Încorporarea de cuvinte și Word2Vec cu exemplu
⚡ Rezumat inteligent
Word Embedding și Word2Vec convertesc textul în vectori numerici denși, astfel încât modelele de învățare automată să recunoască cuvinte cu sens similar. Această resursă explică tehnica, arhitecturile sale CBOW și Skip-Gram, funcțiile de activare și o implementare Gensim completă pentru aplicații reale.
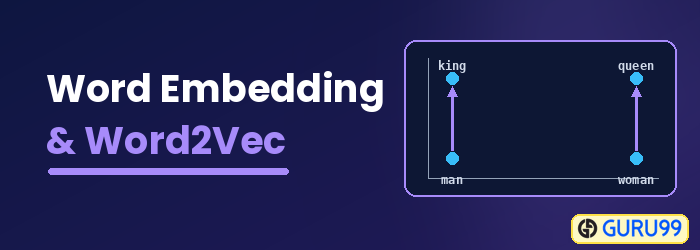
Ce este Word Embedding?
Încorporarea cuvintelor este un tip de reprezentare a cuvintelor care permite algoritmilor de învățare automată să înțeleagă cuvinte cu înțelesuri similare. Este o tehnică de modelare a limbajului și de învățare a caracteristicilor pentru a mapa cuvintele în vectori de numere reale folosind rețele neuronale, modele probabilistice sau reducerea dimensiunii pe matricea de co-apariție a cuvintelor. Unele modele de încorporare a cuvintelor sunt Word2vec (Google), GloVe (Stanford) și fastText (Facebook).
Încorporarea cuvintelor este numită și model semantic distribuit, model reprezentat distribuit, spațiu vectorial semantic sau model de spațiu vectorial. Pe măsură ce citiți aceste nume, dați peste cuvântul semantică, ceea ce înseamnă clasificarea cuvintelor similare împreună. De exemplu, fructe precum măr, mango și banană ar trebui plasate aproape una de alta, în timp ce cărțile vor fi plasate departe de aceste cuvinte. Într-un sens mai larg, încorporarea cuvintelor va crea un vector de fructe care este plasat departe de reprezentarea vectorială a cărților.
Unde se utilizează Word Embedding?
Integrarea de cuvinte ajută la generarea de caracteristici, gruparea documentelor, clasificarea textului și sarcinile de procesare a limbajului natural. Să enumerăm aceste aplicații și să discutăm fiecare dintre ele.
- Calculați cuvinte similare: Încorporarea de cuvinte este utilizată pentru a sugera cuvinte similare cu cuvântul supus modelului de predicție. Pe lângă aceasta, sugerează și cuvinte diferite, precum și cele mai comune cuvinte.
- Creați un grup de cuvinte înrudite: Este folosit pentru grupări semanticeping, care grupează împreună lucrurile cu caracteristici similare și împinge departe elementele diferite.
- Caracteristica pentru clasificarea textului: Textul este mapat în tablouri de vectori care sunt introduși în model atât pentru antrenament, cât și pentru predicție. Modelele de clasificare bazate pe text nu pot fi antrenate pe șiruri de caractere, așa că acest lucru convertește textul într-o formă care poate fi antrenată de mașină. Caracteristicile sale de construire semantică ajută în continuare la clasificarea bazată pe text.
- Gruparea documentelor: Aceasta este o altă aplicație în care Word Embedding și Word2vec sunt utilizate pe scară largă.
- Procesarea limbajului natural: Există multe aplicații în care încorporarea de cuvinte este utilă și câștigă față de exemplele de caracteristici.tracfaze de identificare, cum ar fi etichetarea părților de vorbire, analiza sentimentelor și analiza sintactică.
Acum că înțelegeți unde se aplică încorporarea de cuvinte, haideți să analizăm cel mai popular model folosit pentru a crea aceste încorporări.
Ce este Word2vec?
