NLTK Tokenize: токенизатор слов и предложений с примером
⚡ Умное резюме
NLTK Tokenize разбивает большой текст на более мелкие единицы, называемые токенами, что является основополагающим шагом в обработке естественного языка. Инструментарий предоставляет word_tokenize для разбиения предложений на слова и sent_tokenize для разделения текста на отдельные предложения.

Что такое токенизация?
лексемизацию — это процесс, посредством которого большой объем текста разделяется на более мелкие части, называемые токенами. Эти токены очень полезны для поиска закономерностей и считаются базовым шагом для стемминга и лемматизации. Токенизация также помогает заменить конфиденциальные элементы данных неконфиденциальными элементами данных.
Обработка естественного языка используется для создания таких приложений, как классификация текста, интеллектуальный чатбот, сентиментальный анализ, языковой перевод и т. д. Для достижения вышеуказанной цели становится жизненно важным понять закономерность в тексте.
На данный момент не беспокойтесь о стемминге и лемматизации, а рассматривайте их как этапы очистки текстовых данных с использованием НЛП (обработка естественного языка). Мы обсудим стемминг и лемматизацию позже в этом уроке. Такие задачи, как Классификация текста или фильтрация спама использует НЛП вместе с библиотеками глубокого обучения, такими как Keras и Tensorflow.
В наборе инструментов Natural Language есть очень важный модуль NLTK. токенизировать предложения, которые дополнительно состоят из подмодулей
- токенизировать слово
- разметить предложение
Токенизация слов
Мы используем метод word_tokenize() разделить предложение на слова. Выходные данные токенизации слов можно преобразовать в Data Frame для лучшего понимания текста в приложениях машинного обучения. Его также можно предоставить в качестве входных данных для дальнейших шагов очистки текста, таких как удаление знаков препинания, удаление числовых символов или выделение корней. Модели машинного обучения нуждаются в числовых данных для обучения и прогнозирования. Токенизация слов становится важной частью преобразования текста (строки) в числовые данные. Пожалуйста, прочитайте о Мешок слов или CountVectorizer. Пожалуйста, обратитесь к приведенному ниже примеру токенизации слов NLTK, чтобы лучше понять теорию.
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
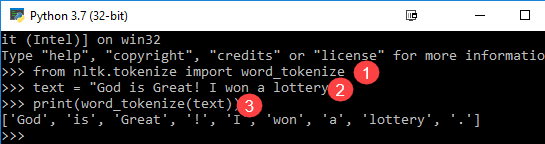
Code объяснение
- Модуль word_tokenize импортирован из библиотеки NLTK.
- Переменная «текст» инициализируется двумя предложениями.
- Текстовая переменная передается в модуль word_tokenize и печатает результат. Этот модуль разбивает каждое слово знаками препинания, которые вы можете увидеть в выводе.
Токенизация предложений
Доступный для вышеперечисленного подмодуль — send_tokenize. Очевидный вопрос в вашей голове будет зачем нужна токенизация предложений, когда у нас есть возможность токенизации слов. Представьте, что вам нужно посчитать среднее количество слов в предложении, как вы будете рассчитывать? Для выполнения такой задачи вам понадобится как токенизатор предложений NLTK, так и токенизатор слов NLTK для расчета соотношения. Такие выходные данные служат важной функцией машинного обучения, поскольку ответ будет числовым.
Ознакомьтесь с приведенным ниже примером токенизатора NLTK, чтобы узнать, чем токенизация предложений отличается от токенизации слов.
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
У нас есть 12 слова и два предложения для того же входа.
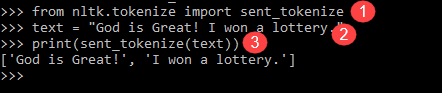
Пояснение к программе
- В строке, как и в предыдущей программе, импортирован модуль send_tokenize.
- Мы приняли тот же приговор. Дальнейший токенизатор предложений в модуле NLTK проанализировал эти предложения и показал выходные данные. Понятно, что эта функция разбивает каждое предложение.
Токенизатор над словом Python примеры — хорошие камни настроек для понимания механики токенизации слов и предложений.