Tokenizacja NLTK: Tokenizator słów i zdań z przykładem
⚡ Inteligentne podsumowanie
NLTK Tokenize dzieli duży tekst na mniejsze jednostki zwane tokenami, co stanowi fundamentalny krok w przetwarzaniu języka naturalnego. Zestaw narzędzi zawiera funkcję word_tokenize do dzielenia zdań na słowa oraz sent_tokenize do dzielenia tekstu na pojedyncze zdania.

Co to jest tokenizacja?
tokenizacja to proces, w wyniku którego duża ilość tekstu jest dzielona na mniejsze części zwane tokenami. Te żetony są bardzo przydatne do znajdowania wzorców i są uważane za podstawowy krok w stemplowaniu i lematyzacji. Tokenizacja pomaga również zastąpić wrażliwe elementy danych elementami danych niewrażliwych.
Przetwarzanie języka naturalnego jest wykorzystywane do tworzenia aplikacji, takich jak klasyfikacja tekstu, inteligentny chatbot, analiza sentymentalna, tłumaczenie językowe itp. Aby osiągnąć powyższy cel, konieczne staje się zrozumienie schematu w tekście.
Na razie nie przejmuj się stemmingiem i lematyzacją, ale traktuj je jako kroki oczyszczania danych tekstowych za pomocą NLP (przetwarzania języka naturalnego). Omówimy stemming i lematyzację później w tym samouczku. Zadania takie jak Klasyfikacja tekstu lub filtrowanie spamu korzysta z NLP wraz z bibliotekami głębokiego uczenia się, takimi jak Keras i Tensorflow.
Zestaw narzędzi języka naturalnego zawiera bardzo ważny moduł NLTK tokenizować zdania, które dodatkowo składają się z podmodułów
- tokenizacja słów
- tokenizować zdanie
Tokenizacja słów
Używamy metody słowo_tokenize() podzielić zdanie na słowa. Dane wyjściowe tokenizacji słów można przekonwertować na ramkę danych w celu lepszego zrozumienia tekstu w aplikacjach do uczenia maszynowego. Może być również dostarczony jako dane wejściowe do dalszych etapów czyszczenia tekstu, takich jak usuwanie znaków interpunkcyjnych, usuwanie znaków numerycznych lub stemplowanie. Modele uczenia maszynowego wymagają danych liczbowych, aby można je było trenować i przewidywać. Tokenizacja słów staje się kluczową częścią konwersji tekstu (stringu) na dane numeryczne. Proszę przeczytać o Worek słów lub CountVectorizer. Aby lepiej zrozumieć teorię, zapoznaj się z poniższym przykładem tokenizacji słów NLTK.
from nltk.tokenize import word_tokenize text = "God is Great! I won a lottery." print(word_tokenize(text)) Output: ['God', 'is', 'Great', '!', 'I', 'won', 'a', 'lottery', '.']
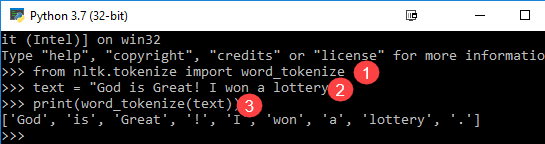
Code Wyjaśnienie
- Moduł word_tokenize jest importowany z biblioteki NLTK.
- Zmienna „tekst” jest inicjowana dwoma zdaniami.
- Zmienna tekstowa jest przekazywana do modułu word_tokenize i drukuje wynik. Moduł ten rozdziela każde słowo znakami interpunkcyjnymi, które można zobaczyć w wynikach.
Tokenizacja zdań
Dostępny dla powyższych podmoduł to send_tokenize. Oczywistym pytaniem w twojej głowie byłoby: dlaczego potrzebna jest tokenizacja zdań, skoro mamy możliwość tokenizacji słów. Wyobraź sobie, że musisz policzyć średnią liczbę słów w zdaniu. Jak to obliczysz? Aby wykonać takie zadanie, do obliczenia współczynnika potrzebny jest zarówno tokenizator zdań NLTK, jak i tokenizator słów NLTK. Takie dane wyjściowe stanowią ważną funkcję uczenia maszynowego, ponieważ odpowiedź będzie liczbowa.
Sprawdź poniższy przykład tokenizatora NLTK, aby dowiedzieć się, czym różni się tokenizacja zdań od tokenizacji słów.
from nltk.tokenize import sent_tokenize text = "God is Great! I won a lottery." print(sent_tokenize(text)) Output: ['God is Great!', 'I won a lottery ']
Praca IT i kariera 12 słowa i dwa zdania dla tego samego wejścia.
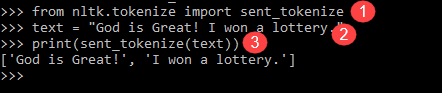
Wyjaśnienie programu
- W linii podobnej do poprzedniego programu zaimportowano moduł send_tokenize.
- Przyjęliśmy to samo zdanie. Dalszy tokenizator zdań w module NLTK przeanalizował te zdania i pokazał wynik. Oczywiste jest, że ta funkcja łamie każde zdanie.
Powyższy tokenizator słów Python przykładami są dobre kamienie ustawień, które pozwalają zrozumieć mechanikę tokenizacji słów i zdań.