Incorporação de palavras e Word2Vec com exemplos
⚡ Resumo Inteligente
Word Embedding e Word2Vec convertem texto em vetores numéricos densos para que modelos de aprendizado de máquina reconheçam palavras com significados semelhantes. Este recurso explica a técnica, suas arquiteturas CBOW e Skip-Gram, funções de ativação e uma implementação completa no Gensim para aplicações reais.
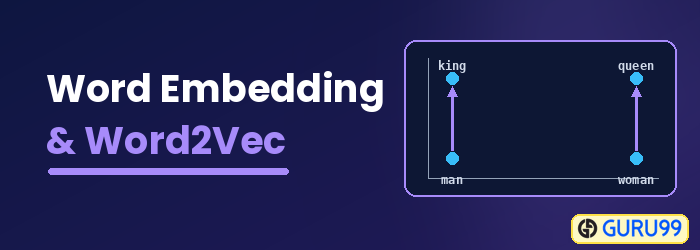
O que é incorporação de palavras?
Incorporação de palavras é um tipo de representação de palavras que permite que algoritmos de aprendizado de máquina entendam palavras com significados semelhantes. É uma técnica de modelagem de linguagem e aprendizado de recursos para mapear palavras em vetores de números reais usando redes neurais, modelos probabilísticos ou redução de dimensionalidade na matriz de coocorrência de palavras. Alguns modelos de incorporação de palavras são Word2vec (Google), GloVe (Stanford) e fastText (Facebook).
O Word Embedding também é chamado de modelo semântico distribuído, modelo de representação distribuída, espaço vetorial semântico ou modelo de espaço vetorial. Ao ler esses nomes, você se depara com a palavra semânticoO que significa categorizar palavras semelhantes juntas. Por exemplo, frutas como maçã, manga e banana devem ser colocadas próximas umas das outras, enquanto livros serão colocados longe dessas palavras. Em um sentido mais amplo, o word embedding criará um vetor de frutas que será colocado longe da representação vetorial de livros.
Onde a incorporação de palavras é usada?
A incorporação de palavras auxilia na geração de características, agrupamento de documentos, classificação de texto e processamento de linguagem natural. Vamos listar essas aplicações e discutir cada uma delas.
- Calcule palavras semelhantes: A incorporação de palavras é usada para sugerir palavras semelhantes à palavra que está sendo submetida ao modelo de previsão. Além disso, também sugere palavras diferentes, bem como as palavras mais comuns.
- Crie um grupo de palavras relacionadas: É usado para agrupamento semântico.ping, que agrupa coisas com características semelhantes e afasta itens diferentes.
- Recurso para classificação de texto: O texto é mapeado em matrizes de vetores que são fornecidas ao modelo para treinamento e previsão. Modelos de classificação baseados em texto não podem ser treinados com strings, portanto, esse método converte o texto em um formato treinável por máquina. Seus recursos de construção semântica auxiliam ainda mais na classificação baseada em texto.
- Agrupamento de documentos: Esta é mais uma aplicação onde Word Embedding e Word2vec são amplamente utilizados.
- Processamento de linguagem natural: Existem muitas aplicações em que o word embedding é útil e supera o feature extracfases de análise, como a classificação gramatical, a análise de sentimentos e a análise sintática.
Agora que você entende onde o word embedding é aplicado, vamos analisar o modelo mais popular usado para criar esses embeddings.
O que é Word2vec?
Word2vec É uma técnica ou modelo que produz representações vetoriais de palavras para uma melhor representação das mesmas. Trata-se de um método de processamento de linguagem natural que captura um grande número de relações sintáticas e semânticas precisas entre palavras. É uma rede neural rasa de duas camadas que, após o treinamento, consegue detectar palavras sinônimas e sugerir palavras adicionais para frases parciais.
