50 pytań i odpowiedzi do rozmowy kwalifikacyjnej SQL na rok 2026
Pytania do rozmowy kwalifikacyjnej SQL dla nowicjuszy
1. Co to jest DBMS?
System zarządzania bazami danych (DBMS) to program sterujący tworzeniem, konserwacją i użytkowaniem bazy danych. DBMS można nazwać menedżerem plików, który zarządza danymi w bazie danych, zamiast zapisywać je w systemach plików.
👉 Bezpłatne pobieranie pliku PDF: pytania i odpowiedzi dotyczące wywiadu SQL >>
2. Co to jest RDBMS?
RDBMS to skrót od Relational Database Management System (system zarządzania relacyjną bazą danych). RDBMS przechowuje dane w zbiorze tabel, które są powiązane wspólnymi polami między kolumnami tabeli. Zapewnia również operatory relacyjne do manipulowania danymi przechowywanymi w tabelach.
Przykład: serwer SQL.
3. Co to jest SQL?
SQL oznacza Structured Query Language i służy do komunikacji z bazą danych. Jest to standardowy język używany do wykonywania zadań, takich jak pobieranie, aktualizacja, wstawianie i usuwanie danych z bazy danych.
Standardowe Polecenia SQL są Wybierz.
4. Co to jest baza danych?
Baza danych to nic innego jak zorganizowana forma danych umożliwiająca łatwy dostęp, przechowywanie, wyszukiwanie i zarządzanie danymi. Nazywa się to również ustrukturyzowaną formą danych, do której można uzyskać dostęp na wiele sposobów.
Przykład: baza danych zarządzania szkołą, baza danych zarządzania bankiem.
5. Czym są tabele i pola?
Tabela to zbiór danych zorganizowanych w model składający się z kolumn i wierszy. Kolumny można podzielić na pionowe, a wiersze na poziome. Tabela ma określoną liczbę kolumn zwanych polami, ale może mieć dowolną liczbę wierszy, co nazywa się rekordem.
Przykład:.
Tabela: Pracownik.
Pole: Identyfikator Emp, Imię Emp, Data urodzenia.
Dane: 201456, Dawid, 11.
6. Co to jest klucz podstawowy?
A klucz podstawowy jest kombinacją pól, które jednoznacznie określają wiersz. Jest to specjalny rodzaj unikalnego klucza, który ma ukryte ograniczenie NOT NULL. Oznacza to, że wartości klucza podstawowego nie mogą mieć wartości NULL.
7. Co to jest unikalny klucz?
Ograniczenie klucza Unique jednoznacznie identyfikuje każdy rekord w bazie danych. Zapewnia to unikalność kolumny lub zestawu kolumn.
Ograniczenie klucza podstawowego ma zdefiniowane automatyczne ograniczenie przez unikalność. Ale nie w przypadku Unique Key.
W tabeli może być zdefiniowanych wiele ograniczeń przez unikalność, ale tylko jedno ograniczenie klucza podstawowego w tabeli.
8. Co to jest klucz obcy?
Klucz obcy to jedna tabela, która może być powiązana z kluczem podstawowym innej tabeli. Należy utworzyć relację między dwiema tabelami, odwołując się do klucza obcego za pomocą klucza podstawowego innej tabeli.
9. Co to jest sprzężenie?
To słowo kluczowe używane do tworzenia zapytań o dane z większej liczby tabel na podstawie relacji między polami tabel. Klucze odgrywają główną rolę, gdy używane są JOIN.
10. Jakie są rodzaje złączeń i wyjaśnij każdy z nich?
Tam są różne typy złączeń których można użyć do pobrania danych i zależy to od relacji między tabelami.
- Połączenie wewnętrzne.
Łączenie wewnętrzne zwraca wiersze, jeśli między tabelami występuje co najmniej jeden zgodny wiersz.
- Prawe dołączenie.
Łączenie prawostronne zwraca wiersze, które są wspólne dla tabel i wszystkich wierszy tabeli po prawej stronie. Po prostu zwraca wszystkie wiersze z tabeli po prawej stronie, nawet jeśli w tabeli po lewej stronie nie ma żadnych dopasowań.
- Lewe dołączenie.
Połączenie lewe powoduje powrót wierszy, które są wspólne dla tabel i wszystkich wierszy tabeli po lewej stronie. Po prostu zwraca wszystkie wiersze z tabeli po lewej stronie, nawet jeśli nie ma żadnych dopasowań w tabeli po prawej stronie.
- Pełne dołączenie.
