บทช่วยสอน Scikit-Learn: วิธีการติดตั้งและตัวอย่าง Scikit-Learn
⚡ สรุปอย่างชาญฉลาด
Scikit-learn เป็นซอฟต์แวร์โอเพนซอร์ส Python ไลบรารีที่ครอบคลุมการประมวลผลล่วงหน้า การจำแนกประเภท การถดถอย การจัดกลุ่ม และการเลือกแบบจำลอง โดยใช้ส่วนต่อประสานตัวประมาณค่าที่สอดคล้องกันเพียงตัวเดียว ซึ่งทำให้เวิร์กโฟลว์การเรียนรู้ของเครื่องทั้งหมดสั้น อ่านง่าย และทำซ้ำได้ ตั้งแต่ข้อมูลดิบไปจนถึงการทำนายที่มีคะแนน

Scikit-learn คืออะไร?
วิทย์ - เรียน เป็นโอเพ่นซอร์ส Python ห้องสมุดสำหรับ เรียนรู้เครื่องมันรองรับอัลกอริธึมที่เป็นที่ยอมรับกันดี เช่น KNN, gradient boosting, random forest และ SVM และสร้างขึ้นบนพื้นฐานของ นำพาย และ SciPy Scikit-learn เป็นที่นิยมใช้กันอย่างแพร่หลายในการแข่งขัน Kaggle รวมถึงในบริษัทเทคโนโลยีชั้นนำต่างๆ โดยครอบคลุมการประมวลผลล่วงหน้า การลดมิติ การจำแนกประเภท การถดถอย การจัดกลุ่ม และการเลือกแบบจำลอง
Scikit-learn มีเอกสารประกอบที่ดีที่สุดในบรรดาไลบรารีโอเพนซอร์สทั้งหมด และยังมีแผนภูมิประมาณการแบบโต้ตอบอีกด้วย การเลือกผู้ประเมินราคาที่เหมาะสมซึ่งจะนำคุณจากขนาดของชุดข้อมูลไปสู่รายชื่ออัลกอริธึมที่ควรลองใช้
ภาพด้านล่างนี้แสดงให้เห็นถึงวิธีการทำงานของ Scikit-learn
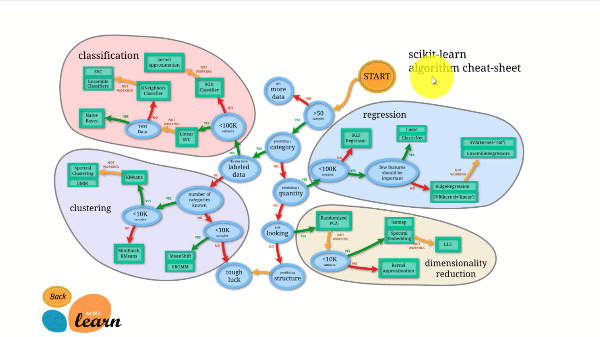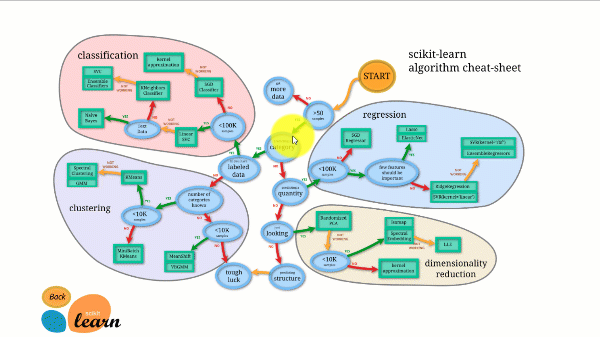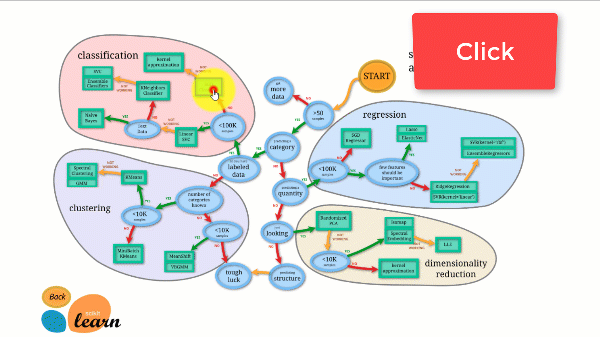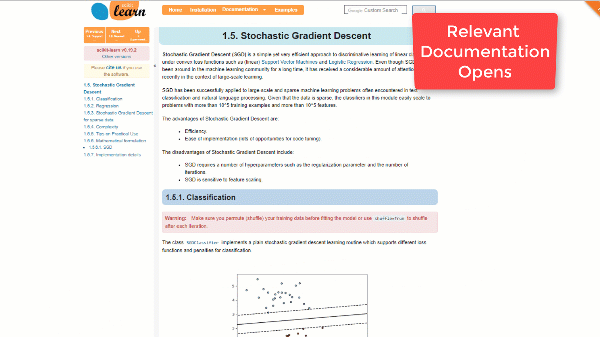
Scikit-learn ใช้งานไม่ยากและให้ผลลัพธ์ที่ยอดเยี่ยม อย่างไรก็ตาม มันทำการฝึกฝนบน CPU โดยการทำงานจะถูกกระจายไปยังคอร์ต่างๆ ด้วยอาร์กิวเมนต์ n_jobs แทนที่จะเป็น GPU การรันอัลกอริธึมการเรียนรู้เชิงลึกด้วย Scikit-learn นั้นเป็นไปได้ แต่ไม่ค่อยได้ผลลัพธ์ที่ดีที่สุด โดยเฉพาะอย่างยิ่งหากคุณรู้วิธีใช้งาน GPU อยู่แล้ว TensorFlow.