Antes de prosseguirmos, observe a diferença entre uma rede neural rasa e uma rede neural profunda, conforme mostrado no diagrama de exemplo de incorporação de palavras abaixo:
Uma rede neural rasa consiste em apenas uma camada oculta entre a entrada e a saída, enquanto uma rede neural profunda contém múltiplas camadas ocultas entre a entrada e a saída. A entrada é processada por nós, enquanto a camada oculta, assim como a camada de saída, contém neurônios.
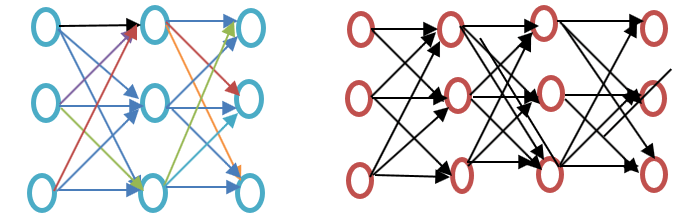
Word2vec é uma rede de duas camadas, composta por uma camada de entrada, uma camada oculta e uma camada de saída.
O Word2vec foi desenvolvido por um grupo de pesquisadores liderado por Tomas Mikolov em GoogleO Word2vec é melhor e mais eficiente do que o modelo de análise semântica latente.
Por que Word2vec?
O Word2vec representa palavras em um espaço vetorial. As palavras são representadas na forma de vetores, e o posicionamento é feito de forma que palavras com significados semelhantes apareçam juntas e palavras com significados diferentes fiquem distantes umas das outras. Isso também é chamado de relação semântica. Redes neurais não entendem texto; em vez disso, elas entendem apenas números. O Word Embedding (incorporação de palavras) fornece uma maneira de converter texto em um vetor numérico.
O Word2vec reconstrói o contexto linguístico das palavras. Antes de prosseguirmos, vamos entender o que é contexto linguístico. Em um cenário geral, quando falamos ou escrevemos para nos comunicar, outras pessoas tentam descobrir o objetivo da frase. Por exemplo: “Qual é a temperatura da Índia?” Aqui, o contexto é que o usuário quer saber a “temperatura da Índia”. Resumindo, o principal objetivo de uma frase é o contexto. As palavras ou frases que cercam a linguagem falada ou escrita ajudam a determinar o significado do contexto. O Word2vec aprende a representação vetorial das palavras por meio desses contextos.
O que o Word2vec faz?
Antes da incorporação de palavras
É importante saber qual abordagem era usada antes do word embedding e quais eram suas desvantagens. Em seguida, veremos como essas desvantagens são superadas pelo word embedding usando a abordagem Word2vec. Finalmente, abordaremos o funcionamento do Word2vec, pois é fundamental entender seu processo.
Abordagem para Análise Semântica Latente
Essa é a abordagem usada antes dos word embeddings. Ela utiliza o conceito de "Saco de Palavras", onde as palavras são representadas na forma de vetores codificados. Trata-se de uma representação vetorial esparsa, cuja dimensão é igual ao tamanho do vocabulário. Se a palavra ocorre no dicionário, ela é contabilizada; caso contrário, não é. Para entender melhor, veja o programa abaixo.
Exemplo Word2vec

from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer() data_corpus = ["guru99 is the best site for online tutorials. I love to visit guru99."] vocabulary = vectorizer.fit(data_corpus) X = vectorizer.transform(data_corpus) print(X.toarray()) print(vectorizer.get_feature_names_out())
Saída:
[[1 2 1 1 1 1 1 1 1 1]] [u'best', u'guru99', u'is', u'love', u'online', u'sitefor', u'the', u'to', u'tutorials', u'visit']
Code Explicação
- O módulo CountVectorizer é usado para armazenar o vocabulário com base na correspondência das palavras a ele. Ele é importado do sklearn.
- Faça o objeto usando a classe CountVectorizer.
- Escreva os dados da lista que devem ser ajustados no CountVectorizer.
- Os dados cabem no objeto criado a partir da classe CountVectorizer.
- Aplique uma abordagem de saco de palavras para contar palavras nos dados usando o vocabulário. Se uma palavra ou token não estiver disponível no vocabulário, a posição do índice correspondente será definida como zero.
