การฝังคำ (Word Embedding) และการแปลงคำเป็นเวกเตอร์ (Word2Vec) พร้อมตัวอย่าง
⚡ สรุปอย่างชาญฉลาด
Word Embedding และ Word2Vec แปลงข้อความให้เป็นเวกเตอร์ตัวเลขที่มีความหนาแน่นสูง เพื่อให้โมเดลการเรียนรู้ของเครื่องสามารถจดจำคำที่มีความหมายคล้ายคลึงกันได้ เอกสารนี้จะอธิบายเทคนิค สถาปัตยกรรม CBOW และ Skip-Gram ฟังก์ชันการกระตุ้น และการใช้งาน Gensim อย่างสมบูรณ์สำหรับแอปพลิเคชันจริง
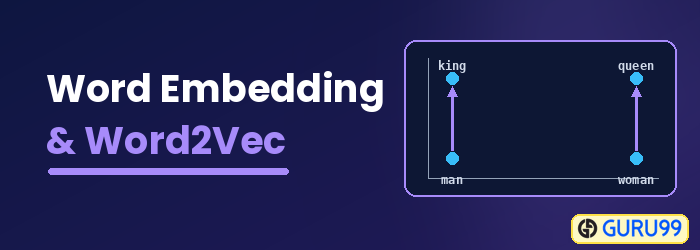
การฝัง Word คืออะไร?
การฝังคำ Word Embedding คือรูปแบบการแสดงคำที่ช่วยให้อัลกอริธึมการเรียนรู้ของเครื่องเข้าใจคำที่มีความหมายคล้ายกัน เป็นเทคนิคการสร้างแบบจำลองภาษาและการเรียนรู้คุณลักษณะเพื่อแมปคำไปยังเวกเตอร์ของจำนวนจริงโดยใช้โครงข่ายประสาทเทียม แบบจำลองความน่าจะเป็น หรือการลดมิติบนเมทริกซ์การเกิดร่วมกันของคำ ตัวอย่างแบบจำลอง Word Embedding บางแบบ ได้แก่ Word2vec (Google), GloVe (มหาวิทยาลัยสแตนฟอร์ด) และ fastText (เฟซบุ๊ก)
Word Embedding ยังเรียกอีกอย่างว่าแบบจำลองความหมายแบบกระจาย แบบจำลองที่แสดงแทนแบบกระจาย พื้นที่เวกเตอร์ความหมาย หรือแบบจำลองพื้นที่เวกเตอร์ เมื่อคุณอ่านชื่อเหล่านี้ คุณจะพบกับคำว่า ความหมายซึ่งหมายถึงการจัดกลุ่มคำที่คล้ายกันเข้าด้วยกัน ตัวอย่างเช่น ผลไม้ เช่น แอปเปิล มะม่วง และกล้วย ควรวางไว้ใกล้กัน ในขณะที่หนังสือจะวางไว้ห่างจากคำเหล่านี้ ในความหมายที่กว้างขึ้น การฝังคำจะสร้างเวกเตอร์ของผลไม้ซึ่งวางอยู่ห่างจากเวกเตอร์ที่แสดงถึงหนังสือ
การฝัง Word ใช้ที่ไหน?
การฝังคำ (Word embedding) ช่วยในการสร้างคุณลักษณะ การจัดกลุ่มเอกสาร การจำแนกประเภทข้อความ และงานประมวลผลภาษาธรรมชาติ เรามาลองยกตัวอย่างการใช้งานเหล่านี้และอธิบายแต่ละอย่างกัน
- คำนวณคำที่คล้ายกัน: การฝังคำ (Word embedding) ใช้เพื่อแนะนำคำที่คล้ายคลึงกับคำที่กำลังถูกนำไปใช้กับแบบจำลองการทำนาย นอกจากนี้ยังแนะนำคำที่ไม่คล้ายคลึงกัน รวมถึงคำที่พบบ่อยที่สุดด้วย
- สร้างกลุ่มคำที่เกี่ยวข้อง: ใช้สำหรับการจัดกลุ่มตามความหมายpingซึ่งจะจัดกลุ่มสิ่งที่มีลักษณะคล้ายคลึงกันไว้ด้วยกัน และผลักสิ่งที่ไม่เหมือนกันออกไปให้ไกล
- คุณสมบัติสำหรับการจำแนกข้อความ: ข้อความจะถูกแปลงเป็นอาร์เรย์ของเวกเตอร์ ซึ่งจะถูกป้อนเข้าสู่โมเดลเพื่อใช้ในการฝึกฝนและการทำนาย โมเดลจำแนกประเภทตามข้อความไม่สามารถฝึกฝนได้จากสตริง ดังนั้นวิธีการนี้จึงแปลงข้อความให้อยู่ในรูปแบบที่เครื่องสามารถฝึกฝนได้ คุณสมบัติการสร้างความหมายเพิ่มเติมช่วยในการจำแนกประเภทตามข้อความได้ดียิ่งขึ้น
- การจัดกลุ่มเอกสาร: นี่เป็นอีกหนึ่งแอปพลิเคชันที่ใช้ Word Embedding และ Word2vec อย่างแพร่หลาย
- การประมวลผลภาษาธรรมชาติ: มีแอปพลิเคชันมากมายที่การฝังคำมีประโยชน์และเหนือกว่าการใช้คุณลักษณะเฉพาะtracขั้นตอนการประมวลผล เช่น การระบุชนิดของคำ การวิเคราะห์ความรู้สึก และการวิเคราะห์โครงสร้างประโยค
เมื่อคุณเข้าใจแล้วว่าการฝังคำ (word embedding) ถูกนำไปใช้ที่ใดบ้าง ต่อไปเรามาดูโมเดลที่นิยมใช้มากที่สุดในการสร้างการฝังคำเหล่านี้กัน
Word2vec คืออะไร?
