Scikit-Learn Tutorial: Hvordan installere og Scikit-Learn eksempler
⚡ Smart oppsummering
Scikit-learn er åpen kildekode Python bibliotek som dekker forprosessering, klassifisering, regresjon, klynging og modellvalg bak et enkelt konsistent estimatorgrensesnitt, som holder en komplett maskinlæringsarbeidsflyt kort, lesbar og reproduserbar fra rådata til scorede prediksjoner.

Hva er Scikit-learn?
Scikit lære er en åpen kildekode Python bibliotek for maskinlæringDen støtter veletablerte algoritmer som KNN, gradient boosting, random forest og SVM, og den er bygget på toppen av nusset og SciPy. Scikit-learn er mye brukt i Kaggle-konkurranser så vel som i fremtredende teknologiselskaper. Det dekker forprosessering, dimensjonalitetsreduksjon, klassifisering, regresjon, klynging og modellvalg.
Scikit-learn har noe av den beste dokumentasjonen av alle åpen kildekode-biblioteker. Det tilbyr til og med et interaktivt estimatordiagram, Velge riktig estimator, som veileder deg fra størrelsen på datasettet ditt til en kortliste over algoritmer som er verdt å prøve.
Figuren nedenfor illustrerer hvordan Scikit-learn fungerer.
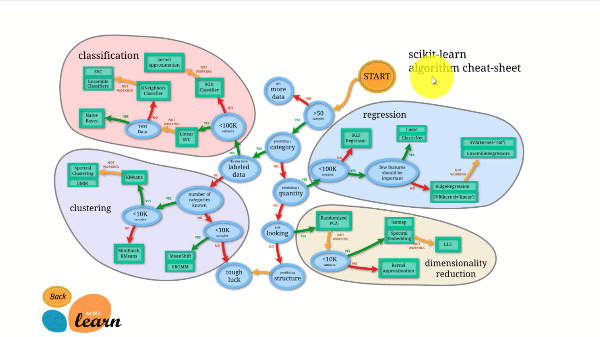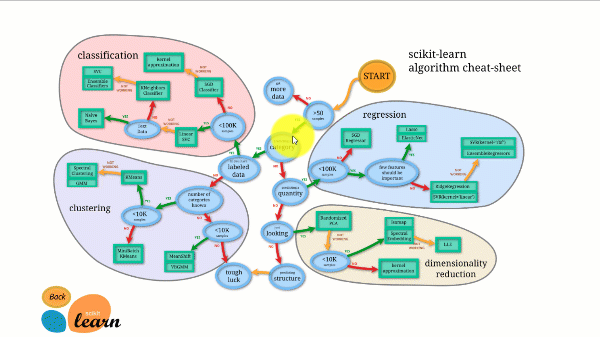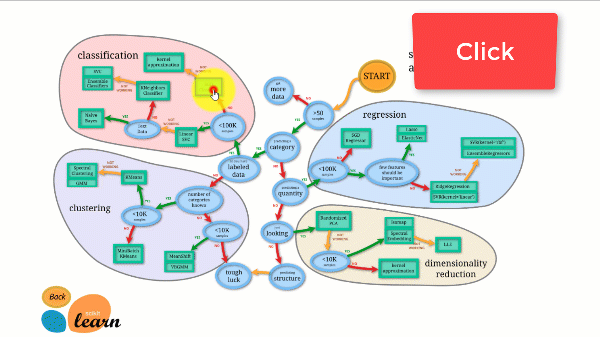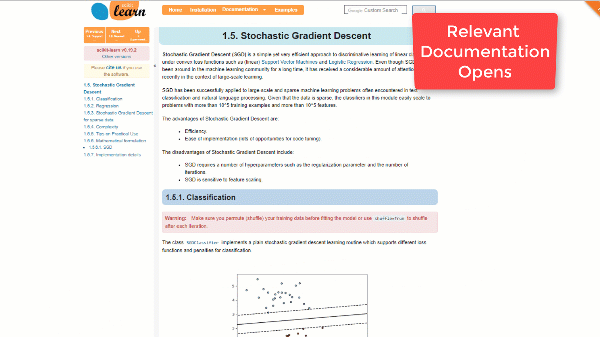
Scikit-learn er ikke vanskelig å bruke og gir utmerkede resultater. Den trener imidlertid på CPU-en: arbeidet paralleliseres på tvers av kjerner med n_jobs-argumentet i stedet for på et GPU. Å kjøre en dyp læringsalgoritme med den er mulig, men sjelden optimalt, spesielt hvis du allerede vet hvordan du bruker den. tensorflow.
