NLTK Tokenize: Tokenizer de cuvinte și propoziții cu exemplu
⚡ Rezumat inteligent
NLTK Tokenize împarte textul mare în unități mai mici numite token-uri, un pas fundamental în procesarea limbajului natural. Setul de instrumente oferă word_tokenize pentru descompunerea propozițiilor în cuvinte și sent_tokenize pentru împărțirea textului în propoziții individuale.

Ce este tokenizarea?
tokenizarea este procesul prin care o cantitate mare de text este împărțită în părți mai mici numite jetoane. Aceste jetoane sunt foarte utile pentru găsirea de modele și sunt considerate ca un pas de bază pentru stemming și lematizare. Tokenizarea ajută, de asemenea, la înlocuirea elementelor de date sensibile cu elemente de date nesensibile.
Procesarea limbajului natural este utilizată pentru construirea de aplicații precum clasificarea textului, chatbot inteligent, analiza sentimentală, traducerea limbii etc. Devine vital să înțelegem tiparul din text pentru a atinge scopul menționat mai sus.
Deocamdată, nu vă faceți griji cu privire la stemming și lematizare, ci tratați-le ca pași pentru curățarea datelor textuale folosind NLP (Natural language processing). Vom discuta despre stemming și lematizare mai târziu în tutorial. Sarcini precum Clasificarea textului sau filtrarea spamului folosește NLP împreună cu biblioteci de deep learning, cum ar fi Keras și flux tensor.
Setul de instrumente Natural Language are un modul foarte important NLTK tokeniza propoziții care mai includ sub-module
- cuvântul tokenize
- propoziție tokenize
Tokenizarea cuvintelor
Folosim metoda word_tokenize() a împărți o propoziție în cuvinte. Ieșirea tokenizării cuvintelor poate fi convertită în Data Frame pentru o mai bună înțelegere a textului în aplicațiile de învățare automată. De asemenea, poate fi furnizat ca intrare pentru pașii suplimentari de curățare a textului, cum ar fi eliminarea semnelor de punctuație, eliminarea caracterelor numerice sau înlăturarea. Modelele de învățare automată au nevoie de date numerice pentru a fi instruite și pentru a face o predicție. Tokenizarea cuvintelor devine o parte crucială a textului (șirului) în conversia datelor numerice. Vă rugăm să citiți despre Pungă de cuvinte sau CountVectorizer. Vă rugăm să consultați exemplul NLTK de tokenizare a cuvântului de mai jos pentru a înțelege mai bine teoria.
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
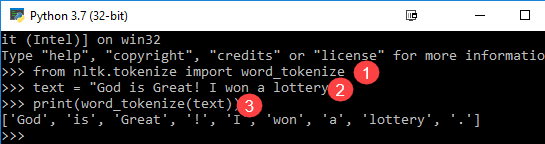
Code Explicație
- Modulul word_tokenize este importat din biblioteca NLTK.
- O variabilă „text” este inițializată cu două propoziții.
- Variabila text este transmisă în modulul word_tokenize și se imprimă rezultatul. Acest modul desparte fiecare cuvânt cu semne de punctuație pe care le puteți vedea în rezultat.
Tokenizarea propozițiilor
Sub-modulul disponibil pentru cele de mai sus este send_tokenize. O întrebare evidentă în mintea ta ar fi de ce este necesară tokenizarea propoziției atunci când avem opțiunea tokenizării cuvintelor. Imaginați-vă că trebuie să numărați cuvintele medii pe propoziție, cum veți calcula? Pentru a realiza o astfel de sarcină, aveți nevoie atât de tokenizer de propoziții NLTK, cât și de tokenizer de cuvinte NLTK pentru a calcula raportul. O astfel de ieșire servește ca o caracteristică importantă pentru antrenamentul cu mașini, deoarece răspunsul ar fi numeric.
Consultați exemplul de tokenizare NLTK de mai jos pentru a afla cum este diferită tokenizarea propoziției de tokenizarea cuvintelor.
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
Noi avem 12 cuvinte și două propoziții pentru aceeași intrare.
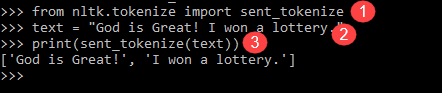
Explicația programului
- Într-o linie ca programul anterior, a importat modulul sent_tokenize.
- Am luat aceeași propoziție. Tokenizer suplimentar de propoziții în modulul NLTK a analizat acele propoziții și a afișat rezultatul. Este clar că această funcție rupe fiecare propoziție.
Deasupra cuvântului tokenizer Python exemplele sunt pietre de setare bune pentru a înțelege mecanica tokenizării cuvintelor și propozițiilor.