เวิร์ด2เวค เป็นเทคนิคหรือแบบจำลองที่สร้างเวิร์ดเอ็มเบดดิ้งเพื่อการแสดงคำที่ดีขึ้น เป็นวิธีการประมวลผลภาษาธรรมชาติที่สามารถจับความสัมพันธ์ทางไวยากรณ์และความหมายของคำจำนวนมากได้อย่างแม่นยำ เป็นโครงข่ายประสาทเทียมแบบสองชั้นที่ไม่ซับซ้อน ซึ่งสามารถตรวจจับคำที่มีความหมายเหมือนกันและแนะนำคำเพิ่มเติมสำหรับประโยคบางส่วนได้เมื่อได้รับการฝึกฝนแล้ว
ก่อนที่จะไปต่อ โปรดดูความแตกต่างระหว่างโครงข่ายประสาทเทียมแบบตื้นและแบบลึกดังแสดงในแผนภาพตัวอย่างการฝังคำด้านล่าง:
โครงข่ายประสาทเทียมแบบตื้นประกอบด้วยชั้นซ่อนเพียงชั้นเดียวระหว่างอินพุตและเอาต์พุต ในขณะที่โครงข่ายประสาทเทียมแบบลึกมีชั้นซ่อนหลายชั้นระหว่างอินพุตและเอาต์พุต อินพุตจะถูกส่งผ่านไปยังโหนด ในขณะที่ชั้นซ่อนและชั้นเอาต์พุตจะมีเซลล์ประสาทอยู่ภายใน
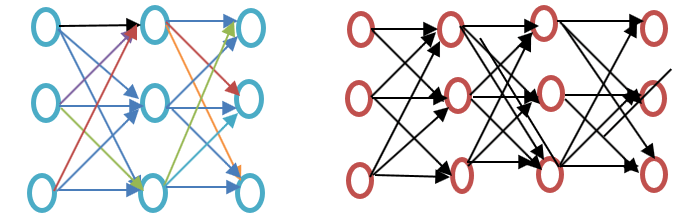
Word2vec เป็นโครงข่ายประสาทเทียมสองชั้น ประกอบด้วยส่วนรับข้อมูล ส่วนซ่อน และส่วนส่งข้อมูล
Word2vec ได้รับการพัฒนาโดยกลุ่มนักวิจัยที่นำโดย โทมัส มิโคลอฟ ที่ GoogleWord2vec ดีกว่าและมีประสิทธิภาพมากกว่าโมเดลการวิเคราะห์ความหมายแฝง (Latent Semantic Analysis: Latent Semantic Analysis: LASE)
ทำไมต้อง Word2vec?
Word2vec แสดงคำในรูปแบบเวกเตอร์ โดยคำต่างๆ จะถูกแทนด้วยเวกเตอร์ และการจัดวางจะทำในลักษณะที่คำที่มีความหมายคล้ายกันจะอยู่ด้วยกัน และคำที่มีความหมายแตกต่างกันจะอยู่ห่างกัน ซึ่งเรียกอีกอย่างว่าความสัมพันธ์เชิงความหมาย เครือข่ายประสาทเทียมไม่เข้าใจข้อความ แต่เข้าใจเฉพาะตัวเลขเท่านั้น การฝังคำ (Word Embedding) จึงเป็นวิธีการแปลงข้อความให้เป็นเวกเตอร์ตัวเลข
Word2vec สร้างบริบททางภาษาของคำขึ้นมาใหม่ ก่อนที่จะไปต่อ เรามาทำความเข้าใจกันก่อนว่าบริบททางภาษาคืออะไร ในสถานการณ์ทั่วไป เมื่อเราพูดหรือเขียนเพื่อสื่อสาร ผู้อื่นจะพยายามหาจุดประสงค์ของประโยค ตัวอย่างเช่น “อุณหภูมิของอินเดียคือเท่าไหร่?” ในที่นี้ บริบทคือผู้ใช้ต้องการทราบ “อุณหภูมิของอินเดีย” กล่าวโดยสรุป จุดประสงค์หลักของประโยคคือบริบท คำหรือประโยคที่อยู่รอบข้างภาษาพูดหรือภาษาเขียนช่วยในการกำหนดความหมายของบริบท Word2vec เรียนรู้การแสดงเวกเตอร์ของคำผ่านบริบทเหล่านี้
Word2vec ทำอะไรได้บ้าง?