Hvordan laste ned og installere Scikit-learn
Nå i dette Python Scikit-learn-veiledningen, du lærer hvordan du laster ned og installerer Scikit-learn:
Alternativ 1: AWS
Scikit-learn kan brukes over AWS. Et Docker-image med scikit-learn forhåndsinstallert sparer oppsettarbeidet fullstendig.
For å installere utviklerversjonen, kjør kommandoen nedenfor Jupyter:
import sys !{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Alternativ 2: Mac eller Windows bruker Anaconda
For å lære mer om installasjon av Anaconda, se hvordan laste ned og installere TensorFlow.
Da denne gjennomgangen ble skrevet, hadde utviklerne av scikit gitt ut en utviklingsversjon som løste problemer som var tilstede i den daværende gjeldende utgivelsen, så trinnene nedenfor bruker den utviklerversjonen. På en ny maskin i dag inneholder den nåværende stabile utgivelsen allerede alle transformatorene som brukes her, og pip install -U scikit-learn er nok.
Hvordan installere scikit-learn med Conda Environment
Hvis du installerte scikit-learn med conda-miljøet, følg trinnene nedenfor for å oppdatere til versjon 0.20.
Trinn 1) Aktiver tensorflow-miljøet
source activate hello-tf
Trinn 2) Fjern scikit-learn ved hjelp av conda-kommandoen
conda remove scikit-learn
Trinn 3) Installer utviklerversjonen
Installer utviklerversjonen av scikit-learn sammen med de nødvendige bibliotekene.
conda install -c anaconda git
pip install Cython
pip install h5py
pip install git+git://github.com/scikit-learn/scikit-learn.git
NOTAT: Windows brukerne trenger Microsoft Visual C++ 14. Du kan få det her..
Scikit-Learn-eksempel med maskinlæring
Denne Scikit-opplæringen er delt inn i to deler:
- Maskinlæring med scikit-learn
- Hvordan stole på modellen din med LIME
Den første delen beskriver hvordan man bygger en pipeline, lager en modell og finjusterer hyperparametrene, mens den andre delen dekker modelltolkning.
Trinn 1) Importer dataene
I løpet av denne Scikit Learn-opplæringen skal du bruke datasettet for voksne.
Filen leses direkte fra UCI Machine Learning Repository i koden nedenfor, så ingen manuell nedlasting er nødvendig. Hvis du er interessert i beskrivende statistikk, er Dive- og Overview-verktøyene verdt å ta en titt på. Se denne opplæringen for å lære mer om Dykk og Oversikt.
Du importerer datasettet med pandas. Merk at du må konvertere de kontinuerlige variablene til flyttallformat.
