วิธีการดาวน์โหลดและติดตั้ง NLTK
⚡ สรุปอย่างชาญฉลาด
ดาวน์โหลดและติดตั้ง NLTK บน WindowsMac หรือ Linux โดยการติดตั้ง Python อันดับแรก จากนั้นจึงเติมส่วนผสมจากธรรมชาติ Language Toolใช้ชุดเครื่องมือผ่าน pip หรือ Anaconda และดาวน์โหลดชุดข้อมูลคอร์ปัส

การติดตั้ง NLTK ใน Windows
เรียนรู้วิธีการตั้งค่า NLTK บน Windows จากพรอมต์คำสั่ง คำแนะนำด้านล่างนี้สมมติว่า Python ยังไม่ได้ติดตั้ง ดังนั้นขั้นตอนแรกคือการติดตั้ง Python.
การติดตั้ง Python in Windows
ขั้นตอน 1) เปิดลิงก์ https://www.python.org/downloads/, และเลือกเวอร์ชันล่าสุด Windows ปล่อย
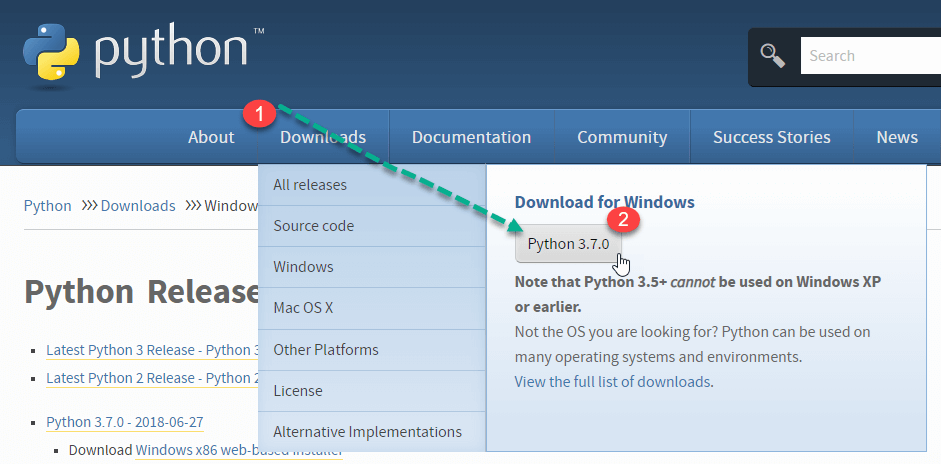
หมายเหตุ: สำหรับเวอร์ชันเก่ากว่า โปรดไปที่แท็บดาวน์โหลดเพื่อดูเวอร์ชันทั้งหมด

ขั้นตอน 2) คลิกไฟล์ติดตั้งที่ดาวน์โหลดมา

ขั้นตอน 3) เลือก ปรับแต่งการติดตั้ง
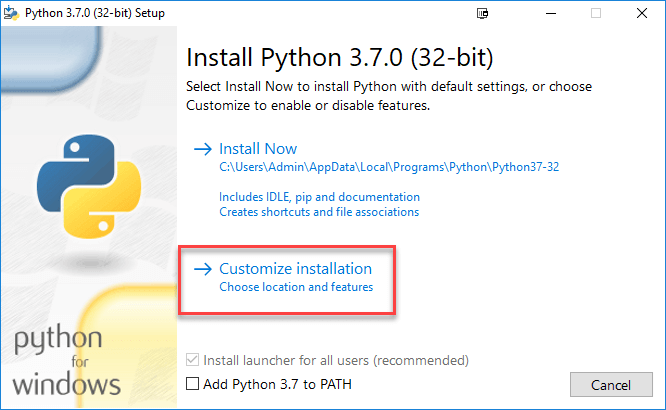
ขั้นตอน 4) คลิกถัดไป

ขั้นตอน 5) ในหน้าจอถัดไป:
- เลือกตัวเลือกขั้นสูง
- ระบุตำแหน่งการติดตั้งที่กำหนดเอง ในตัวอย่างนี้ เลือกโฟลเดอร์ในไดรฟ์ C เพื่อความสะดวกในการเข้าถึง
- คลิกติดตั้ง

ขั้นตอน 6) เมื่อการติดตั้งเสร็จสิ้นแล้ว ให้คลิกปุ่มปิด

ขั้นตอน 7) คัดลอกเส้นทางของโฟลเดอร์สคริปต์ของคุณ

ขั้นตอน 8) ตัว Vortex Indicator ได้ถูกนำเสนอลงในนิตยสาร Windows พร้อมท์คำสั่ง:
- ไปยังตำแหน่งที่ตั้งของโฟลเดอร์ pip
- ป้อนคำสั่งเพื่อติดตั้ง NLTK:
pip3 install nltk
- การติดตั้งน่าจะเสร็จสมบูรณ์โดยไม่มีปัญหา

หมายเหตุ: สำหรับ Python 2. ใช้คำสั่ง pip2 install nltk.
ขั้นตอน 9) จาก Windows เมนูเริ่มต้น ค้นหาและเปิด Python เปลือก.