ก่อนที่จะฝังคำ
สิ่งสำคัญคือต้องทราบว่าก่อนการใช้ Word Embedding นั้นใช้วิธีใดและมีข้อเสียอะไรบ้าง จากนั้นเราจะมาดูกันว่า Word Embedding โดยใช้ Word2vec สามารถเอาชนะข้อเสียเหล่านั้นได้อย่างไร สุดท้าย เราจะมาดูวิธีการทำงานของ Word2vec เพราะการเข้าใจวิธีการทำงานของมันนั้นสำคัญมาก
แนวทางการวิเคราะห์ความหมายแฝง
นี่คือแนวทางที่ใช้ก่อนการใช้เวิร์ดเอ็มเบดดิ้ง (Word Embeddings) โดยใช้แนวคิดของ "ถุงแห่งคำ" (Bag of Words) ซึ่งคำต่างๆ จะถูกแทนด้วยเวกเตอร์ที่เข้ารหัส เป็นการแทนเวกเตอร์แบบเบาบาง (sparse vector representation) ที่มีมิติเท่ากับขนาดของคำศัพท์ หากคำนั้นปรากฏในพจนานุกรม ก็จะถูกนับ มิเช่นนั้นจะไม่ถูกนับ หากต้องการเข้าใจเพิ่มเติม โปรดดูโปรแกรมด้านล่าง
ตัวอย่าง Word2vec

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Output:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code คำอธิบาย
- CountVectorizer เป็นโมดูลที่ใช้ในการจัดเก็บคำศัพท์โดยอิงจากการจับคู่คำในนั้น โมดูลนี้ถูกนำเข้าจาก sklearn
- สร้างวัตถุโดยใช้คลาส CountVectorizer
- เขียนข้อมูลลงในลิสต์ที่จะนำไปใช้กับ CountVectorizer
- ข้อมูลมีความพอดีในวัตถุที่สร้างจากคลาส CountVectorizer
- ใช้แนวทาง Bag-of-words ในการนับคำในข้อมูลโดยใช้คำศัพท์ หากคำหรือโทเค็นใดไม่มีอยู่ในคำศัพท์ ตำแหน่งดัชนีนั้นจะถูกกำหนดเป็นศูนย์
- ตัวแปรในบรรทัดที่ 5 ซึ่งก็คือ x จะถูกแปลงเป็นอาร์เรย์ (ซึ่งเป็นเมธอดที่มีให้สำหรับ x) ผลลัพธ์ที่ได้คือจำนวนนับของแต่ละโทเค็นในประโยคหรือรายการที่ให้มาในบรรทัดที่ 3
- นี่แสดงให้เห็นถึงคุณลักษณะที่เป็นส่วนหนึ่งของคำศัพท์เมื่อนำไปปรับใช้โดยใช้ข้อมูลในบรรทัดที่ 4
ในแนวทางความหมายแฝง (Latent Semantic approach) แถวแสดงถึงคำที่ไม่ซ้ำกัน ในขณะที่คอลัมน์แสดงถึงจำนวนครั้งที่คำนั้นปรากฏในเอกสาร เป็นการแสดงคำในรูปแบบเมทริกซ์เอกสาร ค่าความถี่คำผกผันกับความถี่เอกสาร (Term Frequency-Inverse Document Frequency: TF-IDF) ใช้ในการนับความถี่ของคำในเอกสาร ซึ่งคือความถี่ของคำในเอกสารหารด้วยความถี่ของคำในคลังข้อมูลทั้งหมด
ข้อบกพร่องของวิธี Bag of Words
- มันไม่คำนึงถึงลำดับของคำ ตัวอย่างเช่น นี้ไม่ดี = แย่จังเลย.
- มันไม่สนใจบริบทของคำ สมมติว่าเราเขียนประโยคว่า “เขารักหนังสือ การศึกษาที่ดีที่สุดพบได้ในหนังสือ” มันจะสร้างเวกเตอร์สองตัว ตัวหนึ่งสำหรับ “เขารักหนังสือ” และอีกตัวสำหรับ “การศึกษาที่ดีที่สุดพบได้ในหนังสือ” มันจะถือว่าทั้งสองเป็นเวกเตอร์ตั้งฉากกัน ซึ่งทำให้พวกมันเป็นอิสระต่อกัน แต่ในความเป็นจริงแล้ว พวกมันมีความสัมพันธ์กัน
เพื่อเอาชนะข้อจำกัดเหล่านี้ จึงได้มีการพัฒนาเทคนิคการฝังคำ (word embedding) ขึ้น และ Word2vec ก็เป็นหนึ่งในวิธีการที่ใช้ในการนำเทคนิคนี้ไปใช้
Word2vec ทำงานอย่างไร?
Word2vec เรียนรู้คำศัพท์โดยการคาดเดาบริบทโดยรอบ ตัวอย่างเช่น ลองพิจารณาคำว่า “He” รัก ฟุตบอล."
เราต้องการคำนวณ Word2vec สำหรับคำว่า: รัก.