- A variável na linha 5, que é x, é convertida em um array (um método disponível para x). Isso fornece a contagem de cada token na frase ou lista fornecida na linha 3.
- Isto mostra as características que fazem parte do vocabulário quando este é ajustado utilizando os dados da linha 4.
Na abordagem da Semântica Latente, a linha representa palavras únicas, enquanto a coluna representa o número de vezes que essa palavra aparece no documento. Trata-se de uma representação das palavras na forma de uma matriz de documentos. O coeficiente TF-IDF (Frequência do Termo-Frequência Inversa do Documento) é utilizado para calcular a frequência das palavras no documento, dividindo-se a frequência do termo no documento pela frequência do termo em todo o corpus.
Deficiência do método Bag of Words
- Ignora a ordem das palavras; por exemplo, isto é mau = Isso é ruim..
- Ignora o contexto das palavras. Suponha que escrevamos a frase "Ele amava livros. A melhor educação é encontrada nos livros." Isso criaria dois vetores: um para "Ele amava livros" e outro para "A melhor educação é encontrada nos livros". Ambos seriam tratados como ortogonais, o que os tornaria independentes, mas, na realidade, estão relacionados.
Para superar essas limitações, foi desenvolvido o word embedding, e o Word2vec é uma das abordagens utilizadas para implementá-lo.
Como funciona o Word2vec?
O Word2vec aprende uma palavra prevendo o contexto em que ela está inserida. Por exemplo, vamos considerar a palavra "Ele". ama Futebol."
Queremos calcular o Word2vec para a palavra: ama.
Suponha:
loves = Vin. P(Vout / Vin) is calculated where, Vin is the input word. P is the probability of likelihood. Vout is the output word.
A palavra ama O algoritmo percorre cada palavra do corpus, codificando as relações sintáticas e semânticas entre elas. Isso auxilia na identificação de palavras semelhantes e análogas.
Todas as características aleatórias da palavra ama são calculados. Essas características são alteradas ou atualizadas em relação às palavras vizinhas ou contextuais com a ajuda de um Retropropagação método.
Outra forma de aprendizado é que, se os contextos de duas palavras forem semelhantes, ou se duas palavras tiverem características semelhantes, então essas palavras estão relacionadas.
Word2vec Archiarquitetura
Existem duas arquiteturas usadas pelo Word2vec:
- Saco de Palavras Contínuo (CBOW)
- Skip-gram
Antes de prosseguirmos, vamos discutir por que essas arquiteturas ou modelos são importantes do ponto de vista da representação de palavras. O aprendizado da representação de palavras é essencialmente não supervisionado, mas alvos/rótulos são necessários para treinar o modelo. Skip-gram e CBOW convertem a representação não supervisionada em uma forma supervisionada para o treinamento do modelo.
No CBOW, a palavra atual é prevista usando a janela das janelas de contexto circundantes. Por exemplo, se wi-1, Wi-2, Wi + 1, Wi + 2 recebem palavras ou contexto, este modelo fornecerá wi.
O Skip-Gram realiza a função oposta à do CBOW, ou seja, prevê a sequência ou o contexto a partir da palavra. Você pode inverter o exemplo para entender melhor. Se wi se for dado, isso preverá o contexto, ou wi-1, Wi-2, Wi + 1, Wi + 2.
O Word2vec oferece a opção de escolher entre CBOW (Continuous Bag of Words) e skip-gram. Esses parâmetros são fornecidos durante o treinamento do modelo. É possível optar por usar amostragem negativa ou uma camada softmax hierárquica.
Saco Contínuo de Palavras
Vamos desenhar um diagrama de exemplo simples do Word2vec para entender a arquitetura de saco de palavras contínuo.

