50 SQL-intervjufrågor och svar för 2026
SQL-intervjufrågor för nybörjare
1. Vad är DBMS?
Ett databashanteringssystem (DBMS) är ett program som kontrollerar skapande, underhåll och användning av en databas. DBMS kan betecknas som filhanterare som hanterar data i en databas snarare än att spara dem i filsystem.
👉 Gratis PDF-nedladdning: SQL-intervjufrågor och svar >>
2. Vad är RDBMS?
RDBMS står för Relational Database Management System. RDBMS lagrar data i samlingen av tabeller, som är relaterad till vanliga fält mellan tabellens kolumner. Det tillhandahåller också relationsoperatorer för att manipulera data som lagras i tabellerna.
Exempel: SQL Server.
3. Vad är SQL?
SQL står för Structured Query Language, och det används för att kommunicera med databasen. Detta är ett standardspråk som används för att utföra uppgifter som hämtning, uppdatering, infogning och radering av data från en databas.
Standard SQL-kommandon är Välj.
4. Vad är en databas?
Databas är inget annat än en organiserad form av data för enkel åtkomst, lagring, hämtning och hantering av data. Detta är också känt som strukturerad form av data som kan nås på många sätt.
Exempel: School Management Database, Bank Management Database.
5. Vad är tabeller och fält?
En tabell är en uppsättning data som är organiserade i en modell med kolumner och rader. Kolumner kan kategoriseras som vertikala och rader är horisontella. En tabell har specificerat antal kolumner som kallas fält men kan ha valfritt antal rader som kallas post.
Exempel:.
Tabell: Anställd.
Fält: Emp ID, Emp Namn, Födelsedatum.
Data: 201456, David, 11-15-1960.
6. Vad är en primär nyckel?
A primär nyckel är en kombination av fält som unikt anger en rad. Detta är en speciell typ av unik nyckel, och den har en implicit NOT NULL-begränsning. Det betyder att primärnyckelvärden inte kan vara NULL.
7. Vad är en unik nyckel?
En unik nyckelbegränsning identifierade varje post i databasen unikt. Detta ger en unikhet för kolumnen eller uppsättningen kolumner.
En primärnyckelbegränsning har en automatisk unik begränsning definierad. Men inte, i fallet med Unique Key.
Det kan finnas många unika begränsningar definierade per tabell, men endast en primärnyckelbegränsning definierad per tabell.
8. Vad är en främmande nyckel?
En främmande nyckel är en tabell som kan relateras till primärnyckeln i en annan tabell. Relation måste skapas mellan två tabeller genom att referera främmande nyckel med primärnyckeln för en annan tabell.
9. Vad är en join?
Detta är ett nyckelord som används för att söka efter data från fler tabeller baserat på förhållandet mellan tabellernas fält. Nycklar spelar en stor roll när JOINs används.
10. Vilka typer av gå med och förklara var och en?
ikon olika typer av sammanfogning som kan användas för att hämta data och det beror på relationen mellan tabeller.
- Inre koppling.
Inre sammanfoga returrader när det finns minst en matchning av rader mellan borden.
- Höger Gå med.
Höger sammanfoga returrader som är gemensamma mellan tabellerna och alla rader i höger sidotabell. Helt enkelt returnerar den alla rader från den högra sidotabellen även om det inte finns några matchningar i den vänstra sidotabellen.
- Vänster Gå med.
Vänster sammanfoga returrader som är gemensamma mellan tabellerna och alla rader på vänster sidobord. Helt enkelt returnerar den alla rader från vänster sidotabell även om det inte finns några matchningar i höger sidotabell.
- Fullständigt gå med.
Full sammanfoga returrader när det finns matchande rader i någon av tabellerna. Det betyder att den returnerar alla rader från den vänstra sidotabellen och alla rader från den högra sidotabellen.
SQL-intervjufrågor för 3 års erfarenhet
11. Vad är normalisering?
Normalisering är processen att minimera redundans och beroende genom att organisera fält och tabeller i en databas. Huvudsyftet med normalisering är att lägga till, ta bort eller ändra fält som kan göras i en enda tabell.
12. Vad är denormalisering?
DeNormalization är en teknik som används för att komma åt data från högre till lägre normala former av databas. Det är också processen att införa redundans i en tabell genom att införliva data från de relaterade tabellerna.
13. Vilka är alla olika normaliseringar?
Databas Normalisering kan lätt förstås med hjälp av en fallstudie. De normala formerna kan delas in i 6 former, och de förklaras nedan -.
.png)
- Första normala formen (1NF):.
Detta bör ta bort alla dubbletter av kolumner från tabellen. Skapande av tabeller för relaterade data och identifiering av unika kolumner.