Word2vec este o tehnică sau un model care produce încorporări de cuvinte pentru o reprezentare mai bună a acestora. Este o metodă de procesare a limbajului natural care capturează un număr mare de relații sintactice și semantice precise între cuvinte. Este o rețea neuronală superficială cu două straturi care poate detecta cuvinte sinonime și poate sugera cuvinte suplimentare pentru propoziții parțiale odată ce este antrenată.
Înainte de a continua, vă rugăm să consultați diferența dintre o rețea neuronală superficială și una profundă, așa cum se arată în diagrama exemplului de încorporare Word de mai jos:
Rețeaua neuronală superficială constă dintr-un singur strat ascuns între intrare și ieșire, în timp ce o rețea neuronală profundă conține mai multe straturi ascunse între intrare și ieșire. Intrarea este supusă nodurilor, în timp ce stratul ascuns, precum și stratul de ieșire, conțin neuroni.
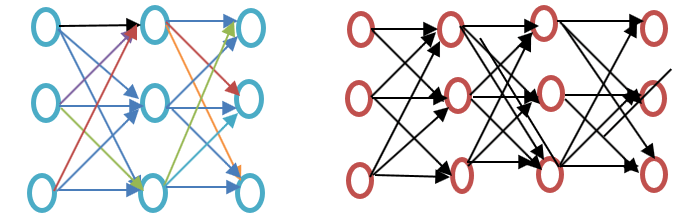
Word2vec este o rețea cu două straturi, în care există o intrare, un strat ascuns și o ieșire.
Word2vec a fost dezvoltat de un grup de cercetători condus de Tomas Mikolov la GoogleWord2vec este mai bun și mai eficient decât modelul de analiză semantică latentă.
De ce Word2vec?
Word2vec reprezintă cuvintele într-o reprezentare vectorială. Cuvintele sunt reprezentate sub formă de vectori, iar plasarea se face astfel încât cuvintele cu sens similar să apară împreună, iar cuvintele diferite să fie amplasate departe. Aceasta se numește și relație semantică. Rețelele neuronale nu înțeleg textul; în schimb, ele înțeleg doar numerele. Integrarea cuvintelor oferă o modalitate de a converti textul într-un vector numeric.
Word2vec reconstruiește contextul lingvistic al cuvintelor. Înainte de a merge mai departe, să înțelegem ce este contextul lingvistic. Într-un scenariu general, atunci când vorbim sau scriem pentru a comunica, alte persoane încearcă să descopere obiectivul propoziției. De exemplu, „Care este temperatura Indiei?” Aici, contextul este acela că utilizatorul dorește să afle „temperatura Indiei”. Pe scurt, obiectivul principal al unei propoziții este contextul. Cuvintele sau propozițiile care înconjoară limbajul vorbit sau scris ajută la determinarea sensului contextului. Word2vec învață reprezentarea vectorială a cuvintelor prin intermediul acestor contexte.
Ce face Word2vec?
Înainte de încorporarea Word
Este important să știm ce abordare a fost utilizată înainte de încorporarea cuvintelor și care sunt dezavantajele acesteia, iar apoi vom vedea cum aceste dezavantaje sunt depășite prin încorporarea cuvintelor folosind abordarea Word2vec. În cele din urmă, vom trece la modul în care funcționează Word2vec, deoarece este important să înțelegem modul său de funcționare.
Abordare pentru analiza semantică latentă
Aceasta este abordarea utilizată înainte de încorporarea cuvintelor. Se folosea conceptul de „Geantă de cuvinte”, unde cuvintele sunt reprezentate sub formă de vectori codificați. Este o reprezentare vectorială dispersă în care dimensiunea este egală cu dimensiunea vocabularului. Dacă cuvântul apare în dicționar, este numărat; altfel, nu. Pentru a înțelege mai multe, vă rugăm să consultați programul de mai jos.
Exemplu Word2vec

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
ieșire:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Explicație
- CountVectorizer este modulul folosit pentru stocarea vocabularului pe baza potrivirii cuvintelor din acesta. Acesta este importat din sklearn.
- Creați obiectul folosind clasa CountVectorizer.
- Scrieți datele din lista care urmează să fie încadrate în CountVectorizer.