Vamos calcular as equações matematicamente. Suponha que V seja o tamanho do vocabulário e N seja o tamanho da camada oculta. A entrada é definida como { xi-1, xi-2, xi + 1, xi + 2 Obtemos a matriz de pesos multiplicando V * N. Outra matriz é obtida multiplicando o vetor de entrada pela matriz de pesos. Isso também pode ser compreendido pela seguinte equação.
h = xitW
onde xit e W são, respectivamente, o vetor de entrada e a matriz de pesos.
Para calcular a correspondência entre o contexto e a próxima palavra, consulte a equação abaixo.
u = representação prevista * h
onde a representação prevista é obtida a partir do modelo na equação acima.
Modelo Skip-Gram
A abordagem Skip-Gram é usada para prever uma frase a partir de uma palavra de entrada. Para melhor compreensão, vejamos o diagrama apresentado no exemplo Word2vec abaixo.

Pode-se considerar esse modelo como o inverso do modelo Continuous Bag of Words, onde a entrada é a palavra e o modelo fornece o contexto ou a sequência. Podemos também concluir que o alvo é fornecido como entrada, e a camada de saída é replicada várias vezes para acomodar o número escolhido de palavras de contexto. O vetor de erro de todas as camadas de saída é somado para ajustar os pesos por meio de um método de retropropagação.
Qual modelo escolher?
O CBOW é várias vezes mais rápido que o skip-gram e fornece uma frequência melhor para palavras frequentes, enquanto o skip-gram precisa de uma pequena quantidade de dados de treinamento e representa até mesmo palavras ou frases raras. A tabela abaixo compara ambas as arquiteturas rapidamente.
| Aspecto | CBOW | Pular grama |
|---|---|---|
| Predição | Prevê a palavra-alvo a partir do contexto. | Prevê o contexto a partir da palavra-alvo. |
| Velocidade de treino | Mais rápido | Mais lento |
| Palavras frequentes | Maior precisão | Precisão menor |
| Palavras raras | Representação mais fraca | Representação mais forte |
| Dados de treinamento | Precisa de mais dados | Funciona com menos dados |
A relação entre Word2vec e NLTK
NLTK é o Natural Language ToolO Word2vec é um kit de pré-processamento de texto. Ele permite realizar diversas operações, como marcação gramatical, lematização, stemming, remoção de stopwords e remoção de palavras raras ou pouco usadas. Isso auxilia na limpeza do texto e na extração de características das palavras mais relevantes. Por outro lado, o Word2vec é utilizado para correspondência semântica (itens intimamente relacionados) e sintática (sequência). Com o Word2vec, é possível encontrar palavras semelhantes, palavras diferentes, realizar redução de dimensionalidade e muito mais. Outra característica importante do Word2vec é a conversão da representação de texto de alta dimensionalidade em vetores de baixa dimensionalidade.
Onde usar NLTK e Word2vec?
Se for necessário realizar tarefas de propósito geral, como tokenização, etiquetagem POS e análise sintática, deve-se optar pelo NLTK, enquanto que para prever palavras de acordo com algum contexto, modelagem de tópicos ou similaridade de documentos, deve-se usar o Word2vec.
Relação de NLTK e Word2vec com ajuda de código
NLTK e Word2vec podem ser usados em conjunto para encontrar representações de palavras semelhantes ou correspondências sintáticas. O toolkit NLTK permite carregar diversos pacotes que acompanham o NLTK, e um modelo pode ser criado usando o Word2vec. Em seguida, ele pode ser testado com palavras em tempo real. Vejamos a combinação de ambos no código a seguir. Antes de prosseguir, consulte os corpora fornecidos pelo NLTK. Você pode baixá-los usando o comando:
nltk(nltk.download('all'))

Por favor, veja a captura de tela para o código.
import nltk import gensim from nltk.corpus import abc model = gensim.models.Word2Vec(abc.sents()) X = list(model.wv.vocab) data = model.most_similar('science') print(data)

Saída:
[('law', 0.9415997266769409), ('practice', 0.9276568293571472), ('discussion', 0.9259148836135864), ('agriculture', 0.9257254004478455), ('media', 0.9232194423675537), ('policy', 0.922248125076294), ('general', 0.9166069030761719), ('undertaking', 0.916458249092102), ('tight', 0.9129181504249573), ('board', 0.9107444286346436)]
Explicação de Code
- A biblioteca nltk foi importada, de onde você pode baixar o corpus abc que usaremos na próxima etapa.