สมมติ:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
คำ รัก โปรแกรมนี้จะทำการวิเคราะห์แต่ละคำในคลังข้อมูล โดยจะเข้ารหัสความสัมพันธ์ทั้งทางด้านไวยากรณ์และความหมายระหว่างคำ ซึ่งช่วยในการค้นหาคำที่คล้ายคลึงกันและคำที่มีความหมายใกล้เคียงกัน
คุณสมบัติสุ่มทั้งหมดของคำ รัก มีการคำนวณ คุณลักษณะเหล่านี้จะถูกเปลี่ยนแปลงหรืออัปเดตโดยสัมพันธ์กับคำข้างเคียงหรือคำบริบทด้วยความช่วยเหลือของ การขยายพันธุ์กลับ วิธี
อีกวิธีหนึ่งในการเรียนรู้คือ ถ้าบริบทของคำสองคำคล้ายกัน หรือคำสองคำมีลักษณะคล้ายคลึงกัน คำเหล่านั้นก็จะมีความสัมพันธ์กัน
เวิร์ด2เวค Archiเทคเจอร์
Word2vec มีสองสถาปัตยกรรมที่ใช้:
- ถุงคำต่อเนื่อง (CBOW)
- สกิปแกรม
ก่อนที่จะไปต่อ เรามาพูดคุยกันก่อนว่าทำไมสถาปัตยกรรมหรือโมเดลเหล่านี้จึงมีความสำคัญจากมุมมองของการแสดงคำศัพท์ การเรียนรู้การแสดงคำศัพท์นั้นโดยพื้นฐานแล้วเป็นการเรียนรู้แบบไม่ใช้ข้อมูลกำกับ แต่จำเป็นต้องมีเป้าหมาย/ป้ายกำกับเพื่อฝึกโมเดล Skip-gram และ CBOW แปลงการแสดงคำศัพท์แบบไม่ใช้ข้อมูลกำกับให้เป็นรูปแบบที่ใช้ข้อมูลกำกับเพื่อใช้ในการฝึกโมเดล
ใน CBOW คำปัจจุบันจะถูกทำนายโดยใช้หน้าต่างของหน้าต่างบริบทโดยรอบ ตัวอย่างเช่น หาก wI-1w,I-2w,i + 1w,i + 2 ได้รับคำหรือบริบท โมเดลนี้จะจัดให้มี wi.
Skip-Gram ทำงานตรงกันข้ามกับ CBOW ซึ่งหมายความว่ามันทำนายลำดับหรือบริบทที่กำหนดจากคำ คุณสามารถย้อนกลับตัวอย่างเพื่อทำความเข้าใจได้ ถ้า wi หากได้รับข้อมูลนี้ จะสามารถทำนายบริบทได้ หรือ...I-1w,I-2w,i + 1w,i + 2.
Word2vec มีตัวเลือกให้เลือกระหว่าง CBOW (Continuous Bag of Words) และ skip-gram โดยสามารถกำหนดพารามิเตอร์เหล่านี้ได้ในระหว่างการฝึกโมเดล นอกจากนี้ยังสามารถเลือกใช้การสุ่มตัวอย่างเชิงลบ (negative sampling) หรือเลเยอร์ softmax แบบลำดับชั้นได้อีกด้วย
ถุงคำพูดอย่างต่อเนื่อง
เรามาลองวาดแผนภาพตัวอย่าง Word2vec อย่างง่ายๆ เพื่อทำความเข้าใจสถาปัตยกรรมถุงคำแบบต่อเนื่องกันดู

ให้เราคำนวณสมการทางคณิตศาสตร์ สมมติว่า V คือขนาดคำศัพท์ และ N คือขนาดเลเยอร์ที่ซ่อนอยู่ อินพุตถูกกำหนดเป็น { xI-1, xI-2, xi + 1, xi + 2 เราได้เมทริกซ์น้ำหนักโดยการคูณ V * N และได้เมทริกซ์อีกตัวหนึ่งโดยการคูณเวกเตอร์อินพุตกับเมทริกซ์น้ำหนัก ซึ่งสามารถเข้าใจได้จากสมการต่อไปนี้
h = xitW
ที่ไหนซีt และ W คือเวกเตอร์อินพุตและเมทริกซ์น้ำหนักตามลำดับ
ในการคำนวณความสอดคล้องระหว่างบริบทและคำถัดไป โปรดดูสมการด้านล่าง
u = การแสดงผลที่คาดการณ์ไว้ * h
โดยที่ค่า predictedrepresentation ได้มาจากแบบจำลองในสมการข้างต้น
โมเดล Skip-Gram
วิธีการ Skip-Gram ใช้ในการทำนายประโยคจากคำที่ป้อนเข้ามา เพื่อให้เข้าใจได้ดียิ่งขึ้น ลองวาดแผนภาพดังแสดงในตัวอย่าง Word2vec ด้านล่าง

อาจมองได้ว่ามันเป็นแบบกลับด้านของโมเดล Continuous Bag of Words โดยที่อินพุตคือคำ และโมเดลจะให้บริบทหรือลำดับของคำนั้น นอกจากนี้ เรายังสรุปได้ว่าเป้าหมายถูกป้อนเข้าไปในอินพุต และเลเยอร์เอาต์พุตจะถูกทำซ้ำหลายครั้งเพื่อรองรับจำนวนคำบริบทที่เลือกไว้ เวกเตอร์ข้อผิดพลาดจากเลเยอร์เอาต์พุตทั้งหมดจะถูกรวมเข้าด้วยกันเพื่อปรับน้ำหนักโดยใช้วิธี backpropagation
เลือกรุ่นไหนดี?