วิธีดาวน์โหลดและติดตั้ง Scikit-learn.mq4
ตอนนี้อยู่ในนี้ Python บทช่วยสอน Scikit-learn นี้จะช่วยให้คุณเรียนรู้วิธีการดาวน์โหลดและติดตั้ง Scikit-learn:
ตัวเลือกที่ 1: AWS
สามารถใช้งาน Scikit-learn บน AWS ได้ อิมเมจ Docker ที่ติดตั้ง Scikit-learn ไว้ล่วงหน้าจะช่วยลดขั้นตอนการติดตั้งลงได้อย่างมาก
ในการติดตั้งเวอร์ชันสำหรับนักพัฒนา ให้รันคำสั่งด้านล่างภายใน Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
ตัวเลือกที่ 2: Mac หรือ Windows โดยใช้อนาคอนด้า
หากต้องการเรียนรู้เกี่ยวกับการติดตั้ง Anaconda โปรดดูที่... วิธีการดาวน์โหลดและติดตั้ง TensorFlow.
ในขณะที่เขียนคู่มือการใช้งานนี้ นักพัฒนา scikit ได้ปล่อยเวอร์ชันสำหรับนักพัฒนาที่แก้ไขปัญหาที่มีอยู่ในเวอร์ชันปัจจุบัน ดังนั้นขั้นตอนด้านล่างจึงใช้เวอร์ชันสำหรับนักพัฒนานั้น ในเครื่องคอมพิวเตอร์ที่ติดตั้งใหม่ในปัจจุบัน เวอร์ชันเสถียรล่าสุดมีทรานส์ฟอร์เมอร์ทุกตัวที่ใช้ในที่นี้อยู่แล้ว และ pip install -U scikit-learn ก็เพียงพอแล้ว
วิธีติดตั้ง scikit-learn ด้วย Conda Environment
หากคุณติดตั้ง scikit-learn โดยใช้สภาพแวดล้อม conda โปรดทำตามขั้นตอนด้านล่างเพื่ออัปเดตเป็นเวอร์ชัน 0.20
ขั้นตอนที่ 1) เปิดใช้งานสภาพแวดล้อม TensorFlow
source activate hello-tf
ขั้นตอนที่ 2) ลบ scikit-learn โดยใช้คำสั่ง conda
conda remove scikit-learn
ขั้นตอนที่ 3) ติดตั้งเวอร์ชันสำหรับนักพัฒนา
ติดตั้ง scikit-learn เวอร์ชันสำหรับนักพัฒนา พร้อมกับไลบรารีที่จำเป็น
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
หมายเหตุ: Windows ผู้ใช้ต้องการ Microsoft ของ Visual C++ 14. คุณสามารถรับมันได้ Good Farm Animal Welfare Awards.
ตัวอย่าง Scikit-เรียนรู้ด้วยการเรียนรู้ของเครื่อง
บทช่วยสอน Scikit นี้แบ่งออกเป็นสองส่วน:
- การเรียนรู้ของเครื่องด้วย scikit-learn
- วิธีเชื่อถือโมเดลของคุณด้วย LIME
ส่วนแรกจะอธิบายรายละเอียดวิธีการสร้างไปป์ไลน์ สร้างแบบจำลอง และปรับแต่งไฮเปอร์พารามิเตอร์ ในขณะที่ส่วนที่สองจะกล่าวถึงการตีความแบบจำลอง
ขั้นตอนที่ 1) นำเข้าข้อมูล
ในบทเรียน Scikit learn นี้ คุณจะใช้ชุดข้อมูลสำมะโนประชากรผู้ใหญ่
ไฟล์จะถูกอ่านโดยตรงจากคลังเก็บข้อมูลการเรียนรู้ของเครื่อง UCI ในโค้ดด้านล่าง ดังนั้นจึงไม่จำเป็นต้องดาวน์โหลดด้วยตนเอง หากคุณสนใจสถิติเชิงพรรณนา เครื่องมือ Dive และ Overview ก็คุ้มค่าที่จะลองใช้ ดูเพิ่มเติมได้ที่ บทช่วยสอนนี้ เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับการดำน้ำและภาพรวม
คุณนำเข้าชุดข้อมูลโดยใช้ pandas โปรดทราบว่าคุณต้องแปลงตัวแปรต่อเนื่องให้เป็นรูปแบบทศนิยมก่อน
ชุดข้อมูลนี้ประกอบด้วยตัวแปรเชิงหมวดหมู่แปดตัว ซึ่งแสดงอยู่ใน CATE_FEATURES:
- ชั้นเรียน
- การศึกษา
- สมรส
- อาชีพ
- ความสัมพันธ์
- แข่ง
- เพศ
- พื้นเมือง_ประเทศ
นอกจากนี้ยังประกอบด้วยตัวแปรต่อเนื่องหกตัว ซึ่งระบุไว้ใน CONTI_FEATURES:
- อายุ
- Fnlwgt