- O Gensim foi importado. Se o Gensim Word2vec não estiver instalado, instale-o usando o comando “pip3 install gensim”. Veja a captura de tela abaixo.

- Importe o corpus abc, que foi baixado usando nltk.download('abc').
- Passe os arquivos para o modelo Word2vec, que é importado usando o Gensim, como frases.
- O vocabulário é armazenado na forma de uma variável.
- O modelo é testado na palavra de exemplo. ciência, visto que esses arquivos estão relacionados à ciência.
- Aqui, o modelo prevê uma palavra semelhante à "ciência".
Ativadores e Word2Vec
A função de ativação de um neurônio define a saída desse neurônio em resposta a um conjunto de estímulos. Ela é inspirada biologicamente pela atividade em nossos cérebros, onde diferentes neurônios são ativados por diferentes estímulos. Vamos entender a função de ativação através do diagrama a seguir.

Aqui, x1, x2, … x4 são os nós da rede neural.
w1, w2 e w3 são os pesos dos nós.
A soma (Σ) de todos os pesos e valores dos nós funciona como a função de ativação.
Por que função de ativação?
Se nenhuma função de ativação for usada, a saída será linear, mas a funcionalidade de uma função linear é limitada. Para alcançar funcionalidades complexas como detecção de objetos, classificação de imagens, etc., é necessário utilizar uma função de ativação.ping Para gerar texto usando voz e para muitas outras saídas não lineares, é necessária uma função de ativação.
Como a camada de ativação é calculada na incorporação de palavras (Word2vec)
A camada Softmax (função exponencial normalizada) é a função da camada de saída que ativa ou dispara cada nó. Outra abordagem utilizada é a Softmax Hierárquica, cuja complexidade é calculada por O(log n).2V), enquanto que na softmax é O(V), onde V é o tamanho do vocabulário. A diferença entre elas reside na redução da complexidade na camada softmax hierárquica. Para entender seu funcionamento, veja o exemplo de incorporação de palavras abaixo:

Suponha que queiramos calcular a probabilidade de observar a palavra gosta, Dado um determinado contexto, o fluxo da raiz para o nó folha primeiro se moverá para o nó 2 e depois para o nó 5. Portanto, se tivermos um vocabulário de tamanho 8, apenas três cálculos serão necessários. Isso permite decompor o cálculo da probabilidade de uma palavra (gosta,).
Que outras opções estão disponíveis além do Softmax hierárquico?
De forma geral, as opções de incorporação de palavras disponíveis são: Softmax Diferenciado, CNN-Softmax, Amostragem por Importância, Amostragem por Importância Adaptativa, Estimativa de Contraste de Ruído, Amostragem Negativa, Auto-Normalização e Normalização Infrequente.
Falando especificamente sobre o Word2vec, temos amostragem negativa disponível.
A amostragem negativa é uma forma de amostrar os dados de treinamento. É semelhante ao método do gradiente descendente estocástico, mas com algumas diferenças. A amostragem negativa busca apenas exemplos de treinamento negativos. Ela se baseia na estimativa contrastiva de ruído e amostra aleatoriamente palavras que não estão no contexto. É um método de treinamento rápido e escolhe o contexto aleatoriamente. Se a palavra prevista aparecer no contexto escolhido aleatoriamente, ambos os vetores estarão próximos um do outro.
Que conclusão pode ser tirada?
Os ativadores disparam os neurônios da mesma forma que nossos neurônios são disparados por estímulos externos. A camada Softmax é uma das funções da camada de saída que dispara os neurônios no caso de embeddings de palavras. No Word2vec, temos opções como softmax hierárquico e amostragem negativa. Usando ativadores, é possível converter uma função linear em uma função não linear, e um algoritmo complexo de aprendizado de máquina pode ser implementado utilizando essas funções.
