ETL (np.tracProces t, Transform i Load w magazynie danych
Inteligentne podsumowanie
ETL (np.tracProces „t, Transform i Load” w hurtowni danych opisuje systematyczny przepływ danych z wielu heterogenicznych źródeł do scentralizowanego repozytorium. Zapewnia spójność, dokładność i gotowość danych do analizy poprzez ustrukturyzowane procesy.traccja, transformacja i zoptymalizowane mechanizmy ładowania.

Co to jest ETL?
ETL jest procesem, który byłtracPobiera dane z różnych systemów źródłowych, następnie transformuje je (np. stosując obliczenia, konkatenacje itp.), a na koniec ładuje do systemu hurtowni danych. Pełna nazwa ETL to Extract, Transform i Load.
Można by pomyśleć, że stworzenie magazynu danych to po prostu np.tracPobieranie danych z wielu źródeł i ładowanie ich do bazy danych. W rzeczywistości wymaga to jednak złożonego procesu ETL. Proces ETL wymaga aktywnego zaangażowania różnych interesariuszy, w tym programistów, analityków, testerów i kadry kierowniczej wyższego szczebla, i jest technicznie wymagający.
Aby utrzymać swoją wartość jako narzędzie dla decydentów, system hurtowni danych musi ewoluować wraz ze zmianami biznesowymi. ETL to cykliczna (codzienna, tygodniowa lub miesięczna) czynność systemu hurtowni danych, która musi być zwinna, zautomatyzowana i dobrze udokumentowana.
Dlaczego potrzebujesz ETL?
Powodów wdrożenia ETL w organizacji jest wiele:
- Pomaga firmom analizować dane biznesowe w celu podejmowania kluczowych decyzji biznesowych.
- Bazy danych transakcyjnych nie potrafią udzielić odpowiedzi na złożone pytania biznesowe, na które można odpowiedzieć za pomocą przykładu ETL.
- Magazyn danych zapewnia wspólne repozytorium danych
- ETL zapewnia metodę przenoszenia danych z różnych źródeł do hurtowni danych.
- Gdy źródła danych ulegną zmianie, magazyn danych zostanie automatycznie zaktualizowany.
- Dobrze zaprojektowany i udokumentowany system ETL jest niemalże niezbędny do sukcesu projektu magazynu danych.
- Umożliwia weryfikację transformacji danych, agregacji i reguł obliczeniowych.
- Proces ETL umożliwia porównanie danych próbnych między systemem źródłowym i docelowym.
- Proces ETL umożliwia wykonywanie złożonych transformacji i wymaga dodatkowego obszaru do przechowywania danych.
- ETL pomaga migrować dane do hurtowni danych, konwertując różne formaty i typy danych do jednego spójnego systemu.
- ETL to predefiniowany proces uzyskiwania dostępu do danych źródłowych i manipulowania nimi w docelowej bazie danych.
- ETL w magazynie danych zapewnia przedsiębiorstwu głęboki kontekst historyczny.
- Pomaga zwiększyć produktywność, ponieważ kodyfikuje i ponownie wykorzystuje informacje bez konieczności posiadania umiejętności technicznych.
Mając jasne zrozumienie wartości ETL, możemy przejść do trzyetapowego procesu, który sprawia, że to wszystko działa.