- การศึกษา_num
- ทุน_กำไร
- เงินทุน_ขาดทุน
- ชั่วโมง_สัปดาห์
รายการเหล่านี้ถูกกรอกด้วยมือเพื่อให้คุณเห็นภาพชัดเจนขึ้นว่าคอลัมน์ใดบ้างที่เกี่ยวข้อง วิธีที่เร็วกว่าในการสร้างรายการคอลัมน์ประเภทจัดกลุ่มหรือคอลัมน์ต่อเนื่องคือ:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
นี่คือรหัสสำหรับนำเข้าข้อมูล:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
การเรียกใช้ describe() บนเฟรมจะส่งคืนสถิติสรุปสำหรับคอลัมน์ต่อเนื่องทั้งหกคอลัมน์:
| อายุ | Fnlwgt | การศึกษา_num | ทุน_กำไร | เงินทุน_ขาดทุน | ชั่วโมง_สัปดาห์ | |
|---|---|---|---|---|---|---|
| นับ | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| หมายความ | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| มาตรฐาน | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| นาที | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| แม็กซ์ | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
คุณสามารถตรวจสอบจำนวนค่าที่ไม่ซ้ำกันของคุณลักษณะ native_country ได้ มีเพียงครัวเรือนเดียวที่มาจากฮอลแลนด์-เนเธอร์แลนด์ ครัวเรือนนั้นไม่มีข้อมูลและจะทำให้เกิดข้อผิดพลาดระหว่างการฝึกโมเดล
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
คุณสามารถตัดแถวที่ไม่ให้ข้อมูลนี้ออกจากชุดข้อมูลได้:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
ถัดไป คุณจะจัดเก็บตำแหน่งของคุณลักษณะต่อเนื่องในรายการ คุณจะต้องใช้มันในขั้นตอนถัดไปเพื่อสร้างไปป์ไลน์
โค้ดด้านล่างจะวนลูปไปตามชื่อคอลัมน์ทั้งหมดใน CONTI_FEATURES อ่านตำแหน่งแต่ละตำแหน่ง (นั่นคือหมายเลขคอลัมน์) และเพิ่มเข้าไปในลิสต์ที่ชื่อว่า conti_features
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
ส่วนถัดไปจะทำหน้าที่เดียวกันสำหรับตัวแปรเชิงหมวดหมู่
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
ทีนี้ลองมาดูชุดข้อมูลกัน แต่ละคุณลักษณะเชิงหมวดหมู่เป็นค่าสตริง และโมเดลไม่สามารถรับค่าสตริงได้ ดังนั้นชุดข้อมูลจึงต้องถูกแปลงด้วยตัวแปรดัมมี่
df_train.head(5)
อันที่จริง คุณต้องมีคอลัมน์หนึ่งคอลัมน์สำหรับแต่ละกลุ่มในแต่ละคุณลักษณะ ก่อนอื่น ให้รันโค้ดด้านล่างเพื่อคำนวณจำนวนคอลัมน์ทั้งหมดที่ต้องการ
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
ชุดข้อมูลทั้งหมดประกอบด้วย 101 กลุ่ม ดังที่แสดงไว้ข้างต้น คุณลักษณะ workclass เพียงอย่างเดียวมีถึงเก้ากลุ่ม คุณสามารถแสดงรายการชื่อกลุ่มได้ด้วยโค้ดด้านล่าง โดยฟังก์ชัน unique() จะส่งคืนค่าที่ไม่ซ้ำกันของแต่ละคุณลักษณะเชิงหมวดหมู่
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
ดังนั้นชุดข้อมูลฝึกฝนจะมี 101 + 6 คอลัมน์ ได้แก่ กลุ่มวันฮอต (one-hot groups) และคุณลักษณะต่อเนื่องอีกหกรายการ
Scikit-learn สามารถจัดการการแปลงได้ในสองขั้นตอน:
- แปลงสตริงให้เป็น ID เช่น State-gov จะเป็น ID 1, Self-emp-not-inc จะเป็น ID 2 เป็นต้น LabelEncoder จะทำสิ่งนี้ให้คุณ