O que é Gensim?
Gensim é um kit de ferramentas de modelagem de tópicos e processamento de linguagem natural de código aberto que é implementado em Python e Cython. O kit de ferramentas Gensim permite que os usuários importem o Word2vec para modelagem de tópicos, a fim de descobrir estruturas ocultas no corpo do texto. O Gensim fornece não apenas uma implementação do Word2vec, mas também do Doc2vec e do FastText.
Esta seção se concentra no Word2vec, portanto, vamos nos ater ao tópico atual.
Como implementar Word2vec usando Gensim
Até agora, discutimos o que é Word2vec, suas diferentes arquiteturas, por que há uma mudança de um modelo de saco de palavras para Word2vec, a relação entre Word2vec e NLTK com código em execução e funções de ativação.
A seguir, apresentamos o método passo a passo para implementar o Word2vec usando o Gensim:
Etapa 1) Coleta de dados
O primeiro passo para implementar qualquer modelo de aprendizado de máquina ou processamento de linguagem natural é a coleta de dados.
Observe os dados para construir um chatbot inteligente, conforme mostrado no exemplo Gensim Word2vec abaixo.
[{"tag": "welcome",
"patterns": ["Hi", "How are you", "Is any one to talk?", "Hello", "hi are you available"],
"responses": ["Hello, thanks for contacting us", "Good to see you here", "Hi there, how may I assist you?"]
},
{"tag": "goodbye",
"patterns": ["Bye", "See you later", "Goodbye", "I will come back soon"],
"responses": ["See you later, thanks for visiting", "have a great day ahead", "Wish you Come back again soon."]
},
{"tag": "thankful",
"patterns": ["Thanks for helping me", "Thank your guidance", "That's helpful and kind from you"],
"responses": ["Happy to help!", "Any time!", "My pleasure", "It is my duty to help you"]
},
{"tag": "hoursopening",
"patterns": ["What hours are you open?", "Tell your opening time?", "When are you open?", "Just your timing please"],
"responses": ["We're open every day 8am-7pm", "Our office hours are 8am-7pm every day", "We open office at 8 am and close at 7 pm"]
},
{"tag": "payments",
"patterns": ["Can I pay using credit card?", "Can I pay using Mastercard?", "Can I pay using cash only?"],
"responses": ["We accept VISA, Mastercard and credit card", "We accept credit card, debit cards and cash. Please don't worry"]
}
]
Eis o que concluímos a partir dos dados:
- Esses dados contêm três elementos: tag, padrão e respostas. A tag representa a intenção (qual é o tópico da discussão).
- Os dados estão no formato JSON.
- Um padrão é uma pergunta que os usuários farão ao bot.
- As respostas são as informações que o chatbot fornecerá para a pergunta/padrão correspondente.
Etapa 2) Pré-processamento de dados
É muito importante processar os dados brutos. Se os dados limpos forem alimentados na máquina, o modelo responderá com mais precisão e aprenderá os dados com mais eficiência.
Esta etapa envolve a remoção de palavras irrelevantes, lematização, palavras desnecessárias, etc. Antes de prosseguir, é importante carregar os dados e convertê-los em um dataframe. Veja o código abaixo para isso.
import json json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f)
Explicação de Code:
- Como os dados estão em formato JSON, o JSON é importado.
- O arquivo está armazenado na variável.
- O arquivo é aberto e carregado na variável de dados.
Agora que os dados foram importados, é hora de convertê-los em um dataframe. Veja o código abaixo para o próximo passo.
import pandas as pd df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join)
Explicação de Code:
1. Os dados são convertidos em um data frame usando o pandas, que foi importado anteriormente.
2. Converte a lista de padrões de coluna em uma string.
from nltk.corpus import stopwords from textblob import Word stop = stopwords.words('english') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()]))
Code Explicação:
1. As palavras irrelevantes em inglês são importadas usando o módulo stop-word do kit de ferramentas nltk.
2. Todas as palavras do texto são convertidas para minúsculas usando uma condição `for` e uma função lambda. Função lambda é uma função anônima.