CBOW เร็วกว่า skip-gram หลายเท่า และให้ความถี่ที่ดีกว่าสำหรับคำที่ใช้บ่อย ในขณะที่ skip-gram ต้องการข้อมูลฝึกฝนเพียงเล็กน้อย และสามารถแสดงความถี่ของคำหรือวลีที่หายากได้ด้วย ตารางด้านล่างเปรียบเทียบสถาปัตยกรรมทั้งสองแบบโดยสังเขป
| แง่มุม | ซีโบว | สกิปแกรม |
|---|---|---|
| คำทำนาย | ทำนายคำเป้าหมายจากบริบท | คาดการณ์บริบทจากคำเป้าหมาย |
| ความเร็วในการฝึก | ได้เร็วขึ้น | ช้าลง |
| คำที่ใช้บ่อย | ความแม่นยำสูงกว่า | ความแม่นยำต่ำกว่า |
| คำศัพท์หายาก | การเป็นตัวแทนที่อ่อนแอกว่า | การเป็นตัวแทนที่แข็งแกร่งยิ่งขึ้น |
| ข้อมูลการฝึกอบรม | ต้องการข้อมูลเพิ่มเติม | ทำงานได้โดยใช้ข้อมูลน้อยลง |
ความสัมพันธ์ระหว่าง Word2vec และ NLTK
เอ็นแอลทีเค เป็นธรรมชาติ Language Toolชุดเครื่องมือนี้ใช้สำหรับการประมวลผลข้อความเบื้องต้น สามารถดำเนินการต่างๆ ได้ เช่น การระบุส่วนของคำพูด การหาคำหลัก การตัดคำ การลบคำที่ไม่สำคัญ และการลบคำที่หายากหรือใช้น้อยที่สุด ช่วยในการทำความสะอาดข้อความและเตรียมคุณลักษณะจากคำที่มีประสิทธิภาพ ในทางกลับกัน Word2vec ใช้สำหรับการจับคู่ความหมาย (รายการที่เกี่ยวข้องกันอย่างใกล้ชิด) และการจับคู่ไวยากรณ์ (ลำดับ) โดยใช้ Word2vec สามารถค้นหาคำที่คล้ายกัน คำที่ไม่เหมือนกัน การลดมิติ และอื่นๆ อีกมากมาย คุณสมบัติที่สำคัญอีกอย่างของ Word2vec คือการแปลงการแสดงข้อความที่มีมิติสูงให้เป็นเวกเตอร์ที่มีมิติต่ำกว่า
จะใช้ NLTK และ Word2vec ได้ที่ไหน
หากต้องการทำงานทั่วไปตามที่กล่าวมาข้างต้น เช่น การแบ่งคำ การติดแท็กส่วนของคำพูด และการวิเคราะห์ไวยากรณ์ ควรเลือกใช้ NLTK ในขณะที่หากต้องการทำนายคำตามบริบท การสร้างแบบจำลองหัวข้อ หรือความคล้ายคลึงของเอกสาร ควรใช้ Word2vec
ความสัมพันธ์ของ NLTK และ Word2vec ด้วยความช่วยเหลือของโค้ด
NLTK และ Word2vec สามารถใช้ร่วมกันเพื่อค้นหาคำที่คล้ายคลึงกันหรือการจับคู่ทางไวยากรณ์ได้ ชุดเครื่องมือ NLTK สามารถใช้โหลดแพ็กเกจต่างๆ ที่มาพร้อมกับ NLTK และสามารถสร้างโมเดลโดยใช้ Word2vec จากนั้นจึงทดสอบกับคำศัพท์จริง มาดูการใช้งานร่วมกันของทั้งสองในโค้ดต่อไปนี้ ก่อนที่จะดำเนินการต่อไป โปรดดูคลังข้อมูลที่ NLTK จัดเตรียมไว้ให้ คุณสามารถดาวน์โหลดได้โดยใช้คำสั่ง:
nltk(nltk.download('all'))

โปรดดูภาพหน้าจอสำหรับรหัส
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Output:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
คำอธิบายของ Code
- ได้ทำการนำเข้าไลบรารี nltk แล้ว ซึ่งคุณสามารถดาวน์โหลดคอร์ปัส abc ที่เราจะใช้ในขั้นตอนต่อไปได้จากที่นี่
- ได้ทำการนำเข้า Gensim แล้ว หากยังไม่ได้ติดตั้ง Gensim Word2vec โปรดติดตั้งโดยใช้คำสั่ง “pip3 install gensim” โปรดดูภาพหน้าจอประกอบด้านล่าง

- นำเข้าคลังข้อมูล abc ที่ดาวน์โหลดมาแล้วโดยใช้คำสั่ง nltk.download('abc')
- ส่งไฟล์ไปยังโมเดล Word2vec ซึ่งนำเข้าโดยใช้ Gensim ในรูปแบบของประโยค
- คำศัพท์จะถูกจัดเก็บในรูปแบบของตัวแปร
- โมเดลนี้ได้รับการทดสอบกับคำตัวอย่าง วิทยาศาสตร์เนื่องจากไฟล์เหล่านี้เกี่ยวข้องกับวิทยาศาสตร์
- ในที่นี้ แบบจำลองได้ทำนายคำที่มีความหมายคล้ายกันคือ “วิทยาศาสตร์”
ตัวกระตุ้นและ Word2Vec
ฟังก์ชันการกระตุ้นของเซลล์ประสาทกำหนดผลลัพธ์ของเซลล์ประสาทนั้นเมื่อได้รับชุดข้อมูลป้อนเข้า แนวคิดนี้ได้รับแรงบันดาลใจทางชีววิทยาจากกิจกรรมในสมองของเรา ซึ่งเซลล์ประสาทต่างๆ จะถูกกระตุ้นด้วยสิ่งเร้าที่แตกต่างกัน เรามาทำความเข้าใจฟังก์ชันการกระตุ้นผ่านแผนภาพต่อไปนี้กัน

ในที่นี้ x1, x2, … x4 คือโหนดของโครงข่ายประสาทเทียม
w1, w2, w3 คือค่าน้ำหนักของโหนดต่างๆ
ผลรวม (Σ) ของค่าน้ำหนักและค่าโหนดทั้งหมดทำหน้าที่เป็นฟังก์ชันการกระตุ้น
ทำไมต้องเปิดใช้งานฟังก์ชั่น?