- Datele se potrivesc în obiectul creat din clasa CountVectorizer.
- Aplicați o abordare de tip „bag-of-words” pentru a număra cuvintele din date folosind vocabularul. Dacă un cuvânt sau un token nu este disponibil în vocabular, atunci o astfel de poziție a indexului este setată la zero.
- Variabila din linia 5, care este x, este convertită într-un tablou (o metodă disponibilă pentru x). Aceasta oferă numărul fiecărui token din propoziția sau lista furnizată în linia 3.
- Aceasta arată caracteristicile care fac parte din vocabular atunci când este ajustat folosind datele din linia 4.
În abordarea semantică latentă, rândul reprezintă cuvinte unice, în timp ce coloana reprezintă numărul de apariții ale cuvântului respectiv în document. Este o reprezentare a cuvintelor sub forma unei matrice de document. Frecvența termenilor - Inversa frecvenței documentelor (TF-IDF) este utilizată pentru a număra frecvența cuvintelor din document, care este frecvența termenului din document împărțită la frecvența termenului în întregul corpus.
Deficiența metodei Bag of Words
- Ignoră ordinea cuvântului; de exemplu, asta e rău = rău este asta.
- Ignoră contextul cuvintelor. Să presupunem că scriem propoziția „Iubea cărțile. Educația se găsește cel mai bine în cărți”. S-ar crea doi vectori: unul pentru „Iubea cărțile” și altul pentru „Educația se găsește cel mai bine în cărți”. I-ar trata pe amândoi ca fiind ortogonali, ceea ce îi face independenți, dar în realitate, sunt înrudiți unul cu celălalt.
Pentru a depăși aceste limitări, a fost dezvoltată încorporarea de cuvinte, iar Word2vec este o abordare utilizată pentru implementarea acesteia.
Cum funcționează Word2vec?
Word2vec învață un cuvânt prin prezicerea contextului înconjurător. De exemplu, să luăm cuvântul „El” iubeste Fotbal."
Vrem să calculăm Word2vec pentru cuvântul: iubeste.
Presupune:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
Cuvantul iubeste parcurge fiecare cuvânt din corpus. Sunt codificate atât relațiile sintactice, cât și cele semantice dintre cuvinte. Acest lucru ajută la găsirea cuvintelor similare și analoage.
Toate caracteristicile aleatorii ale cuvântului iubeste sunt calculate. Aceste caracteristici sunt modificate sau actualizate în raport cu cuvintele vecine sau de context cu ajutorul unui Propagarea înapoi metodă.
O altă modalitate de învățare este că, dacă contextele a două cuvinte sunt similare sau două cuvinte au caracteristici similare, atunci aceste cuvinte sunt înrudite.
Word2vec Architectură
Există două arhitecturi folosite de Word2vec:
- Pungă continuă de cuvinte (CBOW)
- Skip-gram
Înainte de a continua, să discutăm de ce aceste arhitecturi sau modele sunt importante din punctul de vedere al reprezentării cuvintelor. Învățarea reprezentării cuvintelor este în esență nesupervizată, dar sunt necesare ținte/etichete pentru antrenarea modelului. Skip-gram și CBOW convertesc reprezentarea nesupervizată într-o formă supervizată pentru antrenarea modelului.
În CBOW, cuvântul curent este prezis folosind fereastra ferestrelor de context din jur. De exemplu, dacă wI-1, WI-2, Wi + 1, Wi + 2 sunt date cuvinte sau context, acest model va oferi wi.
Skip-Gram face opusul lui CBOW, ceea ce implică faptul că prezice secvența sau contextul dat din cuvânt. Puteți inversa exemplul pentru a-l înțelege. Dacă wi este dat, acest lucru va prezice contextul sau wI-1, WI-2, Wi + 1, Wi + 2.
Word2vec oferă opțiunea de a alege între CBOW (Continuous Bag of Words - Sac de cuvinte continuu) și skip-gram. Acești parametri sunt furnizați în timpul antrenamentului modelului. Se poate opta pentru eșantionarea negativă sau un strat softmax ierarhic.