Dette datasettet inneholder åtte kategoriske variabler, oppført i CATE_FEATURES:
- arbeidsklasse
- utdanning
- ekteskapelig
- okkupasjon
- forholdet
- rase
- kjønn
- native_country
Den inkluderer også seks kontinuerlige variabler, oppført i CONTI_FEATURES:
- alder
- fnlwgt
- utdanning_nummer
- kapitalgevinst
- kapitaltap
- timer_uke
Listene fylles ut for hånd her, slik at du får en klarere oversikt over hvilke kolonner som er i spill. En raskere måte å bygge en liste med kategoriske eller kontinuerlige kolonner på er:
## List Categorical CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns print(CATE_FEATURES) ## List continuous CONTI_FEATURES = df_train._get_numeric_data() print(CONTI_FEATURES)
Her er koden for å importere dataene:
# Import dataset import pandas as pd ## Define path data COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country', 'label'] ### Define continuous list CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week'] ### Define categorical list CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country'] ## Prepare the data features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data" df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False) df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64') df_train.describe()
Å kalle describe() på rammen returnerer sammendragsstatistikken for de seks sammenhengende kolonnene:
| alder | fnlwgt | utdanning_nummer | kapitalgevinst | kapitaltap | timer_uke | |
|---|---|---|---|---|---|---|
| telle | 32561.000000 | 3.256100e + 04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| bety | 38.581647 | 1.897784e + 05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e + 05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| minutter | 17.000000 | 1.228500e + 04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e + 05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e + 05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e + 05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e + 06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
Du kan sjekke antallet unike verdier for native_country-funksjonen. Bare én husstand kommer fra Holland, Nederland. Den husstanden gir ingen informasjon og vil gi en feilmelding under trening.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
Du kan ekskludere denne uinformative raden fra datasettet:
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Deretter lagrer du posisjonen til de kontinuerlige funksjonene i en liste. Du trenger det i neste trinn for å bygge rørledningen.
Koden nedenfor går over alle kolonnenavnene i CONTI_FEATURES, leser hver plassering (det vil si kolonnenummeret) og legger den til i en liste kalt conti_features.
## Get the column index of the categorical features conti_features = [] for i in CONTI_FEATURES: position = df_train.columns.get_loc(i) conti_features.append(position) print(conti_features)
[0, 2, 10, 4, 11, 12]
Den neste blokken gjør den samme jobben for de kategoriske variablene.
## Get the column index of the categorical features categorical_features = [] for i in CATE_FEATURES: position = df_train.columns.get_loc(i) categorical_features.append(position) print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
Se nå på selve datasettet. Hvert kategorisk trekk er en streng, og en modell kan ikke mates med en strengverdi, så datasettet må transformeres med dummyvariabler.
df_train.head(5)
Faktisk trenger du én kolonne for hver gruppe i hver funksjon. Kjør først koden nedenfor for å beregne det totale antallet kolonner som trengs.
print(df_train[CATE_FEATURES].nunique(), 'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9
education 16
marital 7
occupation 15
relationship 6
race 5
sex 2
native_country 41
dtype: int64 There are 101 groups in the whole dataset
Hele datasettet inneholder 101 grupper, som vist ovenfor. Arbeidsklassefunksjonen alene har ni grupper. Du kan liste opp navnene på gruppene med koden nedenfor; unique() returnerer de distinkte verdiene for hver kategoriske funksjon.
for i in CATE_FEATURES: print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Treningsdatasettet vil derfor inneholde 101 + 6 kolonner: gruppene med én aktiv funksjon pluss de seks kontinuerlige funksjonene.
Scikit-learn kan ta seg av konverteringen i to trinn:
- Konverter strengen til en ID. State-gov blir ID 1, Self-emp-not-inc blir ID 2 og så videre. LabelEncoder gjør dette for deg.
- Transponer hver ID til en ny kolonne. Datasettet har 101 gruppe-ID-er, så det vil være 101 kolonner som fanger opp hver kategoriske funksjonsgruppe. Scikit-learn tilbyr OneHotEncoder for denne operasjonen.
Trinn 2) Lag toget/testsettet
Nå som datasettet er klart, del det 80/20: 80 prosent for treningssettet og 20 prosent for testsettet.
Du kan bruke train_test_split. Det første argumentet er datarammen til funksjonene, og det andre er etiketten. Du angir størrelsen på testsettet med test_size.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df_train[features], df_train.label, test_size = 0.2, random_state=0) X_train.head(5) print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Trinn 3) Bygg rørledningen
Pipelinen gjør det enklere å mate modellen med konsistente data. Tanken er å sende rådataene gjennom ett objekt som utfører hver operasjon i rekkefølge.
Med dette datasettet må du standardisere de kontinuerlige variablene og konvertere de kategoriske. Enhver operasjon kan ligge i en pipeline: manglende verdier kan erstattes med gjennomsnittet eller medianen, og nye variabler kan opprettes.
