Как скачать и установить NLTK
⚡ Умное резюме
Загрузите и установите NLTK на Windowsдля Mac или Linux путем установки Python сначала, затем добавив натуральный Language ToolДля этого необходимо собрать комплект данных через pip или Anaconda и загрузить наборы данных корпуса.

Установка NLTK в Windows
Узнайте, как настроить NLTK на Windows из командной строки. Приведенные ниже инструкции предполагают Python Он еще не установлен, поэтому первым шагом будет его установка. Python.
Установка Python in Windows
Шаг 1) Открыть ссылку https://www.python.org/downloads/, и выберите последнюю версию Windows отпустить.
ВниманиеДля просмотра более старой версии перейдите на вкладку «Загрузки», чтобы увидеть все выпущенные версии.

Шаг 2) Нажмите на загруженный файл установщика.

Шаг 3) Выберите «Настроить установку».
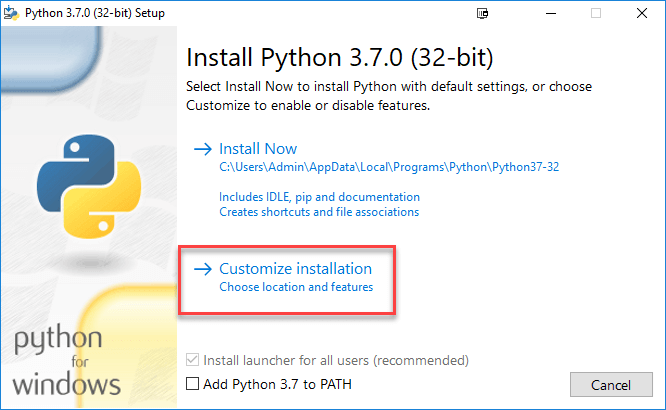
Шаг 4) Нажмите кнопку "Далее.

Шаг 5) На следующем экране:
- Выберите дополнительные параметры.
- Укажите пользовательское место установки. В этом примере для более удобного доступа выбрана папка на диске C.
- Нажмите кнопку Установить.

Шаг 6) После завершения установки нажмите кнопку «Закрыть».

Шаг 7) Скопируйте путь к папке «Сценарии».

Шаг 8) В Windows командная строка:
- Перейдите в папку, где находится pip.
- Введите команду для установки NLTK:
pip3 install nltk
- Установка должна успешно завершиться.

ЗАМЕТКА: За Python 2. Используйте команду. pip2 install nltk.
Шаг 9) Из издания Windows В меню «Пуск» найдите и откройте Python Оболочка.

Шаг 10) Убедитесь в корректности установки, выполнив следующую команду:
import nltk

Если ошибок не отображается, установка завершена.
Установка NLTK в Mac/Linux
Для установки NLTK на Mac или Linux требуется следующее: Python Менеджер пакетов pip. Если pip не установлен, следуйте инструкциям ниже, чтобы завершить процесс.
Шаг 1) Обновить индекс пакетов по типуping приведенная ниже команда:
sudo apt update
Шаг 2) Установите pip для Python 3:
sudo apt install python3-pip
Также вы можете установить pip через easy_install:
sudo apt-get install python-setuptools python-dev build-essential
После установки easy_install выполните следующую команду для установки pip:
sudo easy_install pip
Шаг 3) Для установки NLTK используйте следующую команду:
sudo pip install -U nltk sudo pip3 install -U nltk
Установка NLTK через Anaconda
Шаг 1) Установите Anaconda, перейдя по ссылке: https://www.anaconda.com/products/individual и выбрав Python нужная вам версия.

Примечание. Обратитесь к этому руководству для получения подробных инструкций по установить Anaconda.
Шаг 2) В командной строке Anaconda:
- Введите команду:
conda install -c anaconda nltk
- RevПросмотрите информацию об обновлении, понижении версии и установке пакета, затем введите «да».
- NLTK загружен и установлен.

Набор данных НЛТК
Модуль NLTK поставляется со множеством наборов данных, которые необходимо загрузить перед использованием. Технически каждый набор данных называется тело. Обычные примеры включают в себя игнорируемые слова, Гутенберг, Framenet_v15, big_grammars, коричневый и Wordnet.
Как скачать все пакеты NLTK
Шаг 1) Запустите Python переводчик in Windows или Linux.
Шаг 2)
- Введите команды:
import nltk nltk.download ()
- Откроется окно NLTK Downloader. Нажмите кнопку «Загрузить», чтобы получить набор данных. Этот процесс займет некоторое время в зависимости от скорости вашего интернет-соединения.

ПРИМЕЧАНИЕ: Изменить место сохранения загрузок можно, нажав «Файл» > «Изменить папку для загрузок».

Шаг 3) Для проверки установленных данных используйте следующий код:
>>> from nltk.corpus import brown >>>brown.words()
['The', 'Фултон', 'Каунти', 'Гранд', 'Присяжные', 'Сказал',…]

Запуск сценария НЛП
В этом разделе объясняется, как работает скрипт обработки естественного языка на локальном компьютере. Выбор подходящей библиотеки зависит от ваших требований. См. официальный список. библиотеки НЛП в качестве альтернативы можно использовать spaCy, gensim и TextBlob.
Как запустить сценарий NLTK
Шаг 1) В вашем любимом редакторе кода скопируйте код и сохраните файл как NLTKsample.py:
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer(r'\w+')
filterdText=tokenizer.tokenize('Hello Guru99, You have build a very good site and I love visiting your site.')
print(filterdText)

Code Объяснение:
- Цель этой программы — удалить все виды знаков препинания из заданного текста. Мы импортировали модуль «RegexpTokenizer». НЛТК Это удаляет любое выбранное вами выражение, символ, знак или числовое значение.
- В модуль «RegexpTokenizer» передается регулярное выражение.
- Текст токенизируется с помощью метода «tokenize», а результат сохраняется в переменной «filterdText».
- Результат выводится с помощью функции «print()».
Шаг 2) В командной строке:
- Перейдите в папку, где вы сохранили файл.
- Запустите команду
python NLTKsample.py.

Выход:
['Привет', 'Guru99', 'You', 'have', 'build', 'a', 'very', 'good', 'site', 'and', 'I', 'love', 'visiting', 'your', 'site']