturun.
Pandas'tan df_train'i NumPy'ye çok kolay bir şekilde kopyalayıp dönüştürebilirsiniz.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Sınıf adını alın
Etikete unique() fonksiyonu aracılığıyla erişilebilir. Şunu görmelisiniz:
- "<=50K"
- '>50K'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Kategorik özellik sütunlarını indeksleyin.
Daha önce öğrendiğiniz yöntemi kullanarak her grubun adını alın. Etiketi LabelEncoder ile kodlayın ve işlemi her kategorik özellik üzerinde tekrarlayın.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Veri seti hazır olduğuna göre, aşağıdaki Scikit learn örneklerinde gösterilen farklı veri setlerini oluşturabilirsiniz. LIME ile ilgili hataları önlemek için veriler burada işlem hattının dışında dönüştürülür: LimeTabularExplainer'a iletilen eğitim seti, dize içermeyen bir NumPy dizisi olmalıdır ve yukarıdaki yöntem zaten böyle bir dizi oluşturmuştur.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
XGBoost tarafından bulunan en uygun parametrelerle işlem hattını oluşturabilirsiniz.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Bir uyarı alıyorsunuz. Bu uyarı, işlem hattından önce bir etiket kodlayıcı oluşturmanıza gerek olmadığını açıklıyor. LIME kullanmıyorsanız, bu Scikit-learn ile Makine Öğrenimi eğitiminin ilk bölümündeki yöntem uygundur. Aksi takdirde, şu yaklaşımı izleyin: önce kodlanmış bir veri seti oluşturun, ardından işlem hattı içinde tekil kodlayıcıyı uygulayın.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
LIME'ı kullanmaya başlamadan önce, yanlış sınıflandırılan satırların özelliklerini içeren bir NumPy dizisi oluşturun. Bu listeyi daha sonra sınıflandırıcıyı neyin yanılttığına dair bir fikir edinmek için kullanabilirsiniz.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
Ardından, yeni veriler için modelden tahmini alan bir lambda fonksiyonu oluşturursunuz. Buna kısa süre sonra ihtiyacınız olacak.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Pandas veri çerçevesini NumPy dizisine dönüştürüyorsunuz.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Şimdi test verilerinden rastgele bir hane seçin ve hem tahmini hem de bilgisayarın bu tahmine nasıl ulaştığını inceleyin.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Modelin ardındaki mantığı incelemek için explain_instance ile birlikte explainer'ı kullanabilirsiniz. Oluşturduğu grafik aşağıda gösterilmiştir.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Sınıflandırıcı bu hanehalkını doğru tahmin etti: gelir gerçekten de 50 binin üzerinde.
Öncelikle belirtmek gerekir ki, sınıflandırıcı kendinden pek emin değil. 50 doların üzerinde bir geliri %64 olasılıkla tahmin ediyor ve bu %64'lük oran sermaye kazancı ve medeni durumdan kaynaklanıyor. Mavi renk pozitif sınıfa negatif, turuncu çizgi ise pozitif katkıda bulunuyor.
Sınıflandırıcı, bu hanehalkının sermaye kazancının sıfır olması nedeniyle tereddüt ediyor; oysa sermaye kazancı genellikle zenginliğin iyi bir göstergesidir. Ayrıca hanehalkı haftada 40 saatten az çalışıyor. Yaş, meslek ve cinsiyetin hepsi olumlu katkıda bulunuyor.
Medeni durum bekar olsaydı, sınıflandırıcı 50 bin doların altında bir gelir tahmin ederdi (0.64 – 0.18 = 0.46).
Şimdi yanlış sınıflandırılmış başka bir haneyi deneyin. Bununla ilgili açıklama tablosu kodun ardından geliyor.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Sınıflandırıcı, geliri 50'in altında tahmin etti ki bu yanlış. Bu hanehalkı alışılmadık bir durumda: ne sermaye kazancı ne de sermaye kaybı var, kişi boşanmış, 60 yaşına yakın ve eğitimli (eğitim_sayısı > 12). Genel örüntüyü takip ederek, sınıflandırıcı hanehalkını 50'in altında bir gelir seviyesine yerleştirdi.
LIME'ı kendiniz deneyin ve sınıflandırıcıdan kaynaklanan birçok bariz hatayı fark edeceksiniz. Kütüphane yazarının GitHub deposunda görüntü ve metin sınıflandırması için ek belgeler bulunmaktadır.
Scikit-learn Komut Referansı
Aşağıda, scikit-learn 0.20 ve sonraki sürümleri için geçerli olan faydalı komutların bir listesi bulunmaktadır.
| Görev | Fonksiyon veya sınıf |
|---|---|
| Eğitim/test veri setini oluşturun. | train_test_split |
| Bir boru hattı oluşturun | |
| Sütunları seçin ve dönüşümü uygulayın. | sütun dönüştürücü yap |
| Dönüşüm türü | |
| Standartlaştırmak | Standart Ölçekleyici |
| Minimum-maksimum ölçeklendirme | MinMaksÖlçekleyici |
| Normalleştirmek | Normalleştirici |
| Eksik değerleri doldurun. | Simpilgisayar |
| Kategorik dönüştür | OneHotKodlayıcı |
| Verileri sığdırın ve dönüştürün | uyum_dönüşümü |
| Boru hattını yapın | make_pipeline |
| Temel model | |
| Lojistik regresyon | Lojistik regresyon |
| XGBoost | XGBSınıflandırıcı |
| Sinir ağı | MLP Sınıflandırıcı |
| ızgara arama | IzgaraAramaCV |
| Rastgele arama | Rastgele AramaCV |