- ย้าย ID แต่ละตัวไปยังคอลัมน์ใหม่ ชุดข้อมูลมี ID กลุ่ม 101 กลุ่ม ดังนั้นจะมี 101 คอลัมน์ที่บันทึกกลุ่มคุณลักษณะเชิงหมวดหมู่แต่ละกลุ่ม Scikit-learn มี OneHotEncoder สำหรับการดำเนินการนี้
ขั้นตอนที่ 2) สร้างชุดฝึก/ชุดทดสอบ
เมื่อเตรียมชุดข้อมูลพร้อมแล้ว ให้แบ่งชุดข้อมูลเป็น 80/20: 80 เปอร์เซ็นต์สำหรับชุดฝึกฝน และ 20 เปอร์เซ็นต์สำหรับชุดทดสอบ
คุณสามารถใช้ train_test_split ได้ โดยอาร์กิวเมนต์แรกคือ dataframe ของฟีเจอร์ และอาร์กิวเมนต์ที่สองคือป้ายกำกับ คุณกำหนดขนาดของชุดข้อมูลทดสอบด้วย test_size
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
ขั้นตอนที่ 3) สร้างไปป์ไลน์
กระบวนการนี้ช่วยให้ป้อนข้อมูลที่สม่ำเสมอเข้าสู่โมเดลได้ง่ายขึ้น แนวคิดคือการผลักดันข้อมูลดิบผ่านวัตถุเดียวที่ดำเนินการทุกอย่างตามลำดับ
ชุดข้อมูลนี้จำเป็นต้องปรับค่าตัวแปรต่อเนื่องให้เป็นมาตรฐานและแปลงค่าตัวแปรเชิงหมวดหมู่ การดำเนินการใดๆ ก็สามารถทำได้ภายในไปป์ไลน์ เช่น สามารถแทนที่ค่าที่หายไปด้วยค่าเฉลี่ยหรือค่ามัธยฐาน และสามารถสร้างตัวแปรใหม่ได้
คุณมีทางเลือกสองทาง: เขียนโค้ดแบบตายตัวสำหรับสองกระบวนการนี้ หรือสร้างไปป์ไลน์ การเขียนโค้ดแบบตายตัวอาจทำให้ข้อมูลทดสอบรั่วไหลเข้าไปในสถิติที่คำนวณได้ และสร้างความไม่สม่ำเสมอเมื่อเวลาผ่านไป ดังนั้นไปป์ไลน์จึงเป็นตัวเลือกที่ดีกว่า
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
กระบวนการนี้จะดำเนินการสองขั้นตอนก่อนที่จะส่งข้อมูลไปยังตัวจำแนกประเภทโลจิสติกส์:
- แปลงตัวแปรให้เป็นมาตรฐาน: StandardScaler()
- แปลงคุณลักษณะตามหมวดหมู่: OneHotEncoder(sparse=False)
คุณดำเนินการทั้งสองขั้นตอนโดยใช้ make_column_transformer เมื่อเขียนคู่มือนี้ ฟังก์ชันดังกล่าวยังไม่มีอยู่ในเวอร์ชันที่เผยแพร่ของ scikit-learn (0.19) ดังนั้นจึงใช้เวอร์ชันสำหรับนักพัฒนา ซึ่งฟังก์ชันนี้ได้ถูกรวมอยู่ในเวอร์ชันเสถียรทุกเวอร์ชันตั้งแต่ 0.20 เป็นต้นมา
เมธอด make_column_transformer นั้นใช้งานง่าย: คุณเพียงแค่ระบุว่าต้องการแปลงคอลัมน์ใดบ้าง และจะใช้การแปลงแบบใด สำหรับการทำให้คุณลักษณะต่อเนื่องเป็นมาตรฐาน คุณต้องส่งค่าต่อไปนี้:
- conti_features, StandardScaler() ภายใน make_column_transformer
- conti_features: รายชื่อคอลัมน์ต่อเนื่อง
- StandardScaler: ปรับมาตรฐานคอลัมน์เหล่านั้น
อ็อบเจ็กต์ OneHotEncoder ภายใน make_column_transformer จะเข้ารหัสป้ายกำกับโดยอัตโนมัติ
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
หมายเหตุเกี่ยวกับเวอร์ชัน: ข้อโต้แย้งสองข้อในบล็อกด้านบนได้ถูกแก้ไขแล้ว เวอร์ชันปัจจุบันคาดหวังว่าตัวแปลงจะมาก่อนและคอลัมน์จะมาทีหลัง และ กระจัดกระจาย ถูกเปลี่ยนชื่อ เอาต์พุตแบบเบาบาง ใน scikit-learn เวอร์ชัน 1.2 และถูกลบออกในเวอร์ชัน 1.4 ดังนั้นโค้ดเวอร์ชันใหม่กว่าจึงอ่านได้ดังนี้ OneHotEncoder(sparse_output=False).