Pełne łączenie zwraca wiersze, jeśli w którejkolwiek tabeli znajdują się pasujące wiersze. Oznacza to, że zwraca wszystkie wiersze z tabeli po lewej stronie i wszystkie wiersze z tabeli po prawej stronie.
Pytania do rozmowy kwalifikacyjnej SQL dotyczące 3-letniego doświadczenia
11. Co to jest normalizacja?
Normalizacja to proces minimalizacji redundancji i zależności poprzez organizowanie pól i tabel bazy danych. Głównym celem normalizacji jest dodawanie, usuwanie lub modyfikowanie pól, które można utworzyć w pojedynczej tabeli.
12. Czym jest denormalizacja?
DeNormalizacja to technika używana do uzyskiwania dostępu do danych z wyższych i niższych normalnych form bazy danych. Jest to także proces wprowadzania redundancji do tabeli poprzez włączenie danych z powiązanych tabel.
13. Jakie są różne normalizacje?
Normalizacja bazy danych można łatwo zrozumieć na podstawie studium przypadku. Formy normalne można podzielić na 6 form, które wyjaśniono poniżej.
.png)
- Pierwsza postać normalna (1NF):.
To powinno usunąć wszystkie zduplikowane kolumny z tabeli. Tworzenie tabel dla powiązanych danych i identyfikacja unikalnych kolumn.
- Druga postać normalna (2NF):.
Spełnia wszystkie wymagania pierwszej postaci normalnej. Umieszczanie podzbiorów danych w oddzielnych tabelach i Tworzenie relacji pomiędzy tabelami za pomocą kluczy podstawowych.
- Trzecia postać normalna (3NF):.
Powinno to spełniać wszystkie wymagania 2NF. Usuwanie kolumn, które nie są zależne od ograniczeń klucza podstawowego.
- Czwarta postać normalna (4NF):.
Jeśli żadna instancja tabeli bazy danych nie zawiera dwóch lub więcej niezależnych i wielowartościowych danych opisujących daną jednostkę, to znajduje się ona w 4th Normalna forma.
- Piąta postać normalna (5NF):.
Tabela jest w piątej postaci normalnej tylko wtedy, gdy jest w 5NF i nie można jej rozłożyć na dowolną liczbę mniejszych tabel bez utraty danych.
- Szósta postać normalna (6NF):.
6. Forma Normalna nie jest ustandaryzowana, jednak od pewnego czasu jest dyskutowana przez ekspertów ds. baz danych. Mamy nadzieję, że w najbliższej przyszłości będziemy mieli jasną i ustandaryzowaną definicję szóstej formy normalnej…
14. Co to jest widok?
Widok to wirtualna tabela, która składa się z podzbioru danych zawartych w tabeli. Widoki nie są praktycznie obecne, a przechowywanie zajmuje mniej miejsca. Widok może zawierać dane z jednej lub większej liczby tabel połączonych, w zależności od relacji.
15. Co to jest indeks?
Indeks to metoda dostrajania wydajności umożliwiająca szybsze pobieranie rekordów z tabeli. Indeks tworzy wpis dla każdej wartości i szybsze będzie pobieranie danych.
16. Jakie są różne typy indeksów?
Istnieją trzy typy indeksów -.
- Pojedynczy indeks.
To indeksowanie nie pozwala, aby pole miało zduplikowane wartości, jeśli kolumna jest indeksowana unikalnie. Unikalny indeks może zostać zastosowany automatycznie po zdefiniowaniu klucza podstawowego.
- Clusterwyd. Indeks.
Ten typ indeksu zmienia kolejność fizyczną tabeli i wyszukiwania na podstawie wartości klucza. Każda tabela może mieć tylko jeden indeks klastrowy.
- NieClusterwyd. Indeks.
NieClustered Index nie zmienia fizycznej kolejności tabeli i utrzymuje logiczną kolejność danych. Każda tabela może mieć 999 nieklastrowanych indeksów.
17. Co to jest kursor?
Kursor bazy danych to element sterujący umożliwiający poruszanie się po wierszach lub rekordach w tabeli. Można to postrzegać jako wskaźnik do jednego wiersza w zestawie wierszy. Kursor jest bardzo przydatny do poruszania się, np. wyszukiwania, dodawania i usuwania rekordów z bazy danych.
18. Czym jest związek i czym jest?
Relację bazy danych definiuje się jako połączenie między tabelami w bazie danych. Istnieją różne relacje oparte na danych i są one następujące:
- Relacja jeden do jednego.
- Relacja jeden do wielu.
- Relacja wiele do jednego.
