Python Arquivo XML – Como ler, escrever e analisar
⚡ Resumo Inteligente
Python O processamento XML permite ler, escrever e analisar documentos XML usando os módulos integrados minidom e ElementTree. A classe minidom carrega um arquivo na memória como um DOM, enquanto o ElementTree oferece uma abordagem mais rápida e abrangente. PythonAPI da árvore IC.

As seções abaixo abordam a análise sintática, a escrita e a leitura de arquivos XML em Python.
O que é XML?
XML significa eXtensible Markup Language. Ele foi projetado para armazenar e transportar pequenas e médias quantidades de dados e é amplamente utilizado para compartilhar informações estruturadas.
Python Permite analisar e modificar documentos XML. Para analisar um documento XML, você precisa ter o documento XML inteiro na memória. Neste tutorial, veremos como podemos usar a classe minidom do XML em Python para carregar e analisar arquivos XML.
Como analisar XML usando minidom
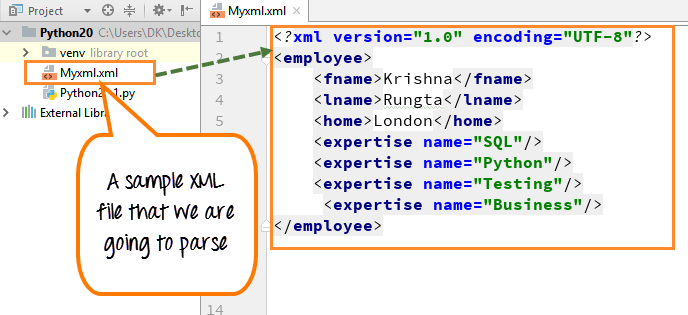
Criamos um arquivo XML de amostra que iremos analisar.
Etapa 1) Criar arquivo XML de amostra
Dentro do arquivo, podemos ver o nome, sobrenome, residência e área de atuação (SQL, Python, Testes e Negócios).
Etapa 2) Use a função de análise para carregar e analisar o arquivo XML
Após analisarmos o documento, imprimiremos o "nome do nó" da raiz do documento e o "nome da tag do primeiro filho". Tagname e nodename são propriedades padrão do arquivo XML.

- Importe o módulo xml.dom.minidom e declare o arquivo que deve ser analisado (myxml.xml).
- Este arquivo contém algumas informações básicas sobre um funcionário, como nome, sobrenome, residência, especialização, etc.
- Usamos a função de análise no minidom XML para carregar e analisar o arquivo XML
- Temos uma variável `doc`, e `doc` recebe o resultado da função `parse`.
- Queremos imprimir o nome do nó e o nome da tag filha do arquivo, então declaramos isso na função de impressão.
- Execute o código - ele imprime o nome do nó (#document) do arquivo XML e o primeiro tagname filho (funcionário) do arquivo XML
ObservaçãoNodename e child tagname são os nomes ou propriedades padrão de um DOM XML.
Passo 3) Obtenha a lista de tags XML do documento XML e imprima-a.
Em seguida, também podemos extrair a lista de tags XML do documento XML e imprimi-la. Aqui, imprimimos o conjunto de habilidades como SQL, Python, Testes e Negócios.

- Declare a variável expertise, a partir da qual vamos extrairtract todos os nomes de especialização que o funcionário possui
- Use a função padrão dom chamada “getElementsByTagName”
- Isso obterá todos os elementos chamados habilidade
- Declare um loop para cada uma das tags de habilidade.
- Execute o código - Ele fornecerá uma lista de quatro habilidades.
Como escrever um nó XML
Podemos criar um novo atributo usando a função “createElement” e então anexar esse novo atributo ou tag às tags XML existentes. Adicionamos uma nova tag “BigData” em nosso arquivo XML.
- Você precisa escrever um código para adicionar o novo atributo (BigData) à tag XML existente.
- Em seguida, você precisa imprimir a tag XML com o novo atributo anexado à tag XML existente.

- Para adicionar uma nova tag XML e inseri-la no documento, usamos o código “doc.createElement”.
- Este código criará uma nova etiqueta de habilidade para o nosso novo atributo “BigData”.
- Adicione esta etiqueta de habilidade ao primeiro elemento filho do documento (funcionário).
- Execute o código — a nova tag “BigData” aparecerá junto com a lista de especialidades.
Exemplo de analisador XML
Python 2 Exemplo
import xml.dom.minidom def main(): # use the parse() function to load and parse an XML file doc = xml.dom.minidom.parse("Myxml.xml"); # print out the document node and the name of the first child tag print doc.nodeName print doc.firstChild.tagName # get a list of XML tags from the document and print each one expertise = doc.getElementsByTagName("expertise") print "%d expertise:" % expertise.length for skill in expertise: print skill.getAttribute("name") #Write a new XML tag and add it into the document newexpertise = doc.createElement("expertise") newexpertise.setAttribute("name", "BigData") doc.firstChild.appendChild(newexpertise) print " " expertise = doc.getElementsByTagName("expertise") print "%d expertise:" % expertise.length for skill in expertise: print skill.getAttribute("name") if name == "__main__": main();
Python 3 Exemplo
import xml.dom.minidom def main(): # use the parse() function to load and parse an XML file doc = xml.dom.minidom.parse("Myxml.xml"); # print out the document node and the name of the first child tag print (doc.nodeName) print (doc.firstChild.tagName) # get a list of XML tags from the document and print each one expertise = doc.getElementsByTagName("expertise") print ("%d expertise:" % expertise.length) for skill in expertise: print (skill.getAttribute("name")) # Write a new XML tag and add it into the document newexpertise = doc.createElement("expertise") newexpertise.setAttribute("name", "BigData") doc.firstChild.appendChild(newexpertise) print (" ") expertise = doc.getElementsByTagName("expertise") print ("%d expertise:" % expertise.length) for skill in expertise: print (skill.getAttribute("name")) if __name__ == "__main__": main();
Como analisar XML usando ElementTree
ElementTree é uma API para manipulação de XML. ElementTree é uma maneira fácil de processar arquivos XML.
Estamos usando o seguinte documento XML como dados de amostra:
<data> <items> <item name="expertise1">SQL</item> <item name="expertise2">Python</item> </items> </data>
Lendo XML usando ElementTree:
Primeiro, precisamos importar o módulo xml.etree.ElementTree.
import xml.etree.ElementTree as ET
Agora vamos obter o elemento raiz:
root = tree.getroot()
Segue abaixo o código completo para leitura dos dados XML acima:
import xml.etree.ElementTree as ET tree = ET.parse('items.xml') root = tree.getroot() # all items data print('Expertise Data:') for elem in root: for subelem in elem: print(subelem.text)
Saída:
Expertise Data: SQL Python