Du har et valg: hardkode de to prosessene, eller bygge en pipeline. Hardkoding kan lekke testdata inn i den tilpassede statistikken og skape inkonsekvenser over tid, så pipeline er det bedre alternativet.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
Rørledningen utfører to operasjoner før den mater den logistiske klassifikatoren:
- Standardiser variabelen: StandardScaler()
- Konverter de kategoriske funksjonene: OneHotEncoder(sparse=False)
Du utfører begge trinnene med make_column_transformer. Da denne gjennomgangen ble skrevet, var ikke funksjonen i den utgitte versjonen av scikit-learn (0.19), og det er derfor utviklerversjonen ble brukt; den har blitt levert i alle stabile utgivelser siden 0.20.
make_column_transformer er enkel: du deklarerer hvilke kolonner som skal transformeres og hvilken transformasjon som skal brukes. For å standardisere de kontinuerlige funksjonene sender du:
- conti_features, StandardScaler() inni make_column_transformer
- conti_features: listen over kontinuerlige kolonner
- StandardScaler: standardiserer disse kolonnene
OneHotEncoder-objektet i make_column_transformer koder etikettene automatisk.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
Versjonsmerknad: to argumenter i blokken ovenfor har flyttet seg. Nåværende utgivelser forventer transformatoren først og kolonnene deretter, og sparsom ble omdøpt sparse_output i scikit-learn 1.2 og fjernet i 1.4, så nyere kode leses OneHotEncoder(sparse_output=False).
Du kan teste om pipelinen fungerer med fit_transform. Utdataene skal ha formen 26048, 107.
preprocess.fit_transform(X_train).shape
(26048, 107)
Datatransformatoren er klar. Du oppretter pipelinen med make_pipeline, og når dataene er transformert, mater du den logistiske regresjonen.
model = make_pipeline(
preprocess,
LogisticRegression())
Det er da trivielt å trene en modell med scikit-learn: kall tilpasning på pipelinen. Du kan skrive ut nøyaktigheten med score-metoden.
model.fit(X_train, y_train) print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Til slutt kan du forutsi klassene med predict_proba, som returnerer sannsynligheten for hver klasse. Merk at de to sannsynlighetene summerer seg til én.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Trinn 4) Bruk av rørledningen vår i et rutenettsøk
Å justere hyperparametrene, verdiene som fikserer modellens struktur, kan være kjedelig og utmattende.
En måte å evaluere modellen på ville være å endre størrelsen på treningssettet og måle ytelsen, og gjenta øvelsen ti ganger for å se spredningen av poengsummen. Det er mye manuelt arbeid.
I stedet tilbyr scikit-learn funksjoner som utfører parameterjustering og kryssvalidering for deg.
Kryssvalidering
Kryssvalidering betyr at treningssettet deles n ganger i folder under trening, og modellen evalueres n ganger. Hvis cv settes til 10, trenes og evalueres modellen ti ganger. I hver runde trener klassifikatoren på ni tilfeldig valgte folder, og den tiende folden beholdes for evaluering.
Rutenettsøk
Hver klassifikator har hyperparametere som skal finjusteres. Du kan prøve verdier én om gangen, eller angi et parameternett. Dokumentasjonen for scikit-learn viser alle parameterne den logistiske klassifikatoren godtar. For å holde treningen rask, finjusterer dette eksemplet bare C-parameteren, som kontrollerer regularisering. Den må være positiv, og en liten verdi gir mer vekt til regularisatoren.
Du bruker GridSearchCV-objektet, som tar en ordbok med hyperparametrene for å finjustere. List opp hver hyperparameter etterfulgt av verdiene du vil prøve. For å finjustere C skriver du:
- 'logisticregression__C': [0.001, 0.01, 0.1, 1.0] — parameternavnet innledes av klassifikatornavnet med små bokstaver og to understrekninger.
Modellen vil prøve fire forskjellige verdier: 0.001, 0.01, 0.1 og 1. Den er trent med 10 folder, det vil si cv=10.
from sklearn.model_selection import GridSearchCV # Construct the parameter grid param_grid = { 'logisticregression__C': [0.001, 0.01,0.1, 1.0], }
Du kan nå trene modellen ved hjelp av GridSearchCV med parameterne grid og cv.