- Relacja autoreferencyjna.
19. Co to jest zapytanie?
Zapytanie DB to kod napisany w celu uzyskania informacji z bazy danych. Zapytanie można zaprojektować w taki sposób, aby było zgodne z naszymi oczekiwaniami dotyczącymi zestawu wyników. Po prostu pytanie do bazy danych.
20. Co to jest podzapytanie?
Podzapytanie to zapytanie zawarte w innym zapytaniu. Zapytanie zewnętrzne nazywa się zapytaniem głównym, a zapytanie wewnętrzne nazywa się podzapytaniem. Podzapytanie jest zawsze wykonywane jako pierwsze, a wynik podzapytania przekazywany jest do zapytania głównego.
Przyjrzyjmy się składni podzapytania –
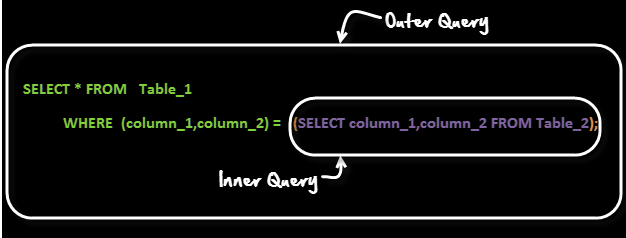
Częstą skargą klientów w Bibliotece wideo MyFlix jest mała liczba tytułów filmów. Zarząd chce kupować filmy w kategorii, która ma najmniejszą liczbę tytułów.
Możesz użyć zapytania typu
SELECT category_name FROM categories WHERE category_id =( SELECT MIN(category_id) from movies);
Pytania do rozmowy kwalifikacyjnej SQL dotyczące 5-letniego doświadczenia
21. Jakie są rodzaje podzapytań?
Istnieją dwa typy podzapytań – skorelowane i nieskorelowane.
Podzapytanie skorelowane nie może być traktowane jako zapytanie niezależne, ale może odnosić się do kolumny w tabeli wymienionej na liście Z zapytania głównego.
Nieskorelowane zapytanie podrzędne można uznać za zapytanie niezależne, a wyniki podzapytania są zastępowane w zapytaniu głównym.
22. Co to jest procedura składowana?
Procedura składowana to funkcja składająca się z wielu instrukcji SQL umożliwiających dostęp do systemu bazy danych. Kilka instrukcji SQL jest skonsolidowanych w procedurę składowaną i wykonuje je kiedykolwiek i gdziekolwiek jest to wymagane.
23. Co to jest wyzwalacz?
Wyzwalacz DB to kod lub programy, które są automatycznie wykonywane w odpowiedzi na jakieś zdarzenie w tabeli lub widoku w bazie danych. Głównie wyzwalacz pomaga zachować integralność bazy danych.
Przykład: Po dodaniu nowego ucznia do bazy danych uczniów należy utworzyć nowe rekordy w powiązanych tabelach, takich jak tabele egzaminów, wyników i frekwencji.
24. Jaka jest różnica pomiędzy poleceniami DELETE i TRUNCATE?
Polecenie DELETE służy do usuwania wierszy z tabeli, a klauzula WHERE pozwala na warunkowe ustawienie parametrów. Zatwierdzenie i wycofanie można wykonać po instrukcji usuwania.
TRUNCATE usuwa wszystkie wiersze z tabeli. Operacji obcinania nie można cofnąć.
25. Czym są zmienne lokalne i globalne oraz czym się różnią?
Zmienne lokalne to zmienne, których można użyć lub które mogą istnieć wewnątrz funkcji. Nie są one znane innym funkcjom i nie można do nich odwoływać się ani ich używać. Zmienne można tworzyć przy każdym wywołaniu tej funkcji.
Zmienne globalne to zmienne, których można używać lub które mogą istnieć w całym programie. Ta sama zmienna zadeklarowana w global nie może być używana w funkcjach. Nie można utworzyć zmiennych globalnych przy każdym wywołaniu tej funkcji.
26. Co to jest ograniczenie?
Ograniczenia można użyć do określenia limitu typu danych tabeli. Ograniczenie można określić podczas tworzenia lub modyfikowania instrukcji tabeli. Przykładowe ograniczenia to.
- NIE JEST ZEREM.
- CZEK.
- DOMYŚLNA.
- JEDYNY W SWOIM RODZAJU.
- GŁÓWNY KLUCZ.
- KLUCZ OBCY.