Proces ETL w magazynach danych
ETL to proces składający się z trzech etapów
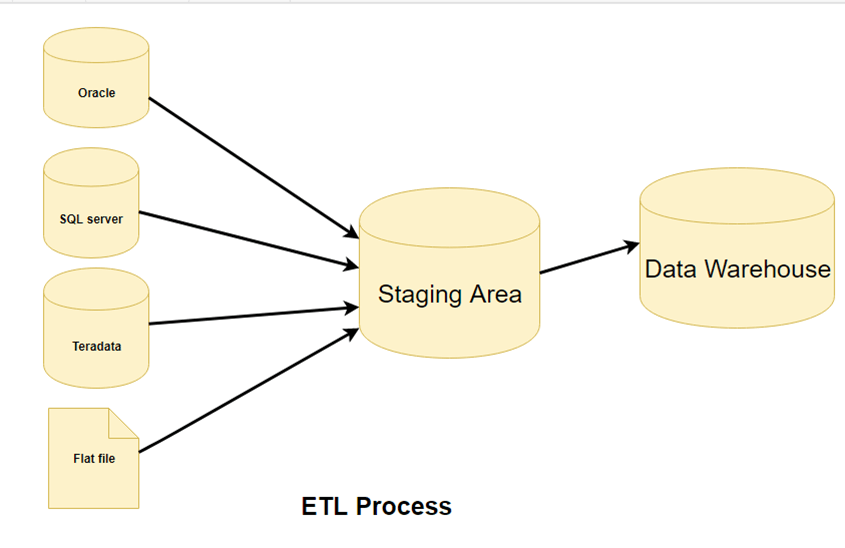
Krok 1) Przykładtraccja
Na tym etapie architektury ETL dane sątracPrzenoszone z systemu źródłowego do obszaru przejściowego. Ewentualne transformacje są przeprowadzane w obszarze przejściowym, aby nie dopuścić do spadku wydajności systemu źródłowego. Ponadto, jeśli uszkodzone dane zostaną skopiowane bezpośrednio ze źródła do bazy danych magazynu danych, wycofanie ich będzie trudne. Obszar przejściowy daje możliwość weryfikacji.tracdane przed umieszczeniem ich w magazynie danych.
Magazyn danych musi integrować systemy, które mają różne systemy DBMS, sprzęt, OperaSystemy komunikacyjne i protokoły komunikacyjne. Źródła mogą obejmować starsze aplikacje, takie jak komputery mainframe, aplikacje niestandardowe, urządzenia punktu kontaktowego, takie jak bankomaty, przełączniki połączeń, pliki tekstowe, arkusze kalkulacyjne, systemy ERP, dane od dostawców i partnerów, między innymi.
Dlatego przed wyeksportowaniem danych potrzebna jest logiczna mapa danych.tracted i załadowane fizycznie. Ta mapa danych opisuje relację między danymi źródłowymi a danymi docelowymi.
Trzy dane Extracmetody cji:
- Pełny Extraccja
- Częściowy Extraccja- bez powiadomienia o aktualizacji.
- Częściowy Extraccja – z powiadomieniem o aktualizacji
Niezależnie od użytej metody, np.tracNie powinno to wpływać na wydajność i czas reakcji systemów źródłowych. Systemy te są działającymi bazami danych. Każde spowolnienie lub zablokowanie może wpłynąć na wyniki finansowe firmy.
Niektóre walidacje przeprowadzane są podczas Extraccja:
- Uzgodnij zapisy z danymi źródłowymi
- Upewnij się, że nie załadowano żadnego spamu/niechcianych danych
- Kontrola typu danych
- Usuń wszystkie typy zduplikowanych/fragmentowanych danych
- Sprawdź czy wszystkie klucze są na swoim miejscu.
Krok 2) Transformacja
Dane extracDane z serwera źródłowego są surowe i nie nadają się do użytku w oryginalnej formie. Dlatego należy je oczyścić, zmapować i przekształcić. W rzeczywistości jest to kluczowy krok, w którym proces ETL dodaje wartość i modyfikuje dane, umożliwiając generowanie wnikliwych raportów BI.
Jest to jedna z ważnych koncepcji ETL, w której stosuje się zbiór funkcji na przykładtracdane ted. Dane, które nie wymagają żadnej transformacji, nazywane są bezpośredni ruch or dane przepustowe.
Na etapie transformacji można wykonywać niestandardowe operacje na danych. Na przykład, jeśli użytkownik chce uzyskać sumę przychodów ze sprzedaży, której nie ma w bazie danych. Lub jeśli imię i nazwisko w tabeli znajdują się w różnych kolumnach, możliwe jest ich połączenie przed załadowaniem.

Poniżej znajdują się dane Integrity Problemy:
- Różne pisownie imienia tej samej osoby, np. Jon, John, itd.
- Istnieje wiele sposobów na oznaczenie nazwy firmy, takich jak: Google, Google Inc
- Stosowanie różnych nazw, takich jak Cleaveland i Cleveland.