# Train the model grid_clf = GridSearchCV(model, param_grid, cv=10, iid=False) grid_clf.fit(X_train, y_train)
Utgang:
GridSearchCV(cv=10, error_score='raise-deprecating', estimator=Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001, verbose=0, warm_start=False))]), fit_params=None, iid=False, n_jobs=1, param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn', scoring=None, verbose=0)
Versjonsmerknad: de iid Argumentet som er synlig i denne utdataen ble avskrevet i scikit-learn 0.22 og fjernet i 0.24, så det bør ganske enkelt fjernes fra GridSearchCV-kallet på nåværende versjoner.
For å få tilgang til de beste parameterne bruker du best_params_.
grid_clf.best_params_
Utgang:
{'logisticregression__C': 1.0}
Etter å ha trent modellen med fire forskjellige regulariseringsverdier, gir den optimale parameteren:
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
beste logistiske regresjon fra rutenettsøk: 0.850891
For å få tilgang til de anslåtte sannsynlighetene:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
XGBoost-modell med scikit-learn
Prøv nå en av de sterkeste klassifikatorene på markedet. XGBoost er en gradientforsterkende forbedring av den tilfeldige skogen. Den teoretiske bakgrunnen er utenfor rammen av dette. Python Scikit-opplæringen, men husk at XGBoost har vunnet mange Kaggle-konkurranser. På et datasett av gjennomsnittlig størrelse kan den prestere like bra som en dyp læringsalgoritme, eller bedre.
Klassifikatoren er utfordrende å trene fordi den eksponerer et stort antall parametere. Du kan selvfølgelig bruke GridSearchCV til å velge dem for deg.
Et bedre alternativ her er RandomizedSearchCV. GridSearchCV blir treg når rutenettet er stort, fordi søkeområdet vokser med hver parameter som legges til. RandomizedSearchCV sampler i stedet verdiene til hver hyperparameter tilfeldig på hver iterasjon, slik at 1,000 iterasjoner evaluerer 1,000 kombinasjoner. Det fungerer ellers omtrent som GridSearchCV.
Du må importere xgboost. Hvis biblioteket ikke er installert, kjør pip3 install xgboost, eller installer det fra innsiden av en Jupyter notatbok med:
use import sys
!{sys.executable} -m pip install xgboost
Importer deretter klassifikatoren og de to søkehjelperne:
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
Det neste trinnet i denne Scikit Python veiledningen går ut på å spesifisere parameterne som skal finjusteres. Den offisielle XGBoost-dokumentasjonen lister dem alle opp. Av hensyn til dette Python I Sklearn-opplæringen velger du bare to hyperparametere med to verdier hver, fordi XGBoost tar lang tid å trene og hvert ekstra gridpunkt øker ventetiden.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
Deretter konstruerer du en ny pipeline med XGBoost-klassifikatoren og 600 estimatorer. n_estimators er i seg selv justerbar, og en høy verdi kan føre til overtilpasning. Du kan prøve andre verdier, men vær oppmerksom på at det kan ta timer. Alle andre parametere beholder standardverdien.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
Du kan forbedre kryssvalideringen med kryssvalidatoren Stratified K-Folds. Bare tre folder brukes her for å øke hastigheten på beregningen, noe som går utover kvaliteten. Øk dette til 5 eller 10 på din egen maskin for bedre resultater. Modellen trenes over fire iterasjoner.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
Det randomiserte søket er klart, slik at du kan trene modellen.
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False)
random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 ..............
[CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min
[Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min
[CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
Som du kan se, scorer XGBoost bedre enn den tidligere logistiske regresjonen.
print("Best parameter", random_search.best_params_) print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Lag DNN med MLPClassifier i scikit-learn
Til slutt kan du trene et nevralt nettverk med scikit-learn. Metoden er den samme som for alle andre klassifikatorer, og estimatoren er MLPClassifier.
from sklearn.neural_network import MLPClassifier
Nettverket nedenfor er definert med:
- Adam løser
- ReLU aktiveringsfunksjon
- Alfa = 0.0001
- Batchstørrelse på 150
- To skjulte lag med henholdsvis 200 og 100 nevroner
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
Du kan endre antall lag for å forbedre modellen.
model_dnn.fit(X_train, y_train) print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN regresjonsscore: 0.821253
LIME: Stol på modellen din
Nå som du har en god modell, trenger du en måte å stole på den. Maskinlæringsalgoritmer, spesielt tilfeldige skoger og nevrale nettverk, er kjent som svartboksmodeller: de fungerer, men ingen kan se hvorfor.
