Tutorial Scikit-Learn: Cum se instalează și exemple Scikit-Learn
⚡ Rezumat inteligent
Scikit-learn este open source Python bibliotecă ce acoperă preprocesarea, clasificarea, regresia, gruparea și selecția modelelor în spatele unei singure interfețe de estimare consistente, ceea ce menține un flux de lucru complet de învățare automată scurt, lizibil și reproductibil, de la date brute la predicții scorate.

Ce este Scikit-learn?
Scikit-învață este un open-source Python biblioteca pentru masina de învățareAcceptă algoritmi bine stabiliți, cum ar fi KNN, gradient boosting, random forest și SVM și este construit pe baza NumPy și SciPy. Scikit-learn este utilizat pe scară largă în competițiile Kaggle, precum și în companiile tehnologice importante. Acesta acoperă preprocesarea, reducerea dimensionalității, clasificarea, regresia, clusterizarea și selecția modelelor.
Scikit-learn are una dintre cele mai bune documentații dintre toate bibliotecile open-source. Oferă chiar și o diagramă interactivă de estimare. Alegerea estimatorului potrivit, care te ghidează de la dimensiunea setului de date până la o listă scurtă de algoritmi care merită încercați.
Figura de mai jos ilustrează cum funcționează Scikit-learn.
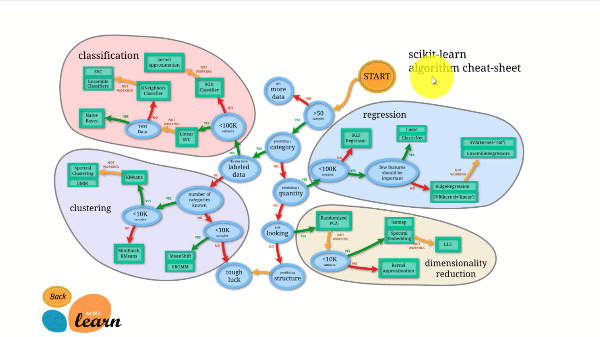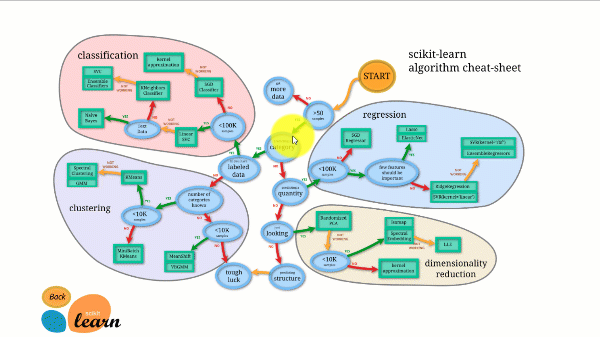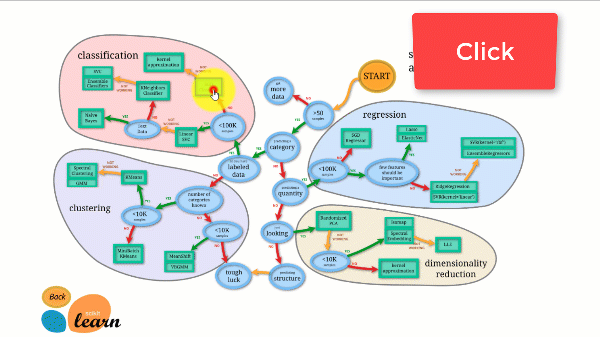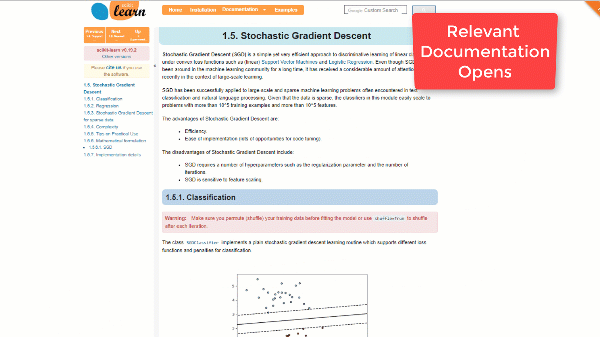
Scikit-learn nu este dificil de utilizat și oferă rezultate excelente. Cu toate acestea, se antrenează pe procesor: lucrul este paralelizat între nuclee cu argumentul n_jobs, mai degrabă decât pe un GPU. Rularea unui algoritm de deep learning cu acesta este posibilă, dar rareori optimă, mai ales dacă știi deja cum să îl folosești. TensorFlow.