คุณสามารถทดสอบว่าไปป์ไลน์ทำงานได้หรือไม่โดยใช้ fit_transform ผลลัพธ์ควรมีรูปร่าง 26048, 107
preprocess.fit_transform(X_train).shape
(26048, 107)
ตัวแปลงข้อมูลพร้อมใช้งานแล้ว คุณสร้างไปป์ไลน์ด้วย make_pipeline และเมื่อแปลงข้อมูลเสร็จแล้ว ก็ป้อนข้อมูลเข้าสู่การถดถอยโลจิสติกส์
model = make_pipeline(
preprocess,
LogisticRegression())
การฝึกโมเดลด้วย scikit-learn นั้นง่ายมาก เพียงแค่เรียกใช้เมธอด fit บนไปป์ไลน์ คุณก็สามารถแสดงค่าความแม่นยำได้โดยใช้เมธอด score
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
สุดท้าย คุณสามารถใช้ฟังก์ชัน predict_proba เพื่อทำนายคลาส ซึ่งจะส่งคืนค่าความน่าจะเป็นของแต่ละคลาส โปรดทราบว่าผลรวมของค่าความน่าจะเป็นทั้งสองเท่ากับหนึ่ง
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
ขั้นตอนที่ 4) การใช้ไปป์ไลน์ของเราในการค้นหากริด
การปรับแต่งค่าไฮเปอร์พารามิเตอร์ ซึ่งเป็นค่าที่กำหนดโครงสร้างของแบบจำลอง อาจเป็นเรื่องที่น่าเบื่อและเหน็ดเหนื่อย
วิธีหนึ่งในการประเมินโมเดลคือการเปลี่ยนขนาดของชุดข้อมูลฝึกฝนและวัดประสิทธิภาพ โดยทำซ้ำขั้นตอนนี้สิบครั้งเพื่อดูการกระจายของคะแนน แต่นั่นเป็นงานที่ต้องทำด้วยตนเองจำนวนมาก
แต่ในทางกลับกัน scikit-learn มีฟังก์ชันที่ทำการปรับแต่งพารามิเตอร์และตรวจสอบความถูกต้องแบบไขว้ให้คุณโดยอัตโนมัติ
การตรวจสอบข้าม
การตรวจสอบแบบไขว้ (Cross-validation) หมายความว่า ในระหว่างการฝึกฝน ชุดข้อมูลฝึกฝนจะถูกแบ่งออกเป็น n ส่วน และโมเดลจะถูกประเมินผล n ครั้ง หากตั้งค่า cv เป็น 10 โมเดลจะถูกฝึกฝนและประเมินผลสิบครั้ง ในแต่ละรอบ ตัวจำแนกจะฝึกฝนกับเก้าส่วนที่เลือกแบบสุ่ม และส่วนที่สิบจะถูกเก็บไว้สำหรับการประเมินผล
ค้นหากริด
ตัวจำแนกทุกตัวมีพารามิเตอร์ที่ต้องปรับแต่ง คุณสามารถลองค่าทีละค่า หรือตั้งค่าตารางพารามิเตอร์ก็ได้ เอกสารประกอบของ scikit-learn แสดงรายการพารามิเตอร์ทั้งหมดที่ตัวจำแนกแบบโลจิสติกยอมรับ เพื่อให้การฝึกฝนรวดเร็ว ตัวอย่างนี้จึงปรับแต่งเฉพาะพารามิเตอร์ C ซึ่งควบคุมการปรับค่าให้เป็นมาตรฐาน ค่านี้ต้องเป็นบวก และค่าที่น้อยจะให้น้ำหนักกับการปรับค่าให้เป็นมาตรฐานมากขึ้น
คุณใช้ GridSearchCV object ซึ่งรับพจนานุกรมของไฮเปอร์พารามิเตอร์ที่ต้องการปรับแต่ง ระบุไฮเปอร์พารามิเตอร์แต่ละตัวตามด้วยค่าที่คุณต้องการลอง สำหรับการปรับแต่ง C คุณเขียนดังนี้:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — ชื่อพารามิเตอร์นำหน้าด้วยชื่อตัวจำแนกประเภทที่เป็นตัวพิมพ์เล็กและมีเครื่องหมายขีดล่างสองตัว
โมเดลจะลองใช้ค่าที่แตกต่างกันสี่ค่า ได้แก่ 0.001, 0.01, 0.1 และ 1 โดยจะทำการฝึกฝนด้วยการแบ่งข้อมูลออกเป็น 10 ส่วน (folds) นั่นคือ cv=10
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
ตอนนี้คุณสามารถฝึกฝนโมเดลโดยใช้ GridSearchCV ด้วยพารามิเตอร์ grid และ cv ได้แล้ว
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Output:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
หมายเหตุเกี่ยวกับเวอร์ชัน: ไอไอดี อาร์กิวเมนต์ที่ปรากฏในเอาต์พุตนี้ถูกยกเลิกการใช้งานใน scikit-learn เวอร์ชัน 0.22 และถูกลบออกในเวอร์ชัน 0.24 ดังนั้นจึงควรตัดออกจากการเรียกใช้ GridSearchCV ในเวอร์ชันปัจจุบัน
หากต้องการเข้าถึงพารามิเตอร์ที่ดีที่สุด ให้ใช้ best_params_
grid_clf.best_params_
Output:
{'logisticregression__C': 1.0}
หลังจากฝึกฝนโมเดลด้วยค่าการปรับค่าความเรียบ (regularisation) ที่แตกต่างกันสี่ค่าแล้ว พารามิเตอร์ที่เหมาะสมที่สุดจะได้ดังนี้:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