3. Todas as linhas do texto no quadro de dados são verificadas quanto à presença de pontuação e, em seguida, filtradas.
4. Caracteres como números ou pontos são removidos usando uma expressão regular.
5. Digits são removidos do texto.
6. As palavras irrelevantes são removidas nesta fase.
7. As palavras foram filtradas e diferentes formas da mesma palavra foram removidas usando lematização. Com isso, concluímos o pré-processamento dos dados.
Saída:
, patterns, responses, tag 0,hi one talk hello hi available,"['Hello, thanks for contacting us', 'Good to see you here', ' Hi there, how may I assist you?']",welcome 1,bye see later goodbye come back soon,"['See you later, thanks for visiting', 'have a great day ahead', 'Wish you Come back again soon.']",goodbye 2,thanks helping thank guidance thats helpful kind,"['Happy to help!', 'Any time!', 'My pleasure', 'It is my duty to help you']",thankful 3,hour open tell opening time open timing please,"[""We're open every day 8am-7pm"", 'Our office hours are 8am-7pm every day', 'We open office at 8 am and close at 7 pm']",hoursopening 4,pay using credit card pay using mastercard pay using cash,"['We accept VISA, Mastercard and credit card', 'We accept credit card, debit cards and cash. Please dont worry']",payments
Etapa 3) Construção de rede neural usando Word2vec
Agora é hora de construir um modelo usando o módulo Word2vec do Gensim. Precisamos importar o Word2vec do Gensim. Vamos fazer isso, e então construiremos o modelo. Na etapa final, testaremos o modelo com dados em tempo real.
from gensim.models import Word2Vec
Agora podemos construir o modelo com sucesso usando o Word2Vec. Consulte a próxima linha de código para aprender como criar o modelo usando o Word2Vec. O texto é fornecido ao modelo na forma de uma lista, então vamos converter o texto do dataframe para uma lista usando o código abaixo.
Bigger_list = [] for i in df['patterns']: li = list(i.split("")) Bigger_list.append(li) Model = Word2Vec(Bigger_list, min_count=1, size=300, workers=4)
Explicação de Code:
1. Criou-se a lista `bigger_list`, onde a lista interna é anexada. Este é o formato que é fornecido ao modelo Word2Vec.
2. Um laço é implementado e cada entrada da coluna "patterns" do dataframe é iterada.
3. Cada elemento dos padrões de coluna é dividido e armazenado na lista interna li.
4. A lista interna é concatenada com a lista externa.
5. Esta lista é fornecida ao modelo Word2Vec. Vamos entender alguns dos parâmetros fornecidos aqui.
Contagem_mín.: Ignora todas as palavras com frequência total inferior a esta.
Tamanho Ele informa a dimensionalidade dos vetores de palavras.
Trabalhadores: Essas são as threads para treinar o modelo.
Existem também outras opções disponíveis, e algumas das mais importantes são explicadas abaixo.
Janela: Distância máxima entre a palavra atual e a prevista em uma frase.
Sg: Trata-se de um algoritmo de treinamento: 1 para skip-gram e 0 para Continuous Bag of Words. Já discutimos esses algoritmos em detalhes acima.
Hs: Se o valor for 1, estamos usando softmax hierárquico para o treinamento, e se for 0, estamos usando amostragem negativa.
Alfa: Taxa de aprendizagem inicial.