Cum să descărcați și să instalați Scikit-learn
Acum în asta Python Tutorial Scikit-learn, veți învăța cum să descărcați și să instalați Scikit-learn:
Opțiunea 1: AWS
Scikit-learn poate fi utilizat prin AWS. O imagine Docker cu scikit-learn preinstalat economisește complet munca de configurare.
Pentru a instala versiunea pentru dezvoltatori, executați comanda de mai jos în Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Opțiunea 2: Mac sau Windows folosind Anaconda
Pentru a afla mai multe despre instalarea Anaconda, consultați cum se descarcă și se instalează TensorFlow.
În momentul scrierii acestei soluții, dezvoltatorii scikit lansaseră o versiune de dezvoltare care remedia problemele prezente în versiunea curentă de atunci, așa că pașii de mai jos utilizează acea versiune de dezvoltator. Pe o mașină nouă, versiunea stabilă curentă conține deja fiecare transformator folosit aici și pip install -U scikit-learn E deajuns.
Cum se instalează scikit-learn cu Conda Environment
Dacă ați instalat scikit-learn cu mediul conda, urmați pașii de mai jos pentru a actualiza la versiunea 0.20.
Pasul 1) Activați mediul tensorflow
source activate hello-tf
Pasul 2) Eliminați scikit-learn folosind comanda conda
conda remove scikit-learn
Pasul 3) Instalați versiunea pentru dezvoltatori
Instalați versiunea pentru dezvoltatori scikit-learn împreună cu bibliotecile necesare.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
NOTĂ: Windows utilizatorii au nevoie Microsoft Vizual C++ 14. Poți să-l obții aici.
Scikit-Learn Exemplu cu Machine Learning
Acest tutorial Scikit este împărțit în două părți:
- Învățare automată cu scikit-learn
- Cum să ai încredere în modelul tău cu LIME
Prima parte detaliază cum se construiește o conductă, se creează un model și se ajustează hiperparametrii, în timp ce a doua parte acoperă interpretarea modelului.
Pasul 1) Importați datele
În timpul acestui tutorial Scikit Learn, veți utiliza setul de date pentru recensământul adulților.
Fișierul este citit direct din Depozitul de Învățare Automată UCI în codul de mai jos, deci nu este necesară nicio descărcare manuală. Dacă sunteți interesat de statisticile descriptive, merită să consultați instrumentele Dive și Overview. Consultați acest tutorial pentru a afla mai multe despre Scufundare și Prezentare generală.
Importați setul de date cu pandas. Rețineți că trebuie să convertiți variabilele continue în format float.
Acest set de date include opt variabile categorice, listate în CATE_FEATURES:
- clasa de lucru
- educaţie
- marital
- ocupație
- relaţie
- rasă
- sex
- tara de origine
De asemenea, include șase variabile continue, listate în CONTI_FEATURES:
- vârstă
- fnlwgt
- educație_num
- câștig de capital
- pierdere_capital
- ore_săptămână
Listele sunt completate manual aici, astfel încât să aveți o idee mai clară despre coloanele care sunt utilizate. O modalitate mai rapidă de a construi o listă de coloane categorice sau continue este:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Iată codul pentru a importa datele:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
Apelarea funcției describe() pe frame returnează statisticile rezumative pentru cele șase coloane continue:
| vârstă | fnlwgt | educație_num | câștig de capital | pierdere_capital | ore_săptămână | |
|---|---|---|---|---|---|---|
| conta | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| însemna | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| minute | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Puteți verifica numărul de valori unice ale caracteristicii native_country. O singură gospodărie provine din Olanda. Gospodăria respectivă nu aduce nicio informație și va genera o eroare în timpul antrenamentului.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Puteți exclude acest rând neinformativ din setul de date:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Apoi, stocați poziția caracteristicilor continue într-o listă. Veți avea nevoie de el în următorul pas pentru a construi conducta.