27. Czym są dane Integrity?
Dane Integrity definiuje dokładność i spójność danych przechowywanych w bazie danych. Może również definiować ograniczenia integralności, aby egzekwować reguły biznesowe dotyczące danych, gdy są one wprowadzane do aplikacji lub bazy danych.
28. Co to jest automatyczny przyrost?
Słowo kluczowe autoinkrementacji umożliwia użytkownikowi utworzenie unikalnego numeru, który będzie generowany po wstawieniu nowego rekordu do tabeli. Można użyć słowa kluczowego AUTO INCREMENT Oracle i słowo kluczowe IDENTITY mogą być używane w SQL SERVER.
Najczęściej tego słowa kluczowego można używać za każdym razem, gdy używany jest KLUCZ PODSTAWOWY.
29. Jaka jest różnica między Cluster i nieCluster Indeks?
Clusterindeks ed jest używany do łatwego pobierania danych z bazy danych poprzez zmianę sposobu przechowywania rekordów. Baza danych sortuje wiersze według kolumny, która jest ustawiona jako indeks klastrowany.
Indeks nieklastrowany nie zmienia sposobu, w jaki był przechowywany, ale tworzy całkowicie oddzielny obiekt w tabeli. Wskazuje on z powrotem na oryginalne wiersze tabeli po przeszukaniu.
30. Czym jest hurtownia danych?
Hurtownia danych to centralne repozytorium danych pochodzących z wielu źródeł informacji. Dane te są konsolidowane, przekształcane i udostępniane do eksploracji i przetwarzania online. Dane hurtowni obejmują podzbiór danych zwany Data Marts.
31. Co to jest samodzielne łączenie?
Samołączenie jest ustawione jako zapytanie używane do porównywania z samym sobą. Służy do porównywania wartości w kolumnie z innymi wartościami w tej samej kolumnie w tej samej tabeli. ALIAS ES można zastosować do tego samego porównania tabel.
32. Co to jest łączenie krzyżowe?
Sprzężenie krzyżowe definiuje się jako iloczyn kartezjański, w którym liczba wierszy w pierwszej tabeli jest pomnożona przez liczbę wierszy w drugiej tabeli. Jeśli załóżmy, że w łączeniu krzyżowym użyta zostanie klauzula WHERE, wówczas zapytanie będzie działać jak INNER JOIN.
33. Co to są funkcje zdefiniowane przez użytkownika?
Funkcje zdefiniowane przez użytkownika to funkcje napisane tak, aby używać tej logiki, gdy jest to wymagane. Nie jest konieczne pisanie tej samej logiki kilka razy. Zamiast tego funkcję można wywołać lub wykonać w razie potrzeby.
34. Jakie są rodzaje funkcji zdefiniowanych przez użytkownika?
Istnieją trzy typy funkcji zdefiniowanych przez użytkownika.
- Funkcje skalarne.
- Funkcje wyceniane w tabeli wbudowanej.
- Funkcje wartościujące wiele instrukcji.
Skalarna jednostka zwracana, wariant definiuje klauzulę return. Pozostałe dwa typy zwracają tabelę jako zwrot.
35. Co to jest zestawienie?
Sortowanie definiuje się jako zbiór reguł określających sposób sortowania i porównywania danych znakowych. Można to wykorzystać do porównania znaków A i innych języków, a także zależy to od szerokości znaków.
Do porównania tych danych znakowych można użyć wartości ASCII.
36. Jakie są różne rodzaje czułości sortowania?
Poniżej przedstawiono różne typy wrażliwości zestawienia.
- Rozróżnianie wielkości liter – A i a oraz B i b.
- Czułość akcentu.
- Czułość Kana – japońskie znaki Kana.
- Czułość szerokości – znaki jednobajtowe i dwubajtowe.
37. Zalety i wady procedury składowanej?
Procedurę składowaną można wykorzystać jako programowanie modułowe – oznacza to jednorazowe utworzenie, zapisanie i wywołanie kilka razy, gdy zajdzie taka potrzeba. Obsługuje to szybsze wykonywanie zamiast wykonywania wielu zapytań. Zmniejsza to ruch sieciowy i zapewnia większe bezpieczeństwo danych.
Wadą jest to, że można go wykonać tylko w bazie danych i zużywa więcej pamięci na serwerze bazy danych.
38. Co to jest przetwarzanie transakcji online (OLTP)?
Przetwarzanie transakcji online (OLTP) zarządza aplikacjami transakcyjnymi, których można używać do wprowadzania, wyszukiwania i przetwarzania danych. OLTP sprawia, że zarządzanie danymi jest proste i wydajne. W przeciwieństwie do systemów OLAP celem systemów OLTP jest obsługa transakcji w czasie rzeczywistym.