การถดถอยโลจิสติกที่ดีที่สุดจากการค้นหากริด: 0.850891
วิธีเข้าถึงความน่าจะเป็นที่คาดการณ์ไว้:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
โมเดล XGBoost พร้อม scikit-learn
ลองใช้หนึ่งในตัวจำแนกประเภทที่ทรงพลังที่สุดในตลาดดูสิ XGBoost คือการปรับปรุง Random Forest โดยใช้ Gradient Boosting ส่วนพื้นฐานทางทฤษฎีนั้นอยู่นอกเหนือขอบเขตของบทความนี้ Python ดูบทช่วยสอนของ Scikit แต่โปรดจำไว้ว่า XGBoost ได้รับรางวัลจากการแข่งขัน Kaggle มามากมาย ในชุดข้อมูลขนาดเฉลี่ย มันสามารถทำงานได้ดีเท่ากับหรือดีกว่าอัลกอริธึมการเรียนรู้เชิงลึก
การฝึกฝนตัวจำแนกประเภทนั้นค่อนข้างท้าทาย เนื่องจากมีพารามิเตอร์จำนวนมาก คุณสามารถใช้ GridSearchCV เพื่อช่วยเลือกพารามิเตอร์เหล่านั้นได้
ตัวเลือกที่ดีกว่าคือ RandomizedSearchCV GridSearchCV จะทำงานช้าลงเมื่อตารางมีขนาดใหญ่ เนื่องจากพื้นที่การค้นหาจะขยายใหญ่ขึ้นทุกครั้งที่มีการเพิ่มพารามิเตอร์ ในทางกลับกัน RandomizedSearchCV จะสุ่มค่าของแต่ละไฮเปอร์พารามิเตอร์ในแต่ละรอบการวนซ้ำ ดังนั้น 1,000 รอบการวนซ้ำจะประเมิน 1,000 ชุดค่าผสม โดยหลักการทำงานอื่นๆ คล้ายกับ GridSearchCV มาก
คุณต้องนำเข้า xgboost หากไลบรารีไม่ได้ติดตั้ง ให้เรียกใช้คำสั่ง pip3 install xgboost หรือติดตั้งจากภายในไฟล์ .xgboost Jupyter สมุดบันทึกที่มี:
use import sys
!{sys.executable} -m pip install xgboost
จากนั้นนำเข้าตัวจำแนกประเภทและตัวช่วยค้นหาทั้งสองตัว:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
ก้าวต่อไปใน Scikit นี้ Python บทช่วยสอนนี้มีจุดประสงค์เพื่อระบุพารามิเตอร์ที่จะปรับแต่ง เอกสารอย่างเป็นทางการของ XGBoost ระบุพารามิเตอร์ทั้งหมดไว้แล้ว สำหรับบทช่วยสอนนี้ Python ในบทช่วยสอนของ Sklearn คุณจะเลือกไฮเปอร์พารามิเตอร์เพียงสองตัว โดยแต่ละตัวมีค่าสองค่า เนื่องจาก XGBoost ใช้เวลานานในการฝึกฝน และจุดกริดเพิ่มเติมแต่ละจุดจะทำให้เวลาในการรอเพิ่มขึ้น
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
จากนั้นคุณสร้างไปป์ไลน์ใหม่โดยใช้ตัวจำแนก XGBoost และตัวประมาณค่า 600 ตัว n_estimators สามารถปรับแต่งได้ และค่าที่สูงเกินไปอาจนำไปสู่การโอเวอร์ฟิตติ้ง คุณสามารถลองใช้ค่าอื่นๆ ได้ แต่โปรดทราบว่าอาจใช้เวลานานหลายชั่วโมง พารามิเตอร์อื่นๆ ทั้งหมดจะคงค่าเริ่มต้นไว้
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
คุณสามารถปรับปรุงการตรวจสอบความถูกต้องแบบไขว้ (cross-validation) ด้วยตัวตรวจสอบความถูกต้องแบบไขว้ Stratified K-Folds ได้ ในที่นี้ใช้เพียงสามส่วน (folds) เพื่อเพิ่มความเร็วในการคำนวณ แต่จะทำให้คุณภาพลดลงบ้าง หากต้องการผลลัพธ์ที่ดีกว่า ควรเพิ่มเป็น 5 หรือ 10 ส่วนในเครื่องของคุณเอง โมเดลนี้ได้รับการฝึกฝนซ้ำทั้งหมดสี่รอบ
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
การค้นหาแบบสุ่มพร้อมแล้ว คุณจึงสามารถเริ่มฝึกฝนโมเดลได้
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
อย่างที่คุณเห็น XGBoost ให้ผลลัพธ์ที่ดีกว่าการถดถอยโลจิสติกส์แบบเดิม
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
สร้าง DNN ด้วย MLPClassifier ใน scikit-learn
สุดท้ายนี้ คุณสามารถฝึกโครงข่ายประสาทเทียมด้วย scikit-learn ได้โดยตรง วิธีการนั้นเหมือนกับตัวจำแนกประเภทอื่นๆ และใช้ MLPClassifier เป็นตัวประมาณค่า
from sklearn.neural_network import MLPClassifier
เครือข่ายด้านล่างนี้ถูกกำหนดด้วย:
- อดัม นักแก้ปัญหา
- ฟังก์ชั่นการเปิดใช้งาน ReLU