Pungă continuă de cuvinte
Să desenăm o diagramă simplă de exemplu Word2vec pentru a înțelege arhitectura continuă de tip sac de cuvinte.

Să calculăm ecuațiile matematic. Să presupunem că V este dimensiunea vocabularului și N este dimensiunea stratului ascuns. Intrarea este definită ca { xI-1, XI-2, Xi + 1, Xi + 2 }. Obținem matricea de ponderi prin înmulțirea lui V * N. O altă matrice se obține prin înmulțirea vectorului de intrare cu matricea de ponderi. Acest lucru poate fi înțeles și prin următoarea ecuație.
h = xitW
unde xit și W sunt vectorul de intrare și, respectiv, matricea de ponderi.
Pentru a calcula potrivirea dintre context și cuvântul următor, vă rugăm să consultați ecuația de mai jos.
u = reprezentare prezisă * h
unde reprezentarea prezisă se obține din modelul din ecuația de mai sus.
Model Skip-Gram
Abordarea Skip-Gram este utilizată pentru a prezice o propoziție având la dispoziție un cuvânt de intrare. Pentru a o înțelege mai bine, să desenăm diagrama prezentată în exemplul Word2vec de mai jos.

Se poate trata ca inversul modelului Continuous Bag of Words (Sacul Continuu de Cuvinte), unde intrarea este cuvântul, iar modelul oferă contextul sau secvența. De asemenea, putem concluziona că ținta este transmisă intrării, iar stratul de ieșire este replicat de mai multe ori pentru a acomoda numărul ales de cuvinte contextuale. Vectorul de eroare din toate straturile de ieșire este însumat pentru a ajusta ponderile printr-o metodă de retropropagare.
Ce model sa aleg?
CBOW este de câteva ori mai rapid decât skip-gram și oferă o frecvență mai bună pentru cuvintele frecvente, în timp ce skip-gram necesită o cantitate mică de date de antrenament și reprezintă chiar și cuvinte sau expresii rare. Tabelul de mai jos compară ambele arhitecturi dintr-o privire.
| Aspect | CBOW | Skip-Gram |
|---|---|---|
| Prezicere | Prezice cuvântul țintă din context | Prezice contextul din cuvântul țintă |
| Viteza de antrenament | Mai rapid | Mai lent |
| Cuvinte frecvente | Precizie mai mare | Precizie mai mică |
| Cuvinte rare | Reprezentare mai slabă | Reprezentare mai puternică |
| Date de instruire | Necesită mai multe date | Funcționează cu mai puține date |
Relația dintre Word2vec și NLTK
NLTK este Natural Language Toolkit. Este utilizat pentru preprocesarea textului. Se pot efectua diferite operațiuni, cum ar fi etichetarea părților de vorbire, lematizarea, atribuirea rădăcinilor, eliminarea cuvintelor stop-word și eliminarea cuvintelor rare sau mai puțin utilizate. Ajută la curățarea textului, precum și la pregătirea caracteristicilor din cuvintele eficiente. Pe de altă parte, Word2vec este utilizat pentru potrivirea semantică (elemente strâns legate între ele) și sintactică (secvență). Folosind Word2vec, se pot găsi cuvinte similare, cuvinte diferite, reducerea dimensională și multe altele. O altă caracteristică importantă a Word2vec este convertirea reprezentării de dimensiuni superioare a textului în vectori de dimensiuni inferioare.
Unde să folosiți NLTK și Word2vec?
Dacă cineva trebuie să îndeplinească anumite sarcini de uz general, așa cum s-a menționat mai sus, cum ar fi tokenizarea, etichetarea POS și parsarea, trebuie să se utilizeze NLTK, în timp ce pentru prezicerea cuvintelor în funcție de un anumit context, modelarea subiectelor sau similaritatea documentelor, trebuie să se utilizeze Word2vec.