ขั้นตอน 10) ตรวจสอบว่าการติดตั้งทำงานได้อย่างถูกต้องโดยเรียกใช้คำสั่งด้านล่าง:
import nltk

หากไม่มีข้อผิดพลาดใดๆ เกิดขึ้น การติดตั้งก็เสร็จสมบูรณ์แล้ว
การติดตั้ง NLTK ใน Mac/Linux
การติดตั้ง NLTK บน Mac หรือ Linux ต้องใช้... Python ตัวจัดการแพ็กเกจ pip หากไม่ได้ติดตั้ง pip โปรดทำตามคำแนะนำด้านล่างเพื่อดำเนินการให้เสร็จสมบูรณ์
ขั้นตอน 1) อัปเดตดัชนีแพ็กเกจโดย typing คำสั่งด้านล่างนี้:
sudo apt update
ขั้นตอน 2) ติดตั้ง pip สำหรับ Python 3:
sudo apt install python3-pip
คุณสามารถติดตั้ง pip ผ่าน easy_install ได้เช่นกัน:
sudo apt-get install python-setuptools python-dev build-essential
เมื่อติดตั้ง easy_install เสร็จแล้ว ให้รันคำสั่งด้านล่างเพื่อติดตั้ง pip:
sudo easy_install pip
ขั้นตอน 3) ใช้คำสั่งต่อไปนี้เพื่อติดตั้ง NLTK:
sudo pip install -U nltk sudo pip3 install -U nltk
การติดตั้ง NLTK ผ่าน Anaconda
ขั้นตอน 1) ติดตั้ง Anaconda โดยไปที่ https://www.anaconda.com/products/individual และเลือก Python เวอร์ชันที่คุณต้องการ

หมายเหตุ: โปรดดูบทช่วยสอนนี้สำหรับขั้นตอนโดยละเอียด ติดตั้ง Anaconda.
ขั้นตอน 2) ในข้อความแจ้งเตือนของ Anaconda:
- ป้อนคำสั่ง:
conda install -c anaconda nltk
- Revดูข้อมูลการอัปเกรด ดาวน์เกรด และการติดตั้งแพ็กเกจ จากนั้นป้อน "ใช่"
- NLTK ถูกดาวน์โหลดและติดตั้งเรียบร้อยแล้ว

ชุดข้อมูล NLTK
โมดูล NLTK มาพร้อมกับชุดข้อมูลจำนวนมากที่คุณต้องดาวน์โหลดก่อนใช้งาน ในทางเทคนิคแล้ว ชุดข้อมูลแต่ละชุดเรียกว่า `dataset` คลังตัวอย่างทั่วไปได้แก่ คำหยุด, กูเทนเบิร์ก, framenet_v15, large_grammars, สีน้ำตาลและ เวิร์ดเน็ต.
วิธีดาวน์โหลดแพ็คเกจทั้งหมดของ NLTK
ขั้นตอน 1) เรียกใช้ Python ล่าม in Windows หรือลินุกซ์
ขั้นตอน 2)
- ป้อนคำสั่ง:
import nltk nltk.download ()
- หน้าต่าง NLTK Downloader จะเปิดขึ้น คลิกปุ่ม Download เพื่อดาวน์โหลดชุดข้อมูล กระบวนการนี้ใช้เวลาขึ้นอยู่กับความเร็วอินเทอร์เน็ตของคุณ

หมายเหตุ: คุณสามารถเปลี่ยนตำแหน่งที่ดาวน์โหลดได้โดยคลิกที่ ไฟล์ > เปลี่ยนไดเร็กทอรีดาวน์โหลด

ขั้นตอน 3) หากต้องการทดสอบข้อมูลที่ติดตั้ง ให้ใช้โค้ดต่อไปนี้:
>>> from nltk.corpus import brown >>>brown.words()
['เดอะ', 'ฟุลตัน', 'เคาน์ตี', 'แกรนด์', 'คณะลูกขุน', 'พูด', …]

การรันสคริปต์ NLP
ส่วนนี้อธิบายวิธีการทำงานของสคริปต์ NLP บนพีซีในเครื่อง การเลือกไลบรารีที่เหมาะสมนั้นขึ้นอยู่กับความต้องการของคุณ ดูรายการอย่างเป็นทางการได้ที่นี่ ห้องสมุด NLP สำหรับทางเลือกอื่นๆ เช่น spaCy, gensim และ TextBlob
วิธีเรียกใช้สคริปต์ NLTK
ขั้นตอน 1) ในโปรแกรมแก้ไขโค้ดที่คุณชื่นชอบ ให้คัดลอกโค้ดและบันทึกไฟล์เป็น NLTKsample.py:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)

Code คำอธิบาย:
- จุดประสงค์ของโปรแกรมนี้คือการลบเครื่องหมายวรรคตอนทุกชนิดออกจากข้อความที่กำหนด เราได้นำเข้าโมดูล “RegexpTokenizer” จากไลบรารีหนึ่ง เอ็นแอลทีเค ซึ่งจะลบนิพจน์ สัญลักษณ์ อักขระ หรือค่าตัวเลขใดๆ ที่คุณเลือกออกไป
- มีการส่งนิพจน์ปกติไปยังโมดูล “RegexpTokenizer”
- ข้อความจะถูกแยกเป็นโทเค็นโดยใช้วิธี "tokenize" และผลลัพธ์จะถูกเก็บไว้ในตัวแปร "filterdText"
- ผลลัพธ์จะถูกพิมพ์โดยใช้ฟังก์ชัน “print()”
ขั้นตอน 2) ในหน้าต่างคำสั่ง:
- ไปยังตำแหน่งที่คุณบันทึกไฟล์ไว้
- เรียกใช้คำสั่ง
python NLTKsample.py.

ผลลัพธ์คือ:
['สวัสดี', 'Guru[99', 'คุณ', 'มี', 'สร้าง', 'เว็บไซต์', 'ดีมาก', 'และ', 'ฉัน', 'ชอบ', 'เยี่ยมชม', 'เว็บไซต์ของคุณ']