- อัลฟ่า = 0.0001
- ขนาดชุด 150
- สองชั้นที่ซ่อนอยู่ซึ่งมีเซลล์ประสาท 200 และ 100 เซลล์ตามลำดับ
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
คุณสามารถเปลี่ยนจำนวนเลเยอร์เพื่อปรับปรุงโมเดลได้
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
คะแนนการถดถอย DNN: 0.821253
LIME: เชื่อถือโมเดลของคุณ
เมื่อคุณมีแบบจำลองที่ดีแล้ว คุณจำเป็นต้องมีวิธีที่จะเชื่อถือแบบจำลองนั้น อัลกอริทึมการเรียนรู้ของเครื่อง โดยเฉพาะอย่างยิ่ง Random Forests และ Neural Networks เป็นที่รู้จักกันในชื่อแบบจำลองกล่องดำ: มันทำงานได้ แต่ไม่มีใครสามารถเห็นได้ว่าทำไม
นักวิจัยสามคนได้สร้างเครื่องมือที่แสดงให้เห็นว่าคอมพิวเตอร์ทำการคาดการณ์ได้อย่างไร บทความของพวกเขาคือ... “ทำไมฉันถึงควรเชื่อใจคุณ?”และอัลกอริทึมที่พวกเขาเผยแพร่มีชื่อว่า Local Interpretable Model-Agnostic Explanations (LIME)
ยกตัวอย่างเช่น บางครั้งคุณอาจไม่รู้ว่าผลการทำนายจากแมชชีนเลิร์นนิงนั้นเชื่อถือได้หรือไม่ แพทย์ไม่สามารถยอมรับการวินิจฉัยเพียงเพราะคอมพิวเตอร์สร้างขึ้นมาได้ และคุณจำเป็นต้องรู้ว่าแบบจำลองนั้นเชื่อถือได้หรือไม่ก่อนที่จะนำไปใช้งานจริง
ลองนึกภาพว่าคุณสามารถเห็นได้ว่าทำไมตัวจำแนกใดๆ จึงทำการทำนาย แม้แต่สำหรับโมเดลที่ซับซ้อนอย่างโครงข่ายประสาทเทียม ป่าสุ่ม หรือ SVM ที่มีเคอร์เนลแบบกำหนดเอง การเชื่อถือการทำนายจะง่ายขึ้นมากเมื่อมองเห็นเหตุผลเบื้องหลัง และการตัดสินใจว่าเมื่อใดไม่ควรเชื่อถือโมเดลก็จะง่ายขึ้นเช่นกัน LIME จะบอกคุณว่าคุณลักษณะใดที่ขับเคลื่อนการตัดสินใจของตัวจำแนก
การเตรียมข้อมูล
มีบางสิ่งที่คุณต้องเปลี่ยนแปลงเพื่อให้สามารถใช้งาน LIME ได้ Pythonขั้นแรก ติดตั้ง Lime ในเทอร์มินัลด้วยคำสั่ง pip install lime
Lime ใช้ object LimeTabularExplainer เพื่อประมาณแบบจำลองในระดับท้องถิ่น object นี้ต้องการ:
- ชุดข้อมูลใน นำพาย รูป
- ชื่อของคุณสมบัติ: Feature_names
- ชื่อของคลาส: class_names
- ดัชนีของคอลัมน์คุณลักษณะตามหมวดหมู่: categorical_features
- ชื่อกลุ่มสำหรับคุณลักษณะเชิงหมวดหมู่แต่ละรายการ: categorical_names
สร้างชุดข้อมูลรถไฟ NumPy
คุณสามารถคัดลอกและแปลง df_train จาก pandas ไปยัง NumPy ได้อย่างง่ายดาย
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
รับชื่อชั้นเรียน
สามารถเข้าถึงป้ายกำกับได้โดยใช้ unique() คุณควรเห็น:
- '<=50K'
- '>50K'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
จัดทำดัชนีคอลัมน์คุณลักษณะเชิงหมวดหมู่
ใช้เมธอดที่คุณเรียนรู้ก่อนหน้านี้เพื่อรับชื่อของแต่ละกลุ่ม คุณเข้ารหัสป้ายกำกับด้วย LabelEncoder และทำซ้ำขั้นตอนดังกล่าวกับคุณลักษณะเชิงหมวดหมู่ทุกรายการ
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
เมื่อชุดข้อมูลพร้อมแล้ว คุณสามารถสร้างชุดข้อมูลต่างๆ ที่แสดงในตัวอย่าง Scikit learn ด้านล่างได้ ข้อมูลจะถูกแปลงภายนอกไปป์ไลน์ในที่นี้เพื่อหลีกเลี่ยงข้อผิดพลาดกับ LIME: ชุดข้อมูลฝึกฝนที่ส่งไปยัง LimeTabularExplainer ต้องเป็นอาร์เรย์ NumPy ที่ไม่มีสตริง และวิธีการข้างต้นได้สร้างอาร์เรย์ดังกล่าวไว้แล้ว
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
คุณสามารถสร้างไปป์ไลน์ด้วยพารามิเตอร์ที่เหมาะสมที่สุดซึ่งค้นพบโดย XGBoost ได้
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
คุณจะได้รับคำเตือน ซึ่งอธิบายว่าคุณไม่จำเป็นต้องสร้างตัวเข้ารหัสป้ายกำกับก่อนเริ่มกระบวนการ หากคุณไม่ได้ใช้ LIME วิธีการจากส่วนแรกของบทช่วยสอนการเรียนรู้เครื่องจักรด้วย Scikit-learn นี้ก็ใช้ได้ดี แต่ถ้าใช้ LIME ให้ใช้วิธีนี้: สร้างชุดข้อมูลที่เข้ารหัสก่อน จากนั้นจึงใช้ตัวเข้ารหัสแบบ one-hot ภายในกระบวนการ