Przykład – codzienne transakcje bankowe.
39. Co to jest KLAUZULA?
Klauzula SQL ma na celu ograniczenie zestawu wyników poprzez podanie warunku do zapytania. Zwykle filtruje to niektóre wiersze z całego zestawu rekordów.
Przykład – Zapytanie zawierające warunek WHERE
Zapytanie zawierające warunek HAVING.
40. Co to jest rekursywna procedura składowana?
Procedura składowana, która wywołuje się sama, dopóki nie osiągnie pewnego warunku brzegowego. Ta funkcja lub procedura rekurencyjna pomaga programistom używać tego samego zestawu kodu dowolną liczbę razy.
Pytania do rozmowy kwalifikacyjnej SQL dotyczące ponad 10-letniego doświadczenia
41. Co to są polecenia Union, minus i Interact?
Operator UNION służy do łączenia wyników dwóch tabel i eliminowania zduplikowanych wierszy z tabel.
Operator MINUS jest używany do zwracania wierszy z pierwszego zapytania, ale nie z drugiego zapytania. Pasujące rekordy pierwszego i drugiego zapytania oraz inne wiersze z pierwszego zapytania zostaną wyświetlone jako zestaw wyników.
Operator INTERSECT służy do zwracania wierszy zwróconych przez oba zapytania.
42. Co to jest polecenie ALIAS?
Nazwę ALIAS można nadać tabeli lub kolumnie. Do tego pseudonimu można się odwoływać klauzula GDZIE do identyfikacji tabeli lub kolumny.
Przykład-.
Select st.StudentID, Ex.Result from student st, Exam as Ex where st.studentID = Ex. StudentID
Tutaj st odnosi się do nazwy aliasu tabeli ucznia, a Ex odnosi się do nazwy aliasu tabeli egzaminu.
43. Jaka jest różnica pomiędzy instrukcjami TRUNCATE i DROP?
TRUNCATE usuwa wszystkie wiersze z tabeli i nie można jej wycofać. Polecenie DROP usuwa tabelę z bazy danych i operacji nie można wycofać.
44. Co to są funkcje agregujące i skalarne?
Funkcje agregujące służą do obliczania obliczeń matematycznych i zwracania pojedynczych wartości. Można to obliczyć na podstawie kolumn w tabeli. Funkcje skalarne zwracają pojedynczą wartość na podstawie wartości wejściowej.
Przykład -.
Agregat – max(), liczba – Obliczane w odniesieniu do liczb.
Skalarny – UCASE(), TERAZ() – Obliczane w odniesieniu do ciągów znaków.
45. Jak utworzyć pustą tabelę z istniejącej tabeli?
Przykładem będzie -.
Select * into studentcopy from student where 1=2
Tutaj kopiujemy tabelę ucznia do innej tabeli o tej samej strukturze, bez kopiowanych wierszy.
46. Jak pobrać wspólne rekordy z dwóch tabel?
Wspólny zestaw wyników rekordów można osiągnąć poprzez -.
Select studentID from student INTERSECT Select StudentID from Exam
47. Jak pobrać alternatywne rekordy z tabeli?
Rekordy można pobierać zarówno dla nieparzystych, jak i parzystych numerów wierszy.
Aby wyświetlić liczby parzyste-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=0
Aby wyświetlić liczby nieparzyste-.
Select studentId from (Select rowno, studentId from student) where mod(rowno,2)=1
from (Wybierz rowno, studentId od studenta) gdzie mod(rowno,2)=1.[/sql]
48. Jak wybrać unikalne rekordy z tabeli?
Wybierz unikalne rekordy z tabeli, używając słowa kluczowego DISTINCT.
Select DISTINCT StudentID, StudentName from Student.
49. Jakie polecenie służy do pobrania pierwszych 5 znaków ciągu?
Istnieje wiele sposobów pobrania pierwszych 5 znaków ciągu -.
Select SUBSTRING(StudentName,1,5) as studentname from student
Select LEFT(Studentname,5) as studentname from student
50. Którego operatora używa się w zapytaniu o dopasowanie wzorca?
Operator LIKE służy do dopasowywania wzorców i może być używany jako -.
- % – dopasowuje zero lub więcej znaków.
- _(Podkreślenie) – Dopasowanie dokładnie jednego znaku.
Przykład -.
Select * from Student where studentname like 'a%'
Select * from Student where studentname like 'ami_'
Te pytania podczas rozmowy kwalifikacyjnej pomogą również w Twoim życiu (ustach)