Relația dintre NLTK și Word2vec cu ajutorul codului
NLTK și Word2vec pot fi utilizate împreună pentru a găsi reprezentări similare ale cuvintelor sau potriviri sintactice. Setul de instrumente NLTK poate fi utilizat pentru a încărca multe pachete care vin cu NLTK, iar un model poate fi creat folosind Word2vec. Acesta poate fi apoi testat pe cuvinte în timp real. Să vedem combinația ambelor în codul următor. Înainte de a continua procesarea, vă rugăm să aruncați o privire la corpusurile furnizate de NLTK. Le puteți descărca folosind comanda:
nltk(nltk.download('all'))

Vă rugăm să vedeți captura de ecran pentru cod.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

ieșire:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Explicația de Code
- Biblioteca nltk este importată, de unde puteți descărca corpusul abc pe care îl vom folosi în pasul următor.
- Gensim este importat. Dacă Gensim Word2vec nu este instalat, vă rugăm să îl instalați folosind comanda „pip3 install gensim”. Vă rugăm să consultați captura de ecran de mai jos.

- Importați corpusul abc, care a fost descărcat folosind nltk.download('abc').
- Transmiteți fișierele către modelul Word2vec, care este importat folosind Gensim, ca propoziții.
- Vocabularul este stocat sub forma unei variabile.
- Modelul este testat pe cuvântul eșantion ştiinţă, deoarece aceste fișiere sunt legate de știință.
- Aici, cuvântul similar „știință” este prezis de model.
Activatori și Word2Vec
Funcția de activare a unui neuron definește ieșirea acelui neuron în funcție de un set de intrări. Aceasta este inspirată biologic de activitatea din creierul nostru, unde diferiți neuroni sunt activați folosind stimuli diferiți. Să înțelegem funcția de activare prin intermediul următoarei diagrame.

Aici x1, x2, … x4 sunt nodurile rețelei neuronale.
w1, w2, w3 sunt ponderile nodurilor.
Sumarea (Σ) tuturor ponderilor și valorilor nodurilor funcționează ca funcție de activare.
De ce funcția de activare?
Dacă nu se utilizează nicio funcție de activare, ieșirea ar fi liniară, dar funcționalitatea unei funcții liniare este limitată. Pentru a obține funcționalități complexe, cum ar fi detectarea obiectelor, clasificarea imaginilor, etc.ping text care utilizează vocea și multe alte ieșiri neliniare, este necesară o funcție de activare.
Cum este calculat stratul de activare în încorporarea cuvântului (Word2vec)
Stratul Softmax (funcția exponențială normalizată) este funcția stratului de ieșire care activează sau declanșează fiecare nod. O altă abordare utilizată este Softmax ierarhic, unde complexitatea este calculată prin O(log2V), în timp ce în softmax este O(V), unde V este dimensiunea vocabularului. Diferența dintre acestea constă în reducerea complexității în stratul ierarhic softmax. Pentru a înțelege funcționalitatea sa, vă rugăm să consultați exemplul de încorporare Word de mai jos:

Să presupunem că vrem să calculăm probabilitatea de a observa cuvântul dragoste dat un anumit context. Fluxul de la rădăcină la nodul frunză se va deplasa mai întâi la nodul 2 și apoi la nodul 5. Deci, dacă avem o dimensiune a vocabularului de 8, sunt necesare doar trei calcule. Acest lucru permite descompunerea calculului probabilității unui cuvânt (dragoste).
Ce alte opțiuni sunt disponibile în afară de Hierarchical Softmax?
Într-un sens general, opțiunile de încorporare a cuvintelor disponibile sunt Softmax diferențiat, CNN-Softmax, Eșantionare a importanței, Eșantionare adaptivă a importanței, Estimare contrastivă a zgomotului, Eșantionare negativă, Autonormalizare și Normalizare infrecventă.
Vorbind în mod specific despre Word2vec, avem disponibilă eșantionarea negativă.
Eșantionarea negativă este o modalitate de eșantionare a datelor de antrenament. Este oarecum similară cu coborârea stocastică în gradient, dar cu unele diferențe. Eșantionarea negativă caută doar exemple de antrenament negative. Se bazează pe estimarea prin contrast cu zgomot și eșantionează aleatoriu cuvinte care nu se află în context. Este o metodă de antrenament rapidă și alege contextul în mod aleatoriu. Dacă cuvântul prezis apare în contextul ales aleatoriu, ambii vectori sunt apropiați unul de celălalt.