Tre forskere har laget et verktøy som viser hvordan datamaskinen kommer frem til en prediksjon. Artikkelen deres er «Hvorfor skulle jeg stole på deg?», og algoritmen de publiserte kalles Local Interpretable Model-Agnostic Explanations (LIME).
Ta et eksempel. Noen ganger vet du ikke om en maskinlæringsprediksjon kan stoles på. En lege kan ikke godta en diagnose bare fordi en datamaskin produserte den, og du må vite om en modell er pålitelig før du setter den i produksjon.
Tenk deg å kunne se hvorfor en klassifikator kom med en prediksjon, selv for modeller så kompliserte som nevrale nettverk, tilfeldige skoger eller SVM-er med en vilkårlig kjerne. Det blir mye enklere å stole på en prediksjon når årsakene bak den er synlige, og like enklere å avgjøre når en modell ikke bør stoles på. LIME forteller deg hvilke funksjoner som drev klassifikatorens beslutning.
Dataklargjøring
Det er et par ting du må endre for å kjøre LIME med PythonFørst installerer du lime i terminalen med pip install lime.
Lime bruker et LimeTabularExplainer-objekt for å tilnærme modellen lokalt. Dette objektet krever:
- et datasett i nusset format
- Navnet på funksjonene: funksjonsnavn
- Navnet på klassene: klassenavn
- Indeksen til kolonnen med kategoriske funksjoner: categorical_features
- Navnet på gruppen for hvert kategoriske trekk: kategoriske_navn
Lag NumPy-togsettet
Du kan kopiere og konvertere df_train fra pandas til NumPy veldig enkelt.
df_train.head(5)
# Create numpy data
df_lime = df_train
df_lime.head(3)
Få klassenavnet
Etiketten er tilgjengelig via unique(). Du skal se:
- '<= 50 XNUMX'
- '> 50K'
# Get the class name
class_names = df_lime.label.unique()
class_names
array(['<=50K', '>50K'], dtype=object)
Indekser de kategoriske funksjonskolonnene
Bruk metoden du lærte tidligere for å få navnet på hver gruppe. Du koder etiketten med LabelEncoder og gjentar operasjonen på hvert kategoriske trekk.
## import sklearn.preprocessing as preprocessing categorical_names = {} for feature in CATE_FEATURES: le = preprocessing.LabelEncoder() le.fit(df_lime[feature]) df_lime[feature] = le.transform(df_lime[feature]) categorical_names[feature] = le.classes_ print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Nå som datasettet er klart, kan du bygge de forskjellige datasettene som vises i Scikit-læringseksemplene nedenfor. Dataene transformeres utenfor pipelinen her for å unngå feil med LIME: treningssettet som sendes til LimeTabularExplainer må være en NumPy-matrise uten strenger, og metoden ovenfor har allerede produsert en.
from sklearn.model_selection import train_test_split X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features], df_lime.label, test_size = 0.2, random_state=0) X_train_lime.head(5)
Du kan lage pipelinen med de optimale parametrene som XGBoost finner.