Codul de mai jos parcurge toate numele coloanelor din CONTI_FEATURES, citește fiecare locație (adică numărul coloanei sale) și o adaugă la o listă numită conti_features.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
Următorul bloc face aceeași treabă pentru variabilele categorice.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Acum uită-te la setul de date în sine. Fiecare caracteristică categorică este un șir de caractere, iar unui model nu i se poate atribui o valoare de tip șir de caractere, așadar setul de date trebuie transformat cu variabile fictive.
df_train.head(5)
De fapt, aveți nevoie de câte o coloană pentru fiecare grup din fiecare caracteristică. Mai întâi, rulați codul de mai jos pentru a calcula numărul total de coloane necesare.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
Întregul set de date conține 101 grupuri, așa cum se arată mai sus. Numai caracteristica clasei de lucru are nouă grupuri. Puteți lista numele grupurilor cu ajutorul codului de mai jos; unique() returnează valorile distincte ale fiecărei caracteristici categorice.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Prin urmare, setul de date de antrenament va conține 101 + 6 coloane: grupurile cu un singur punct fierbinte plus cele șase caracteristici continue.
Scikit-learn se poate ocupa de conversie, în doi pași:
- Convertește șirul de caractere într-un ID. State-gov devine ID-ul 1, Self-emp-not-inc devine ID-ul 2 și așa mai departe. LabelEncoder face asta pentru tine.
- Transpuneți fiecare ID într-o coloană nouă. Setul de date are 101 ID-uri de grup, deci vor exista 101 coloane care capturează fiecare grup de caracteristici categorice. Scikit-learn oferă OneHotEncoder pentru această operațiune.
Pasul 2) Creați trenul/setul de testare
Acum că setul de date este gata, împărțiți-l 80/20: 80% pentru setul de antrenament și 20% pentru setul de testare.
Poți folosi train_test_split. Primul argument este dataframe-ul de caracteristici, iar al doilea este eticheta. Dimensiunea setului de teste se setează cu test_size.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Pasul 3) Construiți conducta
Canalul facilitează alimentarea modelului cu date consistente. Ideea este de a transmite datele brute printr-un singur obiect care efectuează fiecare operațiune în ordine.
Cu acest set de date trebuie să standardizați variabilele continue și să le convertiți pe cele categorice. Orice operațiune poate fi utilizată într-o rețea de procesare: valorile lipsă pot fi înlocuite cu media sau mediana și pot fi create variabile noi.
Ai de ales: să programezi cele două procese în mod hardcode sau să construiești o rețea de procese. Hardcoding-ul poate genera scurgeri de date de testare în statisticile ajustate și poate crea inconsistențe în timp, așa că rețeaua de procese este opțiunea mai bună.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Canalul efectuează două operațiuni înainte de a alimenta clasificatorul logistic:
- Standardizați variabila: StandardScaler()
- Convertiți caracteristicile categoriale: OneHotEncoder(sparse=False)
Ambii pași se efectuează cu make_column_transformer. Când a fost scrisă această demonstrație, funcția nu era în versiunea lansată a scikit-learn (0.19), motiv pentru care a fost utilizată versiunea pentru dezvoltatori; aceasta a fost inclusă în fiecare versiune stabilă începând cu 0.20.
`make_column_transformer` este simplu: declari ce coloane să transformi și ce transformare să aplici. Pentru a standardiza caracteristicile continue pe care le transmiți:
- conti_features, StandardScaler() în cadrul make_column_transformer
- conti_features: lista de coloane continue
- StandardScaler: standardizează acele coloane
Obiectul OneHotEncoder din cadrul make_column_transformer codifică etichetele automat.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Notă privind versiunea: Două argumente din blocul de mai sus au fost mutate. Versiunile actuale așteaptă transformatorul primul și coloanele al doilea și rar a fost redenumită ieșire_sparsă în scikit-learn 1.2 și eliminat în 1.4, deci codul mai nou citește OneHotEncoder(ieșire_rară=Fals).