หากไม่ใช้ฟังก์ชันการกระตุ้น ผลลัพธ์จะเป็นเชิงเส้น แต่ฟังก์ชันเชิงเส้นมีข้อจำกัดในการใช้งาน เพื่อให้ได้ฟังก์ชันที่ซับซ้อน เช่น การตรวจจับวัตถุ การจำแนกภาพ เป็นต้นping สำหรับการส่งข้อความโดยใช้เสียง และผลลัพธ์ที่ไม่เป็นเชิงเส้นอื่นๆ อีกมากมาย จำเป็นต้องมีฟังก์ชันการเปิดใช้งาน
วิธีคำนวณเลเยอร์การเปิดใช้งานในการฝังคำ (Word2vec)
เลเยอร์ Softmax (ฟังก์ชันเลขชี้กำลังแบบนอร์มาไลซ์) คือฟังก์ชันในเลเยอร์เอาต์พุตที่กระตุ้นหรือสั่งการแต่ละโหนด อีกแนวทางหนึ่งที่ใช้คือ Softmax แบบลำดับชั้น ซึ่งความซับซ้อนคำนวณได้จาก O(log2ในขณะที่ softmax มีความซับซ้อน O(V) โดยที่ V คือขนาดของคำศัพท์ ความแตกต่างระหว่างสองวิธีนี้คือการลดความซับซ้อนในเลเยอร์ softmax แบบลำดับชั้น เพื่อให้เข้าใจการทำงาน โปรดดูตัวอย่างการฝังคำด้านล่าง:

สมมติว่าเราต้องการคำนวณความน่าจะเป็นที่จะสังเกตคำนั้น ความรัก ภายใต้บริบทที่กำหนด การไหลจากโหนดรากไปยังโหนดใบจะเคลื่อนไปยังโหนด 2 ก่อน แล้วจึงไปยังโหนด 5 ดังนั้นหากเรามีคำศัพท์ขนาด 8 คำ จะต้องใช้การคำนวณเพียงสามครั้งเท่านั้น ซึ่งช่วยให้สามารถแยกการคำนวณความน่าจะเป็นของคำหนึ่งคำได้ (ความรัก).
มีตัวเลือกอื่นใดอีกนอกจาก Hierarchical Softmax บ้าง?
โดยทั่วไปแล้ว ตัวเลือกการฝังคำที่มีให้เลือก ได้แก่ Differentiated Softmax, CNN-Softmax, Importance Sampling, Adaptive Importance Sampling, Noise Contrastive Estimation, Negative Sampling, Self-Normalization และ Infrequent Normalization
หากพูดถึง Word2vec โดยเฉพาะ เรามีการสุ่มตัวอย่างเชิงลบให้ใช้งานได้
การสุ่มตัวอย่างเชิงลบ (Negative Sampling) เป็นวิธีการสุ่มตัวอย่างข้อมูลฝึกฝน คล้ายกับการไล่ระดับความชันแบบสุ่ม (Stochastic Gradient Descent) แต่มีความแตกต่างกันอยู่บ้าง การสุ่มตัวอย่างเชิงลบจะมองหาเฉพาะตัวอย่างฝึกฝนที่เป็นลบเท่านั้น โดยอาศัยการประมาณค่าความแตกต่างของสัญญาณรบกวน (Noise Contrastive Estimation) และสุ่มเลือกคำที่ไม่เกี่ยวข้องกับบริบท เป็นวิธีการฝึกฝนที่รวดเร็วและเลือกบริบทแบบสุ่ม หากคำที่ทำนายปรากฏในบริบทที่เลือกแบบสุ่ม เวกเตอร์ทั้งสองจะอยู่ใกล้กัน
ข้อสรุปอะไรที่สามารถสรุปได้?
ตัวกระตุ้นจะสั่งการให้เซลล์ประสาททำงานเช่นเดียวกับเซลล์ประสาทของเราที่ถูกกระตุ้นด้วยสิ่งเร้าภายนอก เลเยอร์ Softmax เป็นหนึ่งในฟังก์ชันของเลเยอร์เอาต์พุตที่สั่งการให้เซลล์ประสาททำงานในกรณีของเวิร์ดเอ็มเบดดิ้ง ใน Word2vec เรามีตัวเลือกต่างๆ เช่น softmax แบบลำดับชั้นและการสุ่มตัวอย่างเชิงลบ การใช้ตัวกระตุ้นช่วยให้เราสามารถแปลงฟังก์ชันเชิงเส้นให้เป็นฟังก์ชันที่ไม่เป็นเชิงเส้น และสามารถนำอัลกอริทึมการเรียนรู้ของเครื่องที่ซับซ้อนมาใช้ได้โดยใช้ฟังก์ชันดังกล่าว
เกนซิมคืออะไร?