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
ก่อนเริ่มใช้งาน LIME ให้สร้างอาร์เรย์ NumPy ที่เก็บคุณลักษณะของแถวที่จัดประเภทผิดพลาด คุณสามารถใช้รายการนั้นในภายหลังเพื่อทำความเข้าใจว่าอะไรทำให้ตัวจัดประเภทเข้าใจผิด
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
จากนั้นสร้างฟังก์ชันแลมบ์ดาที่ดึงค่าการทำนายจากโมเดลสำหรับข้อมูลใหม่ คุณจะต้องใช้ฟังก์ชันนี้ในไม่ช้า
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
คุณแปลง DataFrame ของ pandas ให้เป็นอาร์เรย์ NumPy
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
ทีนี้ลองสุ่มเลือกครัวเรือนหนึ่งจากชุดข้อมูลทดสอบ แล้วดูทั้งผลการทำนายและวิธีการที่คอมพิวเตอร์คำนวณออกมา
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
คุณสามารถใช้ฟังก์ชัน explainer ร่วมกับ explain_instance เพื่อตรวจสอบเหตุผลเบื้องหลังโมเดลได้ แผนภูมิที่แสดงจะมีค่าดังภาพด้านล่าง
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

ระบบจำแนกประเภททำนายครัวเรือนนี้ได้อย่างถูกต้อง: รายได้สูงกว่า 50 จริง ๆ
สิ่งแรกที่ควรสังเกตคือ ตัวจำแนกประเภทนี้ไม่ค่อยมั่นใจในตัวเองนัก มันทำนายรายได้ที่สูงกว่า 50 ด้วยความน่าจะเป็น 64% และความน่าจะเป็น 64% นั้นขึ้นอยู่กับกำไรจากสินทรัพย์และสถานภาพสมรส เส้นสีน้ำเงินส่งผลลบต่อกลุ่มที่มีรายได้สูง และเส้นสีส้มส่งผลบวก
ผู้ประเมินลังเลใจเนื่องจากกำไรจากการลงทุนของครัวเรือนนี้เป็นศูนย์ ในขณะที่กำไรจากการลงทุนมักเป็นตัวบ่งชี้ความมั่งคั่งที่ดี นอกจากนี้ ครัวเรือนนี้ทำงานน้อยกว่า 40 ชั่วโมงต่อสัปดาห์ อายุ อาชีพ และเพศ ล้วนเป็นปัจจัยที่ส่งผลดี
หากสถานภาพสมรสเป็นโสด ตัวจำแนกประเภทจะคาดการณ์รายได้ต่ำกว่า 50 (0.64 – 0.18 = 0.46)
ทีนี้ลองดูครัวเรือนอื่นบ้าง ครัวเรือนที่ถูกจัดประเภทผิดพลาด แผนภูมิอธิบายสำหรับครัวเรือนนั้นจะอยู่ถัดจากรหัส
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

ตัวจำแนกประเภทคาดการณ์รายได้ต่ำกว่า 50 ซึ่งไม่ถูกต้อง ครัวเรือนนี้มีความผิดปกติ คือ ไม่มีกำไรหรือขาดทุนจากสินทรัพย์ บุคคลนั้นหย่าร้างแล้ว อายุใกล้ 60 ปี และมีการศึกษา คือมีระดับการศึกษามากกว่า 12 เมื่อพิจารณาตามรูปแบบโดยรวมแล้ว ตัวจำแนกประเภทจึงจัดให้ครัวเรือนนี้มีรายได้ต่ำกว่า 50
ลองใช้งาน LIME ด้วยตัวเอง แล้วคุณจะสังเกตเห็นข้อผิดพลาดมากมายจากตัวจำแนกประเภท เอกสารเพิ่มเติมเกี่ยวกับการจำแนกภาพและข้อความมีอยู่ในคลัง GitHub ของผู้พัฒนาไลบรารี
คู่มือคำสั่ง Scikit-learn
ด้านล่างนี้คือรายการคำสั่งที่มีประโยชน์ซึ่งใช้ได้กับ scikit-learn เวอร์ชัน 0.20 และเวอร์ชันที่ใหม่กว่า
| งาน | ฟังก์ชันหรือคลาส |
|---|---|
| สร้างชุดข้อมูลฝึกฝน/ทดสอบ | รถไฟ_test_split |
| สร้างท่อส่งน้ำ | |
| เลือกคอลัมน์และใช้การแปลงข้อมูล | สร้างตัวแปลงคอลัมน์ |
| ประเภทของการแปลง | |
| กำหนดมาตรฐาน | เครื่องชั่งน้ำหนักมาตราฐาน |
| การปรับขนาดค่าต่ำสุด-สูงสุด | MinMaxScaler |
| ทำให้เป็นปกติ | นอร์มัลไลเซอร์ |
| เติมค่าที่หายไป | ซิมเพิลอิมพิวเตอร์ |
| แปลงเด็ดขาด | OneHotEncoder |
| พอดีและแปลงข้อมูล | พอดี_แปลงร่าง |
| ทำท่อ | make_ไปป์ไลน์ |
| แบบจำลองพื้นฐาน | |
| การถดถอยโลจิสติก | การถดถอยโลจิสติก |
| XGBoost | XGBคลาสซิฟายเออร์ |
| โครงข่ายประสาท | MLPลักษณนาม |
| ค้นหากริด | GridSearchCV |
| การค้นหาแบบสุ่ม | สุ่มค้นหาCV |