Ce concluzie se poate trage?
Activatorii declanșează neuronii la fel cum neuronii noștri sunt declanșați de stimuli externi. Stratul Softmax este una dintre funcțiile stratului de ieșire care declanșează neuronii în cazul încorporării de cuvinte. În Word2vec, avem opțiuni precum softmax ierarhic și eșantionare negativă. Folosind activatori, se poate converti o funcție liniară într-o funcție neliniară, iar un algoritm complex de învățare automată poate fi implementat folosind astfel de funcții.
Ce este Gensim?
Gensim este un set de instrumente de modelare a subiectelor și procesare a limbajului natural, care este implementat în Python și Cython. Setul de instrumente Gensim permite utilizatorilor să importe Word2vec pentru modelarea subiectelor pentru a descoperi structuri ascunse în corpul textului. Gensim oferă nu doar o implementare a Word2vec, ci și a Doc2vec și FastText.
Această secțiune este axată pe Word2vec, așa că ne vom limita la subiectul actual.
Cum să implementați Word2vec folosind Gensim
Până acum, am discutat ce este Word2vec, diferitele sale arhitecturi, de ce există o trecere de la un set de cuvinte la Word2vec, relația dintre Word2vec și NLTK cu cod live și funcțiile de activare.
Mai jos este metoda pas cu pas pentru implementarea Word2vec folosind Gensim:
Pasul 1) Colectarea datelor
Primul pas pentru implementarea oricărui model de învățare automată sau pentru implementarea procesării limbajului natural este colectarea datelor.
Vă rugăm să respectați datele pentru a construi un chatbot inteligent, așa cum se arată în exemplul Gensim Word2vec de mai jos.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Iată ce înțelegem din date:
- Aceste date conțin trei elemente: etichetă, model și răspunsuri. Eticheta reprezintă intenția (care este subiectul discuției).
- Datele sunt în format JSON.
- Un model este o întrebare pe care utilizatorii o vor adresa botului.
- Răspunsurile sunt răspunsurile pe care chatbot-ul le va oferi la întrebarea/modelul corespunzător.
Pasul 2) Preprocesarea datelor
Este foarte important să procesați datele brute. Dacă datele curățate sunt transmise mașinii, atunci modelul va răspunde mai precis și va învăța datele mai eficient.
Acest pas implică eliminarea cuvintelor oprite, a cuvintelor cu rădăcini, a cuvintelor inutile etc. Înainte de a continua, este important să încărcați datele și să le convertiți într-un cadru de date. Vă rugăm să consultați codul de mai jos pentru acest lucru.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Explicația de Code:
- Deoarece datele sunt în format JSON, se importă json.
- Fișierul este stocat în variabila .
- Fișierul este deschis și încărcat în variabila de date.
Acum datele sunt importate și este timpul să le convertim într-un cadru de date. Consultați codul de mai jos pentru pasul următor.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Explicația de Code:
1. Datele sunt convertite într-un cadru de date folosind panda, care a fost importat mai sus.
2. Convertește lista din modelele de coloane într-un șir de caractere.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Explicaţie:
1. Cuvintele oprite în limba engleză sunt importate folosind modulul stop-word din setul de instrumente nltk.
2. Toate cuvintele din text sunt convertite în litere mici folosind o condiție `for` și o funcție lambda. A Funcția lambda este o funcție anonimă.
3. Toate rândurile de text din cadrul de date sunt verificate pentru punctuația șirurilor de caractere și acestea sunt filtrate.