เกนซิม เป็นชุดเครื่องมือการสร้างแบบจำลองหัวข้อโอเพ่นซอร์สและการประมวลผลภาษาธรรมชาติที่นำมาใช้ Python และ Cython ชุดเครื่องมือ Gensim ช่วยให้ผู้ใช้สามารถนำเข้า Word2vec สำหรับการสร้างแบบจำลองหัวข้อเพื่อค้นหาโครงสร้างที่ซ่อนอยู่ภายในเนื้อหาข้อความ Gensim ไม่เพียงแต่มี Word2vec เท่านั้น แต่ยังมี Doc2vec และ FastText อีกด้วย
ส่วนนี้เน้นที่ Word2vec ดังนั้นเราจะยึดตามหัวข้อปัจจุบันเท่านั้น
วิธีการใช้งาน Word2vec โดยใช้ Gensim
จนถึงตอนนี้ เราได้พูดคุยกันไปแล้วว่า Word2vec คืออะไร สถาปัตยกรรมแบบต่างๆ ของมัน เหตุใดจึงมีการเปลี่ยนจาก Bag of Words มาเป็น Word2vec ความสัมพันธ์ระหว่าง Word2vec และ NLTK กับ Live Code และฟังก์ชันการเปิดใช้งาน
ด้านล่างนี้คือขั้นตอนการใช้งาน Word2vec โดยใช้ Gensim:
ขั้นตอนที่ 1) การรวบรวมข้อมูล
ขั้นตอนแรกในการนำโมเดลการเรียนรู้ของเครื่องหรือการประมวลผลภาษาธรรมชาติมาใช้ คือการรวบรวมข้อมูล
โปรดสังเกตข้อมูลเพื่อสร้างแชทบอทอัจฉริยะดังที่แสดงในตัวอย่าง Gensim Word2vec ด้านล่าง
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
นี่คือสิ่งที่เราเข้าใจจากข้อมูล:
- ข้อมูลนี้ประกอบด้วยสามส่วน ได้แก่ แท็ก รูปแบบ และการตอบสนอง แท็กคือเจตนา (หัวข้อของการสนทนาคืออะไร)
- ข้อมูลอยู่ในรูปแบบ JSON
- รูปแบบคือคำถามที่ผู้ใช้จะถามบอท
- คำตอบคือคำตอบที่แชทบอทจะให้ต่อคำถาม/รูปแบบที่เกี่ยวข้อง
ขั้นตอนที่ 2) การประมวลผลข้อมูลล่วงหน้า
การประมวลผลข้อมูลดิบเป็นสิ่งสำคัญมาก หากข้อมูลที่ล้างแล้วถูกป้อนเข้าเครื่อง โมเดลจะตอบสนองได้แม่นยำยิ่งขึ้น และจะเรียนรู้ข้อมูลได้อย่างมีประสิทธิภาพมากขึ้น
ขั้นตอนนี้เกี่ยวข้องกับการลบคำที่ไม่สำคัญ การตัดคำที่ไม่จำเป็น ฯลฯ ก่อนดำเนินการต่อ จำเป็นต้องโหลดข้อมูลและแปลงข้อมูลให้อยู่ในรูปแบบดาต้าเฟรม โปรดดูโค้ดด้านล่างสำหรับขั้นตอนนี้
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
คำอธิบายของ Code:
- เนื่องจากข้อมูลอยู่ในรูปแบบ JSON จึงต้องนำเข้าข้อมูลในรูปแบบ JSON
- ไฟล์ถูกเก็บไว้ในตัวแปร
- ไฟล์ถูกเปิดและโหลดลงในตัวแปรข้อมูล
ตอนนี้ข้อมูลถูกนำเข้าเรียบร้อยแล้ว และถึงเวลาแปลงข้อมูลให้อยู่ในรูปแบบดาต้าเฟรม โปรดดูโค้ดด้านล่างสำหรับขั้นตอนต่อไป
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
คำอธิบายของ Code:
1. ข้อมูลจะถูกแปลงเป็น DataFrame โดยใช้ Pandas ซึ่งได้นำเข้าไว้ข้างต้นแล้ว
2. ฟังก์ชันนี้จะแปลงรายการในรูปแบบคอลัมน์ให้เป็นสตริง
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code คำอธิบาย:
1. คำหยุด (stop words) ภาษาอังกฤษจะถูกนำเข้าโดยใช้โมดูล stop-word จากชุดเครื่องมือ nltk
2. คำทุกคำในข้อความจะถูกแปลงเป็นตัวพิมพ์เล็กโดยใช้เงื่อนไข for และฟังก์ชัน lambda A ฟังก์ชันแลมบ์ดา เป็นฟังก์ชันที่ไม่ระบุชื่อ
3. ระบบจะตรวจสอบข้อความทุกแถวใน data frame เพื่อหาเครื่องหมายวรรคตอน และกรองข้อความเหล่านั้นออก
4. อักขระ เช่น ตัวเลขหรือจุด จะถูกลบออกโดยใช้ regular expression
5. Digits จะถูกลบออกจากข้อความ
6. คำหยุดจะถูกลบออกในขั้นตอนนี้
7. ตอนนี้คำต่างๆ ถูกกรองแล้ว และคำที่มีรูปแบบแตกต่างกันแต่เหมือนกันจะถูกลบออกโดยใช้การหาคำหลัก (lemmatization) ด้วยขั้นตอนเหล่านี้ เราได้เสร็จสิ้นการประมวลผลข้อมูลเบื้องต้นแล้ว
Output:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
ขั้นตอนที่ 3) การสร้างโครงข่ายประสาทเทียมโดยใช้ Word2vec
ตอนนี้ถึงเวลาสร้างแบบจำลองโดยใช้โมดูล Word2vec ของ Gensim แล้ว เราต้องนำเข้า Word2vec จาก Gensim ก่อน จากนั้นเราจะสร้างแบบจำลอง และในขั้นตอนสุดท้ายเราจะตรวจสอบแบบจำลองกับข้อมูลแบบเรียลไทม์