- Andra normala formen (2NF):.
Uppfyller alla krav i den första normala formen. Placera delmängder av data i separata tabeller och Skapa relationer mellan tabellerna med hjälp av primärnycklar.
- Tredje normalformen (3NF):.
Detta bör uppfylla alla krav i 2NF. Ta bort kolumner som inte är beroende av primärnyckelbegränsningar.
- Fjärde normalformen (4NF):.
Om ingen databastabellinstans innehåller två eller flera, oberoende och flervärdesdata som beskriver den relevanta enheten, är den i 4th Normal form.
- Femte normalformen (5NF):.
En tabell är i 5:e normalform endast om den är i 4NF och den kan inte delas upp i ett antal mindre tabeller utan att data går förlorade.
- Sjätte normalformen (6NF):.
6:e normalformen är inte standardiserad, men den har dock diskuterats av databasexperter under en tid. Förhoppningsvis skulle vi ha en tydlig och standardiserad definition för 6:e normalformen inom en snar framtid...
14. Vad är en vy?
En vy är en virtuell tabell som består av en delmängd av data som finns i en tabell. Vyer är inte praktiskt taget närvarande, och det tar mindre utrymme att lagra. View kan ha data för en eller flera tabeller kombinerade, och det beror på relationen.
15. Vad är ett index?
Ett index är en prestandajusteringsmetod för att möjliggöra snabbare hämtning av poster från tabellen. Ett index skapar en post för varje värde och det blir snabbare att hämta data.
16. Vilka är alla olika typer av index?
Det finns tre typer av index -.
- Enkelt index.
Denna indexering tillåter inte att fältet har dubbletter av värden om kolumnen är unikt indexerad. Unikt index kan tillämpas automatiskt när primärnyckeln är definierad.
- Clustered Index.
Denna typ av index ändrar den fysiska ordningen för tabellen och sökningen baserat på nyckelvärdena. Varje tabell kan bara ha ett klustrat index.
- EjClustered Index.
EjClustered Index ändrar inte tabellens fysiska ordning och upprätthåller logisk dataordning. Varje tabell kan ha 999 icke-klustrade index.
17. Vad är en markör?
En databasmarkör är en kontroll som gör det möjligt att gå över raderna eller posterna i tabellen. Detta kan ses som en pekare till en rad i en uppsättning rader. Markören är mycket användbar för att korsa, såsom hämtning, tillägg och borttagning av databasposter.
18. Vad är ett förhållande och vad är det?
Databasrelation definieras som kopplingen mellan tabellerna i en databas. Det finns olika databasrelationer, och de är följande:.
- Ett till ett förhållande.
- En till många relation.
- Många till ett förhållande.
- Självrefererande förhållande.
19. Vad är en fråga?
En DB-fråga är en kod skriven för att få tillbaka informationen från databasen. Frågan kan utformas på ett sådant sätt att den matchar våra förväntningar på resultatet. Helt enkelt en fråga till databasen.
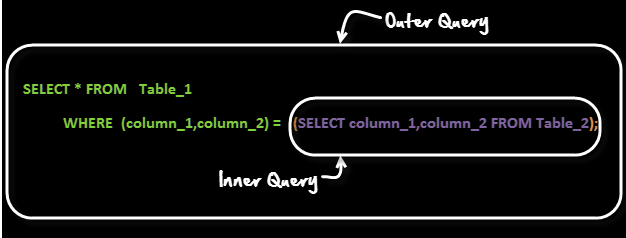
20. Vad är subquery?
En underfråga är en fråga i en annan fråga. Den yttre frågan kallas huvudfrågan, och den inre frågan kallas underfrågan. SubQuery exekveras alltid först, och resultatet av subquery skickas vidare till huvudfrågan.
Låt oss titta på syntaxen för underfrågan –
Ett vanligt kundklagomål på MyFlix Video Library är det låga antalet filmtitlar. Ledningen vill köpa filmer för en kategori som har minst antal titlar.
Du kan använda en fråga som
SELECT category_name FROM categories WHERE category_id =( SELECT MIN(category_id) from movies);
SQL-intervjufrågor för 5 års erfarenhet
21. Vilka typer av subquery finns det?
Det finns två typer av subquery - korrelerade och icke-korrelerade.
En korrelerad underfråga kan inte betraktas som en oberoende fråga, men den kan referera till kolumnen i en tabell som listas i FRÅN listan över huvudfrågan.
En icke-korrelerad underfråga kan betraktas som en oberoende fråga och utdata från underfrågan ersätts i huvudfrågan.