Puteți testa dacă pipeline-ul funcționează cu fit_transform. Rezultatul ar trebui să aibă forma 26048, 107.
preprocess.fit_transform(X_train).shape
(26048, 107)
Transformatorul de date este gata. Creați conducta cu make_pipeline, iar odată ce datele sunt transformate, alimentați regresia logistică.
model = make_pipeline(
preprocess,
LogisticRegression())
Antrenarea unui model cu scikit-learn este atunci banală: apelați fit pe pipeline. Puteți afișa acuratețea cu metoda score.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
În cele din urmă, puteți prezice clasele cu predict_proba, care returnează probabilitatea fiecărei clase. Rețineți că suma celor două probabilități este egală cu unu.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Pasul 4) Utilizarea conductei noastre într-o căutare în grilă
Ajustarea hiperparametrilor, valorile care fixează structura modelului, poate fi plictisitoare și epuizantă.
O modalitate de a evalua modelul ar fi modificarea dimensiunii setului de antrenament și măsurarea performanței, repetând exercițiul de zece ori pentru a vedea dispersia scorului. Aceasta necesită multă muncă manuală.
În schimb, scikit-learn oferă funcții care efectuează reglarea parametrilor și validarea încrucișată.
Validare încrucișată
Validarea încrucișată înseamnă că, în timpul antrenamentului, setul de antrenament este împărțit de n ori în pliuri, iar modelul este evaluat de n ori. Dacă cv este setat la 10, modelul este antrenat și evaluat de zece ori. În fiecare rundă, clasificatorul se antrenează pe nouă pliuri alese aleatoriu, iar al zecelea pliu este păstrat pentru evaluare.
Căutare în grilă
Fiecare clasificator are hiperparametri de reglat. Puteți încerca valori pe rând sau puteți seta o grilă de parametri. Documentația scikit-learn listează toți parametrii pe care îi acceptă clasificatorul logistic. Pentru a menține antrenamentul rapid, acest exemplu reglează doar parametrul C, care controlează regularizarea. Acesta trebuie să fie pozitiv, iar o valoare mică oferă mai multă pondere regularizatorului.
Folosești obiectul GridSearchCV, care preia un dicționar al hiperparametrilor de reglat. Enumera fiecare hiperparametru urmat de valorile pe care dorești să le încerci. Pentru a regla limbajul C, scrii:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — numele parametrului este precedat de numele clasificatorului cu literă mică și două sublinieri.
Modelul va încerca patru valori diferite: 0.001, 0.01, 0.1 și 1. Este antrenat cu 10 plieri, adică cv=10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Acum puteți antrena modelul folosind GridSearchCV cu parametrii grid și cv.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
ieșire:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Notă privind versiunea: il iid Argumentul vizibil în această ieșire a fost depreciat în scikit-learn 0.22 și eliminat în 0.24, așa că ar trebui pur și simplu eliminat din apelul GridSearchCV în versiunile curente.
Pentru a accesa cei mai buni parametri, utilizați best_params_.
grid_clf.best_params_
ieșire:
{'logisticregression__C': 1.0}
După antrenarea modelului cu patru valori diferite de regularizare, parametrul optim dă:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
cea mai bună regresie logistică din căutarea în grilă: 0.850891
Pentru a accesa probabilitățile prezise:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
Model XGBoost cu scikit-learn
Acum încercați unul dintre cei mai puternici clasificatori de pe piață. XGBoost este o îmbunătățire a sistemului Random Forest care amplifică gradientul. Fundamentul său teoretic este în afara domeniului de aplicare al acestui articol. Python Tutorial Scikit, dar rețineți că XGBoost a câștigat foarte multe concursuri Kaggle. Pe un set de date de dimensiuni medii, poate funcționa la fel de bine ca un algoritm de deep learning sau chiar mai bine.
Clasificatorul este dificil de antrenat deoarece expune un număr mare de parametri. Desigur, puteți utiliza GridSearchCV pentru a-i alege automat.
O opțiune mai bună în acest caz este RandomizedSearchCV. GridSearchCV devine lent atunci când grila este mare, deoarece spațiul de căutare crește odată cu fiecare parametru adăugat. În schimb, RandomizedSearchCV eșantionează valorile fiecărui hiperparametru la întâmplare la fiecare iterație, astfel încât 1,000 de iterații evaluează 1,000 de combinații. În rest, funcționează la fel ca GridSearchCV.