from gensim.models import Word2Vec
ตอนนี้เราสามารถสร้างโมเดลโดยใช้ Word2Vec ได้สำเร็จแล้ว โปรดดูโค้ดบรรทัดถัดไปเพื่อเรียนรู้วิธีการสร้างโมเดลโดยใช้ Word2Vec ข้อความที่ป้อนให้กับโมเดลอยู่ในรูปแบบของลิสต์ ดังนั้นเราจะแปลงข้อความจากเฟรมข้อมูลให้เป็นลิสต์โดยใช้โค้ดด้านล่าง
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
คำอธิบายของ Code:
1. สร้าง bigger_list โดยเพิ่ม inner list เข้าไป นี่คือรูปแบบที่จะป้อนให้กับโมเดล Word2Vec
2. มีการสร้างลูปขึ้นมา และวนซ้ำแต่ละรายการในคอลัมน์ patterns ของ data frame
3. แต่ละองค์ประกอบของรูปแบบคอลัมน์จะถูกแยกและจัดเก็บไว้ในลิสต์ภายใน li
4. รายการภายในจะถูกต่อท้ายด้วยรายการภายนอก
5. รายการนี้ถูกส่งไปยังโมเดล Word2Vec เรามาทำความเข้าใจพารามิเตอร์บางส่วนที่ให้มาในที่นี้กัน
ขั้นต่ำ_จำนวน: ระบบจะละเว้นคำทั้งหมดที่มีความถี่รวมต่ำกว่าค่านี้
ขนาด: มันบอกมิติของคำว่าเวกเตอร์
แรงงาน: นี่คือเธรดที่จะใช้ในการฝึกฝนโมเดล
นอกจากนี้ยังมีตัวเลือกอื่นๆ อีก ซึ่งตัวเลือกที่สำคัญบางส่วนจะอธิบายไว้ด้านล่างนี้
หน้าต่าง: ระยะห่างสูงสุดระหว่างคำปัจจุบันและคำที่คาดเดาภายในประโยค
เอสจี: นี่คืออัลกอริธึมการฝึกฝน: 1 สำหรับ skip-gram และ 0 สำหรับ Continuous Bag of Words เราได้กล่าวถึงรายละเอียดเหล่านี้ไว้ข้างต้นแล้ว
ชั่วโมง: ถ้าค่านี้เป็น 1 แสดงว่าเราใช้ softmax แบบลำดับชั้นในการฝึกฝน และถ้าเป็น 0 แสดงว่าใช้การสุ่มตัวอย่างเชิงลบ
อัลฟา: อัตราการเรียนรู้เริ่มต้น
ให้เราแสดงโค้ดสุดท้ายด้านล่าง:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
ขั้นตอนที่ 4) การบันทึกโมเดล
สามารถบันทึกโมเดลในรูปแบบไฟล์ bin และไฟล์โมเดลได้ โดยไฟล์ bin เป็นรูปแบบไบนารี โปรดดูวิธีการบันทึกโมเดลตามบรรทัดด้านล่าง
model.save("word2vec.model") model.save("model.bin")
คำอธิบายของรหัสข้างต้น
1. โมเดลจะถูกบันทึกในรูปแบบไฟล์ .model
2. โมเดลจะถูกบันทึกในรูปแบบไฟล์ .bin
เราจะใช้โมเดลนี้ในการทดสอบแบบเรียลไทม์ เช่น คำที่คล้ายกัน คำที่แตกต่างกัน และคำที่ใช้บ่อยที่สุด
ขั้นตอนที่ 5) กำลังโหลดโมเดลและดำเนินการทดสอบแบบเรียลไทม์
โมเดลนี้ถูกโหลดโดยใช้โค้ดด้านล่างนี้:
model = Word2Vec.load('model.bin')
หากต้องการพิมพ์คำศัพท์จากเอกสารนี้ สามารถทำได้โดยใช้คำสั่งด้านล่างนี้:
vocab = list(model.wv.vocab)
โปรดดูผลลัพธ์:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
ขั้นตอนที่ 6) การตรวจสอบคำที่คล้ายกันมากที่สุด
ให้เรานำสิ่งต่าง ๆ ไปใช้จริง:
similar_words = model.most_similar('thanks') print(similar_words)
โปรดดูผลลัพธ์:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
ขั้นตอนที่ 7) ไม่ตรงกับคำจากคำที่ให้มา
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
เราได้จัดหาคำ 'ไว้เจอกันใหม่ ขอบคุณที่มาเยี่ยม'โค้ดนี้จะพิมพ์คำที่แตกต่างจากคำเหล่านี้มากที่สุด ลองรันโค้ดนี้และดูผลลัพธ์กัน
ผลลัพธ์หลังจากการรันโค้ดข้างต้น:
Thanks
ขั้นตอนที่ 8) ค้นหาความคล้ายคลึงกันระหว่างคำสองคำ
ส่วนนี้แสดงผลลัพธ์ในแง่ของความน่าจะเป็นของความคล้ายคลึงกันระหว่างสองคำ โปรดดูโค้ดด้านล่างเพื่อดูวิธีการเรียกใช้ส่วนนี้
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
ผลลัพธ์ของโค้ดข้างต้นเป็นดังนี้:
0.13706
คุณสามารถค้นหาคำที่คล้ายกันเพิ่มเติมได้โดยการเรียกใช้โค้ดด้านล่างนี้:
similar = model.similar_by_word('kind') print(similar)
ผลลัพธ์ของโค้ดข้างต้น:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]