22. Vad är ett lagrat förfarande?
Lagrad procedur är en funktion som består av många SQL-satser för att komma åt databassystemet. Flera SQL-satser konsolideras till en lagrad procedur och exekverar dem när och varhelst det behövs.
23. Vad är en utlösare?
En DB-trigger är en kod eller program som körs automatiskt med svar på någon händelse i en tabell eller vy i en databas. Främst hjälper trigger till att upprätthålla databasens integritet.
Exempel: När en ny student läggs till i studentdatabasen ska nya poster skapas i de relaterade tabellerna som Exam, Poäng och Närvarotabeller.
24. Vad är skillnaden mellan kommandona DELETE och TRUNCATE?
DELETE-kommandot används för att ta bort rader från tabellen, och WHERE-satsen kan användas för villkorlig uppsättning parametrar. Commit och Rollback kan utföras efter delete uttalande.
TRUNCATE tar bort alla rader från tabellen. Trunkeringsoperationen kan inte återställas.
25. Vilka är lokala och globala variabler och deras skillnader?
Lokala variabler är de variabler som kan användas eller finns i funktionen. De är inte kända för de andra funktionerna och dessa variabler kan inte refereras eller användas. Variabler kan skapas närhelst den funktionen anropas.
Globala variabler är de variabler som kan användas eller finns i hela programmet. Samma variabel som deklareras i global kan inte användas i funktioner. Globala variabler kan inte skapas när den funktionen anropas.
26. Vad är en begränsning?
Begränsning kan användas för att ange gränsen för datatypen för tabell. Begränsning kan anges när du skapar eller ändrar tabellsatsen. Exempel på begränsning är.
- INTE NULL.
- KOLLA UPP.
- STANDARD.
- SINGLE.
- PRIMÄRNYCKEL.
- FRÄMMANDE NYCKEL.
27. Vad är data Integrity?
Data Integrity definierar noggrannheten och konsistensen av data som lagras i en databas. Den kan också definiera integritetsbegränsningar för att upprätthålla affärsregler på data när den läggs in i applikationen eller databasen.
28. Vad är automatisk ökning?
Autoinkrement nyckelord låter användaren skapa ett unikt nummer som ska genereras när en ny post infogas i tabellen. AUTO INCREMENT nyckelord kan användas i Oracle och IDENTITY nyckelord kan användas i SQL SERVER.
Oftast kan detta nyckelord användas när PRIMÄRKEY används.
29. Vad är skillnaden mellan Cluster och icke-Cluster Index?
Clustered index används för enkel hämtning av data från databasen genom att ändra hur posterna lagras. Databasen sorterar ut rader efter kolumnen som är inställd på att vara klustrad index.
Ett icke-klustrat index ändrar inte hur det lagrades utan skapar ett fullständigt separat objekt i tabellen. Den pekar tillbaka till de ursprungliga tabellraderna efter sökning.
30. Vad är Datawarehouse?
Datawarehouse är ett centralt arkiv av data från flera informationskällor. Dessa data konsolideras, omvandlas och görs tillgängliga för gruvdrift och onlinebearbetning. Lagerdata har en delmängd av data som kallas Data Marts.
31. Vad är Self-Join?
Självanslutning är inställd på att en fråga används för att jämföra med sig själv. Detta används för att jämföra värden i en kolumn med andra värden i samma kolumn i samma tabell. ALIAS ES kan användas för samma tabelljämförelse.
32. Vad är Cross-Join?
Cross join definieras som kartesisk produkt där antalet rader i den första tabellen multiplicerat med antalet rader i den andra tabellen. Om du antar att WHERE-satsen används i cross join kommer frågan att fungera som en INNER JOIN.
33. Vad är användardefinierade funktioner?
Användardefinierade funktioner är de funktioner som är skrivna för att använda den logiken när det behövs. Det är inte nödvändigt att skriva samma logik flera gånger. Istället kan funktionen anropas eller köras när det behövs.
34. Vilka är alla typer av användardefinierade funktioner?
Tre typer av användardefinierade funktioner är.
- Skalära funktioner.
- Inline tabell värderade funktioner.
- Flera uttalanden värderade funktioner.
Skalär returenhet, variant definierade retursatsen. Andra två typer returnerar tabell som en retur.
35. Vad är sammanställning?
Sortering definieras som en uppsättning regler som bestämmer hur teckendata kan sorteras och jämföras. Detta kan användas för att jämföra A och andra språktecken och beror också på tecknens bredd.
ASCII-värde kan användas för att jämföra dessa teckendata.
36. Vad är alla olika typer av kollationskänslighet?
Följande är olika typer av sorteringskänslighet -.
- Kassakänslighet – A och a och B och b.
- Accentkänslighet.