- Może się zdarzyć, że różne aplikacje wygenerują dla tego samego klienta różne numery kont.
- W niektórych przypadkach pliki z wymaganymi danymi pozostają puste
- Nieprawidłowy produkt pobrany w punkcie sprzedaży, ponieważ ręczne wprowadzenie danych może prowadzić do błędów.
Na tym etapie przeprowadzana jest weryfikacja
- Filtrowanie — wybierz tylko niektóre kolumny do załadowania
- Używanie reguł i tabel przeglądowych do standaryzacji danych
- Konwersja zestawu znaków i obsługa kodowania
- Konwersja jednostek miary, np. konwersja daty i godziny, konwersja walut, konwersja liczbowa itp.
- Kontrola poprawności progu danych. Na przykład wiek nie może być dłuższy niż dwie cyfry.
- Walidacja przepływu danych z obszaru tymczasowego do tabel pośrednich.
- Pola wymagane nie powinny pozostać puste.
- Czyszczenie (np. mapy)ping NULL na 0 lub płeć Męska na „M” i Żeńska na „K” itd.)
- Podziel kolumnę na kilka kolumn i połącz kilka kolumn w jedną.
- Transpozycja wierszy i kolumn,
- Użyj wyszukiwań, aby scalić dane
- Korzystanie z dowolnej złożonej walidacji danych (np. jeśli pierwsze dwie kolumny w wierszu są puste, to wiersz jest automatycznie odrzucany z przetwarzania)
Krok 3) Ładowanie
Załadowanie danych do docelowej bazy danych magazynu danych to ostatni etap procesu ETL. W typowej hurtowni danych, w stosunkowo krótkim czasie (kilka nocy) konieczne jest załadowanie ogromnej ilości danych. Dlatego proces ładowania powinien być zoptymalizowany pod kątem wydajności.
W przypadku awarii obciążenia należy skonfigurować mechanizmy odzyskiwania, aby umożliwić ponowne uruchomienie od punktu awarii bez utraty integralności danych. Administratorzy magazynów danych muszą monitorować, wznawiać i anulować obciążenia zgodnie z aktualną wydajnością serwera.
Rodzaje załadunku:
- Początkowe obciążenie — wypełnianie wszystkich tabel magazynu danych
- Obciążenie przyrostowe — wprowadzanie bieżących zmian w razie potrzeby okresowo.
- Pełne odświeżenie —kasowanie zawartości jednej lub więcej tabel i ponowne ładowanie świeżymi danymi.
Weryfikacja obciążenia
- Upewnij się, że kluczowych danych pola nie brakuje ani nie mają wartości null.
- Testuj widoki modelowania w oparciu o tabele docelowe.
- Sprawdź łączne wartości i obliczone miary.
- Sprawdzanie danych w tabeli wymiarów oraz tabeli historii.
- Sprawdź raporty BI w załadowanej tabeli faktów i wymiarów.
Przetwarzanie równoległe i przetwarzanie potokowe ETL
Pipelining ETL umożliwia np.tracaby nastąpiła cja, transformacja i ładowanie jednocześnie zamiast sekwencyjnie. Gdy tylko część danych zostanietracted, jest transformowany i ładowany, podczas gdy nowe dane extracakcja trwa. To przetwarzanie równoległe znacznie zwiększa wydajność, redukuje przestoje i maksymalizuje wykorzystanie zasobów systemowych.
To równoległe przetwarzanie jest niezbędne dla analityka w czasie rzeczywistym, integracja danych na dużą skalę i systemy ETL w chmurze. Poprzez nakładanie sięping zadania, przetwarzanie ETL metodą potokową zapewnia szybsze przenoszenie danych, większą wydajność i bardziej spójne dostarczanie danych dla nowoczesnych przedsiębiorstw.
W jaki sposób AI usprawnia nowoczesne procesy ETL?
Artificial Intelligence revolutJonizuje ETL, czyniąc potoki danych adaptacyjnymi, inteligentnymi i samooptymalizującymi się. Algorytmy sztucznej inteligencji (AI) mogą automatycznie mapować schematy, wykrywać anomalie i przewidywać reguły transformacji bez konieczności ręcznej konfiguracji. Dzięki temu przepływy pracy ETL bezproblemowo obsługują ewoluujące struktury danych, zachowując jednocześnie ich jakość.