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None, steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None, transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,... reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None, silent=True, subsample=1))])
Du får en advarsel. Den forklarer at du ikke trenger å opprette en label-koder før pipelinen. Hvis du ikke bruker LIME, er metoden fra den første delen av denne veiledningen for maskinlæring med Scikit-learn grei. Ellers behold denne tilnærmingen: først opprett et kodet datasett, og bruk deretter one-hot-koderen inne i pipelinen.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Før du tar LIME i bruk, bør du opprette en NumPy-matrise som inneholder funksjonene til de feilklassifiserte radene. Du kan bruke den listen senere for å få en idé om hva som villedet klassifikatoren.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1) temp['predicted'] = model_xgb.predict(X_test_lime) temp['wrong']= temp['label'] != temp['predicted'] temp = temp.query('wrong==True').drop('wrong', axis=1) temp= temp.sort_values(by=['label']) temp.shape
(826, 16)
Deretter oppretter du en lambda-funksjon som henter prediksjonen fra modellen for nye data. Du vil trenge den snart.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float)
X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
Du konverterer pandas-datarammen til en NumPy-array.
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private', 'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'], dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th', 'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad', 'Masters', 'Preschool', 'Prof-school', 'Some-college'], dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse', 'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'], dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair', 'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners', 'Machine-op-inspct', 'Other-service', 'Priv-house-serv', 'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support', 'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child', 'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other', 'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba', 'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England', 'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras', 'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica', 'Japan', 'Laos', 'Mexico', 'Nicaragua', 'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland', 'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan', 'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam', 'Yugoslavia'], dtype=object)}
import lime import lime.lime_tabular ### Train should be label encoded not one hot encoded explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime , feature_names = features, class_names=class_names, categorical_features=categorical_features, categorical_names=categorical_names, kernel_width=3)
Velg nå en tilfeldig husstand fra testsettet og se både prediksjonen og hvordan datamaskinen kom frem til den.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
Du kan bruke explainer-funksjonen med explain_instance for å undersøke resonnementet bak modellen. Diagrammet den gjengir vises nedenfor.
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klassifikatoren forutså denne husstanden riktig: inntekten er faktisk over 50 000.
Det første man må merke seg er at klassifikatoren ikke er veldig sikker på seg selv. Den forutsier en inntekt over 50 000 med en sannsynlighet på 64 %, og at 64 % er drevet av kapitalgevinst og sivilstatus. Den blå fargen bidrar negativt til den positive klassen og den oransje linjen positivt.
Klassifikatoren er nølende fordi kapitalgevinsten til denne husholdningen er null, mens kapitalgevinst vanligvis er en god prediktor for formue. Husholdningen jobber også færre enn 40 timer per uke. Alder, yrke og kjønn bidrar alle positivt.
Hvis sivilstatusen var singel, ville klassifikatoren ha predikert en inntekt under 50 000 (0.64 – 0.18 = 0.46).
Prøv nå en annen husholdning, en som ble feilklassifisert. Forklaringstabellen for den følger koden.
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1 print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K
predicted >50K
Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)

Klassifikatoren forutså en inntekt under 50 000, noe som er feil. Denne husholdningen er uvanlig: den har verken kapitalgevinst eller kapitaltap, personen er skilt, nær 60 år gammel og utdannet, det vil si at utdanningsnummer > 12. Klassifikatoren fulgte det overordnede mønsteret og plasserte husholdningen under 50 000.
Lek deg med LIME selv, og du vil legge merke til mange grove feil fra klassifikatoren. GitHub-arkivet til bibliotekforfatteren inneholder ekstra dokumentasjon for klassifisering av bilder og tekst.
Scikit-learn-kommandoreferanse
Nedenfor er en liste over nyttige kommandoer som gjelder for scikit-learn versjon 0.20 og nyere.
| Oppgave | Funksjon eller klasse |
|---|---|
| Opprett tog-/testdatasettet | train_test_split |
| Bygg en rørledning | |
| Merk kolonnene og bruk transformasjonen | make_column_transformator |
| Type transformasjon | |
| Standardiser | Standard Scaler |
| Min-maks skalering | MinMaxScaler |
| Normaliser | Normalisering |
| Imputer manglende verdier | SimpleImputer |
| Konverter kategorisk | OneHotEncoder |
| Tilpass og transformer dataene | passe_transform |
| Lag rørledningen | make_pipeline |
| Grunnmodell | |
| Logistisk regresjon | Logistisk regresjon |
| Xgboost | XGBClassifier |
| Nevralt nett | MLPClassifier |
| Rutenettsøk | GridSearchCV |
| Randomisert søk | RandomizedSearchCV |