- Kana Sensitivity – Japanska Kana-karaktärer.
- Breddkänslighet – Enkelbytetecken och dubbelbytetecken.
37. Fördelar och nackdelar med lagrad procedur?
Lagrad procedur kan användas som en modulär programmering – innebär att skapa en gång, lagra och ringa flera gånger närhelst det behövs. Detta stöder snabbare exekvering istället för att köra flera frågor. Detta minskar nätverkstrafiken och ger bättre säkerhet för data.
Nackdelen är att den bara kan köras i databasen och använder mer minne i databasservern.
38. Vad är Online Transaction Processing (OLTP)?
Online Transaction Processing (OLTP) hanterar transaktionsbaserade applikationer som kan användas för datainmatning, datahämtning och databehandling. OLTP gör datahanteringen enkel och effektiv. Till skillnad från OLAP-system är målet med OLTP-system att betjäna realtidstransaktioner.
Exempel – Banktransaktioner på daglig basis.
39. Vad är KLAUSUL?
SQL-satsen är definierad för att begränsa resultatuppsättningen genom att tillhandahålla villkor till frågan. Detta filtrerar vanligtvis några rader från hela uppsättningen poster.
Exempel – Fråga som har WHERE-villkoret
Fråga som har HAVING-tillstånd.
40. Vad är rekursiv lagrad procedur?
En lagrad procedur som anropar av sig själv tills den når något gränsvillkor. Denna rekursiva funktion eller procedur hjälper programmerare att använda samma uppsättning kod hur många gånger som helst.
SQL-intervjufrågor för 10+ års erfarenhet
41. Vad är kommandon Union, minus och Interact?
UNION-operatorn används för att kombinera resultaten från två tabeller, och den eliminerar dubbletter av rader från tabellerna.
MINUS-operatorn används för att returnera rader från den första frågan men inte från den andra frågan. Matchande poster för den första och andra frågan och andra rader från den första frågan kommer att visas som en resultatuppsättning.
INTERSECT-operatorn används för att returnera rader som returneras av båda frågorna.
42. Vad är ett ALIAS-kommando?
ALIAS-namn kan ges till en tabell eller kolumn. Detta alias kan hänvisas till VAR klausul för att identifiera tabellen eller kolumnen.
Exempel-.
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
Här hänvisar st till aliasnamn för studenttabell och Ex hänvisar till aliasnamn för tentamenstabell.
43. Vad är skillnaden mellan TRUNCATE- och DROP-satser?
TRUNCATE tar bort alla rader från tabellen och den kan inte rullas tillbaka. DROP-kommandot tar bort en tabell från databasen och operationen kan inte återställas.
44. Vad är aggregerade och skalära funktioner?
Aggregatfunktioner används för att utvärdera matematiska beräkningar och returnera enskilda värden. Detta kan beräknas från kolumnerna i en tabell. Skalära funktioner returnerar ett enda värde baserat på inmatningsvärdet.
Exempel -.
Aggregate – max(), count – Beräknat med avseende på numerisk.
Skalär – UCASE(), NOW() – Beräknas med avseende på strängar.
45. Hur kan du skapa en tom tabell från en befintlig tabell?
Exempel kommer att vara -.
Select * into studentcopy from student where 1=2
Här kopierar vi elevtabellen till en annan tabell med samma struktur utan några rader kopierade.
46. Hur hämtar man vanliga poster från två tabeller?
Gemensamma rekord resultatuppsättning kan uppnås genom -.
Select studentID from student INTERSECT Select StudentID from Exam
47. Hur hämtar man alternativa poster från en tabell?
Poster kan hämtas för både udda och jämna radnummer -.
För att visa jämna nummer-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
För att visa udda nummer-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
from (Välj rowno, studentId från student) där mod(rowno,2)=1.[/sql]
48. Hur väljer man unika poster från en tabell?
Välj unika poster från en tabell genom att använda DISTINCT nyckelord.
Select DISTINCT StudentID, StudentName from Student.
49. Vilket kommando används för att hämta de första 5 tecknen i strängen?
Det finns många sätt att hämta de första 5 tecknen i strängen -.
Select SUBSTRING(StudentName,1,5) as studentname from student
Select LEFT(Studentname,5) as studentname from student
50. Vilken operator används i fråga för mönstermatchning?
LIKE-operatorn används för mönstermatchning, och den kan användas som -.
- % – Matchar noll eller fler tecken.
- _(Understreck) – Matchar exakt ett tecken.
Exempel -.
Select * from Student where studentname like 'a%'
Select * from Student where studentname like 'ami_'
Dessa intervjufrågor kommer också att hjälpa dig i din viva (orals)