Trebuie să importați xgboost. Dacă biblioteca nu este instalată, rulați comanda pip3 install xgboost sau instalați-o din interiorul unui Jupyter caiet cu:
use import sys
!{sys.executable} -m pip install xgboost
Apoi importați clasificatorul și cele două instrumente de căutare:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Următorul pas în acest Scikit Python Tutorialul este de a specifica parametrii de reglat. Documentația oficială XGBoost îi listează pe toți. De dragul acestui lucru Python În tutorialul Sklearn, alegi doar doi hiperparametri cu câte două valori fiecare, deoarece antrenarea XGBoost durează mult timp, iar fiecare punct suplimentar al grilei mărește așteptarea.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Apoi construiești o nouă conductă cu clasificatorul XGBoost și 600 de estimatori. `n_estimators` este în sine reglabil, iar o valoare mare poate duce la supra-ajustare. Poți încerca alte valori, dar reține că poate dura ore întregi. Toți ceilalți parametri își păstrează valorile implicite.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Puteți îmbunătăți validarea încrucișată cu ajutorul validatorului încrucișat Stratified K-Folds. Aici se folosesc doar trei pliuri pentru a accelera calculul, cu un anumit cost al calității; măriți acest număr la 5 sau 10 pe propriul computer pentru rezultate mai bune. Modelul este antrenat pe parcursul a patru iterații.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Căutarea randomizată este gata, deci puteți antrena modelul.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
După cum puteți vedea, XGBoost obține un scor mai bun decât regresia logistică anterioară.
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Creați DNN cu MLPClassifier în scikit-learn
În cele din urmă, poți antrena o rețea neuronală cu scikit-learn în sine. Metoda este aceeași ca pentru orice alt clasificator, iar estimatorul este MLPClassifier.
from sklearn.neural_network import MLPClassifier
Rețeaua de mai jos este definită cu:
- Adam rezolvator
- Funcția de activare ReLU
- Alfa = 0.0001
- Dimensiunea lotului de 150
- Două straturi ascunse cu 200 și, respectiv, 100 de neuroni
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Puteți modifica numărul de straturi pentru a îmbunătăți modelul.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
Scorul de regresie DNN: 0.821253
LIME: Ai încredere în modelul tău
Acum că aveți un model bun, aveți nevoie de o modalitate de a avea încredere în el. Algoritmii de învățare automată, în special pădurile aleatorii și rețelele neuronale, sunt cunoscuți sub numele de modele de tip cutie neagră: funcționează, dar nimeni nu poate înțelege de ce.
Trei cercetători au construit un instrument care arată cum ajunge computerul la o predicție. Lucrarea lor este „De ce ar trebui să am încredere în tine?”, iar algoritmul pe care l-au publicat se numește Explicații Locale Interpretabile fără a lua în considerare Modelul (LIME).
Luați un exemplu. Uneori nu știți dacă o predicție bazată pe învățarea automată poate fi de încredere. Un medic nu poate accepta un diagnostic doar pentru că l-a produs un computer și trebuie să știți dacă un model este fiabil înainte de a-l pune în producție.
Imaginați-vă că puteți vedea de ce un clasificator a făcut o predicție, chiar și pentru modele atât de complicate precum rețelele neuronale, pădurile aleatorii sau SVM-urile cu un nucleu arbitrar. Devine mult mai ușor să ai încredere într-o predicție atunci când motivele din spatele ei sunt vizibile și la fel de ușor să decizi când un model nu ar trebui să ai încredere. LIME îți spune ce caracteristici au determinat decizia clasificatorului.
Pregătirea datelor
Există câteva lucruri pe care trebuie să le schimbi pentru a rula LIME PythonMai întâi, instalați lime în terminal cu comanda pip install lime.