Nowoczesne platformy ETL wspomagane sztuczną inteligencją wykorzystują technologie takie jak AutoML do automatycznej inżynierii cech i mapy schematów opartej na przetwarzaniu języka naturalnegoping Rozumie relacje semantyczne między polami oraz algorytmy wykrywania anomalii, które identyfikują problemy z jakością danych w czasie rzeczywistym. Te możliwości znacznie zmniejszają nakład pracy ręcznej tradycyjnie wymagany przy rozwoju i utrzymaniu procesów ETL.
Nauczanie maszynowe Usprawnia dostrajanie wydajności, zapewniając szybszą i dokładniejszą integrację danych. Dzięki wprowadzeniu automatyzacji i inteligencji predykcyjnej, ETL oparte na sztucznej inteligencji dostarcza analizy w czasie rzeczywistym i zwiększa wydajność w ekosystemach danych w chmurze i hybrydowych.
Aby wdrożyć omówione powyżej koncepcje, organizacje korzystają ze specjalistycznych narzędzi ETL. Oto kilka wiodących rozwiązań dostępnych na rynku.
Narzędzia ETL
Jest wiele Narzędzia ETL dostępne na rynku. Oto niektóre z najpopularniejszych:
1. Logika znaku:
MarkLogic to rozwiązanie do hurtowni danych, które ułatwia i przyspiesza integrację danych dzięki szeregowi funkcji korporacyjnych. Umożliwia ono wyszukiwanie różnych typów danych, takich jak dokumenty, relacje i metadane.
https://www.marklogic.com/product/getting-started/
2. Oracle:
Oracle to wiodąca w branży baza danych. Oferuje szeroką gamę rozwiązań hurtowni danych, zarówno lokalnych, jak i w chmurze. Pomaga optymalizować doświadczenia klientów poprzez zwiększenie efektywności operacyjnej.
https://www.oracle.com/index.html
3. Amazon CzerwonyShift:
Amazon Redshift to narzędzie do obsługi magazynu danych. To proste i niedrogie narzędzie do analizy wszystkich typów danych przy użyciu standardowych SQL i istniejących narzędzi BI. Umożliwia również uruchamianie złożonych zapytań na petabajtach ustrukturyzowanych danych.
https://aws.amazon.com/redshift/?nc2=h_m1
Oto pełna lista przydatnych Narzędzia magazynu danych.
Najlepsze praktyki dla procesu ETL
Poniżej przedstawiono najlepsze praktyki dotyczące etapów procesu ETL:
- Nigdy nie próbuj czyścić wszystkich danych:
Każda organizacja chciałaby mieć wszystkie dane czyste, ale większość z nich nie jest gotowa płacić za czekanie lub po prostu nie jest gotowa czekać. Czyszczenie całości zajęłoby po prostu zbyt dużo czasu, dlatego lepiej nie próbować czyścić wszystkich danych. - Zrównoważenie oczyszczania z priorytetami biznesowymi:
Należy unikać nadmiernego czyszczenia wszystkich danych, ale należy zadbać o oczyszczenie pól krytycznych i o dużym wpływie, aby zapewnić niezawodność. Skoncentruj działania czyszczące na elementach danych, które bezpośrednio wpływają na decyzje biznesowe i dokładność raportowania. - Określ koszt oczyszczenia danych:
Przed wyczyszczeniem wszystkich zanieczyszczonych danych ważne jest, aby określić koszt czyszczenia każdego zanieczyszczonego elementu danych. - Aby przyspieszyć przetwarzanie zapytań, należy mieć widoki pomocnicze i indeksy:
Aby zmniejszyć koszty przechowywania, przechowuj podsumowane dane na taśmach dyskowych. Ponadto wymagany jest kompromis między ilością przechowywanych danych a ich szczegółowym wykorzystaniem. Kompromis na poziomie szczegółowości danych w celu zmniejszenia kosztów przechowywania.