Vamos exibir o código final abaixo:
# list of libraries used by the code import string from gensim.models import Word2Vec import logging from nltk.corpus import stopwords from textblob import Word import json import pandas as pd # data in json format json_file = 'intents.json' with open('intents.json', 'r') as f: data = json.load(f) # displaying the list of stopwords stop = stopwords.words('english') # dataframe df = pd.DataFrame(data) df['patterns'] = df['patterns'].apply(', '.join) # cleaning the data using the NLP approach print(df) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x.lower() for x in x.split())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in string.punctuation)) df['patterns'] = df['patterns'].str.replace('[^\w\s]', '') df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if not x.isdigit())) df['patterns'] = df['patterns'].apply(lambda x: ' '.join(x for x in x.split() if x not in stop)) df['patterns'] = df['patterns'].apply(lambda x: " ".join([Word(word).lemmatize() for word in x.split()])) # taking the outer list bigger_list = [] for i in df['patterns']: li = list(i.split(" ")) bigger_list.append(li) # structure of data to be taken by the model.word2vec print("Data format for the overall list:", bigger_list) # custom data is fed to machine for further processing model = Word2Vec(bigger_list, min_count=1, size=300, workers=4)
Etapa 4) Salvamento do modelo
O modelo pode ser salvo nos formatos binário (bin) e modelo (file). O formato binário é utilizado. Consulte as instruções abaixo para salvar o modelo.
model.save("word2vec.model") model.save("model.bin")
Explicação do código acima
1. O modelo é salvo no formato de um arquivo .model.
2. O modelo é salvo no formato de um arquivo .bin.
Usaremos esse modelo para realizar testes em tempo real, como palavras semelhantes, palavras diferentes e palavras mais comuns.
Etapa 5) Carregando o modelo e realizando testes em tempo real
O modelo é carregado usando o código abaixo:
model = Word2Vec.load('model.bin')
Se você quiser imprimir o vocabulário, isso é feito usando o comando abaixo:
vocab = list(model.wv.vocab)
Por favor veja o resultado:
['see', 'thank', 'back', 'thanks', 'soon', 'open', 'mastercard', 'card', 'time', 'pay', 'talk', 'cash', 'one', 'please', 'goodbye', 'thats', 'helpful', 'hour', 'credit', 'hi', 'later', 'guidance', 'opening', 'timing', 'hello', 'helping', 'bye', 'tell', 'come', 'using', 'kind', 'available']
Etapa 6) Verificação de palavras mais semelhantes
Vamos implementar as coisas na prática:
similar_words = model.most_similar('thanks') print(similar_words)
Por favor veja o resultado:
[('kind', 0.16104359924793243), ('using', 0.1352398842573166), ('come', 0.11500970274209976), ('later', 0.09989878535270691), ('helping', 0.04855936020612717), ('credit', 0.04659383371472359), ('pay', 0.0329081267118454), ('thank', 0.02484947443008423), ('hour', 0.0202352125197649), ('opening', 0.018177658319473267)]
Etapa 7) Não corresponde à palavra das palavras fornecidas
dissimlar_words = model.doesnt_match('See you later, thanks for visiting'.split()) print(dissimlar_words)
Nós fornecemos as palavras 'Até logo, obrigado pela visita'Este código imprime a palavra mais diferente dentre essas palavras. Vamos executar o código e verificar o resultado.
O resultado após a execução do código acima:
Thanks
Etapa 8) Encontrar a semelhança entre duas palavras
Isso indica o resultado em termos da probabilidade de similaridade entre duas palavras. Veja o código abaixo para saber como executar esta seção.
similarity_two_words = model.similarity('please', 'see') print("Please provide the similarity between these two words:") print(similarity_two_words)
O resultado do código acima é o seguinte:
0.13706
Você pode encontrar outras palavras semelhantes executando o código abaixo:
similar = model.similar_by_word('kind') print(similar)
Resultado do código acima:
[('credit', 0.11764447391033173), ('cash', 0.11440904438495636), ('one', 0.11151769757270813), ('hour', 0.0944807156920433), ('using', 0.0705675333738327), ('thats', 0.05206916481256485), ('later', 0.04502468928694725), ('bye', 0.03960943967103958), ('back', 0.03837274760007858), ('thank', 0.0380823090672493)]