Lime folosește un obiect LimeTabularExplainer pentru a aproxima modelul local. Acest obiect necesită:
- un set de date în NumPy format
- Numele caracteristicilor: feature_names
- Numele claselor: class_names
- Indexul coloanei caracteristicilor categoriale: caracteristici_categorice
- Numele grupului pentru fiecare caracteristică categorică: nume_categorice
Creați setul de trenuri NumPy
Puteți copia și converti df_train din pandas în NumPy foarte ușor.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Obțineți numele clasei
Eticheta este accesibilă prin unique(). Ar trebui să vedeți:
- „<=50K”
- „>50K”
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Indexarea coloanelor de caracteristici categorice
Folosește metoda învățată anterior pentru a obține numele fiecărui grup. Codifică eticheta cu LabelEncoder și repetă operațiunea pentru fiecare caracteristică categorică.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Acum că setul de date este gata, puteți construi diferitele seturi de date prezentate în exemplele de învățare Scikit de mai jos. Datele sunt transformate în afara canalului de procesare pentru a evita erorile cu LIME: setul de antrenament transmis către LimeTabularExplainer trebuie să fie un array NumPy fără șiruri de caractere, iar metoda de mai sus a produs deja unul.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
Puteți crea conducta cu parametrii optimi găsiți de XGBoost.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Primești un avertisment. Acesta explică faptul că nu este nevoie să creezi un codificator de etichete înainte de pipeline. Dacă nu folosești LIME, metoda din prima parte a acestui tutorial Machine Learning with Scikit-learn este în regulă. În caz contrar, păstrează această abordare: creează mai întâi un set de date codificat, apoi aplică codificatorul one-hot în interiorul pipeline-ului.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Înainte de a folosi LIME, creați un array NumPy care să conțină caracteristicile rândurilor clasificate greșit. Puteți folosi acea listă mai târziu pentru a vă face o idee despre ce a indus în eroare clasificatorul.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
Apoi creați o funcție lambda care preia predicția din model pentru date noi. Veți avea nevoie de ea în curând.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Convertiți cadrul de date pandas într-un array NumPy.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Acum alegeți o gospodărie aleatorie din setul de testare și observați atât predicția, cât și modul în care a ajuns computerul la ea.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Puteți folosi explicatorul cu explain_instance pentru a inspecta raționamentul din spatele modelului. Graficul pe care îl redă este prezentat mai jos.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Clasificatorul a prezis corect această gospodărie: venitul este într-adevăr peste 50.
Primul lucru de remarcat este că clasificatorul nu este foarte sigur pe sine. Acesta prezice un venit peste 50 de dolari cu o probabilitate de 64%, iar această probabilitate de 64% este determinată de câștigul de capital și de starea civilă. Culoarea albastră contribuie negativ la clasa pozitivă, iar linia portocalie pozitiv.
Clasificatorul este ezitant deoarece câștigul de capital al acestei gospodării este zero, în timp ce câștigul de capital este de obicei un bun predictor al averii. De asemenea, gospodăriile lucrează mai puțin de 40 de ore pe săptămână. Vârsta, ocupația și sexul contribuie toate pozitiv.
Dacă starea civilă ar fi fost celibatară, clasificatorul ar fi prezis un venit sub 50 (0.64 – 0.18 = 0.46).
Acum încercați o altă gospodărie, una care a fost clasificată greșit. Tabelul explicativ pentru aceasta respectă codul.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Clasificatorul a prezis un venit sub 50, ceea ce este greșit. Această gospodărie este neobișnuită: nu are nici câștig de capital, nici pierdere de capital, persoana este divorțată, are aproape 60 de ani și este educată, adică education_num > 12. Urmând modelul general, clasificatorul a plasat gospodăria sub 50.
Exersează-te cu LIME și vei observa o mulțime de greșeli grosolane din partea clasificatorului. Repozitoriul GitHub al autorului bibliotecii conține documentație suplimentară pentru clasificarea imaginilor și a textului.
Referință comandă Scikit-learn
Mai jos este o listă de comenzi utile care se aplică la scikit-learn versiunea 0.20 și versiunile ulterioare.
| Sarcină | Funcție sau clasă |
|---|---|
| Creați setul de date tren/test | train_test_split |
| Construiți o conductă | |
| Selectați coloanele și aplicați transformarea | transformator_de_coloană |
| Tipul de transformare | |
| Standardiza | StandardScaler |
| Scalare min-max | MinMaxScaler |
| Normaliza | Normalizator |
| Imputarea valorilor lipsă | SimpleImputer |
| Convertiți categoric | OneHotEncoder |
| Potriviți și transformați datele | potrivi_transforma |
| Faceți conducta | make_pipeline |
| Model de bază | |
| Regresie logistică | Regresie logistică |
| XGBoost | XGBClassifier |
| Rețea neuronală | Clasificator MLPC |
| Căutare în grilă | GridSearchCV |
| Căutare aleatorie | RandomizedSearchCV |