4. Caracterele precum numerele sau punctele sunt eliminate folosind o expresie regulată.
5. Digits sunt eliminate din text.
6. Cuvintele stop sunt eliminate în această etapă.
7. Cuvintele sunt acum filtrate, iar diferitele forme ale aceluiași cuvânt sunt eliminate folosind lematizarea. Cu acestea, am finalizat preprocesarea datelor.
ieșire:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Pasul 3) Construirea rețelei neuronale folosind Word2vec
Acum este momentul să construim un model folosind modulul Gensim Word2vec. Trebuie să importăm Word2vec din Gensim. Să facem acest lucru, apoi îl vom construi, iar în etapa finală vom verifica modelul pe date în timp real.
from gensim.models import Word2Vec
Acum putem construi cu succes modelul folosind Word2Vec. Vă rugăm să consultați următoarea linie de cod pentru a afla cum să creați modelul folosind Word2Vec. Textul este furnizat modelului sub forma unei liste, așa că vom converti textul din cadrul de date într-o listă folosind codul de mai jos.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Explicația de Code:
1. A fost creată bigger_list-ul unde este adăugată lista interioară. Acesta este formatul care este introdus în modelul Word2Vec.
2. Se implementează o buclă, iar fiecare intrare din coloana patterns a cadrului de date este iterată.
3. Fiecare element al modelelor de coloane este divizat și stocat în lista interioară li.
4. Lista interioară este adăugată la lista externă.
5. Această listă este furnizată modelului Word2Vec. Să înțelegem câțiva dintre parametrii furnizați aici.
Număr_min: Ignoră toate cuvintele cu o frecvență totală mai mică decât aceasta.
Mărimea: Spune dimensionalitatea cuvântului vectori.
Muncitorii: Acestea sunt firele de execuție pentru antrenarea modelului.
Există și alte opțiuni disponibile, iar câteva dintre cele importante sunt explicate mai jos.
Fereastră: Distanța maximă dintre cuvântul curent și cel prezis dintr-o propoziție.
Sg: Este un algoritm de antrenament: 1 pentru skip-gram și 0 pentru un Continuous Bag of Words. Am discutat despre acestea în detaliu mai sus.
Hs: Dacă aceasta este 1, atunci folosim softmax ierarhic pentru antrenament, iar dacă este 0, atunci se utilizează eșantionarea negativă.
Alfa: Rata de învățare inițială.
Să afișăm codul final mai jos:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Pasul 4) Salvarea modelului
Modelul poate fi salvat sub forma unui fișier bin și a unui fișier model. Bin este formatul binar. Consultați liniile de mai jos pentru a salva modelul.
model.save("word2vec.model") model.save("model.bin")
Explicația codului de mai sus
1. Modelul este salvat sub forma unui fișier .model.
2. Modelul este salvat sub forma unui fișier .bin.
Vom folosi acest model pentru a face teste în timp real, cum ar fi cuvinte similare, cuvinte diferite și cele mai comune cuvinte.
Pasul 5) Încărcarea modelului și efectuarea testării în timp real
Modelul este încărcat folosind următorul cod:
model = Word2Vec.load('model.bin')
Dacă doriți să imprimați vocabularul din acesta, acest lucru se face folosind următoarea comandă:
vocab = list(model.wv.vocab)
Vă rugăm să vedeți rezultatul:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Pasul 6) Verificarea celor mai multe cuvinte similare
Să implementăm lucrurile practic:
similar_words = model.most_similar('thanks') print(similar_words)
Vă rugăm să vedeți rezultatul:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Pasul 7) Nu se potrivește cu cuvântul din cuvintele furnizate
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Noi am furnizat cuvintele „Pe mai târziu, mulțumesc pentru vizită.”Aceasta afișează cuvântul cel mai diferit dintre aceste cuvinte. Să rulăm acest cod și să găsim rezultatul.
Rezultatul după executarea codului de mai sus:
Thanks
Pasul 8) Găsirea asemănării dintre două cuvinte
Aceasta indică rezultatul în funcție de probabilitatea de similaritate dintre două cuvinte. Consultați codul de mai jos pentru a afla cum se execută această secțiune.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
Rezultatul codului de mai sus este următorul:
0.13706
Puteți găsi cuvinte similare executând codul de mai jos:
similar = model.similar_by_word('kind') print(similar)
Ieșirea codului de mai sus:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]